
一.概述:
游码编程(RLC, Run Length Coding) ,又称”运动长度编码”或”行程编码”,是一种统计编码,该编码属于无损压缩编码,是栅格数据压缩的重要编码方法.
常见的游程编码格式包括: TGA, Packbits, PCX, ILBM.
二.游码编程的记录方式有两种:
例如:
A A A B B
A C C C A逐行记录每个游程的终点列号:
记作:
A,3 B,5
A,1 C,4 A,5逐行记录每个游程的长度(像元素):
记作:
A,3 B,2
A,1 C,3 A,1优点:
将重复性高的资料压缩成小单元
例如:
一组资料串:"AAAABBBCCDEEEE"
(由4个A、3个B、2个C、1个D、4个E组成)
压缩为:4A3B2C1D4E
(由14个单位转成10个单位)缺点:
若该资料出现频率不高,可能导致压缩结果资料比原始资料大
例如:
原始资料:"ABCDE"
(由1个A、1个B、1个C、1个D、1个E组成)
压缩为:"1A1B1C1D1E"
(由5个单位转成10个单位)。4位元表示法:
利用4个位元来储存整数, 以符号C表示整数值. 其可表现的最大整数值为15, 若资料重复出现次数超过15, 便以”分段”方式处理.
假设某资料出现N次,则可以将其分成(N/15)+1段落来处理,其中N/15的值为无条件舍去。
例如连续出现33个A:
原始资料:
AAAAAAAAAAAAAAA AAAAAAAAAAAAAAA AAA
压缩结果:
15A 15A 3A
内部储存码:
1111 01000001 1111 01000001 0011 01000001
15 A 15 A 3 A8位元素表示法:
同4位元表示法的概念,其能表示最大整数为255。假设某资料出现N次,则可以将其分成(N/255)+1段落来处理,其中N/255的值为无条件舍去。
三. 压缩策略:
先使用一个暂存函数Q读取第一个资料, 接着将下一个资料与Q值比,若资料相同, 则计数器加1; 若资料不同,则将计数器存的数值以及Q值输出, 再初始计数器为, Q值改为下一个资料. 以此类推, 完成资料压缩。
以下为简易的算法:
input: AAABCCBCCCCAA
for i=1:size(input) if (Q = input(i)) 计数器 + else output的前项 = 计数器的值,
output的下一项=Q值, Q换成input(i), 计数器值换成0 endend
解压缩:
其方法为逐一读取整数(以C表示)与资料(以B表示), 将C与B的二进制码分别转成十进制整数以及原始资料符号,最后输出共C次资料B, 即完成一次资料解压缩; 接着重复上述步骤, 完成所有资料输出.
四. 应用场景
大量白色或者黑色的区域单色影像图
电脑生成的同色区块的彩色图像(如建筑绘图纸)
TIFF files
PDF files
五. 总结:
游码编程适合的场景是数据本身具有大量连续重复出现的内容.
六. 压缩文本(Python代码执行)
简单的实现,只能压缩英文字母,读取一个字符串,然后一直数出现了多少个连续字符,当重复被打断时就将上一个的重复字符和重复次数记一下,恢复时反之。
① 只能压缩英文字母, 执行代码:
#! /usr/bin/python3
# -*- coding: utf-8 -*-
import random
import string
def rle_compress(s):
"""
对字符串使用RLE算法压缩,s中不能出现数字
:param s:
:return:
"""
result = ''
last = s[0]
count = 1
for _ in s[1:]:
if last == _:
count += 1
else:
result += str(count) + last
last = _
count = 1
result += str(count) + last
return result
def rle_decompress(s):
result = ''
count = ''
for _ in s:
if _.isdigit():
count += _
else:
result += _ * int(count)
count = ''
return result
def random_rle_friendly_string(length):
"""
生成对RLE算法友好的字符串以演示压缩效果
:param length:
:return:
"""
result = ''
while length > 0:
current_length = random.randint(1, length)
current_char = random.choice(string.ascii_letters)
result += (current_char * current_length)
length -= current_length
return result
if __name__ == '__main__':
raw_string = random_rle_friendly_string(128)
rle_compressed = rle_compress(raw_string)
rle_decompress = rle_decompress(rle_compressed)
print(' raw string: %s' % raw_string)
print(' rle compress: %s' % rle_compressed)
print('rle decompress: %s' % rle_decompress)执行效果:
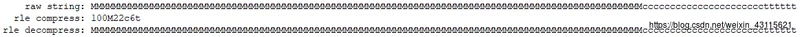
② 采用定长执行代码:
#! /usr/bin/python3
# -*- coding: utf-8 -*-
import random
import string
def rle_compress(s):
"""
对字符串使用RLE算法压缩,s可以出现任意字符,包括数字,因为采用了定长表示重复次数
:param s:
:return:
"""
result = ''
last = s[0]
count = 1
for _ in s[1:]:
# 采用一个字符表示重复次数,所以count最大是9
if last == _ and count < 9:
count += 1
else:
result += str(count) + last
last = _
count = 1
result += str(count) + last
return result
def rle_decompress(s):
result = ''
for _ in range(len(s)):
if _ % 2 == 0:
result += int(s[_]) * s[_ + 1]
return result
def random_rle_friendly_string(length):
"""
生成对RLE算法友好的字符串以演示压缩效果
:param length:
:return:
"""
char_list_to_be_choice = string.digits + string.ascii_letters
result = ''
while length > 0:
current_length = random.randint(1, length)
current_char = random.choice(char_list_to_be_choice)
result += (current_char * current_length)
length -= current_length
return result
if __name__ == '__main__':
# raw_string = random_rle_friendly_string(128)
raw_string = "MMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMcccccccccccccccccccccctttttt"
rle_compressed = rle_compress(raw_string)
rle_decompress = rle_decompress(rle_compressed)
print(' raw string: %s' % raw_string)
print(' rle compress: %s' % rle_compressed)
print('rle decompress: %s' % rle_decompress)执行效果:

③压缩字节(二进制文件)执行代码::
二进制文件在内存中的表示是字节,所以需要想办法能够压缩字节,压缩字节和压缩字符其实是一样一样的,还是结构化的存储,每两个字节一组,每组的第一个字节表示连续出现次数,第二个字节表示连续出现的字节。
#! /usr/bin/python3
# -*- coding: utf-8 -*-
def compress_file_use_rle(src_path, dest_path):
with open(dest_path, 'wb') as dest:
with open(src_path, 'rb') as src:
last = None
count = 0
t = src.read(1)
while t:
if last is None:
last = t
count = 1
else:
# 一个字节能够存储的最大长度是255
if t == last and count < 255:
count += 1
else:
dest.write(int.to_bytes(count, 1, byteorder='big'))
dest.write(last)
last = t
count = 1
t = src.read(1)
dest.write(int.to_bytes(count, 1, byteorder='big'))
dest.write(last)
def decompress_file_use_rle(src_path, dest_path):
with open(dest_path, 'wb') as dest:
with open(src_path, 'rb') as src:
count = src.read(1)
byte = src.read(1)
while count and byte:
dest.write(int.from_bytes(count, byteorder='big') * byte)
count = src.read(1)
byte = src.read(1)
if __name__ == '__main__':
img_name = 'test-bmp-24'
suffix = 'bmp'
raw_img_path = 'data/%s.%s' % (img_name, suffix)
rle_compressed_img_save_path = 'data/%s-rle-compressed.%s' % (img_name, suffix)
rle_decompress_img_save_path = 'data/%s-rle-decompress.%s' % (img_name, suffix)
compress_file_use_rle(raw_img_path, rle_compressed_img_save_path)
decompress_file_use_rle(rle_compressed_img_save_path, rle_decompress_img_save_path)