
概述
本文是对资深游戏AI工程师Troy Humphreys所撰写的《Exploring HTN Planners through Example》一文关于HTN概念和原理部分的解读。在此基础上,笔者又自己绘制了一些示意图,希望能用一种通俗易懂的方式来帮助读者对核心概念和原理的理解。
正文
引入
我们试图解决的问题是【行为选择】,众多我们所熟知的算法都是为了解决这一问题的,比如有限状态机FSM,行为树BT,神经网络NN,规划器Planners。
本文将介绍的解决方案属于Planners的一种,叫做分层任务网络 (Hierarchical Task Networks, HTN),它将待解决问题作为输入,将能解决该问题的一系列行动步骤作为输出。
HTN的特点是,它可以用非常高层次和抽象的方式来描述待解决的问题,比如“像一个城市居民一样行动”。然后在规划过程中,HTN会把高层次的任务逐步地分解为更多更小的低层次任务,最终达到可具体执行的层次。
HTN的组成部分
这边放一张我自己画的图。
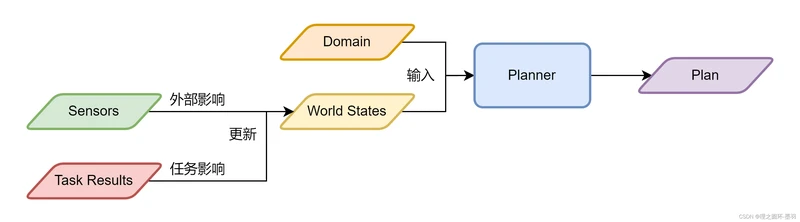
简单来说,就是Planner根据Domain和World States,来输出一个Plan。Domain是需要解决的问题,World States是当前系统的状态。
World States由可以被两个不同的数据源更新。一个是外部数据源,HTN通过Sensors来感知外部数据的变化,并对应地改变World States。而Task Results更像是“内部”的数据,因为Task是包含于Planner给出的Plan中的,这些Task被实际执行后,所产生的效果也会对World States产生更新。
世界状态World States
World States是一组属性,智能体必须依靠这些属性的信息才能够给出合理的推理结果。事实上,World States是对问题的边界限定,系统中可能有着众多的数据项,但是如果某个数据项与当前需要决策的问题无关,那么它就不属于World States。
在HTN中,World States的值使用抽象的值表达,比如近战攻击: EEnemyRange.MeleeRange,而不是使用具体实际值,比如:10。因为World States仅用于提供给Planner做决策使用,它必须能够被Planner理解。
传感器Sensors
之前已经提到,Sensors用于感知外部的变化。比如你在给一个怪兽开发AI系统,怪兽的行动需要依赖于观察附近有没有房子,那么如果奥特曼打爆了一座房子,那么这个变化对怪兽的AI系统来说是一种外部变化,需要由Sensors来感知到。Sensors在感知到信息之后,需要将其加工,从而对World States施加对应的变化,比如:附近房屋数量 - 1
任务Task
在HTN架构中,Task分为两种,一种叫做原始任务(Primitive Tasks),另一种叫做复合任务(Compound Tasks)。原始任务是可以被实际执行的具体任务,而复合任务是抽象的,还不能被实际执行的任务。之前我们举过一个例子,叫做“像一个城市居民一样行动”,这是个复合任务,因为如果你不对其进行拆解的话,你实际上不清楚具体要做哪些事情,它没有办法被直接实际执行。
原始任务Primitive Tasks
计划Plan是由一系列原始任务组成的。当我们在说Plan这个词的时候,我们实际想得到的就是一连串的行动,”先执行A行动,再执行B行动,最后执行C行动”。所以对Planner来说,它的工作其实就是去找这样一个原始任务的列表。
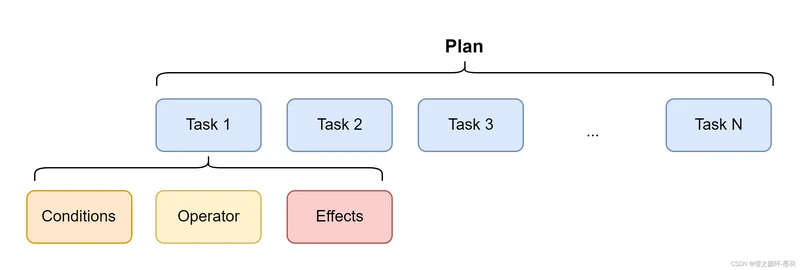
原始任务又由3个要素组成,条件Conditions,操作Operator,效果Effects。
当Planner给出Plan之后,会将Plan交给Plan Runner,由Plan Runner负责执行。只有当Conditions被满足时,该原始任务才能够被执行,Operator指的是具体的行为,比如MoveTo(position),Effects指的是该任务成功执行后产生的效果,特指对World States产生的影响。
原始任务[任务名称(参数1, 参数2, ...)]
条件[条件1, 条件2, ...] // 可选的
操作[操作名称(参数1, 参数2, ...)]
效果[世界状态的变化] // 可选的
复合任务Compound Tasks
先前我们已经简单介绍了复合任务,并且我已经提到“拆解”这个词。直觉上来说,如果我们要从复合任务出发,找到可被执行的原始任务,所使用的方式就是对任务进行拆解。
要“执行”一个复合任务,可以有多种方法Method备选,Planner根据各种方法所需要满足的条件来选择使用何种方法,随后将这个复合任务拆解为该方法下的子任务,子任务可以是原始任务,也可以是复合任务。
复合任务实际上只是方法Method和子任务Subtasks的概念容器,它在概念上帮助我们理解HTN的工作原理,不具有其他实际效果。
复合任务[任务名称(参数1, 参数2, ...)]
方法1[条件1, 条件2, ...]
子任务[子任务1(参数1, 参数2, ...), 子任务2(参数1, 参数2, ...), ...]
方法2[条件1, 条件2, ...]
子任务[子任务1(参数1, 参数2, ...), 子任务2(参数1, 参数2, ...), ...]
域Domain
域包含了由复合任务和原始任务所组成的整个任务层次架构,代表了智能体在各种条件下所能够执行的所有方法和行动。
此处是一个原文中Domain的例子:
Compound Task [BeTrunkThumper]
Method [WsCanSeeEnemy == true]
Subtasks [NavigateToEnemy(), DoTrunkSlam()]
Method [true]
Subtasks [ChooseBridgeToCheck(), NavigateToBridge(), CheckBridge()]
Primitive Task [DoTrunkSlam]
Operator [AnimatedAttackOperator(TrunkSlamAnimName)]
Primitive Task [NavigateToEnemy]
Operator [NavigateToOperator(EnemyLocRef)]
Effects [WsLocation = EnemyLocRef]
Primitive Task [ChooseBridgeToCheck]
Operator [ChooseBridgeToCheckOperator]
Primitive Task [NavigateToBridge]
Operator [NavigateToOperator(NextBridgeLocRef)]
Effects [WsLocation = NextBridgeLocRef]
Primitive Task [CheckBridge]
Operator [CheckBridgeOperator(SearchAnimName)]
整体架构
了解了上述所有概念和原理后,我们再回过头来查看原文中给出的HTN系统架构图。主要是,我一开始看这个图的时候,感觉不太好理解,在逐渐阅读后续内容后,才逐渐理解了各个部分的含义,现在大家看完之前的一些概念,再来理解这个图的时候,应该就比较好懂了。
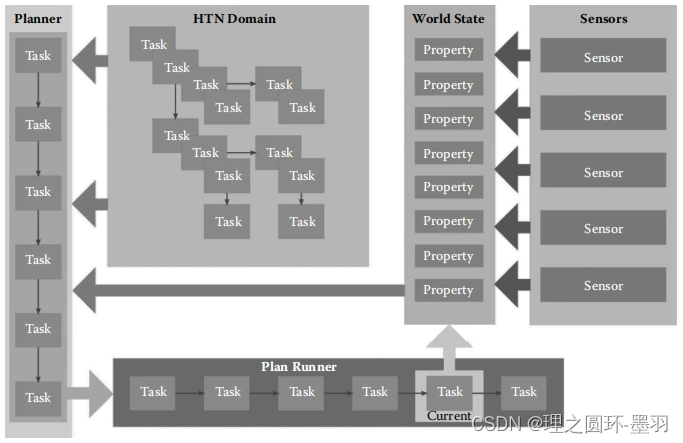
从右往左读,Sensors和Task的Effects共同影响了World States,Domain中包含了所有可选用的Task,和World States信息一起提供给Planner,由Planner给出Plan交给Plan Runner去执行。而Plan其实就是一系列可执行的Primitive Tasks。
Planner工作原理
Planner在需要输出一个计划时工作,那么我们在哪些时间节点需要输出一个计划?
答案是3个时间点:当智能体成功完成或失败退出当前计划时、当智能体当前没有待执行的计划时、当Sensors改变了World States时。
那么Planner怎么去找到满足要求的Plan呢?接下来我们就来看看HTN的核心算法。
WorkingWS = CurrentWorldState // 复制一份当前的WorldStates
TasksToProcess.Push(RootTask) // 把根任务推到待处理任务栈里
// 只要待处理任务栈里还存在待处理的Task,就一直执行后续循环
while TasksToProcess.NotEmpty
{
CurrentTask = TasksToProcess.Pop()
if CurrentTask.Type == CompoundTask
{
// 根据当前WorldStates选一个合适的Method
SatisfiedMethod = CurrentTask.FindSatisfiedMethod(WorkingWS)
if SatisfiedMethod != null
{
// 分解并记录当前复合任务
RecordDecompositionOfTask(CurrentTask, FinalPlan, DecompHistory)
// 把这个复合任务的子任务推到待处理任务栈里
TasksToProcess.InsertTop(SatisfiedMethod.SubTasks)
}
else
{
// 回滚到上一次复合任务分解前
RestoreToLastDecomposedTask()
}
}
else//Primitive Task
{
if PrimitiveConditionMet(CurrentTask)
{
// 执行本原始任务的效果
// 将效果施加到用于决策的WorldStates副本中,而不是WorldStates原始数据。
WorkingWS.ApplyEffects(CurrentTask.Effects)
// 将任务推到FinalPlan队列中
FinalPlan.PushBack(CurrentTask)
}
else
{
// 回滚到上一次复合任务分解前
RestoreToLastDecomposedTask()
}
}
}
大部分环节我都配了注释,有两点想多说一下。
第一点是关于复合任务分解的,复合任务分解时需要记录进DecompHistory数据结构中,用于后续回滚时使用。
HTN本质上是深度有限搜索,如果在当前这个分支上找不到任何继续向下搜索的路径时,就会表现为:1. 复合任务没有任何满足条件的方法;2. 原始任务不满足前置条件。那么此时说明这个分支已经“无路可走了”,要回滚到上一个复合任务被分解之前,再去选择其他分支。
第二点是关于WorkingWS.ApplyEffects(CurrentTask.Effects)这行代码的。此时我们做的事情是已经选定了这个原始任务放入最终的计划之中,那么在实际执行时,执行完这个任务后,它的Effects将改变WorldStates,也就是这个Plan后续的Tasks必须要能够满足被本Task改变过后的WorldStates。因此我们在规划的过程中必须预先模拟这个影响,去对我们复制出来的WorldStates的副本做出相应改变,并在此基础上去寻找后续的计划部分。我们也不应该将影响施加到真实的WorldStates中,因为此时Task还没有真正被执行。
小结
写本文主要是笔者学习过程的记录,加深对HTN框架的理解和认识,如果能够帮助到读者,那就更是锦上添花、荣幸之至了。
之后会继续解读原文中给出的开发案例,以及实际去写一些实验代码来进一步研究HTN。