
HLFR 方法是对LFR方法的改进,在LFR的基础上使用了hierarchical hypothesis技术。效果普遍比传统的DDM方法要好,主要体现在不会出现过多的false positive, 以及对于imbalance class效果很好(因为监视的metric很多)。但是LFR和HLFR效果却差不多。
可改进部分:
- 这两种方法似乎都只能对binary classification有效
- 似乎没有使用windowing技术,可以通过设置窗口限制进入算法的历史时间步
- 在HLFR中,当permutation test否决LFR算法时,可以考虑加入自动调参
先来讲LFR(linear four rates)
这是一种漂移检测算法,four rates指的是由classifier的混淆矩阵所计算而来的四个参数

- True positive rate/tpr:TP/(TP+FN)
- True negative rate/tnr: TN/(TN+FP)
- Positive predicted value/ppv: TP/(TP+FP)
- Negative predicted value/npv: TN/(TN+FN)
主流的漂移检测算法(DDM,ADWIN)只关注模型的error rate,这导致此类算法无法检测出模型的召回率或者精确度降低,通过检测four rates,可以更全面的反映出模型性能的变化。
每当classifier收到新的数据并计算出一个相应的返回值时,总有两个rates会受到影响,记作这两个值 受到 (返回值,真实值)的影响。
在classifier运行中,每次计算新样本都会出现两个被(返回值,真实值)所影响的rates,分别统计四个rates的出现次数作为经验速率(empirical rate).然后通过混淆矩阵计算classifier的precision(精准度)和recall(召回度),利用这两个metrics,然后通过Monte Carlo模拟来模拟出4个rates的历史分布,最后比较rates的统计值和历史分布之间的差异,如果差异显著,则代表检测到concept drift。
具体算法:

注:
R代表4个rates的统计量,注意R其实是4个值,并且计算R的过程中使用了时间衰减因子
P的计算其实就是精确度和召回度的计算,在tpr和tnr中,我们更关心召回度;在ppv和npv中,我们更关心精确度。之后通过BoundTable(不太理解这个算法)计算出warn.bd和detect.bd。
Evaluation:
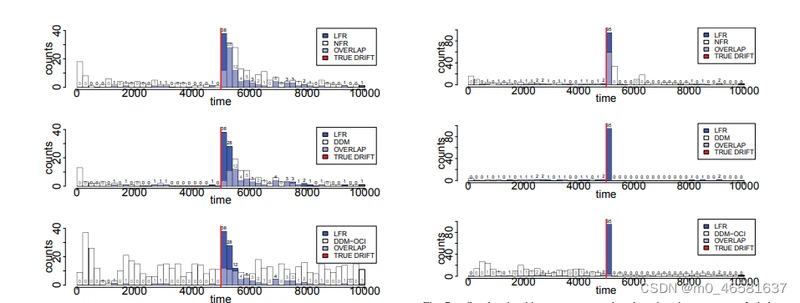
由于监控了更多的metric,LFR的性能比起传统DDM算法有着很大提升,而且大量减少了false alarm

HLFR
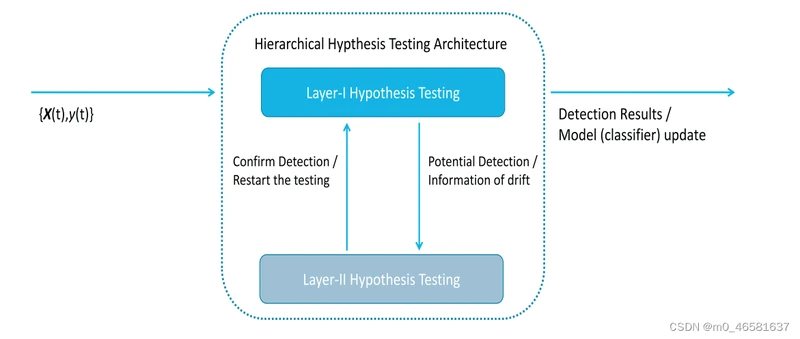
在LFR的基础上加了一层,当LFR检测到drift时,在第二层使用permutation test方法进行二次验证,效果和LFR差不了太多,只能说进一步减少了false alarm。


ref:
1. Concept drift detection and adaptation with hierarchical hypothesis testing
2. Concept Drift Detection for Streaming Data