
一、HPL简介
HPL(The High-Performance Linpack Benchmark)是测试高性能计算集群系统浮点性能的基准程序。HPL通过对高性能计算集群采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算集群的浮点计算能力。
- 什么是高斯消元? 线性代数 —— 高斯消元法_Alex_McAvoy的博客-CSDN博客
- 关于原理:复杂异构计算系统HPL的优化
二、浮点计算峰值
浮点计算峰值(FLOPS,全称Floating-point operations per second)是指计算机每秒可以完成的浮点计算次数,包括理论浮点峰值和实测浮点峰值。
关于浮点计算单位:
一个MFLOPS(megaFLOPS)等於每秒一佰万(=10^6)次的浮点运算,
一个GFLOPS(gigaFLOPS)等於每秒拾亿(=10^9)次的浮点运算,
一个TFLOPS(teraFLOPS)等於每秒万亿(=10^12)次的浮点运算,
一个PFLOPS(petaFLOPS)等於每秒千万亿(=10^15)次的浮点运算,
一个EFLOPS(exaFLOPS)等於每秒百亿亿(=10^18)次的浮点运算
一个ZFLOPS(zettaFLOPS)等于每秒十万京(=10^21)次的浮点运算。
参考文章: CPU算力(cpu理论浮点运算值)_DinqYi的博客-CSDN博客
1、理论浮点峰值
理论浮点峰值=CPU主频×CPU核数×CPU每周期执行浮点运算的次数
理论浮点峰值是该计算机理论上每秒可以完成的浮点计算次数,主要由CPU的主频(GHz)决定。
具体可参考文章:php对cpu浮点运算能力的要求,关于CPU的浮点运算能力计算
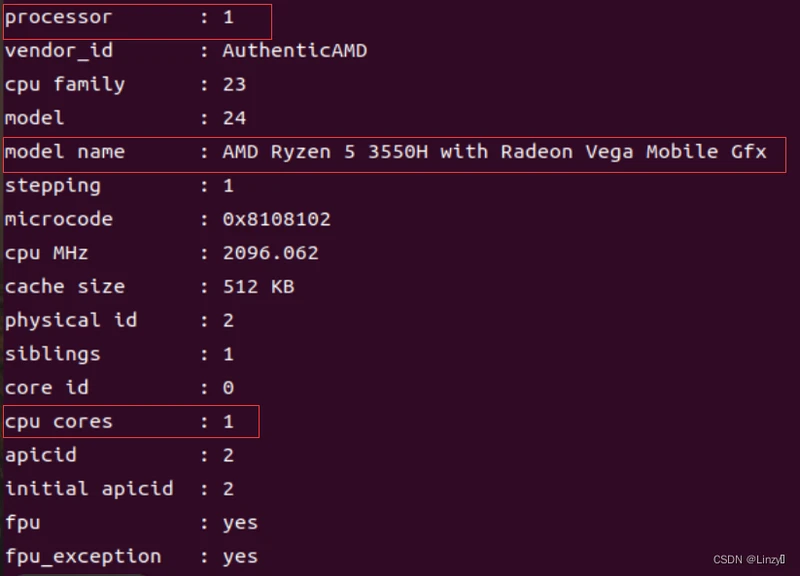
①Linux下查看cpu信息:
linux的cpu信息可以从文件中cpuinfo读取
输入命令:cat /proc/cpuinfo

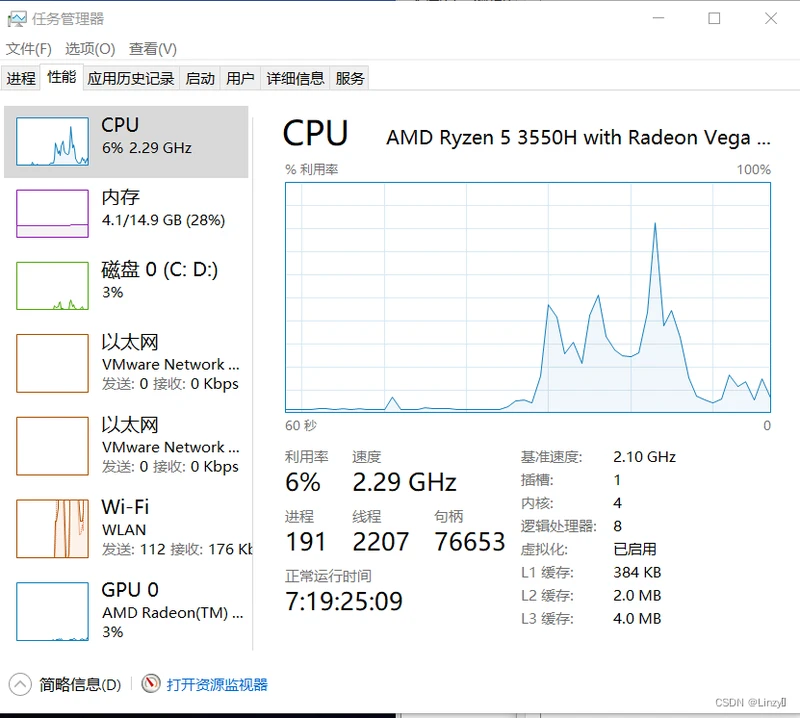
②主机的任务管理器上查询
③虚拟机设置上直接查询
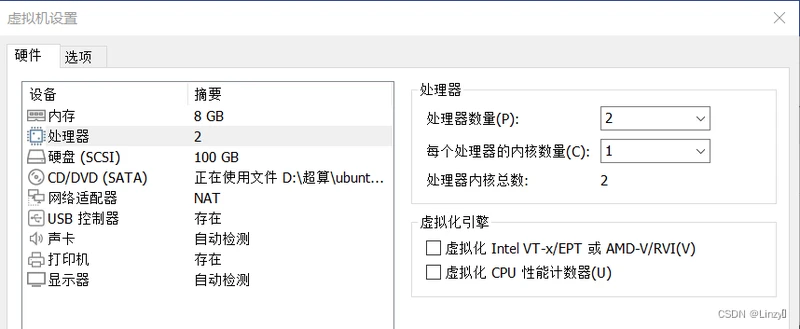
- cpu核数:由上述cpu参数表可知,该虚拟机和CPU核数为2【=1+1(processor从0开始数)】,而cup cores指的是这台机器的每个cpu有1个核心,故所有cpu数为2/1=2
- cpu主频:值得注意的是我们计算的cpu主频并非上述的cpu Mhz(当前的时钟频率,将之与最大的时钟频率比较,可以用来观察cpu是否处在节能状态),而是处在model name 后的Ghz,也是最大的时钟频率(奇怪的是我没法显示,可能是版本过低 ̄へ ̄)。但可以从任务管理器上查到2.1GHz
- CPU每周期执行浮点运算的次数:根据model name上网查(不确定查得对不对)–>结果为16(Intel一般为16,amd一般为8)
综上,理论FLOPS=2乘2.1乘16=67.2
2、实际浮点峰值
参考文章:HPL测试 、 HPL环境安装、配置及初步优化方案(报告)_hpl环境搭建_Yancygao的博客、使用HPL软件测试服务器浮点数计算性能
实验目的:根据调解HPL.dat的参数,测出实际浮点峰值
更改参数:
由于只有前面的N, NB, P 和 Q 对结果影响较大,特别是 N 值影响最大。所以在这里只讨论这4个参数,而其余的采用HPL官方文档的推荐设置(参考文章内有)。
- 问题规模N的值(可理解为系数矩阵的大小):①用物理内存的容量(单位:byte)乘以80%~85%来进行HPL的运算②再处以8,将结果开平方,得到的值比较接近最佳N值。简而言之,就是根据NN8=内存容量*80%计算–>结果:28753
- NB值(可理解每个分块大小):NBx8一定是Cache line的倍数,该虚拟机Cache line的大小为64(一般也都为64)详情 参考:关于CPU Cache和Cache Line。–>这里取64、128、192、256进行讨论

- 二维处理器网格(P × Q):①P × Q = 系统CPU数 = 进程数 = 2 ②一般来说,P的值尽量取得小一点–>故选P为1,Q为2
运行程序:
- 多进程运行命令:mpirun -np 线程数 ./可执行文件,-np参数值是服务器的CPU总核心数。对应着参数文件种 P * Q 的值。要求 -np 参数的值 >= P * Q,否则程序报错。如上,:2个进程运行xhpl,指令为 mpirun -np 2 ./xhpl
数据读取:
- 设置不同的参数来让HPL程序运行多次,取其最高值(峰值)作为服务的FLOPS计算性能
- 程序第一个运行种CPU刚唤醒,导致其有效计算所占的比例要小些,其结果会差些,特别是N值设置不够大时更明显
结果如下:
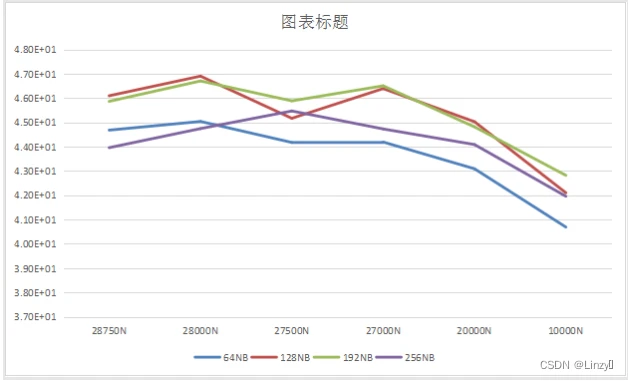
最佳N值和NB值:28000、192
最佳HPL效率为:46.9/67.2=69.79%
分析结果:
- N过大:理论来说,N设置越大,有效计算所占的比例也越大,其结果FLOPS值越大。但由于以下两点,N值存在限制:
①内存消耗大,而计算机物理内存有限。这也是为什么上图中,当N值过大时,测试性能反而下降的原因
②计算时间过长,感觉很费时间 - NB过大:由于每个线程计算量不相等,造成负载不平衡,会使得有些线程先执行完,有些后执行完,造成某些CPU核空闲,影响程序性能
NB过小:通信开销就会很大
所以,这里存在负载和通信开销的权衡问题