
CVPR2022
背景
本文提出,目标检测中,教师和学生的特征在不同的区域有很大的差异,特别是在前景和背景(这种比例的不均匀会影响检测的结果,论文挑了论文做实验,验证前景和背景一起蒸馏的效果是最差的)。
大多数蒸馏应用于分类,导致蒸馏在目标检测领域进步较小一点。
创新点
(1)教师网络和学生网络关注的像素和通道是不同的,做好这个区分,再进行训练会对结果产生影响。
(2)局部蒸馏和全局蒸馏,使学生不仅关注教师的关键像素和通道,同时关注学习像素间的关系。局部蒸馏分离前景和背景,迫使学生关注老师的关键像素和通道。全局蒸馏重建了不同像素间的关系,将教师传递给学生,弥补了局部蒸馏中缺失的全局信息。
模型原理
局部蒸馏(Focal Distillation)
作用:解决前景背景不平衡问题,使学生网络关注教师网络的关键像素和通道。
机制:
(1)二进制掩码M分离背景和前景。
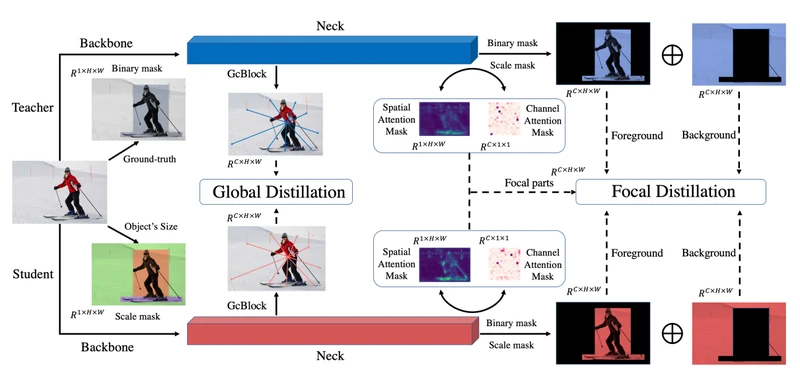
(2)尺度掩码(scale mask)平衡前景和背景比例。
(3)空间注意力和通道注意力帮助学生网络选择像素及通道来提升模型性能。
全局蒸馏 (Global Distillation)
作用:提取不同像素之间的全局关系。
源码分析
局部损失
学生和老师的特征经过注意力机制分别得到S_attention_s(空间注意力)[12, 16, 16],C_attention_s(通道注意力)[12, 1024];S_attention_t, C_attention_t。通过这四项计算损失。
空间注意力
假设输入FGD模块的张量为[12, 1024, 16, 16],通道维度上取平均[12, 16, 16],➗0.5后重塑[12, 256]按行softmax再✖256,再重塑回到[12, 16, 16]。
通道注意力
在后两个维度上取平均[12, 1024],➗0.5后按行softmax再✖1024得到[12, 1024]。
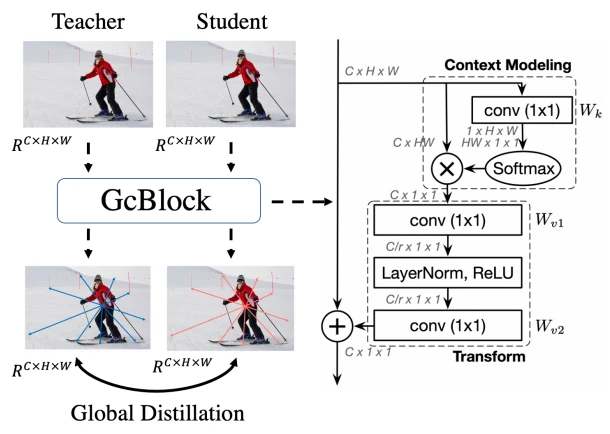
全局损失
学生老师网络产生的中间向量假设为A0[12, 512, 32, 32],重塑为A1[12, 1, 512, 1024] ,经全连接层[12, 1, 1024]经softmax后重塑[12, 1, 1024, 1],与A1相乘的最终得A2[12, 512, 1, 1]。A0与A2相加得到A,学生的A与老师的A共同作为均方损失的输入。