
一、摘要
作者认为现有的研究关系的方法大多是单个视觉区域和单词之间的模型关系,不足以正确回答问题。因为从人类的角度来看,回答视觉问题需要理解视觉和语言信息的总结。在这篇论文中,作者提出了用于视觉问答的多模态潜在交互网络模型(MLI)来解决这个问题。该模型学习潜在视觉和语言摘要之间的交叉模式关系,将视觉区域和问题归纳为少量的潜在表示,从而避免建模无信息单个视觉-问题关系。潜在摘要之间的跨模态信息被传播以融合来自两种模式的有价值信息,并用于更新视觉和问题特征。这类MLI模块可以分为几个阶段来模拟这两种模式之间的复杂和潜在的关系。
二、简介
MLI模块首先将问题和图像特征编码成少量的潜在视觉和问题摘要向量。每个摘要向量都可以表示为视觉或文字特征的加权合并,它从全局的角度总结了每个模式的某些方面,从而编码了比单个单词和区域特征更丰富的信息。在获得每个模态的概要向量之后,我们便在多模态摘要向量之间建立视觉语言关联,提出在摘要向量之间传播信息以对语言和视觉之间的复杂关系进行建模。每个原始视觉区域和单词特征将最终聚集来自更新过的潜在总结的信息,然后使用注意力机制和残差连接来预测正确答案。
三、多模态潜在交互网络模型
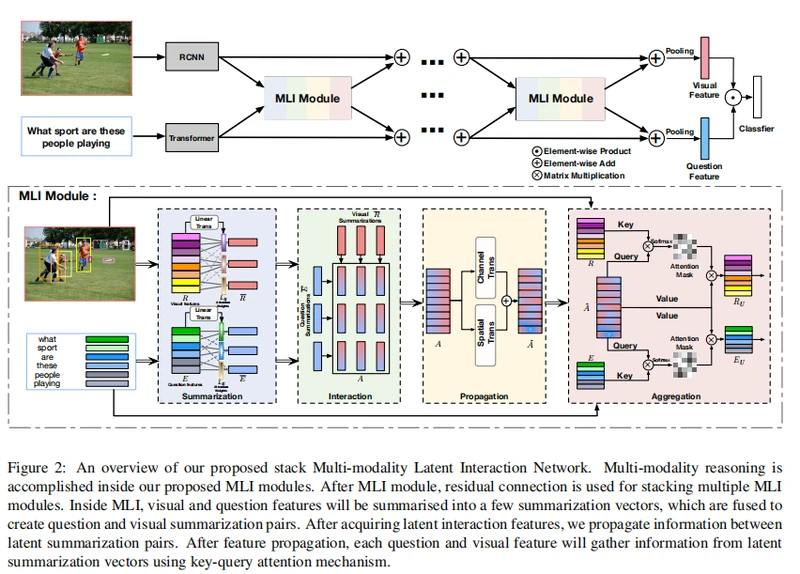
上图给出了MLIN模型,该模型由很多MLI模型堆叠而成,这样做的目的是为每个模态把输入的视觉区域信息和问题单词信息概括为少量的潜在概括向量。其核心思想是将视觉信息和语言信息传播到潜在的总结向量中,从全局的角度对复杂的跨模态交互进行建模。在潜在交互总结向量之间的信息传播之后,视觉区域和单词特征聚合来自跨模态摘要的信息,以更新它们的特征。在最后阶段,我们对视觉区域和问句的平均特征进行元素乘法,以预测最终答案。
3.1Question and Visual Feature Encoding
我们使用Faster RCNN目标检测器从图像I中提取视觉区域特征,每张图片编码M个视觉区域特征,表示为![]() 。而句子将被填充到最大长度14,并由双向transformer进行随机初始化编码,表示为
。而句子将被填充到最大长度14,并由双向transformer进行随机初始化编码,表示为![]() 。多模态特征编码可以表述为:
。多模态特征编码可以表述为:
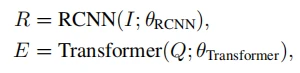
3.2. Modality Summarizations in MLI Module
在获取视觉特征和问题特征后,添加了一个轻量级的神经网络,为每个模态生成k组潜在的视觉或语言概要向量,首先生成k组线性组合权重。
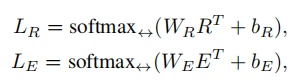
在这里 并且
并且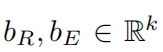 ,它们是每个模态可学习的k组变换权重。
,它们是每个模态可学习的k组变换权重。
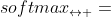 表示沿水平维度的softmax操作,这里用水平的原因我想可能是
表示沿水平维度的softmax操作,这里用水平的原因我想可能是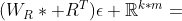 ,共有k行m列,沿水平方向进行softmax操作,共执行k词,每一次操作包含m个区域的信息,实现不同区域的交互,softmax函数的返回结果和输入的tensor有相同的shape。
,共有k行m列,沿水平方向进行softmax操作,共执行k词,每一次操作包含m个区域的信息,实现不同区域的交互,softmax函数的返回结果和输入的tensor有相同的shape。
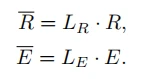
此时的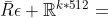 ,
,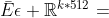 ,经过以上操作,我们为每个模态概要了k个概要特征。
,经过以上操作,我们为每个模态概要了k个概要特征。
k个潜在的视觉或语言摘要向量中的每一个(即R或E的每一行)都是输入单个特征的线性组合,每个模式中的k个摘要向量可以从全局角度捕捉输入特征的k个不同方面信息。
3.3. Relational Learning on Multi-modality Latent Summarizations
1.Relational Latent Summarizations.
该模块对应图中的interaction部分。
利用一个关系学习网络来建立跨模态的关联。我们从上述引入的k个潜在总结向量中创建k×k潜在视觉问题特征对。这种k*k对可以表示为3D关系张量![]() :
:
![]() (省略了转置符号)
(省略了转置符号)
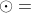 表示对应元素相乘,结果是1*512维的,然后用WA乘,得到512*1的向量。
表示对应元素相乘,结果是1*512维的,然后用WA乘,得到512*1的向量。
2.Relational Modeling and Propagation