
前言
因为对框架源码的生疏,笔者最近在看博文视点的陈昊的《Laravel框架关键技术解析》。
看到书中反复提及的管道处理,写下一些自己的所思所想。
书中一直在描述Laravel框架如何优雅,例如在第6章<Laravel框架中的设计模式>中写这个管道处理使用了装饰器模式,很elegant;在第7章<请求到响应的生命周期>又把装饰器模式提一遍,说中间件&请求是怎么用这个管道处理的。
书写得没错,但我读完之后却有种“马后炮”的感觉,因为我觉得书里面没有阐述明白这个Pipeline解决了什么问题?底层的代码总是为解决某一类问题而设计出来的。
"洋葱"模型是什么?
"洋葱"一词的来源
如果只读Laravel的使用文档,是没有关于洋葱模型的描述的。"洋葱"一词出自/vendor/laravel/framework/src/Illuminate/Pipeline/Pipeline.php
我们可以在 prepareDestination(Closure $destination) 看到这样的注释——
Get the final piece of the Closure onion. 译:获取闭包洋葱的最后一瓣。
在 carry() 看到这样的注释——
Get a Closure that represents a slice of the application onion. 译:获取应用洋葱的一瓣。(一瓣既一个闭包函数)
在Laravel框架中,很多注释和代码名称已经非常形象地表达了程序代码的功能,代码注释中将中间件称为“洋葱”层,将整个处理流程称为“管道”。
观察"洋葱"
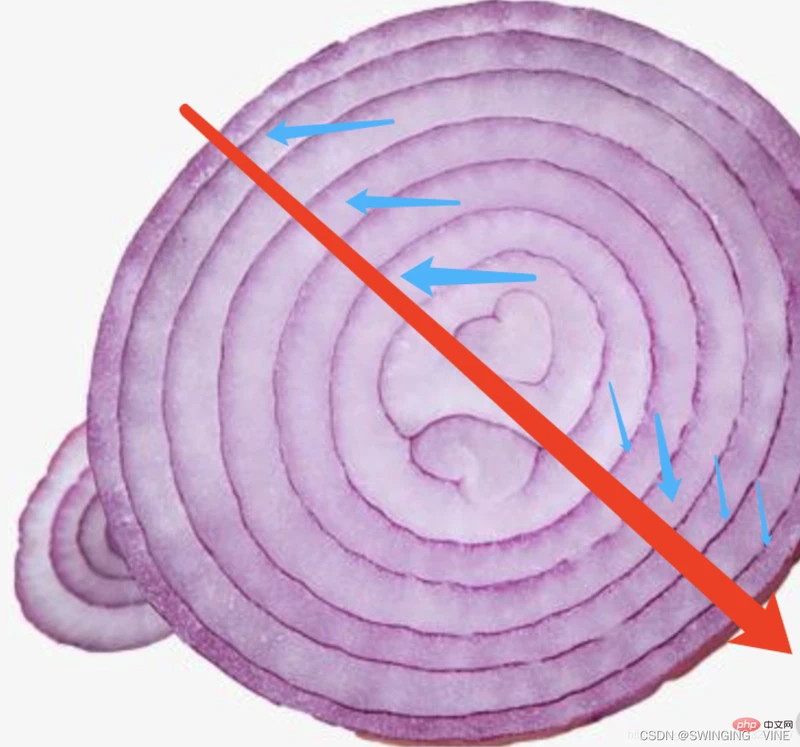
"洋葱"可以近似看作同心圆
在最外层的圆的任意一点向圆心画一条直线,这条直线会依次经过外层圆>内层圆>圆心>内层圆(对侧)>外层圆(对侧)
我们对这类型的业务需求用到的数据结构称之为洋葱模型。
计算机中使用了洋葱模型的设计
①js事件流(事件捕获与冒泡)
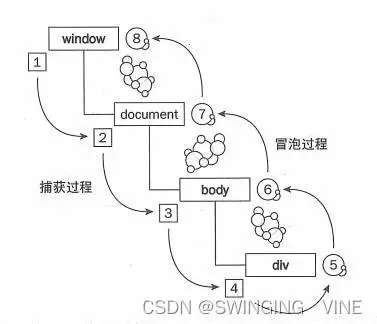
window事件捕获 > document事件捕获 > body事件捕获 > div事件捕获 > 事件处理 > 冒泡至div > 冒泡至body > 冒泡至document > 冒泡至window
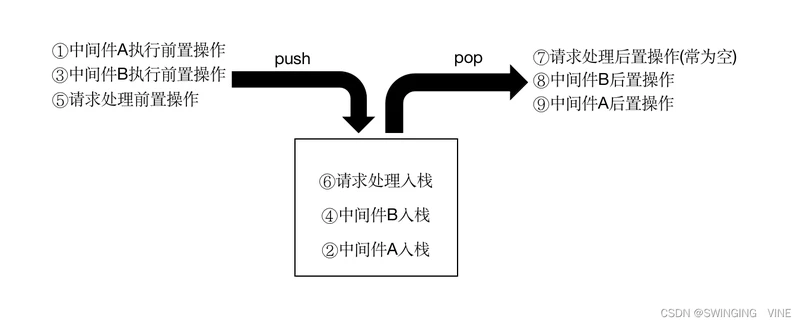
②后端web框架中间件
中间件A前置操作 > 中间件B前置操作 > 请求处理 > 中间件B后置操作 > 中间件A后置操作
描述”洋葱“
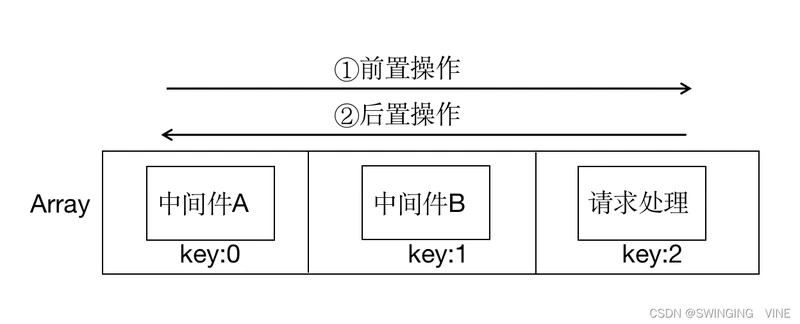
”洋葱“毕竟是是个比喻,如果用计算机术语描述,我倾向于使用栈来表示。
以中间件为例
或者用一个特殊的数组(管道,特点:来回地遍历)这样表示
动手写一个洋葱模型
有了图之后,我们就可以动手敲代码啦
首先先造个洋葱
<?php
//php7.4
/**
* 洋葱瓣
*/
interface Slice
{
function pre_do(); //前置操作
function suf_do(); //后置操作
}
/**
* 洋葱
*/
class Onion
{
//栈
private array $stack = [];
//入栈
public function send(Slice $slice)
{
array_push($this->stack, $slice);
}
public function handle()
{
array_map(function ($slice) {
$slice->pre_do();
}, $this->stack);
$reverseStack = array_reverse($this->stack);
array_map(function ($slice) {
$slice->suf_do();
}, $reverseStack);
}
}然后我们来造些”中间件“ 看看效果
/**
* 中间件A
*/
class MiddlewareA implements Slice
{
public function pre_do()
{
var_dump("MiddlewareA 前置操作");
}
public function suf_do()
{
var_dump("MiddlewareA 后置操作");
}
}
/**
* 中间件B
*/
class MiddlewareB implements Slice
{
public function pre_do()
{
var_dump("MiddlewareB 前置操作");
}
public function suf_do()
{
var_dump("MiddlewareB 后置操作");
}
}
/**
* 请求处理
*/
class HandleRequest implements Slice
{
public function pre_do()
{
var_dump("处理请求");
}
public function suf_do()
{
//do nothing
}
}
//主逻辑
$onion = new Onion();
$onion->send(new MiddlewareA);
$onion->send(new MiddlewareB);
$onion->send(new HandleRequest);
$onion->handle();执行结果如下

初步来说,实现需求了,但写得不优雅。那我们接下来一步一步优化我们的代码。
代码优化
何谓优雅?
优化代码的前提是知道哪里写得不好。
对比Laravel的Pipeline,我有如下启发
1.口语化(将英语中的实词给提取出来了)
我们来读一下下面这段代码
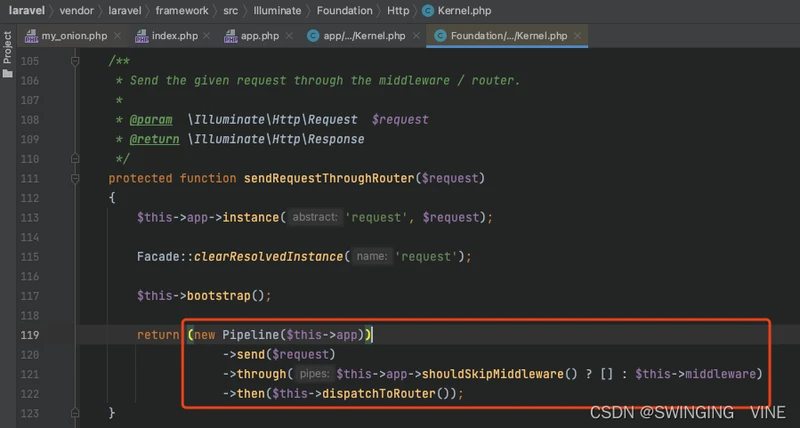
这段代码十分彰显面向对象功底。抽象得恰到好处,将用到的数据结构、相应的行为描述清楚了。
看着这段代码我们会很自然脑补出下述句子
I'd like to send the request through the middlewares pipeline, then dispatch it to router.
将请求通过中间件管道,然后发送给路由器。
将XX通过XXX管道,然后XXX。
2.then() 圆心而不是圆形
前面我们提到了同心圆的例子,圆心是一个点,而不是圆形。给同心圆绘制任一直径所在的直线,我们会说“直线经过了圆心”不会说“直线先经过了圆心的左侧,再经过了圆心的右侧”这样怪异的表达方式
上文中自己写的洋葱模型的代码中,实现上有点投机取巧——将HandleRequest拆成了前置操作和后置操作并且使后置操作为空
代码执行顺序就会变成
MiddlewareA前置操作>MiddlewareB前置操作>处理请求前置操作>处理请求后置操作(空操作)>MiddlewareB后置操作>MiddlewareA后置操作
原本只有一步的”处理请求“就被拆成了两步
3.递归而不是遍历
我觉得这个点是可以快速提升代码逼格的。递归肯定比遍历要更耗费脑细胞,因为递归需要思考延续性,而且很多时候需要额外去思考递归的终点。
站在巨人的肩膀上构思
我们沿着Laravel给的“骨架” Illuminate\Contracts\Pipeline\Pipeline.php管道接口,结合上述几点思考来一步一步丰富这个“洋葱”模型。
遍历变成递归
数组的递归函数,我的第一反应是PHP的array_reduce()函数

这有什么难的嘛,不就是把用array_map()的地方变成array_reduce()嘛
麻溜的,我写出了下面的代码
public function handle()
{
// array_map(function ($slice) {
// $slice->pre_do();
// }, $this->stack);
//
// $reverseStack = array_reverse($this->stack);
//
// array_map(function ($slice) {
// $slice->suf_do();
// }, $reverseStack);
array_reduce($this->stack, function ($carry, $item) {
$item->pre_do();
});
$reverseStack = array_reverse($this->stack);
array_reduce($reverseStack, function ($carry, $item) {
$item->suf_do();
});
}真就换了个函数而已「汗」「汗」「汗」,可以说跟递归没有任何关系,闭包函数的$carry根本没用上啊!!!!
重新审视“洋葱”模型里的递归
递归两大要素:①延续性,既可以递推;②终止递归的条件
延续性:每一层洋葱瓣只需要关心这一层的前置操作是什么,后置操作是什么,不需要关心外层和内层洋葱瓣做了什么。每一层都实现Closure($passable)即可让$passable往下传递。
终止递归的条件:抵达“圆心”
于是就有了使用手册中的《基础功能>中间件》的handle定义
public function handle($request, Closure $next)
{
// 前置操作
$response = $next($request); //处理请求,生成响应
// 后置操作
return $response;
}