
1. 分布式事务概述
1.1 什么是事务
事务是指由一组操作组成的一个工作单元,这个工作单元具有原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability),这就是事务的ACID特性。
原子性:执行单元中的操作要么全部执行成功,要么全部失败。如果有一部分成功一部分失败那么成功的操作要全部回滚到执行前的状态。
一致性:执行一次事务会使用数据从一个正确的状态转换到另一个正确的状态,执行前后数据都是完整的。
隔离性:在该事务执行的过程中,任何数据的改变只存在于该事务之中,对外界没有影响,事务与事务之间是完全隔离的。只有事务提交后其它事务才可以查询到最新的数据。
持久性:事务完成后对数据的改变会永久性的存储起来,即使发生断电宕机数据依然在。
1.2 什么是本地事务
本地事务就是用关系型数据库来控制事务,关系数据库通常都具有ACID特性。传统的单体应用通常会将数据全部存储在一个数据库中,会借助关系型数据库来完成事务控制。
1.3 什么是分布式事务
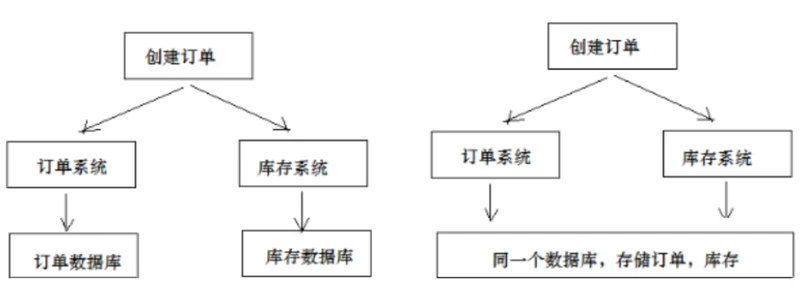
在分布式系统中一次操作由多个系统协同完成,这种一次事务操作涉及多个系统通过网络协同完成的过程称为分布 式事务。例如电商项目中用户下单,此时就需要订单系统和库存系统协同来完成整个下单操作,即首先调用订单系统添加订单,然后调用库存系统扣减库存。
这里强调的是多个系统通过网络协同完成一个事务的过程,并不强调多个系统访问了不同的数据库,即使多个系统访问的是同一个数据库也是分布式事务。 如下图两种形式都属于分布式事务:
1.4 CAP理论
如何保证分布式事务?CAP理论是分布式事务处理的理论基础,了解了CAP理论有助于我们研究分布式事务的处理 方案。 CAP理论是:分布式系统在设计时只能在一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)中满足两种,无法兼顾三种。
通过下图理解CAP理论:
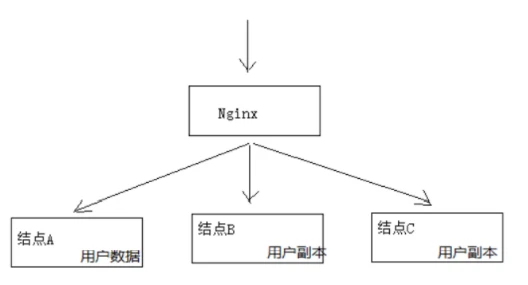
一致性(Consistency):服务A、B、C三个结点都存储了用户数据, 三个结点的数据需要保持同一时刻数据一致 性。
可用性(Availability):服务A、B、C三个结点,其中一个结点宕机不影响整个集群对外提供服务,如果只有服务A结 点,当服务A宕机整个系统将无法提供服务,增加服务B、C是为了保证系统的可用性。
分区容忍性(Partition Tolerance):分布式系统不可避免的出现了多个系统通过网络协同工作的场景,节点之间难 免会出现网络中断、网延延迟等现象,这种现象一旦出现就导致数据被分散在不同的结点上,这就是网络分区。 当一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了,这时分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里,容忍性就提高了。总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
分布式系统能否兼顾C、A、P? 在保证分区容忍性的前提下一致性和可用性无法兼顾,如果要提高系统的可用性就要增加多个结点,如果要保证数据的一致性就要实现每个结点的数据一致,节点越多可用性越好,但是数据一致性越差。 所以,在进行分布式系统设计时,同时满足“一致性”、“可用性”和“分区容忍性”三者是几乎不可能的。
CAP有哪些组合方式?
1、CA:放弃分区容忍性,加强一致性和可用性,关系数据库按照CA进行设计。
2、AP:放弃一致性,加强可用性和分区容忍性,追求最终一致性,很多NoSQL数据库按照AP进行设计。 说明:这里放弃一致性是指放弃强一致性,强一致性就是写入成功立刻要查询出最新数据。追求最终一致性是指允许暂时的数据不一致,只要最终在用户接受的时间内数据一致即可。
3、CP:放弃可用性,加强一致性和分区容忍性,一些强一致性要求的系统按CP进行设计,比如跨行转账,一次转 账请求要等待双方银行系统都完成整个事务才算完成。 说明:由于网络问题的存在CP系统可能会出现待等待超时,如果没有处理超时问题则整理系统会出现阻塞。
总结: 在分布式系统设计中AP的应用较多,即保证分区容忍性和可用性,牺牲数据的强一致性(写操作后立刻读取到最 新数据),保证数据最终一致性。比如:订单退款,今日退款成功,明日账户到账,只要在预定的用户可以接受的时间内退款事务走完即可。
1.5 解决方案
1.5.1 两阶段提交协议(2PC)
为解决分布式系统的数据一致性问题出现了两阶段提交协议(2 Phase Commitment Protocol),两阶段提交由 协调者和参与者组成,共经过两个阶段和三个操作,部分关系数据库如Oracle、MySQL支持两阶段提交协议,本节讲解关系数据库两阶段提交协议。
2PC协议流程图:

第一阶段:准备阶段(prepare) 协调者通知参与者准备提交订单,参与者开始投票。 参与者完成准备工作向协调者回应Yes。
第二阶段:提交(commit)/回滚(rollback)阶段 协调者根据参与者的投票结果发起最终的提交指令。 如果有参与者没有准备好则发起回滚指令。
下图是一个下单减库存的例子:
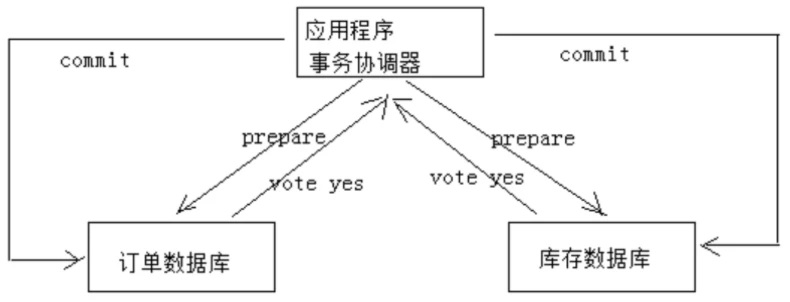
1、应用程序连接两个数据源。
2、应用程序通过事务协调器向两个库发起prepare,两个数据数据库收到消息分别执行本地事务(记录日志),但不提交,如果执行成功则回复yes,否则回复no。
3、事务协调器收到回复,只要有一方回复no则分别向参与者发起回滚事务,参与者开始回滚事务。
4、事务协调器收到回复,全部回复yes,此时向参与者发起提交事务。如果参与者有一方提交事务失败则由事务协调器发起回滚事务。
优点:实现强一致性,部分关系数据库支持(Oracle、MySQL等)。
缺点:整个事务的执行需要由协调者在多个节点之间去协调,增加了事务的执行时间,性能低下。
解决方案有:springboot+Atomikos or Bitronix
1.5.2 事务补偿(TCC)
TCC事务补偿是基于2PC实现的业务层事务控制方案,它是Try、Confirm和Cancel三个单词的首字母,含义如下:
1、Try 检查及预留业务资源,完成提交事务前的检查,并预留好资源。
2、Confirm 确定执行业务操作,对try阶段预留的资源正式执行。
3、Cancel 取消执行业务操作,对try阶段预留的资源释放。
下面用一个下单减库存的业务为例来说明:
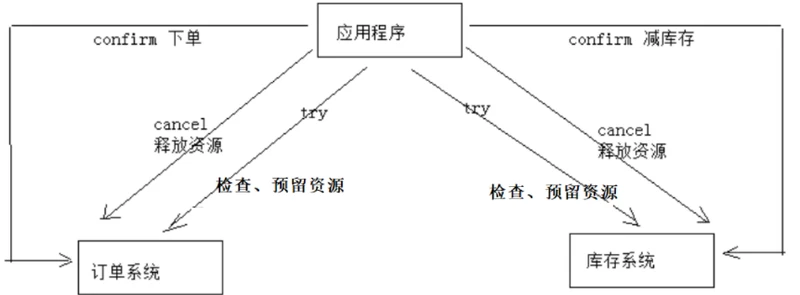
1、Try 下单业务由订单服务和库存服务协同完成,在try阶段订单服务和库存服务完成检查和预留资源。 订单服务检查当前是否满足提交订单的条件(比如:当前存在未完成订单的不允许提交新订单)。 库存服务检查当前是否有充足的库存,并锁定资源。
2、Confirm 订单服务和库存服务成功完成Try后开始正式执行资源操作。 订单服务向订单写一条订单信息。 库存服务减去库存。
3、Cancel 如果订单服务和库存服务有一方出现失败则全部取消操作。 订单服务需要删除新增的订单信息。 库存服务将减去的库存再还原。
优点:最终保证数据的一致性,在业务层实现事务控制,灵活性好。
缺点:开发成本高,每个事务操作每个参与者都需要实现try/confirm/cancel三个接口。
注意:TCC的try/confirm/cancel接口都要实现幂等性,因为在try、confirm、cancel失败后要不断重试。
什么是幂等性?
幂等性是指同一个操作无论请求多少次,其结果都相同。
实现方式有:
1、操作之前在业务方法进行判断如果执行过了就不再执行。
2、缓存所有请求和处理的结果,已经处理的请求则直接返回结果。
3、在数据库表中加一个状态字段(未处理,已处理),数据操作时判断未处理时再处理。
1.5.3 消息队列实现最终一致性
本方案是将分布式事务拆分成多个本地事务来完成,并且由消息队列异步协调完成。 下边以下单减少库存为例来说明:
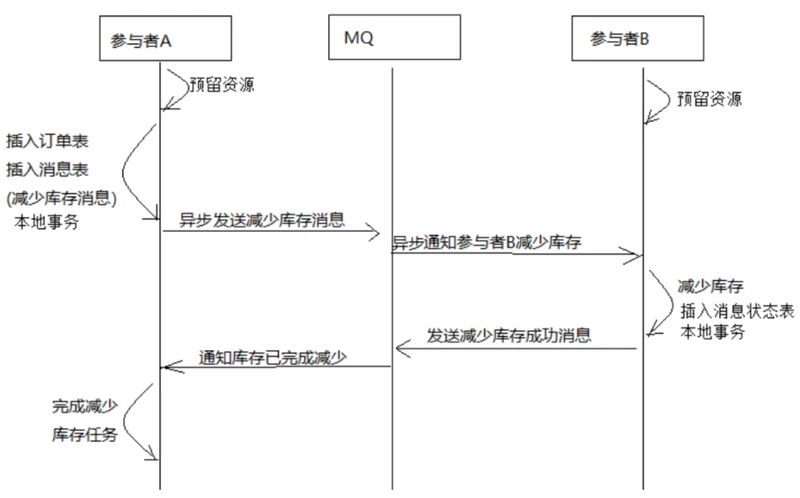
1、订单服务和库存服务完成检查和预留资源。
2、订单服务在本地事务中完成添加订单表记录和添加“减少库存任务消息”。
3、由定时任务根据消息表的记录发送给MQ通知库存服务执行减库存操作。
4、库存服务执行减少库存,并且记录执行消息状态(为避免重复执行消息,在执行减库存之前查询是否执行过此 消息)。
5、库存服务向MQ发送完成减少库存的消息。
6、订单服务接收到完成库存减少的消息后删除原来添加的“减少库存任务消息”。
实现最终事务一致性要求:预留资源成功理论上要求正式执行成功,如果执行失败会进行重试,要求业务执行方法实现幂等。
优点 : 由MQ按异步的方式协调完成事务,性能较高。 不用实现try/confirm/cancel接口,开发成本比TCC低。
缺点: 此种方式基于关系数据库本地事务来实现,会出现频繁读写数据库记录,浪费数据库资源,另外对于高并发操作不是最佳方案。
2. 分布式事务解决方案Seata
2.1 介绍
Seata是阿里巴巴2019年开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。在Seata开源之前,Seata对应的内部版本在阿里内部一直扮演着分布式一致性中间件的角色,帮助阿里度过历年的双11,对各业务进行了有力的支撑。
github地址:https://github.com/seata/seata
Seata服务下载地址:https://github.com/seata/seata/releases
maven依赖:
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.4.0</version>
</dependency>
2.2 组成部分
分布式事务是由一批分支事务组成的全局事务,通常分支事务只是本地事务。
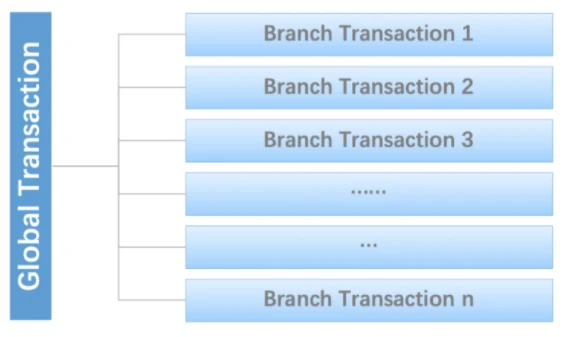
Seata有3个基本组成部分:
- 事务协调器(TC,Transaction Coordinator):维护全局事务和分支事务的状态,驱动全局提交或回滚
- 事务管理器(TM,Transaction Manager):定义全局事务的范围:开始全局事务,提交或回滚全局事务
- 资源管理器(RM,Resource Manager):管理正在处理的分支事务的资源,与TC对话以注册分支事务并报告分支事务的状态,并驱动分支事务的提交或回滚
2.3 生命周期
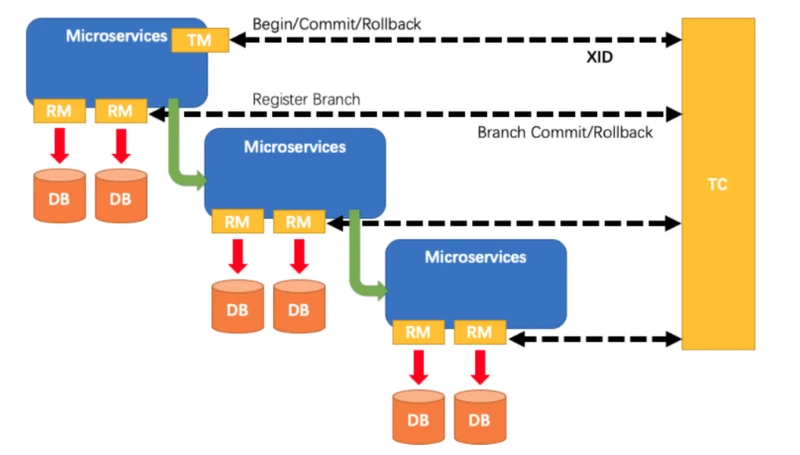
Seata管理的分布式事务的典型生命周期:
- TM要求TC开始一项新的全局事务。TC生成代表全局事务的XID。
- XID通过微服务的调用链传播。
- RM将本地事务注册为XID到TC的相应全局事务的分支。
- TM要求TC提交或回退相应的XID全局事务。
- TC驱动XID的相应全局事务下的所有分支事务以完成分支提交或回滚。
2.4 应用
以客户下单业务逻辑为例,整个业务逻辑需要如下服务支持:
1、建立数据库
新增数据库seata,并导入表:
-- the table to store GlobalSession data
drop table if exists `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) DEFAULT NULL,
`transaction_service_group` varchar(32) DEFAULT NULL,
`transaction_name` varchar(128) DEFAULT NULL,
`timeout` int(11) DEFAULT NULL,
`begin_time` bigint(20) DEFAULT NULL,
`application_data` varchar(2000) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`xid`),
KEY `idx_gmt_modified_status` (`gmt_modified`,`status`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- the table to store BranchSession data
drop table if exists `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`resource_group_id` varchar(32) DEFAULT NULL,
`resource_id` varchar(256) DEFAULT NULL,
`lock_key` varchar(128) DEFAULT NULL,
`branch_type` varchar(8) DEFAULT NULL,
`status` tinyint(4) DEFAULT NULL,
`client_id` varchar(64) DEFAULT NULL,
`application_data` varchar(2000) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- the table to store lock data
drop table if exists `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) NOT NULL,
`xid` varchar(96) DEFAULT NULL,
`transaction_id` mediumtext,
`branch_id` mediumtext,
`resource_id` varchar(256) DEFAULT NULL,
`table_name` varchar(32) DEFAULT NULL,
`pk` varchar(36) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`row_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在业务数据库中添加undo_log表,当前场景需在订单服务数据库(pd_oms)、作业服务数据库(pd_work)中分别创建undo_log表:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
2、启动Seata Server
docker run -d --name seata -p 8091:8091 seataio/seata-server:latest
3、修改registry.conf
本地创建registry.conf文件
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos" #注册中心使用nacos方式
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "68.79.63.42:8848"
group = "SEATA_GROUP"
namespace = "6107f553-3214-48d8-89c3-945f8446e3d9"
cluster = "default"
username = "nacos"
password = "nacos123"
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = 0
password = ""
cluster = "default"
timeout = 0
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file" #配置信息采用file方式
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
appId = "seata-server"
apolloMeta = "http://192.168.1.204:8801"
namespace = "application"
apolloAccesskeySecret = ""
}
zk {
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
复制到容器中
docker cp registry.conf seata:seata-server/resources/registry.conf
4、修改file.conf
本地创建file.conf文件
service {
vgroupMapping.test_tx_group = "default" # 当前值也需要在应用中添加 具体见 “7、增加seata配置” test_tx_group可修改
disableGlobalTransaction = false
}
## transaction log store, only used in seata-server
store {
## store mode: file、db、redis
mode = "db" # 使用数据库方式,需要修改db模块下的配置信息
## file store property
file {
## store location dir
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
maxBranchSessionSize = 16384
# globe session size , if exceeded throws exceptions
maxGlobalSessionSize = 512
# file buffer size , if exceeded allocate new buffer
fileWriteBufferCacheSize = 16384
# when recover batch read size
sessionReloadReadSize = 100
# async, sync
flushDiskMode = async
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://68.79.7.219:3306/seata"
user = "root"
password = "root"
minConn = 5
maxConn = 100
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
## redis store property
redis {
host = "127.0.0.1"
port = "6379"
password = ""
database = "0"
minConn = 1
maxConn = 10
maxTotal = 100
queryLimit = 100
}
}
复制到容器中
docker cp file.conf seata:seata-server/resources/file.conf
5、重启服务
docker restart seata
查看nacos中seata服务是否注册成功
6、引入seata依赖
在test-tms-java/pom.xml中锁定seata的依赖版本:
<!--在dependencyManagement标签中配置-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>
在pd-common/pom.xml中引入seata坐标和openfeign坐标:
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-core</artifactId>
</dependency>
由于pd-druid不需要seata,所以需要排除掉:
<dependency>
<groupId>com.test</groupId>
<artifactId>pd-common</artifactId>
<version>${pd-common.version}</version>
<exclusions>
<exclusion>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</exclusion>
<exclusion>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</exclusion>
<exclusion>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</exclusion>
<!--排除seata-->
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
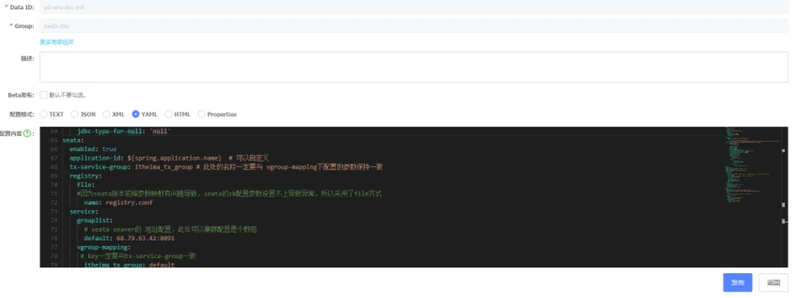
7、增加seata配置
在各个项目配置文件中增加seata配置
seata:
enabled: true
application-id: ${spring.application.name} # 可以自定义
tx-service-group: test_tx_group # 此处的名称一定要与 vgroup-mapping下配置的参数保持一致
registry:
file:
#因为seata版本驼峰参数映射有问题导致,seata的zk配置参数设置不上导致异常,所以采用了file方式
name: registry.conf
service:
grouplist:
# seata server的地址
default: 68.79.63.42:8091
vgroup-mapping:
# key一定要与tx-service-group一致
test_tx_group: default
8、增加过滤器
在pd-common中新增过滤器,用于把当前上下文中获取到的XID放到RootContext
package com.test.common.filter;
import io.seata.core.context.RootContext;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* 创建一个Http Rest请求过滤器,用于把当前上下文中获取到的XID放到RootContext
*/
@Component
@Slf4j
public class TxXidFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String xid = RootContext.getXID();
String txXid = request.getHeader("TX_XID");
boolean bind = false;
if (StringUtils.isBlank(xid) && StringUtils.isNotBlank(txXid)) {
RootContext.bind(txXid);
bind = true;
log.debug("绑定 [" + txXid + "] RootContext");
}
try {
filterChain.doFilter(request, response);
} finally {
if (bind) {
String unbindXid = RootContext.unbind();
log.debug("解绑 [" + unbindXid + "] RootContext");
if (!txXid.equalsIgnoreCase(unbindXid)) {
log.warn("变更 [" + txXid + "] ---> [" + unbindXid + "]");
if (unbindXid != null) {
RootContext.bind(unbindXid);
log.warn("绑定 [" + unbindXid + "] 回 RootContext");
}
}
}
}
}
}
9、增加拦截器
在pd-common中新增拦截器,把RootContext中的XID传递到调用链路
package com.test.common.interceptors;
import feign.RequestInterceptor;
import feign.RequestTemplate;
import io.seata.core.context.RootContext;
import org.apache.commons.lang.StringUtils;
import org.springframework.stereotype.Component;
/**
* 创建一个Feign拦截器,把RootContext中的XID(XID用于标识一个局部事务属于哪个全局事务,需要在调用链路的上下文中传递)传递到调用链路
*/
@Component
public class RequestHeaderInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
String xid = RootContext.getXID();
if (StringUtils.isNotBlank(xid)) {
template.header("TX_XID", xid);
}
}
}
10、取消过滤器注册
由于pd-druid中不需要使用seata,所以需要将上面的过滤器取消掉
package com.test.config;
import com.test.pinda.common.filter.TxXidFilter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class ApacheDruid {
@Bean
public FilterRegistrationBean cancelMyFilterRegistration(TxXidFilter filter) {
log.info(">>>>>>>>>>> 取消TxXidFilter 注册");
FilterRegistrationBean registration = new FilterRegistrationBean(filter);
registration.setEnabled(false);
return registration;
}
}
11、增加注解
在入口方法上增加@GlobalTransactional注解
com.test.controller.MailingController
/**
* 下单
*
* @param entity
* @return
*/
@ApiOperation("下单")
@PostMapping("")
@GlobalTransactional //增加分布式事务注解 (只增加一个即可)
public Result save(@RequestBody MailingSaveDTO entity) {
...
}