
不多说,直接上干货!
Weka的Explorer(探索者)界面,是Weka的主要图形化用户界面,其全部功能都可通过菜单选择或表单填写进行访问。本博客将详细介绍Weka探索者界面的图形化用户界面、预处理界面、分类界面、聚类界面、关联界面、选择属性界面和可视化界面等内容。
一、Weka的Explorer(探索者)界面里的图形化界面
启动Weka GUI选择器窗口之后,用鼠标单击窗口右部最上面的Explorer按钮,启动探索者界面,这时,由于没有加载数据集,除预处理面板外,其他面板都变灰而不可用, 可以使用Open file、Open URL、Open DB或者Generate按钮加载或产生数据集,加载数据集之后,其他面板才可以使用。
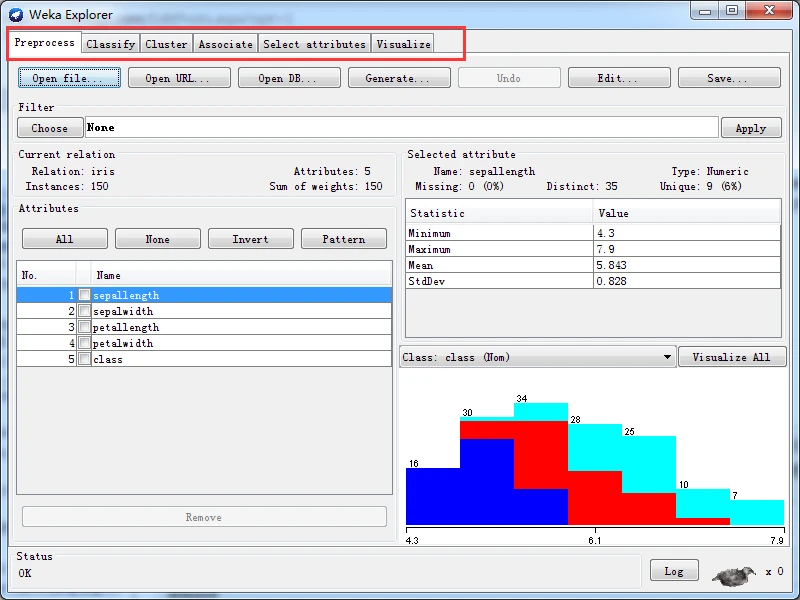
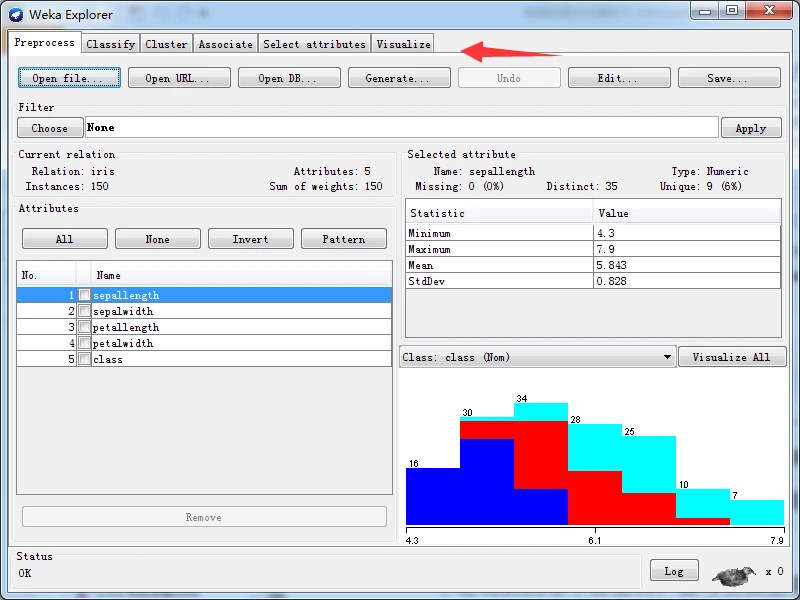
我这里以打开文件为例进行说明。单击左上部的Open file按钮,通过弹出的打开文件对话框,选择打开data子目录下的iris.arfT文件,加载数据集后的探索者界面如下图所示。

区域1的几个选项卡是用来切换不同的挖掘任务面板。这一节用到的只有“Preprocess”,其他面板的功能将在以后介绍。
区域2是一些常用按钮。包括打开数据,保存及编辑功能。
区域3中“Choose”某个“Filter”,可以实现筛选数据或者对数据进行某种变换。数据预处理主要就利用它来实现。
区域4展示了数据集的一些基本情况。
区域5中列出了数据集的所有属性。勾选一些属性并“Remove”就可以删除它们,删除后还可以利用区域2的“Undo”按钮找回。区域5上方的一排按钮是用来实现快速勾选的。
区域6中选中某个属性,则区域6中有关于这个属性的摘要。注意对于数值属性和分类属性,摘要的方式是不一样的。图中显示的是对数值属性“income”的摘要。
区域7是区域5中选中属性的直方图。若数据集的最后一个属性(我们说过这是分类或回归任务的默认目标变量)是分类变量(这里的“pep”正好是),直方图中的每个长方形就会按照该变量的比例分成不同颜色的段。要想换个分段的依据,在区域7上方的下拉框中选个不同的分类属性就可以了。下拉框里选上“No Class”或者一个数值属性会变成黑白的直方图。
区域8是状态栏,可以查看Log以判断是否有错。右边的weka鸟在动的话说明WEKA正在执行挖掘任务。右键点击状态栏还可以执行Java内存的垃圾回收。
1、标签页介绍
下图图所示界面的顶部有六个不同的标签页,代表六个不同的面板,分别对应Weka 听支持的多种数据挖掘方式。如果刚开始打开探索者界面,那么只有第一个预处理标签页可用,其余的标签文字全部变为灰色而不可用,这是因为必须先打开一个数据集,根据应用需要,或许还需要对数据进行预处理,才能使用其他面板。
这六个标签页的介绍如下。
(1) PreprocesS(预处理)。选择数据集,并以不同方式对其进行修改。
(2) Classify(分类)。训练用于分类或回归的学习方案,并对其进行评估。
(3) Cluster(聚类)。学习数据集聚类方案。
(4) Associate(关联)。学习数据关联规则,并对其进行评估。
(5) Select attributes(选择属性)。选择数据集中最相关的部分属性。
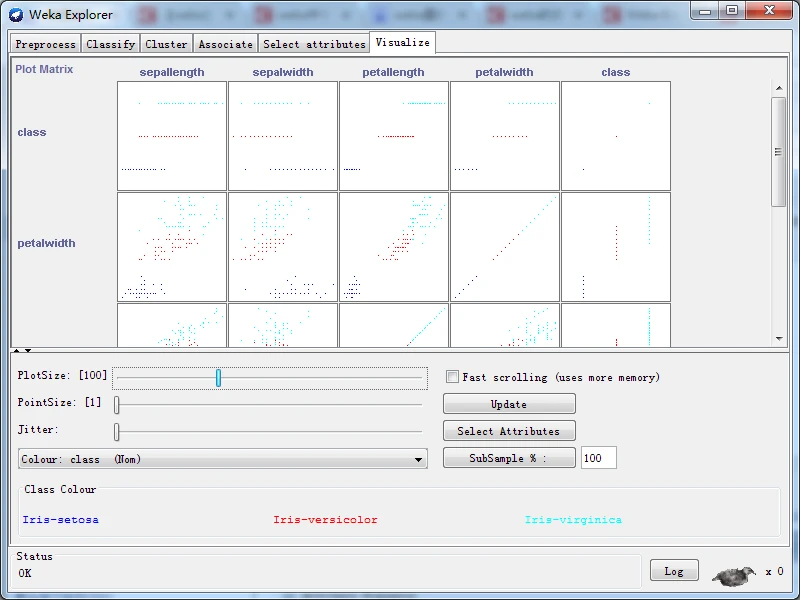
(6) Visualize(可视化)。查看不同二维数据散点图,并与其进行互动。
每个标签页都可完成不同工作,单击标签页上部文字即可实现标签切换。窗口底部包括状态(Status)栏、日志(Log)按钮和一只Weka鸟,这些都是一直保持可见,不论用户切换到哪一个标签页。
2、状态栏
状态栏位于窗口的最下部,显示ih用户了解现在正在进行到哪一步的状态信息。例如,如果探索者正在忙于加载数据文件,状态栏会显示相应的状态信息。
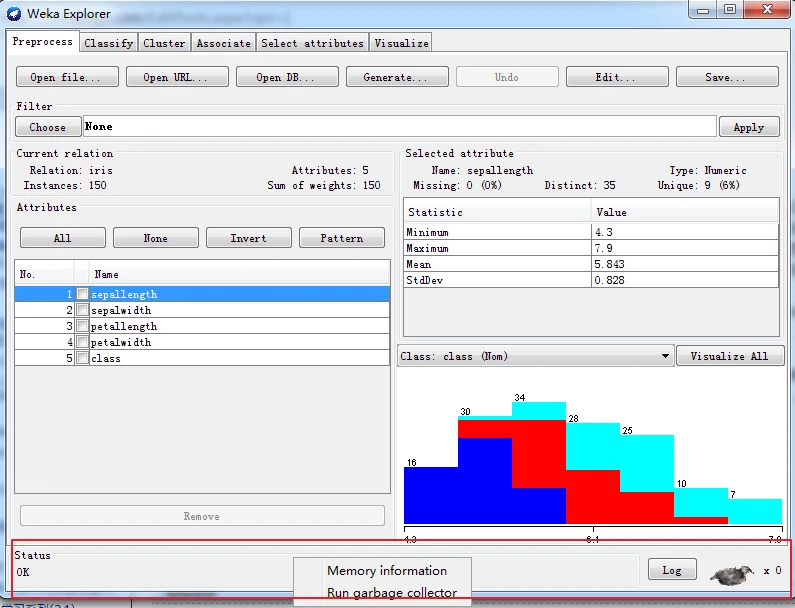
除了显示状态之外,还可以右击来显示内存信总,以及运行垃圾回收器以清理内存。 在状态栏的任意位罝右击,会弹出一个上下文菜单,菜单只包括两个菜单项——Memory information(内存信信息)和Run garbage collector(运行垃圾回收器),第一个菜单项显示Weka 当前可用的内存空间:第二个菜单项启动Java垃圾回收器,搜寻不再使用的内存并释放以回收部分内存空间,提供给新的任务使用。需要指出的是,垃圾回收器是一个不间断运行的后台任务,如果不强制进行垃圾回收,Java虚拟机也会在适当时候自动启动垃圾回收。
日志按钮位于状态栏的右面,单击该按钮会打开可以滚动的日志文本框,显示在此次 运行期间内Weka进行的全部活动以及每项活动的时间戳。不管是使用图形用户界面、命令行还是Simple CLI,日志都会包含分类、聚类、M性选择等操作的完整的设置字符串。 因此,用户可以进行复制和粘贴。顺便提醒大家,学习日志里记录的命令,可以深层次地了解Weka的内部运行机制。
曰志按钮的右边,可以#到称Weka状态图标的鸟。如果没有处理过程在运行,小鸟会坐下来打个盹。“X”符号旁边的数字显示目前有多少个正在进行处理的进程,当系 统空闲时,该数字为零,数字会随着正在进行处理进程数的增加而增加。当启动处理进程 时,小鸟会站起来不停走动。如果小鸟长时间站着不动,说明Weka出现运行错误,此时用户需要关闭并重新启动探索者界面。
3、 图像输出
Weka中显示的大部分图形,不论是通过 GraphVisualizer (图可视化器)或是TreeVisualizer(树可视化器)显示的,都可以保存为图像文件以备将来使用。保存方法是,按下Alt键和 Shift键的同时,在要保存的图形上单击,就可启动保存文件对话框。支持的的图像文件格式有 BMP、 JPEG、 PNG和 Postscript的 EPS,用户可以选择图像文件格式还可以修改输出图像文件的尺寸。
4、手把手教你用
4.1、启动Weka
从Windows左下角的“开始”菜单,依次选择“所有程序”,再找到Weka3.7.8菜单,启动它,如下图所示。
然后,单击窗口右部最上边的Explorer按钮启动Weka 探索者,如下图所示。
现在,除了Preprocess标签页可用外,其余标签页都是不可用的。
2、了解标签页
单击上图的Open file按钮,该按钮位于窗口的左上部。启动“打开”文件窗口,导航到Weka安装目录下的data子目录,选择iris.arff文件,我这里是选择在
D:\SoftWare\Weka-3-7\data。单击打开按钮,打开该文件,如下图所示。
打开文件(或称为加载数据)后的Weka探索者,界面如下如所示,可以看到,加载数据后,六个标签页都变为可用状态。
大家,可以自行去切换标签页,初步了解各个标签页的功能,为后续的学习打下基础。
3、了解状态栏
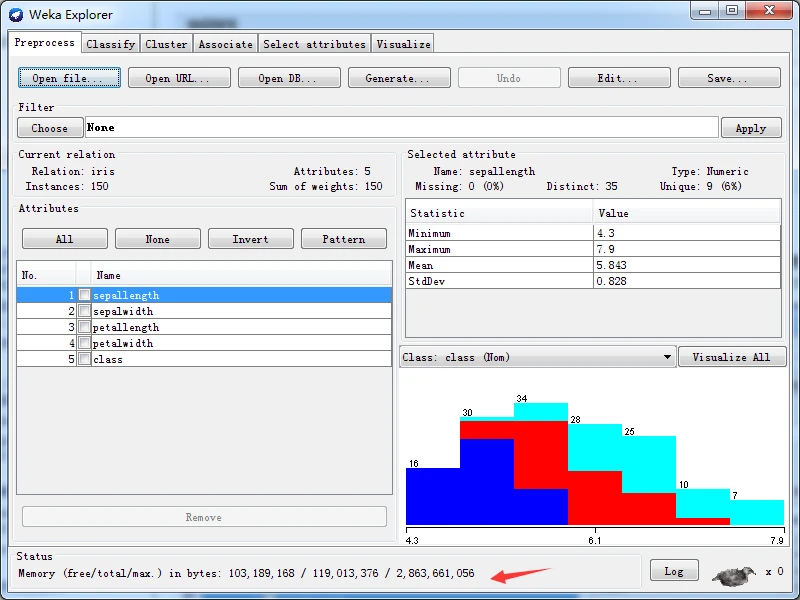
不论切换到哪个标签页,都可以在探索者窗口下部的状态栏查看到状态信息。在状态栏任意位置右击,在弹出的上下文菜单中选择第一项Memory information(内存信息),状态栏显示用斜杠分隔的内存信息,格式为:空闲内存/全部内存/最大内存,单位字节。如下图所示。
如果选择上下文菜单中的第二项Run garbage collector,状态栏会显示ok信息,表示已经启动了垃圾回收器。
单击状态栏右边的Log按钮,可以查看到当前日志。
4、保存图像文件
单击如下图所示的界面右边的Visualize All(全部可视化)按钮,打开如下图所示的全部可视化窗口。
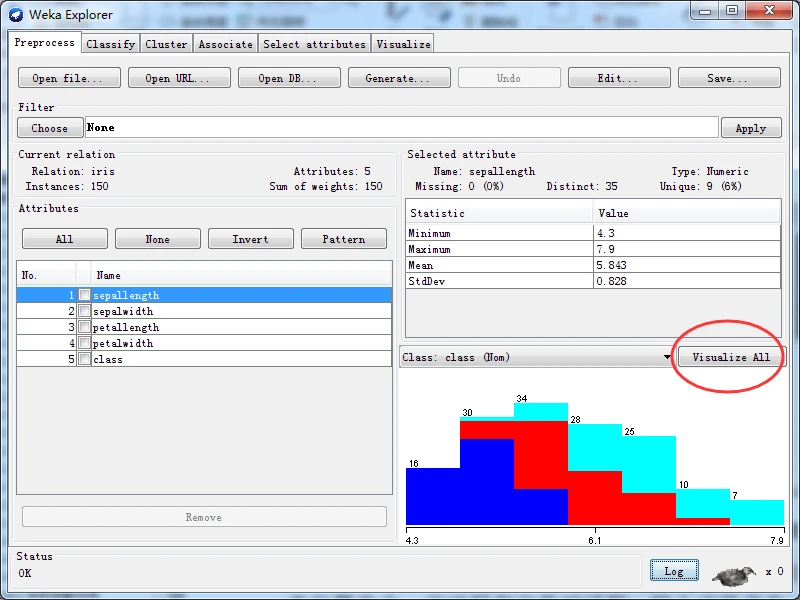

同时,按下Alt键 + Shift键,并在上图所示任选一图标,在图标的任意位置单击,启动保存文件对话框。输入名称为test,选择文件类型为jpg(或其他格式),保存按钮,就可以保存为图像文件了,如下图所示。(比如,我这里选择用最左上方的那一幅图)
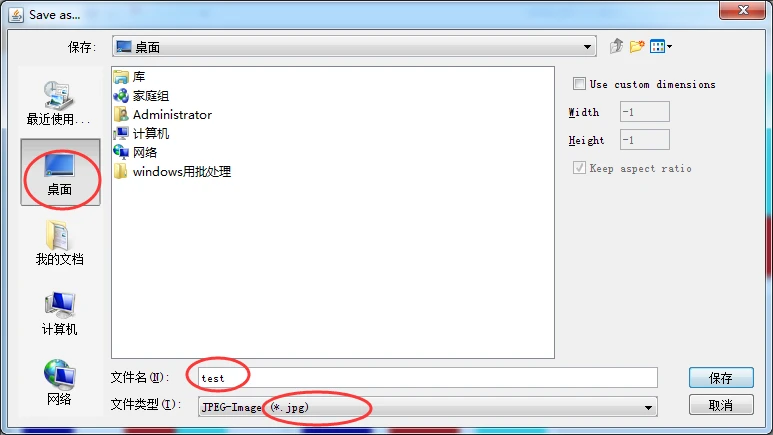
还可以定制图像文件的长、宽尺寸,单位为像素。选中use custom dimensions(使用自定义尺寸)复选框就可以设置图像尺寸,如果选择keep aspect ratio(保持宽高比)复选框,则在修改图像长(或宽)的同时,会按比例自动缩放宽(或长)。


成功!
二、预处理
预处理面板可以从文件、URL或数据库中加载数据集,并且根据应用要求或领域知识过滤掉不需要进行处理或不符合要求的数据。
1、加载数据
预处理标签页的前四个按钮可以让用户将数据加载到Weka系统。
Open file按钮启动打开文件对话框,用户可以浏览本地文件系统,打开本地数据文件;
Open URL按钮要求 用户提供一个统一资源定位符地址,Weka使用HTTP协议从网络位罝下载数据文件;
Open DB按钮用于从数据库中读取数据,支持所有能够用JDBC驱动程序读取的数据库, 使用SQL语句或存储过程读取数据集。
请注意,必须根据自己的计算机环境配置,相应修 改weka/experiment/DatabaseUtils.props配置文件后才能访问数据库,具体参见下面我写的这篇博客;
Generate按钮用于让用户使用不同的DataGenerators(数据生成器)以生成人工 数据,适合用于分类功能的人工数据可以由决策列表RDG1、径向基函数网络 RandomRBF、贝叶斯网络BayesNet、LED24等算法产生,人工回归数据也可以根据数学表达式生成,用于聚类的人工数据可以使用现成的生成算法产生。
如果使用Open file按钮,可以读取多种数据格式的文件,包括Weka ARFF格式、 C4.5数据格式、CSV格式、JSON实例文件格式、libsvm数据文件格式、Matlib ASCII文件格式、svm轻量级数据文件格式、XRFF格式,以及序列化实例的格式。
其中,ARFF 格式文件的后缀为.arff, C4.5文件的后缀为.data或.names, CSV格式文件的后缀为.csv, JSON实例文件格式的后缀为json,libsvm数据文件格式的后缀为.libsvm, Matlib ASCII文件格式的后缀为.m,svm轻量级数据文件格式的后缀为.dat,XRFF格式的后缀为.xrff, 序列化实例对象文件的后缀为.bsi。
注意到有的格式后缀还加上.gz,这是对应文件的压缩 形式。

另外,使用Save(保存)按钮,可以将已加载的数据保存为Weka支持的所有文件格式。该功能特别适合转换文件格式,以及学习Weka文件格式的细节。

由于有多种数据格式,为了从不同种类的数据源中导入数据,Weka提供实用工具类进行转换,这种工具称为转换器(converters),位于weka.core.converters包中。按照功能的不同,转换器分为加载器和保存器,前者的Java类名以Loader结束,后者以Saver结束。
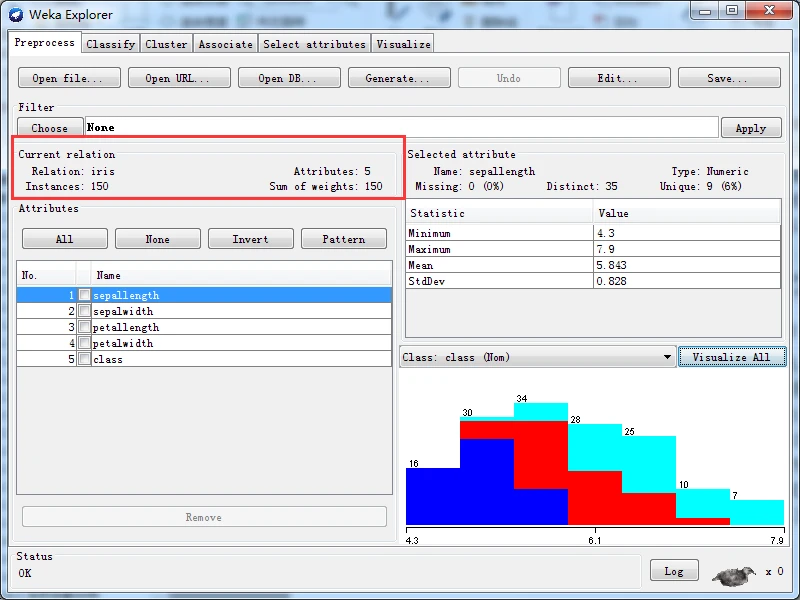
加载数据后,预处理面板会在Currem relation(当前关系)子面板显示当前数据集的一些总结信息。Relation(关系)栏显示关系名称,该名称由加载的文件给定,也可通过过滤器来更改名称;Attributes(属性)栏显示数据集中的属性(或特征)个数:Instances(实例)枚显示数 据集中的实例(或数据点/记录)个数:Sum of weights(权重和)栏显示全部实例的权重之和。 例如,当加载iris数据姐后,当前关系子而板显示关系名称为iris,属性个数为5,实例个数为150,权重和为150,当前关系子面板如下图所示。
Weka根据文件后缀调用不同的转换器来加载数据集。如果Weka无法加载数据,就会尝试以ARFF格式解释数据,如果失败,就会弹出如下图的提示对话框,提示 Weka无法自动决定使用哪一个文件加载器,需要用户自己来选择。
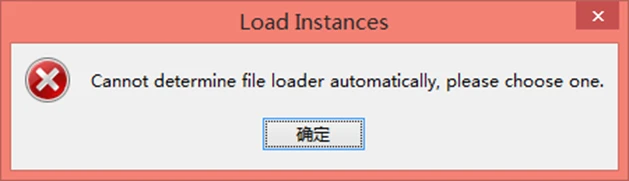
加载数据失败图
然后,单击上图中的“确定”按钮后,会弹出如下图所示的通用对象编辑器对话框, 让用户选定能打幵数据文件的对应转换器。默认转换器为CSVLoader,该转换器专门用于加载后缀为.csv的文件。如果用户己经确定数据文件格式是CSV格式,那么可以输入曰期格式、字段分割符等信息。如果对窗口里的各项输入不了解,可以单击More按钮査看使用说明。
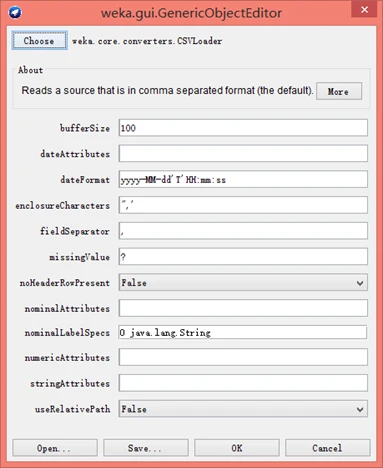
图 通用对象编辑器
如果用户已经知道数据文件格式不是CSV格式,可以单击通用对象编辑器对话框上部的Choose按钮选择其他的转换器,如下图所示。
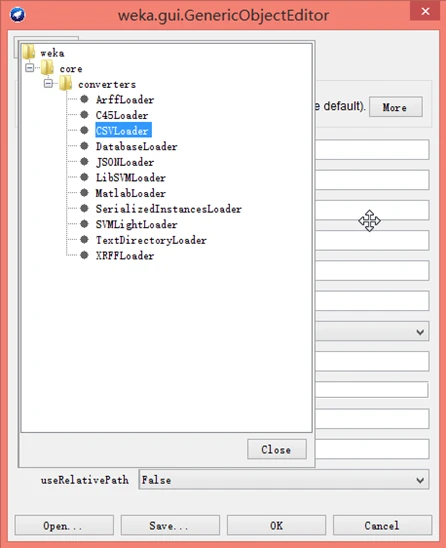
图 选择转换器图
其中,第一个选项是ArffLoader,选择该选项并成功的可能性很小,因为默认使用它来加载数据集,没有成功才会弹出加载数据失败的窗口。
第二个选项是C45Loader,C4.5 格式的数据集对应两种文件,一种文件提供字段名,另一种文件提供实际数据。
第三个选项是默认的CSVLoader,这足一种以逗号分隔各属性的文件格式,前面已经介绍了这种数据转换器。
第四个选项DatabascLoader是从数据库,而不是文件中读取数据集。然而,使用SQLViewer工具来访问数据库,是吏为人性化而方便的方案。 SerializedInstancesLoader选项用于重新加载以前作为Java序列化对象保存的数据集。任何 Java对象都可以采用这种格式予以保存并重新加载。由于序列化对象本身就是Java格式,使用它可能比加载ARFF文件的速度更快,这是因为加载ARFF文件时必须对其进行分析和检查,从而花费更多的时间。如果需要多次加载大数据集时,很值得以这种数据格式进行保存。
值得一提的是,TextDirectoryLoader加载器的功能是导入一个目录,目录中包含若干以文本挖掘为目的的纯文本文件。导入目录应该有特定的结构——一组子目录,每个子目录包含一个或多个扩展名为.txt的文本文件,每个文本文件都会成为数据集中的一个实例,其中,一个字符串型属性保存该文件的内容,一个标称型的类别属性保存文件所在的子目录名称。该数据集可以通过使用StringToWordVector过滤器进一步加工为词典,为后面的文本挖掘做准备。
2、属性处理
在当前关系子面板的下方,可以看到Attributes(属性)子面板,该子面板上部有四个按钮,中部是一个三列多行的表哥,下部有一个Remove按钮。如下图所示。
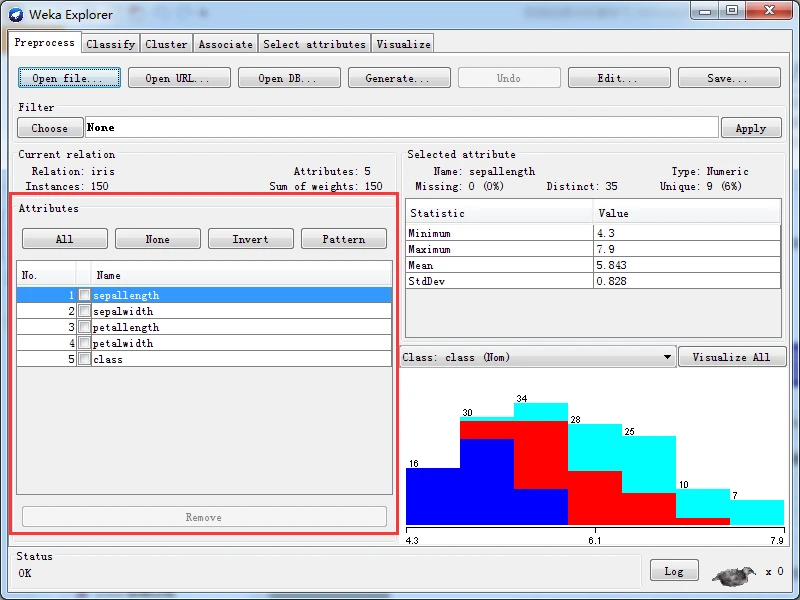
表格有三列表头,包括No.(序号)列、复选框列和Name(名字)列。
其中,序号列用于标识指定数据集中的属性序号;
复选框列用于选择厲性,并对其进行操作;
名字列显示属性名称,与数据文件的属性声明一致。
表格里每行表示一个属性,单击某一行的复选框选中该行,再单击一次则取消选中。 表格上面的四个按钮也可以用于改变选中状态;ALL按钮使全部复选框都选中,即选中全部属性;None按钮使全部复选框都取消选中,即不选中任何属性; Invert按钮反选,即取消选中己经选中的复选框,选中没有选中的复选框;Pattern按钮使用Perl5正则表达式指 定要选中的属性,例如,.*_id选择满足属性名称以_id结束的全部屈性。
一旦己经选中所需的属性,就可以单击属性列表下面的Remove按钮将它们去除,本功能用于去除无关属性。请注意,本功能仅去除内存中的数据集,不会更改数据文件的内容。另外,属性去除之后还可以单击Undo按钮进行撤消,Undo按钮位于预处理面板的上部。
如果选中某一个属性,例如,下图选中名称为sepallength的屈性,该行的颜色就会变为蓝色,并且窗口右边的Selected attribute(己选择属性)子面板将显示选中属性的一些信息。
iris.arff里的,以下是选择数值型属性的统计显示结果。

weather.nominal.arff里的,以下是选择标称型属性的统计显示结果。
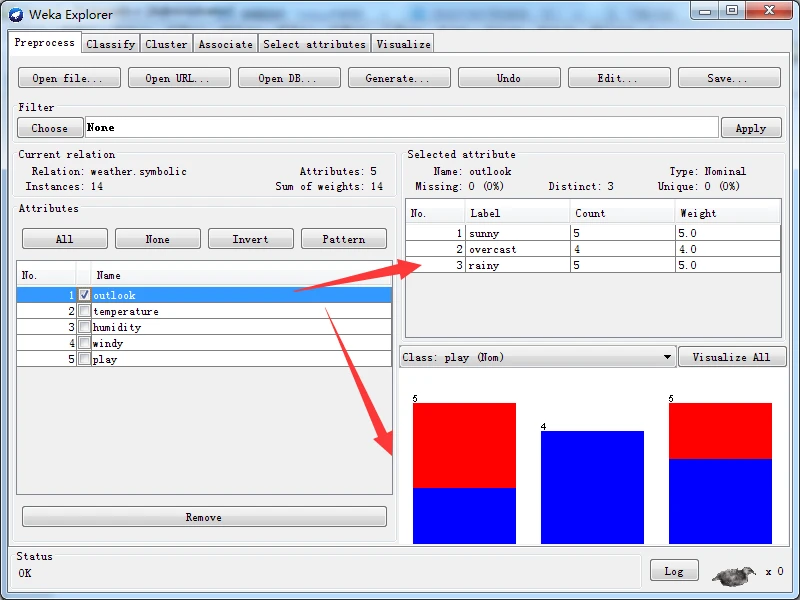
其中,Name栏显示属性的名称,与属性列表中选中属性的名称相同;
Type栏显示属性的类型,最常见的就是标称型和数值型;
Missing(缺失)栏显示数据集中该属性不存在或未指定的实例的数量及百分比;
Distinct(不同)栏显示该属性取不同值的数量;
Unique(唯一)栏显示没有任何其他实例拥有该属性值的数量及百分比。
已选择属性子面板的下部有一个统计表格,显示该属性值的更多信息,根据属性类型的不同,表格会有所差别。
由上面的iris.arff里的,以下是选择数值型属性的统计显示结果 和 weather.nominal.arff里的,以下是选择标称型属性的统计显示结果。得出,
如果属性是数值类型,表格显示数据分布的四种统计描述---Minimum(最小值)、Maximum(最大值)、Mean(平均值)和StdDev(Standard Deviation,标准偏差);
如果属性是标称型,列表显示包含属性的全部可能的No.(编号)、Label(标签)表示属性值名称、Count(数量)表示拥有该属性值的实例数量、Weight(权重)表示拥有该属性值的实例权重。
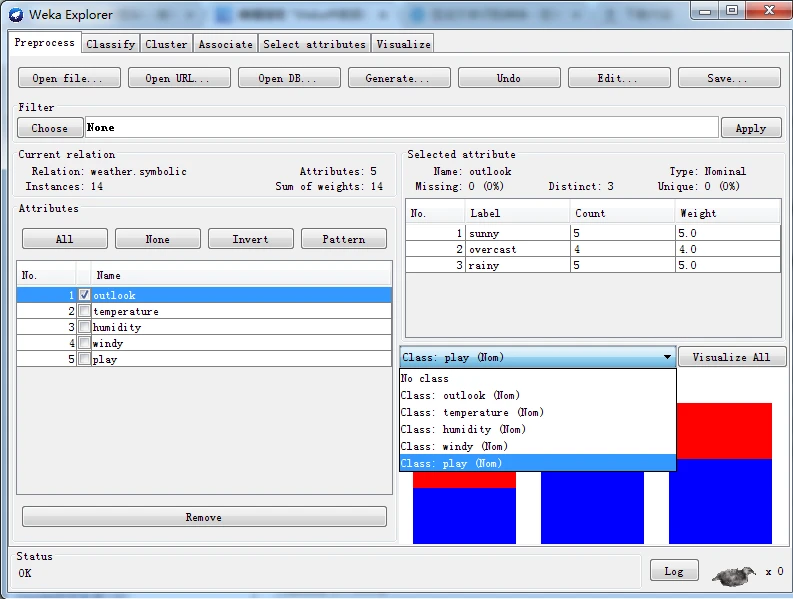
在统计表格之下会显示一个彩色直方图,如图所示,直方图之上有一个下拉列表框,用于选择类别属性。
3、过滤器
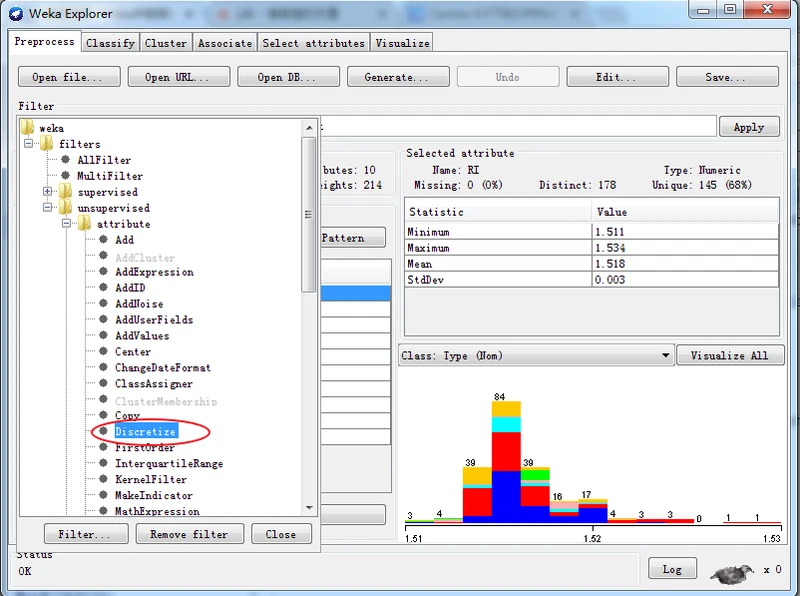
预处理面板允许定义并执行以各种方式转换数据的过滤器,过滤器也称为筛选器。在Filter标签之下有一个Choose(选择)按钮,单击该按钮可以选择一个过滤器,如下图所示,按钮的右侧是过滤器输入框,用于设置所选择的过滤器参数。
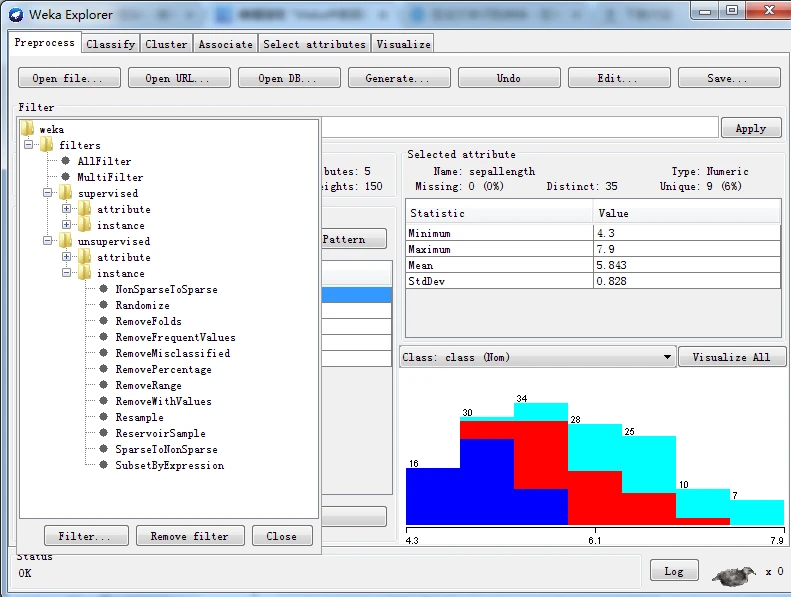
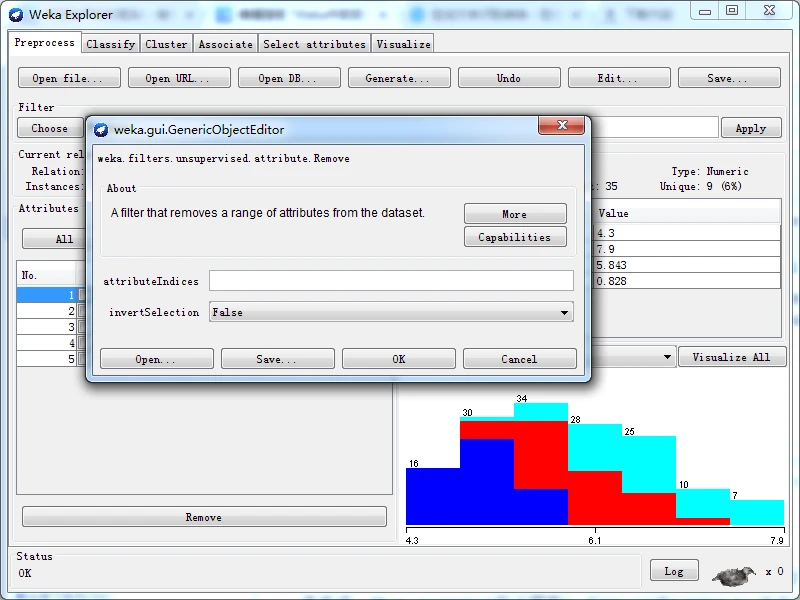
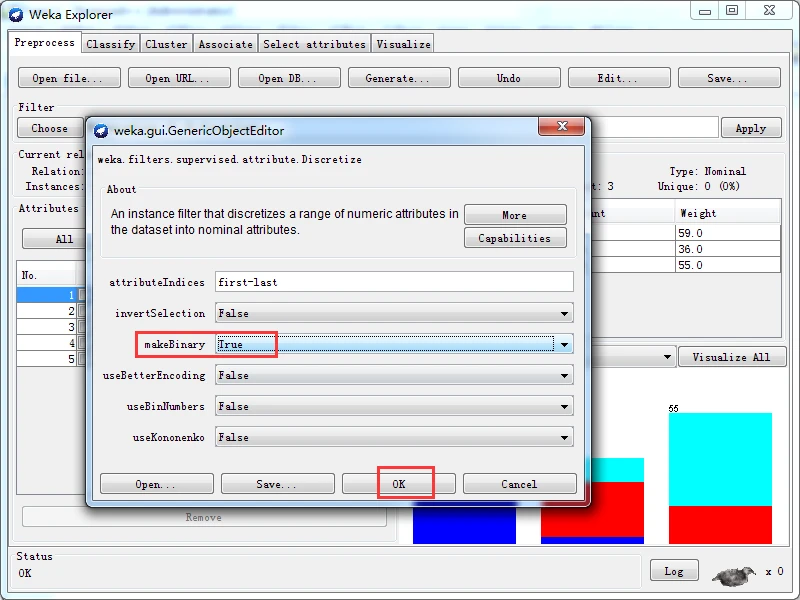
一旦选定过滤器后,其名称和参数都会显示在过滤器输入框内。在框内单击会弹出一个通用对象编辑器对话框,如下图所示。比如我这里选择Weka下的filters下的unsupervised下的attribute下的Remove
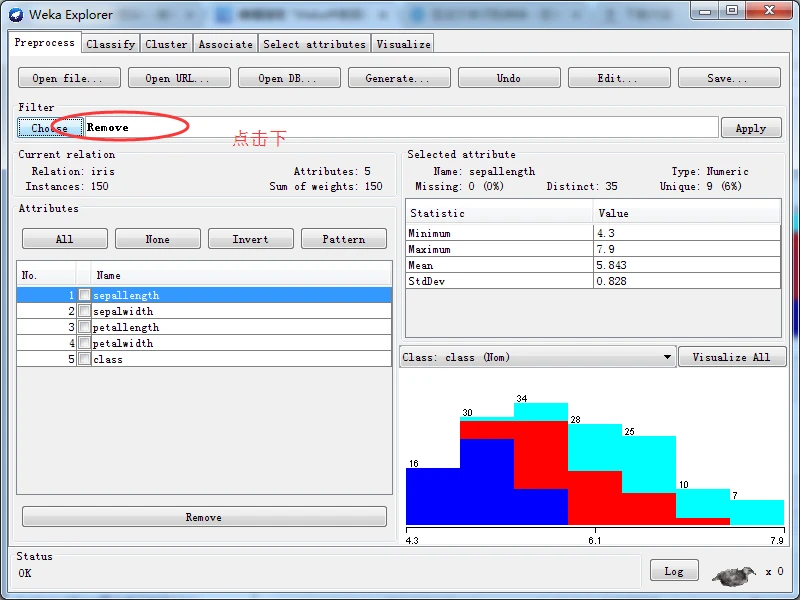
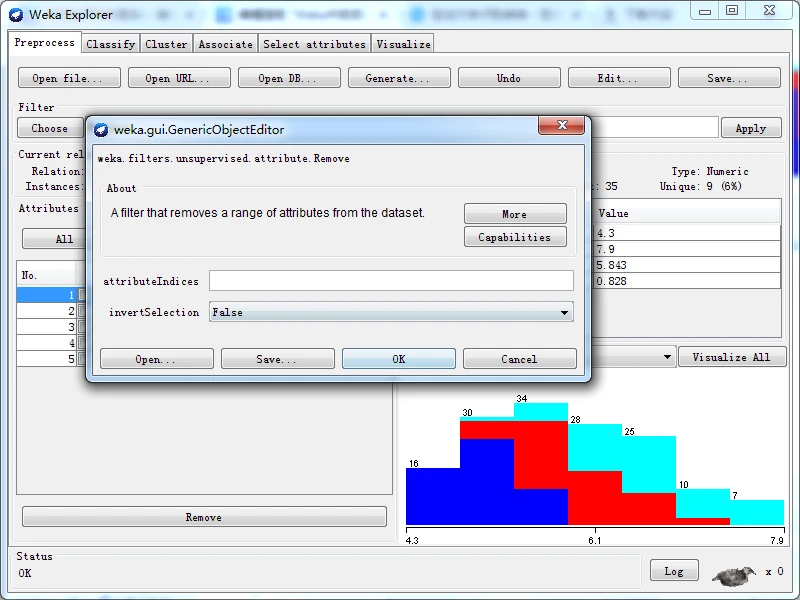
则,得到一个通用对象编辑器对话框用于设置过滤器选项。如果大家用不同的过滤器,则不一样哈!
好的,About框简要说明所选择过滤器的功能;单击右侧的More按钮,弹出一个显示更多信息的窗口,显示该过滤器的简介和不同选项的功能,如下图所示。
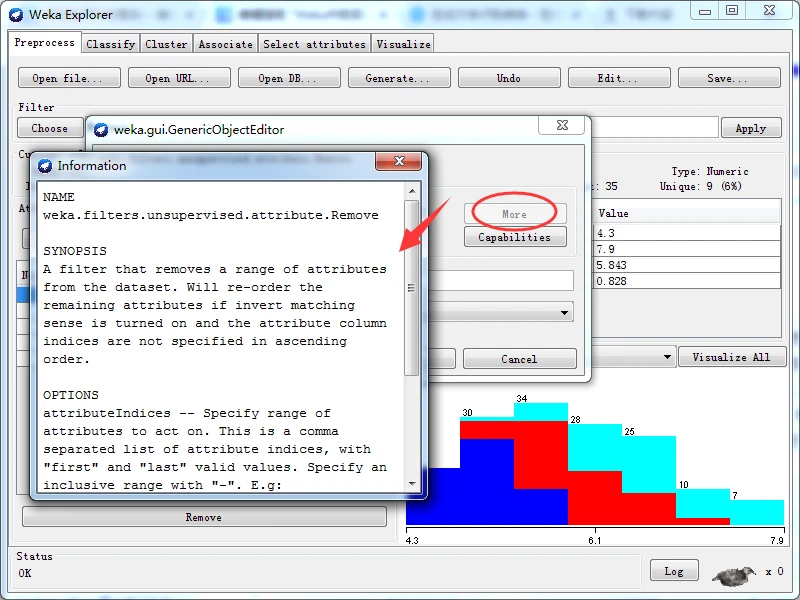
单击Capabilities按钮,弹出一个信息窗口,列出所选择对象能够过处理的类别类型和属性类型,如下图所示。
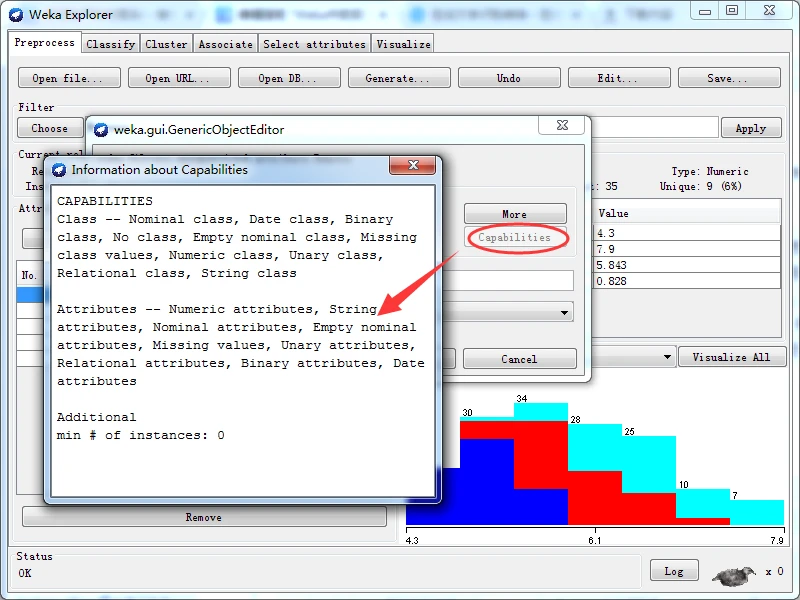
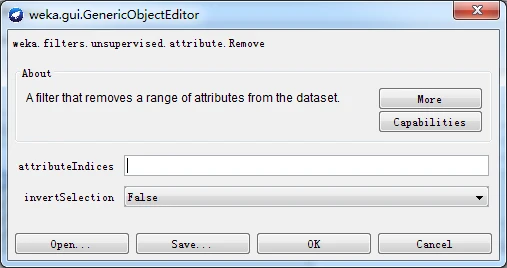
该对话框的中部,attributeIndices文本框用于让用户输入属性的索引(或下标),invertSelection下拉列表框只有ture和false两个选项,提示是否反选。对话框下端有四个按钮,前两个按钮-----Open按钮和Save按钮,用于保存对象选项设置,以备将来使用;Cancel按钮用于取消所做的修改,回退到原来的状态;Ok按钮用于已经正确完成设置后,返回探索者窗口。
用鼠标右击(或用Alt + Shift + 单击)过滤器输入框,就会弹出一个菜单,该带单有四个选项:Show properties(显示属性)、Copy configuration to clipboard(复制设置到剪贴板)、Enter configuration(输入设置)和Edit configuration(编辑设置)。
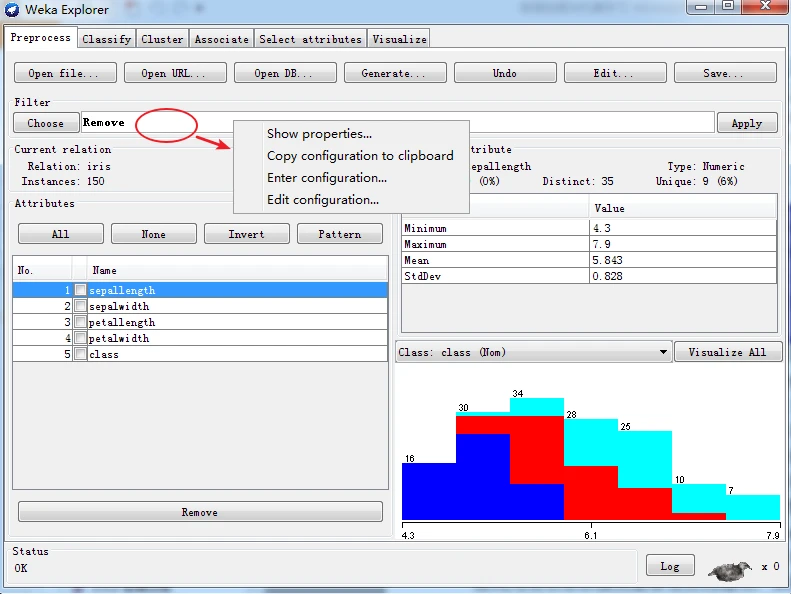
如果选择Show properties,就会弹出一个通用对象编辑器对话框,允许用户修改设置,其功能与单击过滤器输入框一样,如下所示
如果选择Copy configuration to clipboard,则将当前的设置字符串复制到剪贴板,以便用于Weka以外的系统中,当用户设置了很长而复杂的选项设置字符串并且想将来复用时,该功能非常方便,如下所示
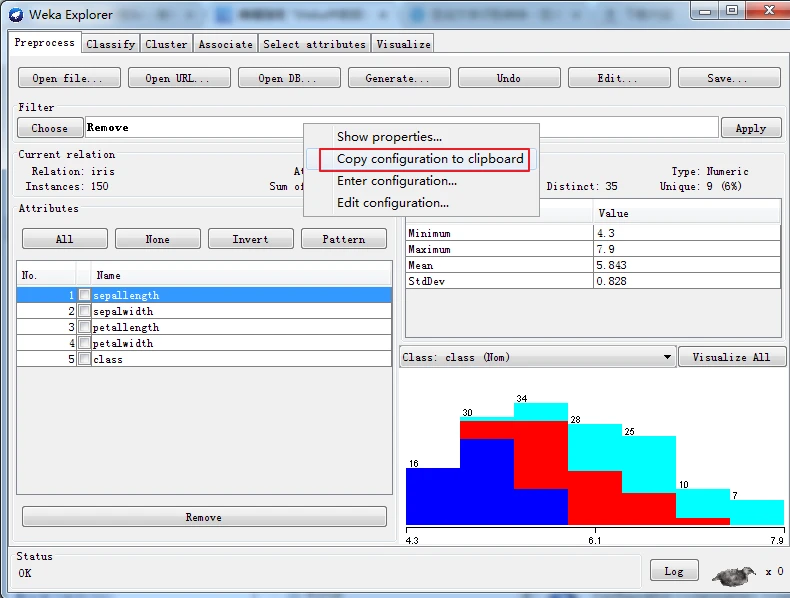
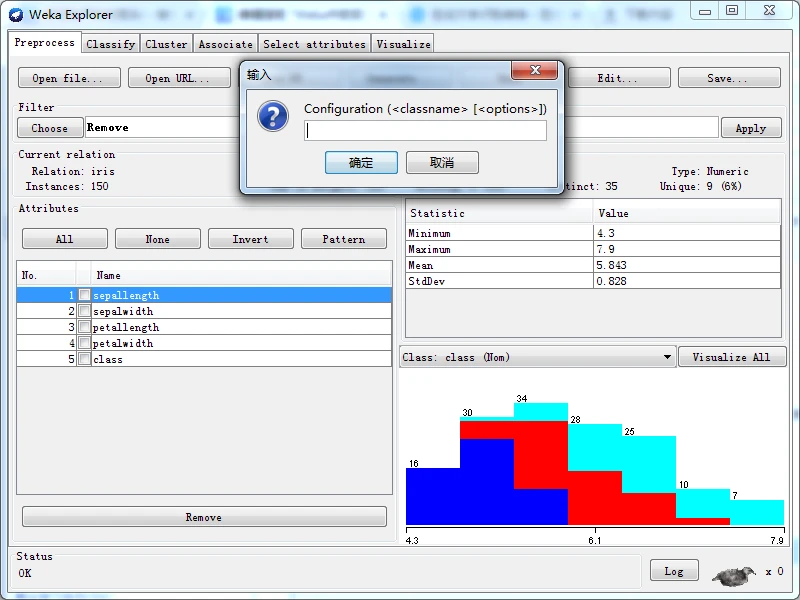
如果选择Enter configuration菜单项,则弹出一个输入dui对话框,让用户直接输入设置字符串,格式为类名称后接类能够支持的选项,如下图所示。
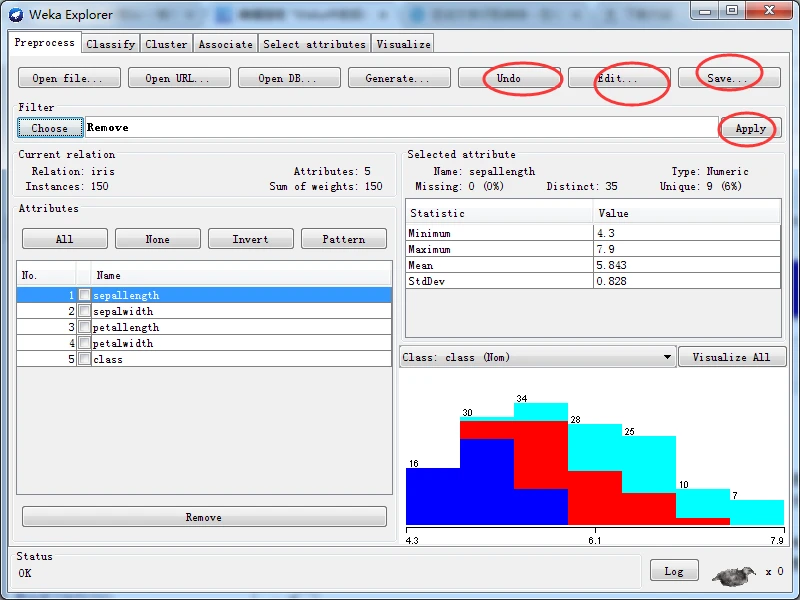
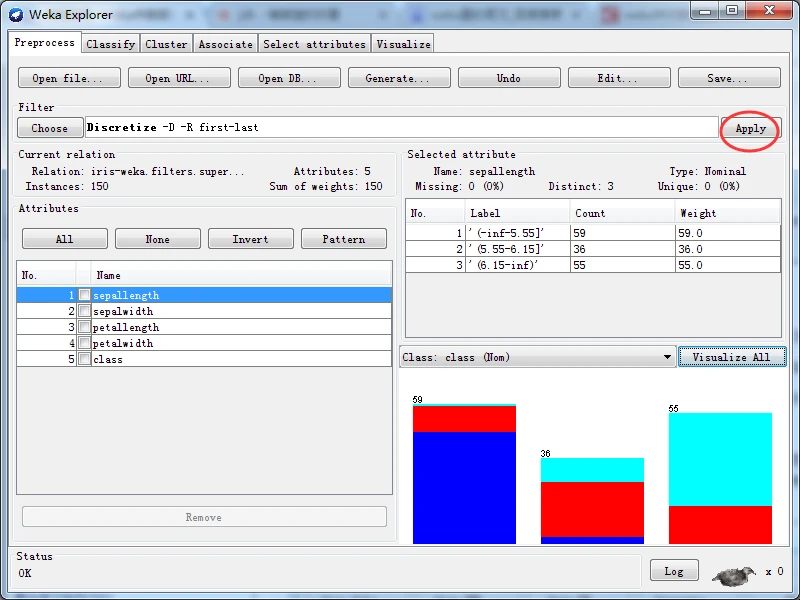
一旦选择并配置好一个过滤器之后,就可以将其应用到数据集。单击位于预处理面板中Filter子面板右端的Apply按钮应用过滤,预处理面板会显示转换后的数据信息。如果对结果不满意,可以单击Undo按钮撤销转换,还可以单击Edit按钮在数据集编辑器里手动修改数据。如果满意修改后的结果,可以单击Preprocess标签页右上角的Save按钮,将当前关系以文件格式进行保存,以供将来使用。
使用直方图上部的下拉列表框,可以设置类别属性。根据是否设置类别属性,有些过滤器的行为会有所不同。特别地,有监督过滤器要求设置类别属性;一些无监督属性过滤器会忽略类别属性,即使已经设置了类别属性。请注意,如果不想设置类别属性,可以将类别属性设为None。
4、过滤器算法介绍
在Weka中实现的过滤算法,这些过滤算法都可以用于探索者、知识流和实验者界面。
所有的过滤器都是将输入数据集进行某种程度的转换,转换为适合数据挖掘的形式。 选杼某个过滤器之后,过滤器的名字及默认参数会出现在Choose按钮旁的输入框内,通过单击该框可以在通用对象编辑器中设置其属性。过滤器以及参数都会以命令行的方式显现在输入框,仔细观察和研宄这些过滤器和参数设设置,是学习如何直接使用Weka命令的好方法。
Weka过滤器分为无监督weka过滤器和有监督weka过滤器两种。过滤器经常应用于训练集,然后再应用于测试集。如果过滤器是有监督的,例如,使用带类别值的离散化过滤器是有监督的,如果将训练得到的良好间隔施加到测试集中,可能会使结果出现偏倚。因此,使用有监督的过滤器时,必须非常小心,以确保评估结果的公平性。然而,由于无须经过训 练,无监督过滤器就不会出现这个问题。
Weka将无监督和有监督两种过滤方法分幵处理,每种类型又细分为属性过滤器和实例过滤器,前者作用于数据集中的属性,后者作用于数据集中的实例。要了解某个过滤器的更多使用信息,请在Weka探索者中选择该过滤器,并查看对应的对象编辑器,以了解该过滤器的功能和选项。
Weka实现的过滤器的更详细介绍请大家在自己机器上逐一去看吧。本博客将按照过滤器的类型和功能顺序进行介绍。
因为,Weka将无监督和有监督两种过滤方法分幵处理,每种类型又细分为属性过滤器和实例过滤器,前者作用于数据集中的属性,后者作用于数据集中的实例!!!
无监督属性过滤器
- 1) 添加和删除属性
- 2) 改变值
- 3) 转换
- 4) 字符串转换
- 5) 时间序列
- 6) 随机化
无监督实例过滤器
- 1) 随机化和子抽样
- 2) 稀疏实例
有监督属性过滤器
- Discretize过滤器
- NominalToBinary过滤器
- ClassOrder过滤器
- AttributeSelection过滤器
- AddClassification过滤器
- PartitionMembership过滤器
有监督实例过滤器
Weka提供四个有监督的实例过滤器。
- ClassBalancer过滤器调整数据集中的实例,使得每个类别都有相同的总权重。所有实例的权重总和将维持不变。
- Resample过滤器与同名的无监督实例过滤器类似,但它保持在子样本的类别分布。另外,它可以配置是否使用均匀的分类偏倚,抽样可以设置为有放回(默认)或无放回模式。
- SpreadSubsample过滤器也产生一个随机子样本,但可以控制最稀少和最常见的类别之间的频率差异。例如,可以指定至多2∶1类别频率差异。也可以通过明确指定某个类别的最大计数值,来限制实例的数量。
- 与无监督的实例过滤器RemoveFolds相似,StratifiedRemoveFolds过滤器为数据集输出指定交叉验证的折,不同之处在于此时的折是分层的
1.无监督属性过滤器
1)添加和删除属性
Add过滤器在一个给定的位置插入一个属性,对于所有实例该属性值声明为缺失。使用通用对象编辑器来指定属性名称,指定的属性名称会出现在属性列表中,标称属性还可以指定可能值:日期属性还可以指定日期格式。Copy过滤器复制现有属性,这样就可以在实验时保护这些属性,以免属性值为过滤器所覆盖。使用表达式可以一起复制多个属性, 例如,“1-3”复制前三个属性,“first-3,5,9-last”复制属性“1、2、3、5、9、10、11、 12、…”。选择可以进行反转,即反选,反选选中除了选定属性以外的所有属性。很多过滤器都拥有表达式和反选功能。
AddID过滤器在用户指定索引的属性列表中插入一个数字标识符属性。标识符属性常用于跟踪某个实例,尤其是在己经通过某种方式处理过数据集之后,例如,通过其他过滤器进行过转换,或者随机化重排实例的顺序之后,标识符便于跟踪。
Remove过滤器删除数据集中指定范围的属性,与之类似的有RemoveType过波器和 RemoveUseless过滤器,RemoveType过滤器删除指定类型(标称、数值、字符串、日期、 或关系)的所有属性,RemoveUseless过滤器删除常量属性以及几乎与所有实例的值都不相 同的标称属性。用户可以通过规定不相同值的数量占全部值总数的百分比来设定可以容忍的变化度,决定是否删除一个属性。需要注意的是,如果在预处理面板己经设置了类别属性(默认情况下,最后一个属性就是类别属性),一些无监督属性过滤器的行为不同。例如,RemoveType和RemoveUseless过滤器都会跳过类别属性。
InterquartileRange过滤器添加新属性,以指示实例的值是否可以视为离群值或极端值。离群值和极端值定义为基r属性值的第25个和第75个四分位数之间的差。如果用户指定的极端值系数和四分位距的乘积值高于第75个四分位数,或低于第25个四分位数, 该值就标记为极端值(也有超出上述范围标记为离群值但不是极端值的情况)。可以设置该 过滤器,如果某个实例的任意M性值认为是离群值或极端值,或产生离群极端的指标,可以标记该实例为离群值或极端值0也可以将所有极端值标记为离群值,并输出与中位数偏 离多少个四分位数的属性。该过滤器忽略类别属性。
AddCluster过滤器先将一种聚类算法应用于数据,然后再进行过滤。用户通过对象编辑器选择聚类算法,其设置方式与过滤器一样。AddCluster对象编辑器通过自己界面的 Choose按钮来选择聚类器,用户单击按钮右边方框开启另外一个对象编辑器窗口,在新窗口中设賈聚类器的参数,必须填写完整后才能返回AddCluster对象编辑器。一旦用户选定一个聚类器,AddCluster会为每个实例指定一个簇号,作为实例的新属性。对象编辑器还允许用户在聚类时忽略某些属性,如前面所述的Copy过滤器那样指定。 ClusterMembership过滤器在过滤器对象编辑器指定所使用的聚类器,生成族隶属度值,以形成新的属性。如果设罝了类别属性,在聚类过程中会忽略。
AddExpression过滤器通过将一个数学函数应用于数值型属性而生成一个新属性。表达式可包括属性引用和常量,四则运算符+、-、*、/和^,函数log、abs、cos、exp、 sqrt、floor、ceil、rint、tan、sin以及左右括号。属性可通过索引加前缀a确定,例如a7指第七个属性。表达式范例如下:
a1^2*a5/log(a7*4.0)
MathExpression过滤器与AddExpression过滤器类似,它根据给定的表达式修改数值 属性,能够用于多个属性。该过滤器只是在原地修改现有属性,并不创建新属性。正因为 如此,该表达式不能引用其他属性的值。所有的适用于AddExpression过滤器操作符都可用,还可以求正在处理属性的最小值、最大值、平均值、和、平方和,以及标准偏差。此 外,可以使用的包含运算符和函数的简if-then-else的表达式。
NumericTransfomi过滤器通过对选中的数值属性调用Java函数,可以执行任意的转换。该函数可以接受任意double数值作为参数,返回值double类型。例如, java.lang.Math包的sqrt()函数就符合这一标准。 NumericTransform过滤器有一个参数是实现该函数Java类的全限定名称,还有一个参数是转换方法的名称。
Normalize过滤器将数据集中的全部数值属性规范化为[0,1]区间。规范化值可以采用用户提供的常数进一步进行缩放和转换。Center和Standardize过滤器能将数值属性转换为具有零均值,后者还能转换为具有单位方差的数值属性。如果设罝了类别属性,上述三个过滤器都会跳过,不对类别属性进行处理。 RandomSubset过滤器随机选择属性的一个子集, 并包括在输出中。可以用绝对数值或百分比指定抽取的范围,输出的新数据集总是把类别属性作为最后一个属性。
ParUtionedMultiFilter过滤器是一种特殊的过滤器,在输入数据集中一组对应的顺范围内应用一组过滤器。只允许使用能操作属性的过滤器,用户提供和配罝每个过滤器,定义过滤器工作的属性范围。removeUnused选项可以删除不在任何范围内属性。将各个过滤器的输出组装成一个新的数据集。Reorder过滤器改变数据中属性的顺序,通过提供属性索引列表,指定新顺序。另外,通过省略或复制属性索引,可以删除属性或添加多个副本。
2)改变值
SwapVaktes过滤器交换同一个标称属性的两个值的位置。值的顺序不影响学习,但如 果选择了类别属性,顺序的改变会影响到混淆矩阵的布局。 MergeTwoVlues过滤器将一 个标称属性的两个值合并为一个单独的类别,新值的名称是原有两个值的字符串连接,每 —个原有值的每次出现都更换为新值,新值的索引比原有值的索引小。例如,如果合并天 气数据集中outlook属性的前两个值,其中有五个sunny、四个overcast、五个rainy实例, 新的outlook屈性就包含sunny_overcast和rainy值,将有九个sunny_overcast实例和原有 的五个rainy实例。
处理缺失值的一个方法是在实施学习方案前,全局替换缺失值。ReplaceMissingValues 过滤器用均值取代每个数值厲性的缺失值,用出现最多的众数取代标称属性的缺失值。如果设置了类别属性,默认不替换该属性的缺失值,但可以使用ignoreClass选项进行修改。
NumericCleaner过滤器用默认值取代数值属性中值太小,或太大,或过于接近某个特定值。也可以为每一种情况指定不同的默认值,供选择情况包括的认定为太大或太小的阈值,以及过于接近定义容差值(tolerance value)。
如果属性标签缺失,可以使用AddValues过滤器为该属性添加给定标签列表。标签能以升序的方式进行排序。如果没有提供标签,则只能选择排序功能。
AddValues过滤器对照用户提供的列表,并在标称属性中添加其中不存在的值,可以 选择对标签进行排序。ClassAssigner过滤器用于设置或取消数据集的类别属性。用户提供 新的类别属性的索引,索引为0值则取消当前类别属性。
3)转换
许多过滤器将属性从一种形式转换为另一种形式。Discretize过滤器使用等宽或等频分箱将指定范围的数值属性离敗化。对于等宽分箱方法,可以指定箱数,或使用留一法交叉验证自动选择使似然值最大化。也可以创建多个二元属性,替换一个多元属性。对于等频离散化,可以改变每个分隔期望的实例数置。PKIDiscretize过滤器使用等频分箱离散化数 值属性,箱的数目设置为等于非缺失值数量的平方根。默认情况下,上述两个过滤器都跳过类别属性。
Makelndicator过滤器将标称属性转换为二元指示符属性,可以用于将多个类别的数据集转换成多个两个类别的数据集。它用二元属性替换所选择的标称属性,其中,如果某个特定的原始值存在,该实例的值为1,否则为0。新厲性默认声明为数值型,但如果需要,也可以声明为标称型。
对于一些学习方案,如支持向量机,多元标称属性必须被转换成二元属性。 NominalToBinary过滤器能将数据集中的所有指定的多元标称属性转换为二元属性,使用 一种简单的“每值一个”(one-per-value)编码,将每个属性替换为k个二元属性的k个值。 默认情况下,新属性将是数值型,己经是二元属性的将保持不变。NumericToBinary过滤器将除了类别属性外的所有数值属性转换成标称二元属性。如果数值属性的值恰好为0, 新属性值也为0 , 如果属性值缺失,新属性值也缺失,否则,新属性的值将为1。上述过滤器都跳过类别属性。 NumericToNominal过滤器通过简单地増加每一个不同数值到标称值列表,将数值属性转换为标称诚性。该过滤器在导入“.csv”文件之后非常有用,Weka的 CSV导入机制对所有的可解析为数字的数据列都相应创建为数值型属性,但有时将整型属 性的值解释为离散的标称型有可能更为恰当。
FirstOrder过滤器对一定范围的数值属性应用一阶差分算子。算法为:将N个数值型 属性替换为N-1个数值型属性,其值是原来实例中连续性值之差,即新属性值等于后一个属性值减去前一个属性值。例如,如果原来的属性值分别为3、2、1,则新的属性值将是-1、-1。
KernelFilter过滤器将数据转换为核矩阵。它输出一个新数据集,包含的实例数量和原 来的一样,新数据集的每个值都是用核函数评估一对原始实例的结果。默认情况下,预处理使用Center过滤器,将所有的值都转换为将中心平移至0,尽管没有重新缩放为单位方差。然而,用户也可以指定用不同的过滤器。
PrincipalComponents过滤器在数据集上进行主成分转换。将多元标称属性转换为二元属性,用均值替换缺失值,默认将数据标准化。主成分数量通常根据用户指定的捜盖比例的方差确定,俏也可以明确指定主成分数量。
4) 字符串转换
字符串属性值的数目不定。StringToNominal过滤器用一组值将其转换为标称型。用户要确保所有要出现的字符串值都会在第一批数据中出现。NominalToString过滤器转换的方向相反。
StringToWordVector过滤器将字符串属性值转换生成表示单词出现频率的数值属性。 单词集合就是新的属性集,由字符串属性值的完整集合确定。新属性可以采用用户指定的前缀来命名,这样通过名称容易区分来源不同的字符串属性。
ChangeDateFormat过滤器更改用于解析日期属性的格式化字符串,可以指定Java的SimpleDateFormat类所支持的任意格式。
5) 时间序列
Weka提供两种处理时间序列的过滤器。TimeSeriesTranslate过滤器将当前实例的属性值替换为以前(或未来)的实例的等效属性值。TimeSeriesDelta过滤器将当前实例的属性值替换为以前(或未来)的实例的等效属性值与当前值之间的差值。对于时移差值未知的实例,要么删除实例,要么使用缺失值。
6) 随机化
—些属性过滤器有意降低数据的质萤。AddNoise过滤器按照指定的一定比例更改标称属性的值。可以保留缺失值,也可以让缺失值和其他值一起变化。Obfuscate过滤器对关系属性、全部属性名称,以及所有标称型和字符串型属性值进行重命名,对数据集进行模糊处理,目的主要是为了交换敏感数据集。RandomProjection过滤器通过使用列为单位长度的随机矩阵,将数据投影到一个低维子空间,以此来降低数据维数。投影不包括类别属性。
2. 无监督实例过滤器
1)随机化和子采样
Randomize过滤器用于将数据集中实例顺序进行随机重排。产生的数据子集的方式有很多种。Resample过滤器产生一个有放回或无放回数据集的随机子样本。RemoveFolds过滤器将数据集分割为给定的交叉验证折数,并指定输出第几折。如果提供一个随机数种子,在提取子集前,先对数据重新排序。 ReservoirSample过滤器使用水库抽样算法从数据集中抽取一个随机样本(无放回)。当在知识流界面或命令行界面使用时,可以增量读取数据集,因此可以抽样超出主内存容量的数据集。
RemovePercentage过滤器删除数据集中的给定亩分比的实例。RemoveRange过滤器删除数据集里给定范围的实例。RemoveWithValues过滤器删除符合条件的实例,如标称属性具有一定值的,或者数值属性人于或小于特定阈值的。默认情况下,会删除所有满足条件 的实例。也可以反向匹配,保留所有满足条件的实例,删除其余实例。
RemoveFrequentValues过滤器用于删除那些满足某个标称型属性值最经常或最不经常使用的对应的实例。用户可以指定频度多大或多小的具体值。
SubsetByExpression过滤器选择那些满足用户提供的逻辑表达式的所有实例。表达式可以是数学运算符和函数,如那塑可用于AddExpression和MathExpression过滤器的运算 符和函数,以及应用于属性值的逻辑运算符(与或非)。例如以下表达式:
(CLASS is 'mammal') and (ATT14 > 2)
选择那些CLASS属性值为mammal并且第14个属性的值大于2的实例。
通过将分类方法应用到数据集,然后使用RemoveMisdassified过滤器删除错误分类的实例,可以删除离群值。通常上述过程需要重复多遍,直到充分清洗数据,也可以指定最 大的迭代次数。除了评估训练数据,还可以使用交叉验证,对数值类别也可以指定的错误阈值。
2)稀疏实例
NonSparseToSparse过滤器将全部输入实例转换为稀疏格式。SparseToNonSparsc过滤器将输入的所有稀疏实例转换为非稀疏格式。
3. 有监督属性过滤器
Discretize过滤器将数据集中一定范围内的数值屈性离散化为标称属性,用户指定属性的范围以及强制属性进行二元离散化。要求类别属性为标称属性,默认的离散化方法楚 Fayyad & Irani的MDL(最小描述长度)判据,也可以使用Kononenko方法。
NominalToBinary过滤器也有一个有监督版本,将全部标称属性转换成二元的数值属性。在有监督版本中,类别属性是标称型还是数值型,决定如何进行转换。如果是标称型,使用每个值一个属性的方法,将k个值的属性转换成k个二元属性。如果是数值型, 考虑类别平均值与每个属性值的关联,创建k-1个新的二元属性。两种情况都不改变类别 本身。
ClassOrder过滤器更改类别顺序。用户指定新顺序是否按随机顺序,或按类别频率进行升序或降序排列。该过滤器不能与FilteredClassifier元学习方案联合使用。 AttributeSelection过滤器用于自动属性选择,并提供与探索者界面中Select attributes子面板相同的功能。
AddClassification过滤器使用指定分类器为数据集添加分类、分类分布和错误标志。 分类器可以通过对数据木身进行训练而得到,也可以通过序列化模型得到。
4.有监督实例过滤器
Weka提供三个有监督的实例过滤器。
Resample过滤器与同名的无监督实例过滤器类似,但它保持在子样本的类别分布。另外,它可以配罝是否使用均匀的分类偏倚,抽样可以设置为有放回(默认)或无放回模式。
SpreadSubsample过滤器也产生一个随机子样本,但时以控制最稀少和最常见的类别之 间的频率差异。例如,可以指定至多2: 1类别频率差异,也可以通过明确指定某个类别 的敁大计数值,限制实例的数量。
与无监督的实例过滤器RemoveFolds相似,StratifiedRemoveFolds过滤器为数据集输出指定交叉验证的折,不同之处在于本次的折是分层的。
5、手把手教你用Weka里的过滤器
- 1. 使用数据集编辑器
- 2. 删除属性
- 3. 添加属性
- 4. 离散化
1.使用数据集编辑器
Weka可以查看和编辑整个数据集。
首先加载weather.nominal.arff文件,单击预处理而板上端的Edit按钮,弹出一个名称 为Viewer(阅读器)的对话框,列出全部天气数据。该窗口以二维表的形式展现数据,用于 查看和编辑整个数据集,如下图所示。
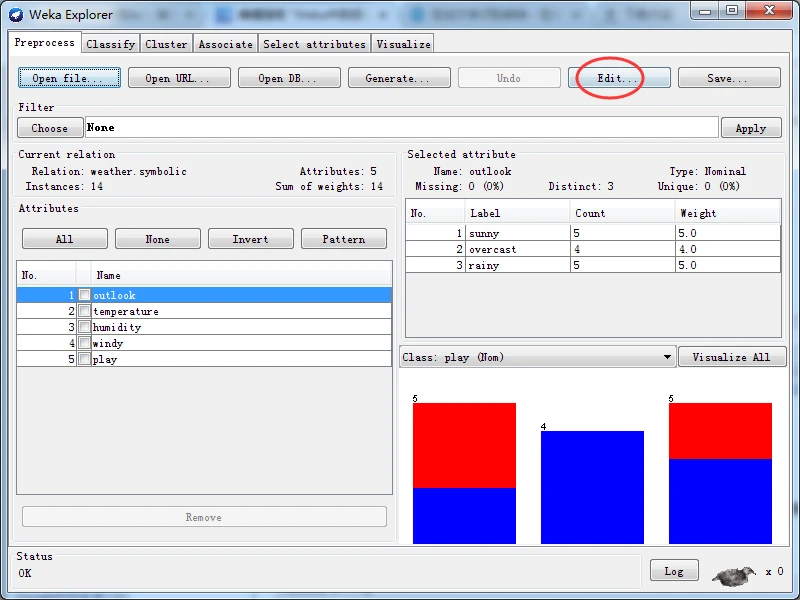
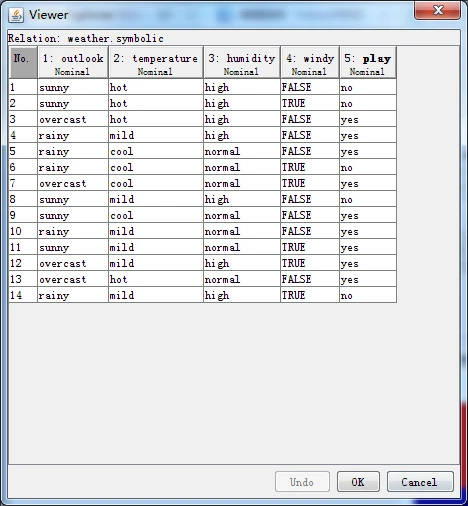
图 数据集编辑器对话框
数据表顶部显示当前数据集的关系名称。表头列出数据集各属性的序号、名称和数据类型。数据集编辑器的第一列是序号,标识实例的编号。
窗口右下部有三个按钮,Undo按钮撤销所做的修改,不关闭窗口;OK按钮提交所做的修改,关闭窗口;Cancel按钮放弃所做的修改,关闭窗口。
2、删除属性
Weka使用过滤器来系统性地更改数据集,因此过滤器属于预处理工具。
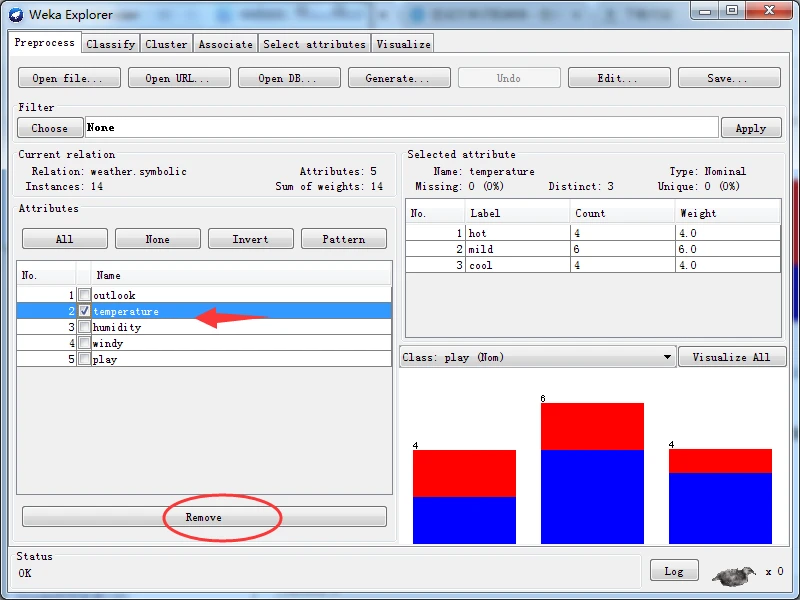
假如要求去除weather.nominal.arff数据集的第二个属性,即temperature属性。删除属性是具体步骤如下。
首先,使用探索者界面加载weather.nominal.arff文件。在预处理面板中单击Choose按钮,打开一个分层菜单,如下图所示。
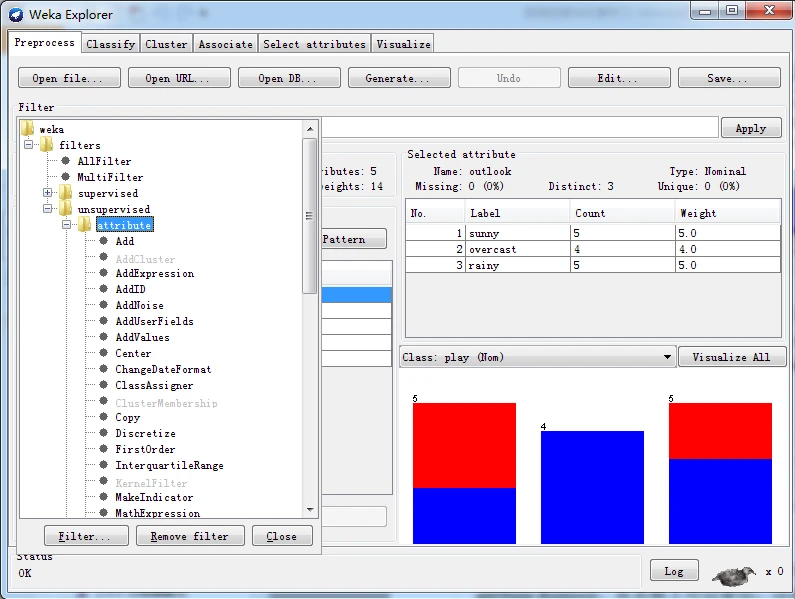
图 过滤器分层菜单图
适合本例要求的过滤器称为Remove,全称是weka.filters.unsupervised.attribme.Remove。从名称上可以看出,过滤器组织成层次结构,根为weka,往下继续分为 imsupervised(无监督)和suervised(有监督)两种类型,无监督要求设置类别属性,有监督不要求设置类别属性。继续往下分为attribute(属性)和instance(实例)两种类型,前者主要处理有关属性的过滤,后者处理有关实例的过滤。
在分层菜单中按照weka\ filters \ unsupervised \attribute路径,找到Remove条目,单击选择该过滤器。这时,Choose按钮右边的文本输入框应该显示Remove字符串。单击该文本框,打开通用对象编辑器对话框以设置参数。
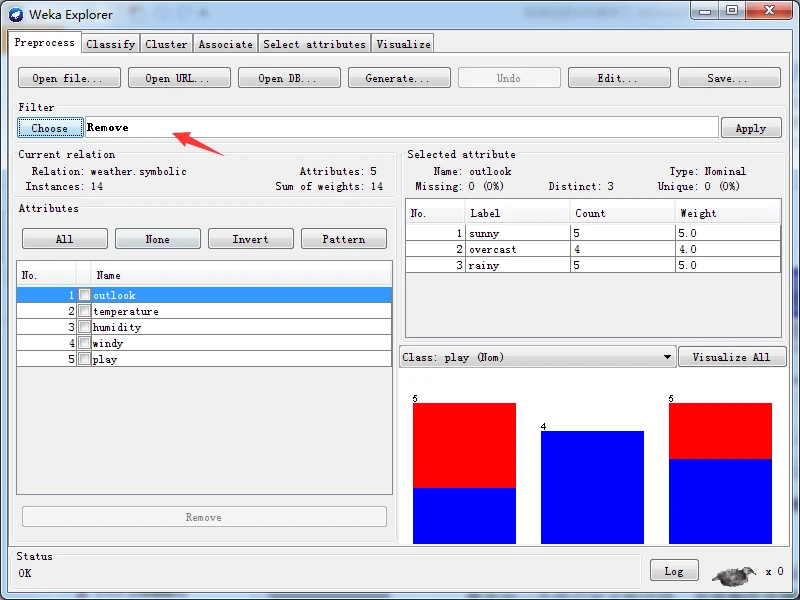
在attributelndices文本框内输入“2”,如下图所示。单击OK按钮关闭通用对象编辑器对话框。
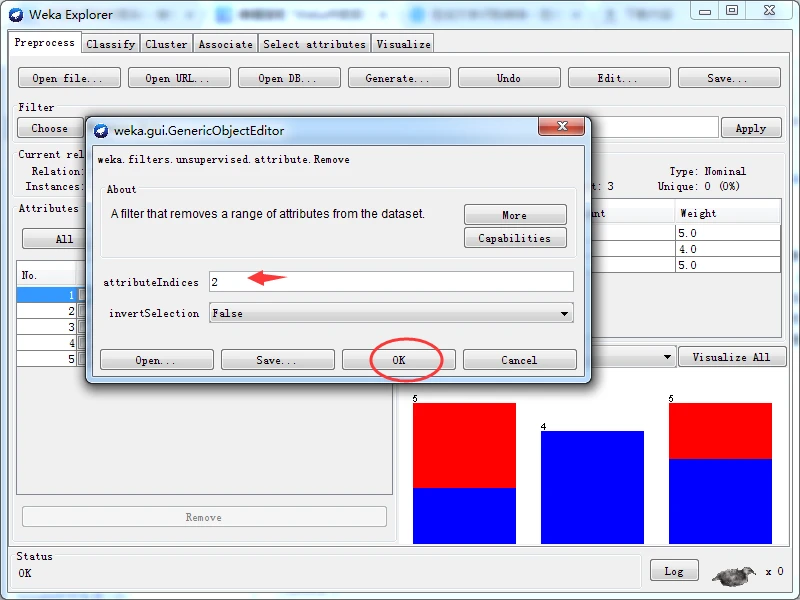
这时,Choose按钮右边的文本框应该显示“Remove -R 2”,含义是从数据集中去除第二个属性。单击该文本框右边的Applly按钮使过滤器生效据。
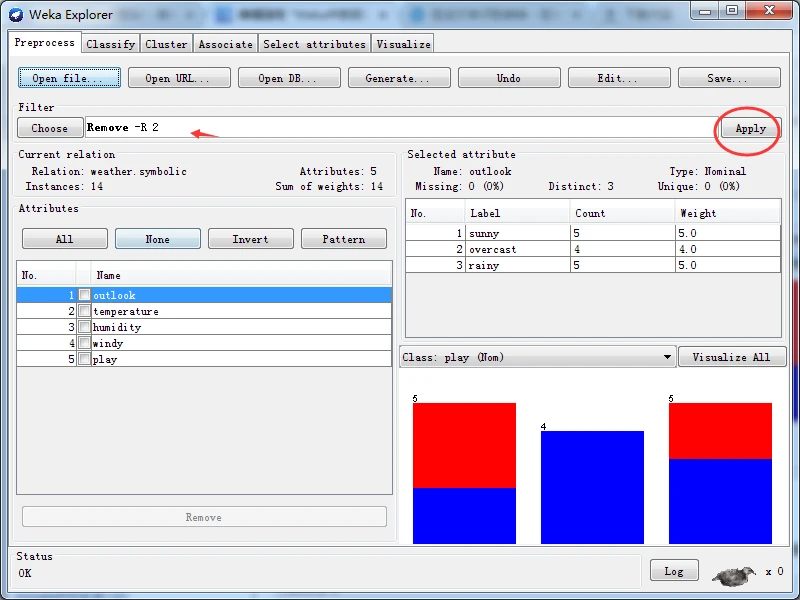
应该看到原来的5个属性现在变为4个,temperature属性己经被去除。要特别说明的是,本操作只影响内存中的数据,不会影响数据集文件中的内容。
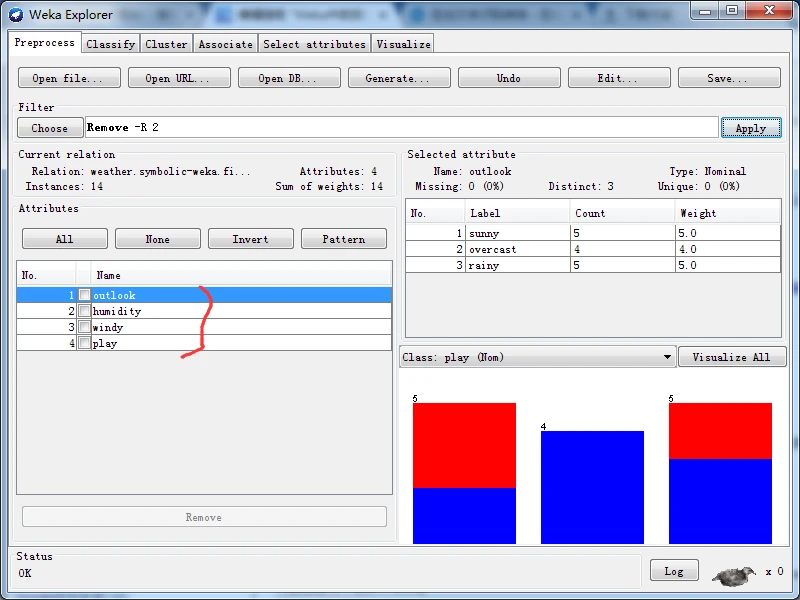
当然,变更后的数据集也可以通过单击Save 按钮并输入文件名另存为ARFF格式或其他格式的新文件。如果要撤消过滤操作,请单击 Undo按钮,撤消操作也只会影响内存中的数。
如果仅需要去除属性,还有更简单并且效果一样的方法。只要在Attributes子面板内选择要去除的属性,然后单击属性列表下面的Remove按钮即可。
3、添加属性
启动探索者界面并加载weaather.nominal.arff数据集。假如要求在数据集倒数第二个属性位置添加一个用户定义的字段,具体操作步骤如下:
在预处理面板上单击Choose按钮,选择AddUserFields过滤器。然后单击Choose按钮旁的方框,在通用对象编辑器设置AddUserFields过滤器。
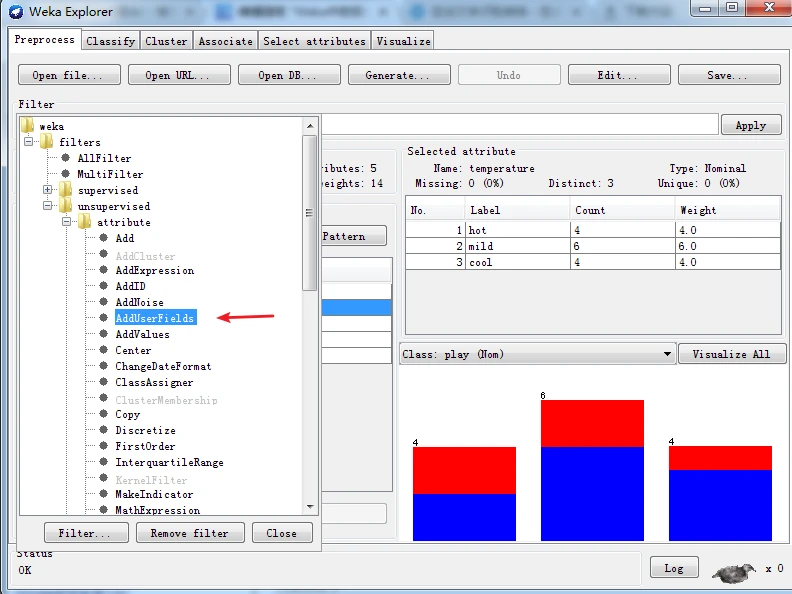
然后单击Choose按钮旁的方框,在通用对象编辑器中设置AddUserFields过滤器的选项。
单击New按钮,然后设置Attribute name(属性名称)为mode,设置Attribute type(属性类型)为nominal,不设置Date format(日期格式)和Attribute value(属性值)两个字段,如下图所示。
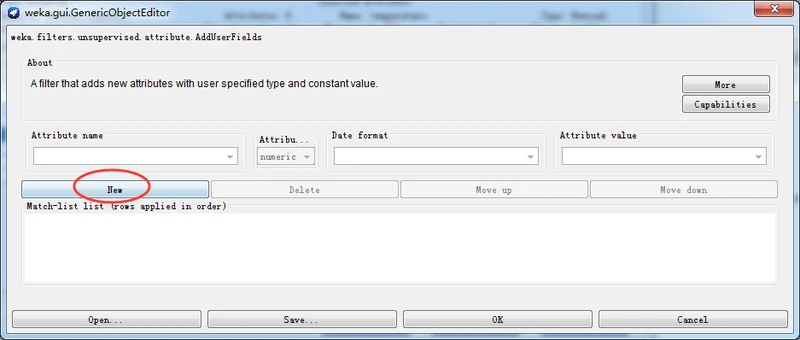
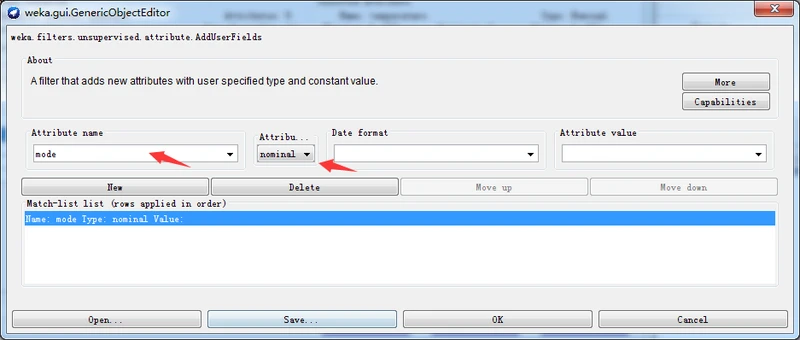
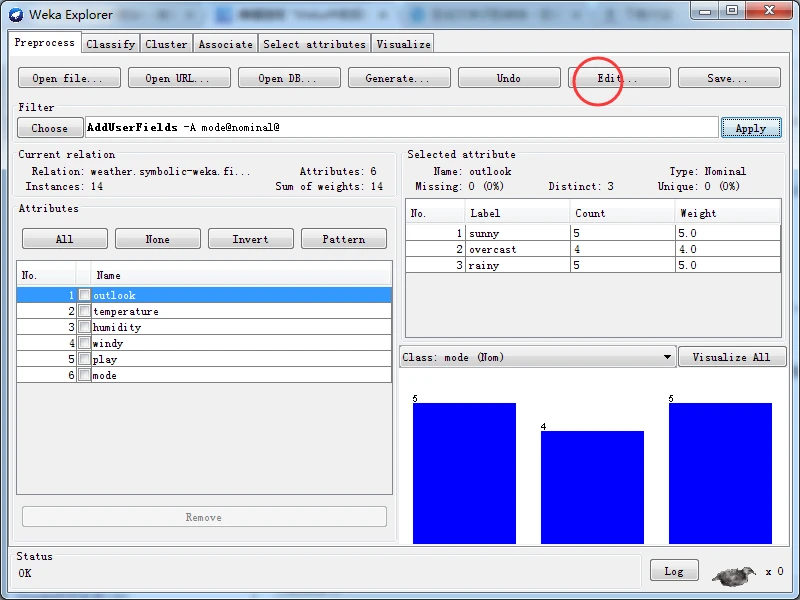
单击OK按钮结束选项设置,并在预处理面板上单击Apply按钮应用过滤器。这时,应该看到Attributes子面板的属性表格中看到多出来一个mode属性。


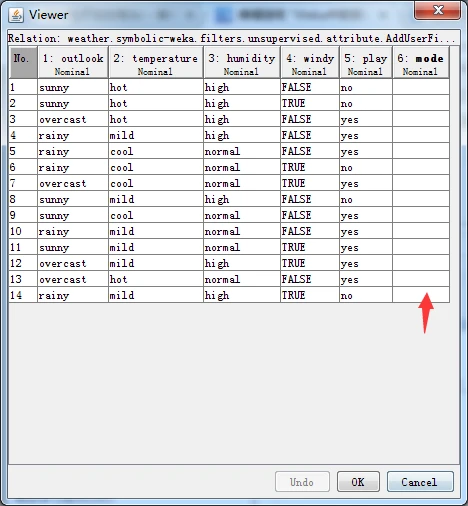
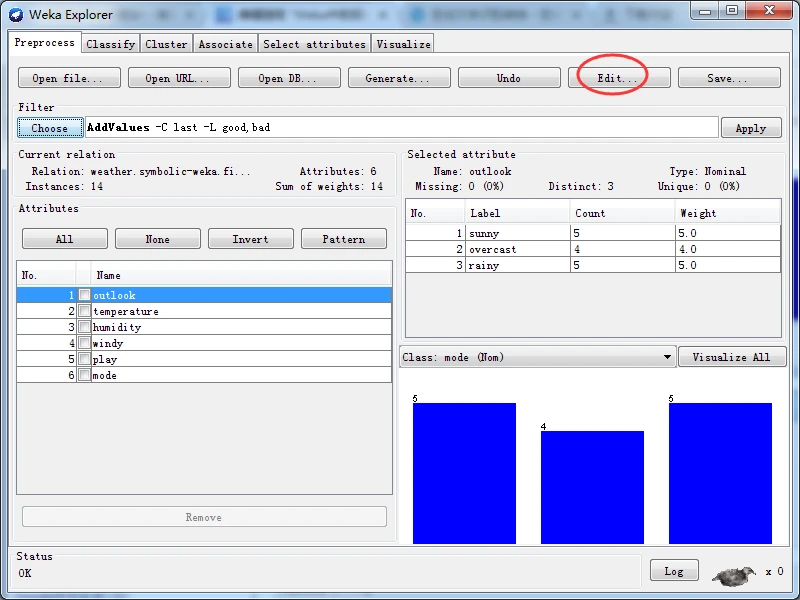
如果单击Edit按钮打开viewer窗口,可以看到新增的属性并没有值,因此,下一步是添加标称属性值。
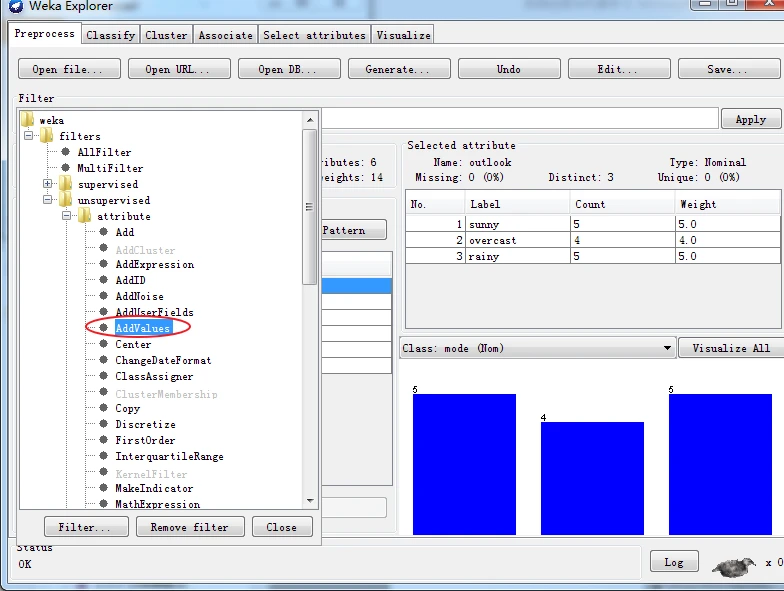
再次,单击Choose按钮,选择AddValues过滤器,按照下图所示设置标称属性的标签。
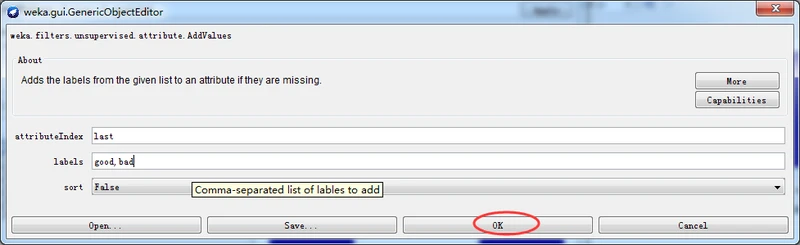
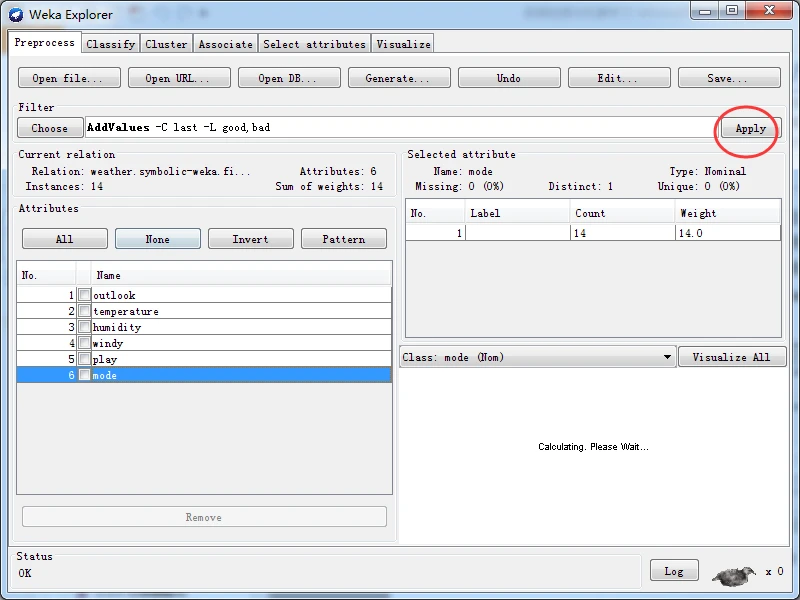
再次单击Edit按钮打开Viewer对话框,如下图所示。可以看到,这次的最后一个属性已经有了标称属性标签,可以随意设置一些值,然后单击OK按钮关闭对话框。
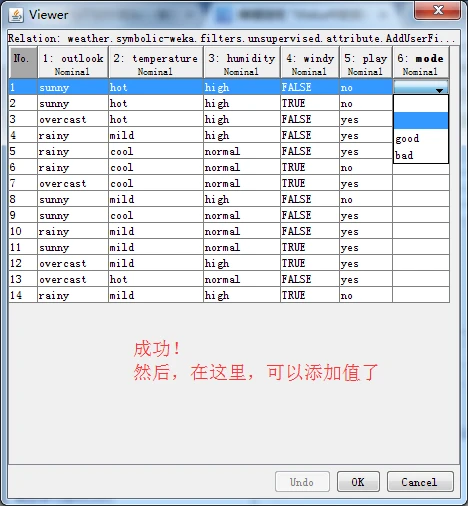
注意:我们新增属性的位置,不符合要求的倒数第二个属性位置。最后一个属性一般是类别属性,需要把第五个属性与第六个属性对换一下,则,该怎么对换呢?得用到Recorder过滤器,参数为"-R 1,2,3,4,6,5”。
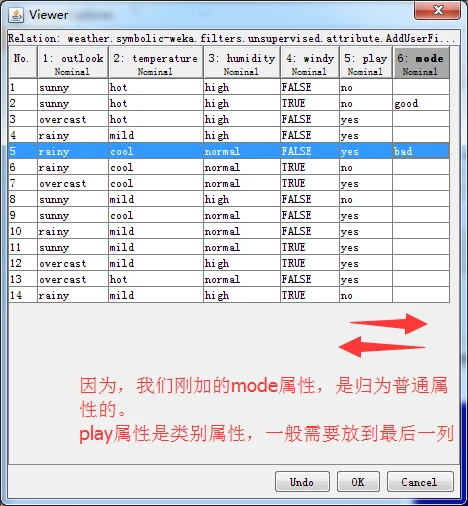
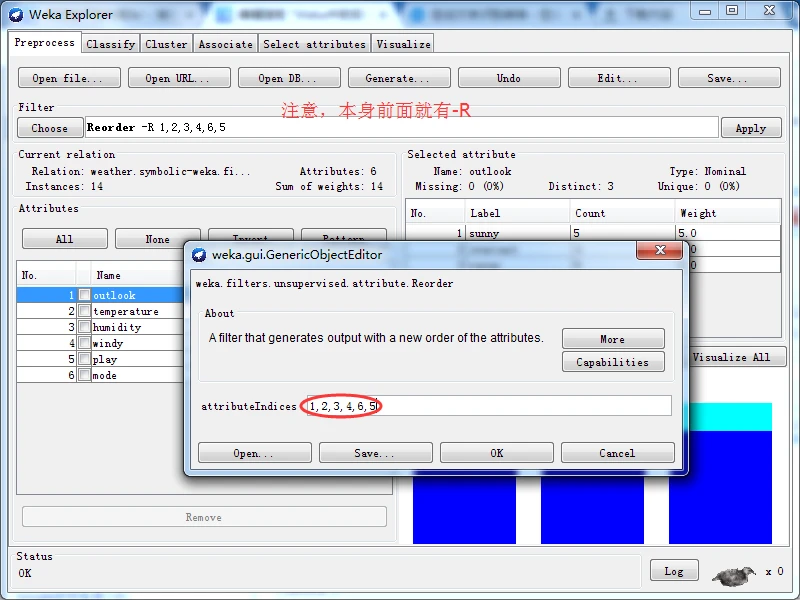
我们只需,输入1,2,3,4,6,5即可。然后点击OK
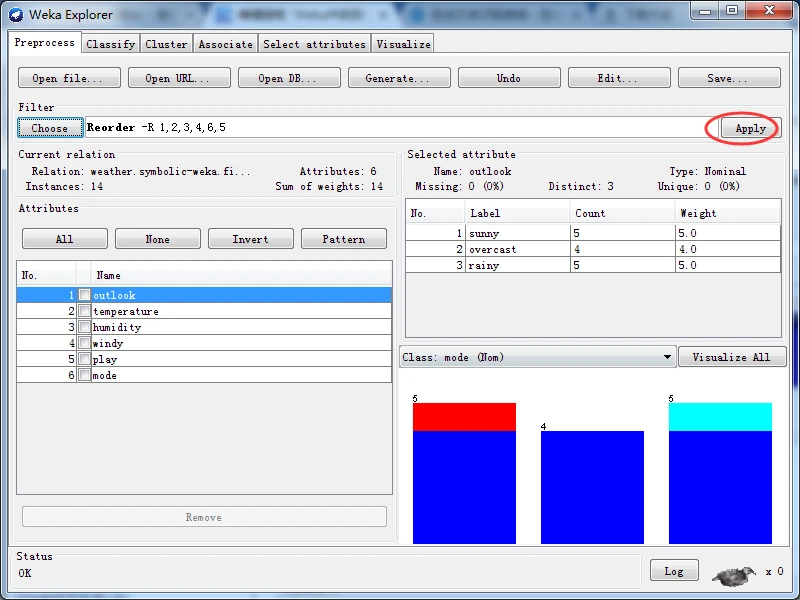
再点击Apply
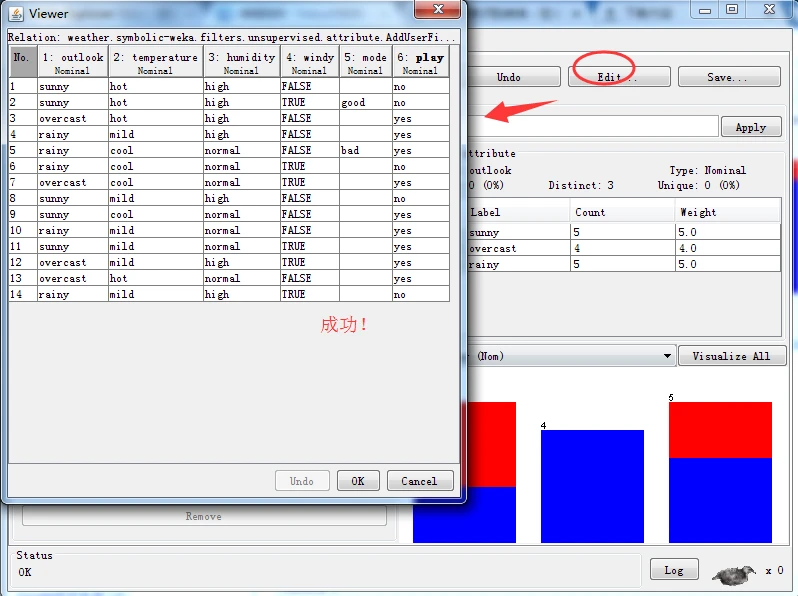
再点击Edit按钮打开Viewer对话框去看看
4.离散化
如果数据集包含数值属性,但所的学习方案只能处理标称型属性的分类问题,先将数值属性进行离散化是必要的,这样就能使学习方案增加处理数值属性的能力,通常能获 得较好的效果。
有两种类型的离散化技术------无监督离散化和有监督离散化,无监督离散化不需要也不关注类别属性值,有监督离散化在创建间隔时考虑实例的分类属性值。离散化数值属性的直观方法是将值域分隔为多个预先设定的间隔区间。显然,如果分隔级别过大,将会混淆学习阶段可能有用的差别;如果分级算法不妥,则会将很多不同类别的实例混合在一起影响学习。Weka 无监督离散化数值属性的 Java 类是 weka.filters.unsupervised.attribute.Discretize,它实现了等宽(默认)和等频两种离散化方法。
等宽离散化(或称为等宽分箱)经常造成实例分布不均匀,有的间隔区域内(箱内)包含很多个实例,但有的却很少甚至没有。这样会降低属性辅助构建较好决策结果的能力。通常也允许不同大小的间隔区域存在,从而使每个区间内的训练实例数量相等,这样的效果会好一些,该方法称为等频离散化(或称为等频分箱),其方法是:根据数轴上实例样木的分布将属性区间分隔为预先设定数量的区间。如果观察结果区间的直方图,会发现其形状平直。等频分箱与朴素贝叶斯学习方案一起应用时效果较好。但是,等频分箱也没有注意实例的类别属性,仍有可能导致不好的区间划分。例如,如果一个区域内的全部实例都属于—个类别,而下一个区域内除了第一个实例外都属于前一个类别,其余的实例都属于另一 个类别,那么,显然将第一个实例包含到前一个区域更为合理。
无监督离散化
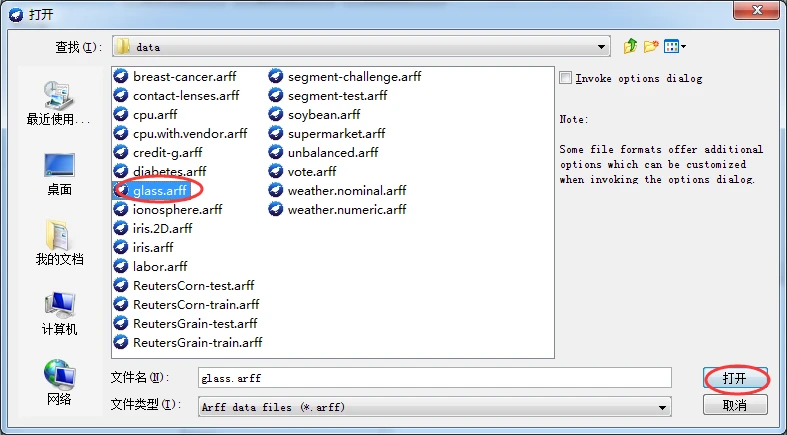
下面以实例说明这两种方法的差异。首先,在data目录中查找到玻璃数据集glass.arf文件,并将它加载至探索者界面,在预处理面板中杳看RI属性直方图,如下图所示。
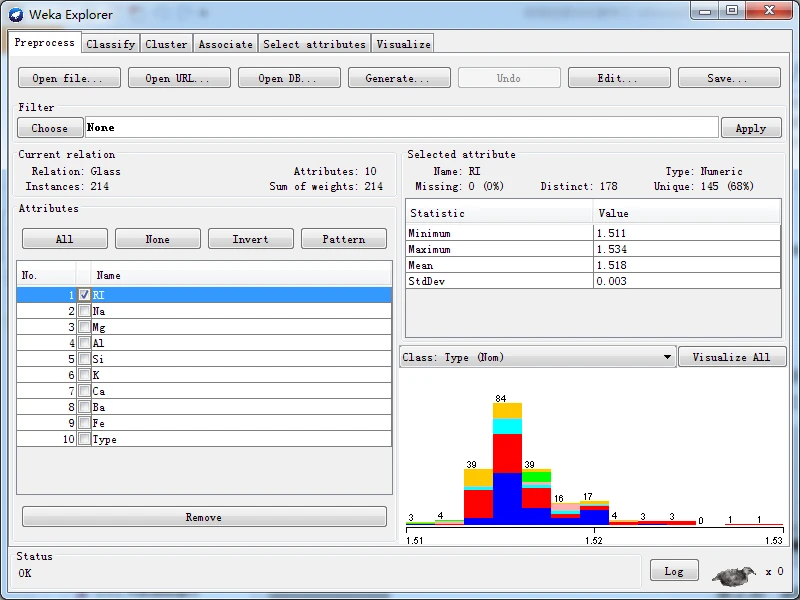
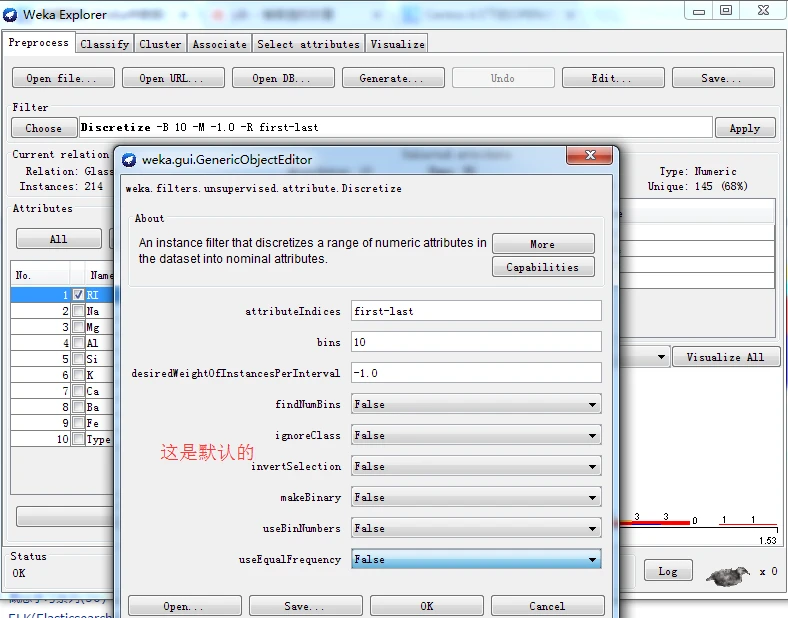
实施无监督离散化过滤器,分别使用等宽和等频两种离散化方法,即首先保持Discretize的全部选项默认值不变,然后将useEqualFrequency选项的值更改为True。得到离散化后对应的RI属性直方图分别如下图所示。
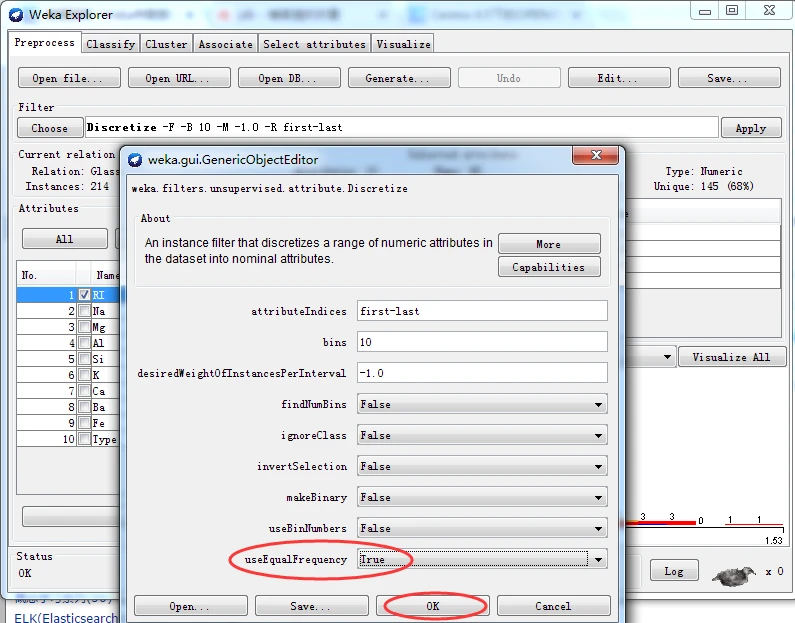
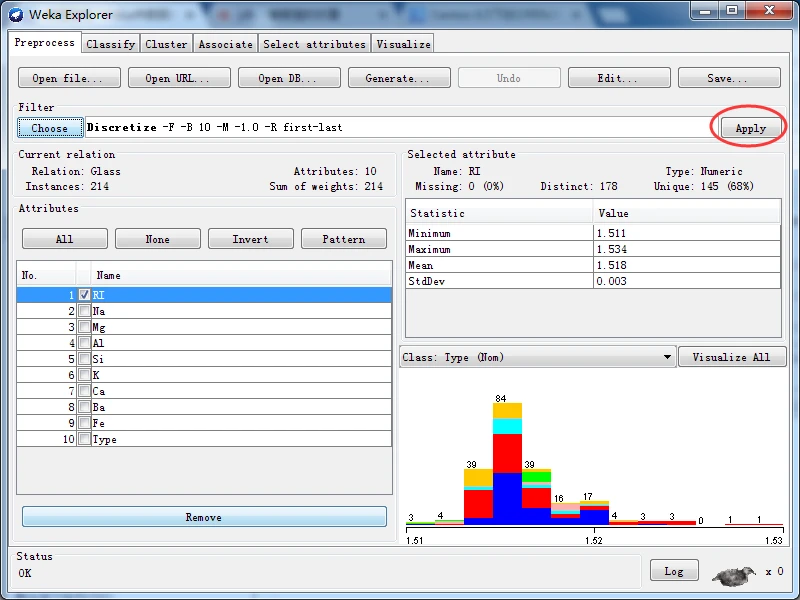
以下是等频离散化后的RI属性(将useEqualFrequency选项的值更改为True)
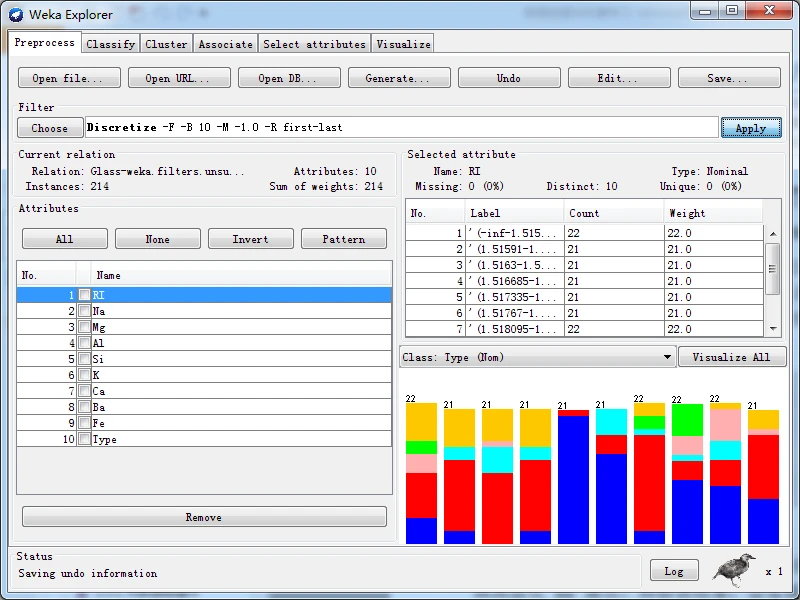
以下是等宽离散化后的RI属性(将useEqualFrequency选项的值更改为true,再次开启就可以了)
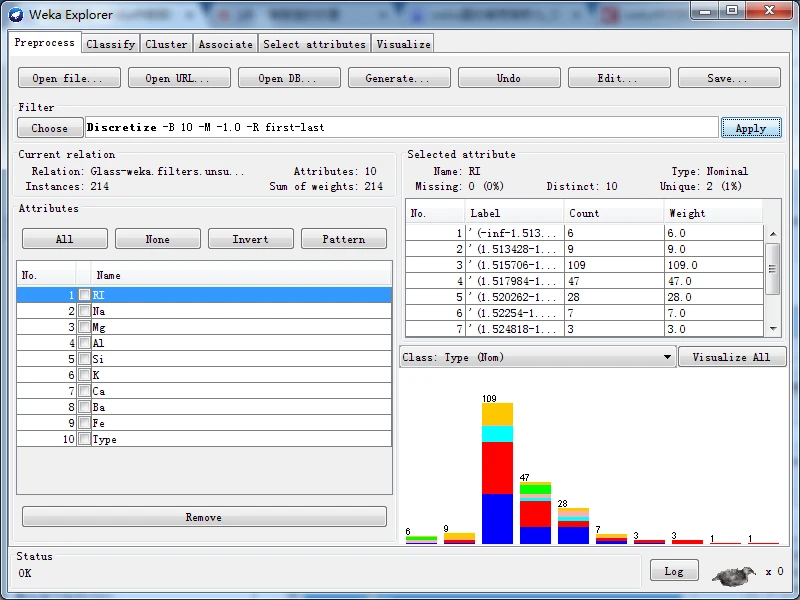
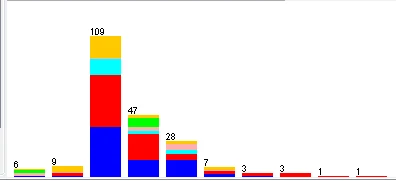
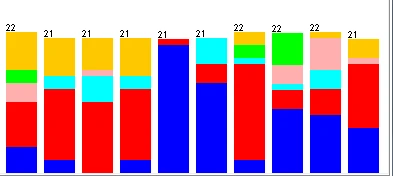
等宽离散化后的RI属性 等频离散化后的RI属性
等宽离散化数值属性从最小值到最大值之间平均分为十份,因此每一份所包含的实例数量就各不相等;而等频离散化按数值属性的大小顺序将全部实例平均分为十份,每份所包含是实例数量为21~22。
大家,也许会形成一个错觉,等频离散化后形成的直方图似乎都会等高。但是,如果等频离散化Ba属性,再检查结果,会发现这些直方图严重地偏向一端,也就是根本不等频。
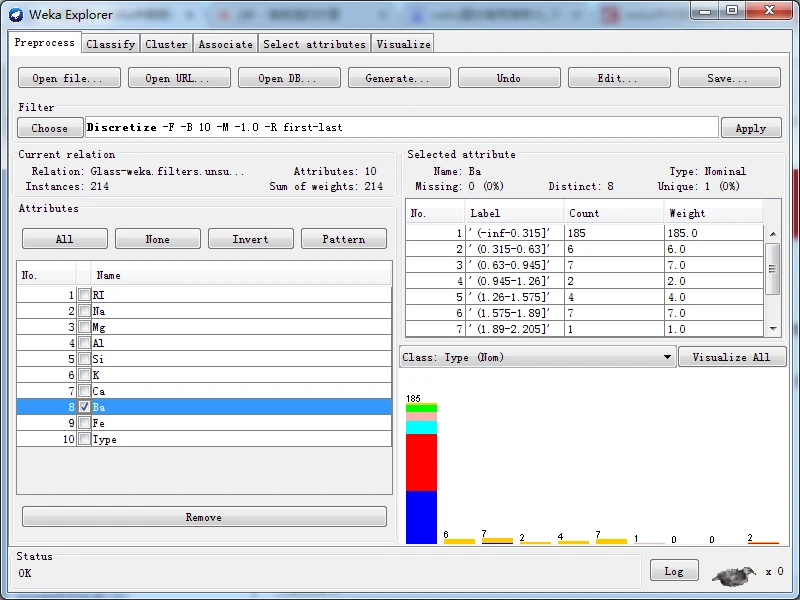
这是为什么呢?仔细观察第一个直方图的标签,其值为(-inf-0.03】,即区间大于负无穷且小于等于0.03。使用数据集编辑器打开离散化前的原始数据集,单击第八列表头,使数据集按照Ba属性进行排序,可以看到,有176个实例的Ba属性值都等于0.0。由于这些值都完全相同,没有办法将它们分开。这就是为什么,上图严重地偏向一端的根本原因。
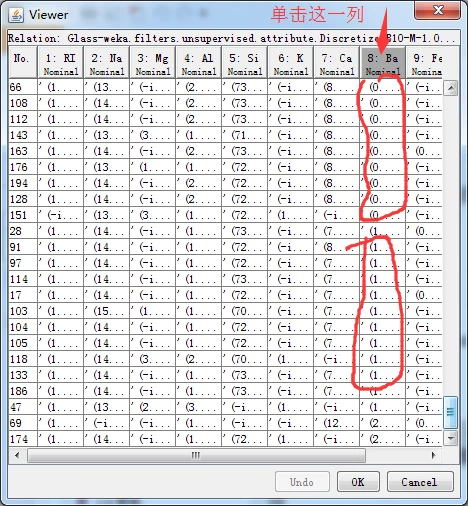
总结:一般情况下,等频离散化后直方图大致等高。但如果有很多实例的值都完全相同,则等频离散化也没法做到“等频”。
有监督离散化
有监督的离散化竭力去构建一种间隔,虽然各个间隔之间的分类分布各不相同,但间隔内的分布保持一致。Weka有监督的离散化数值属性的java类的全路径名称为weka.filters.supervised.Discretize。首先,定位到data目录下的鸢尾花数据集,加载iris.arff文件,施加有监督的离散化方案,观察得到的直方图如下图所示。
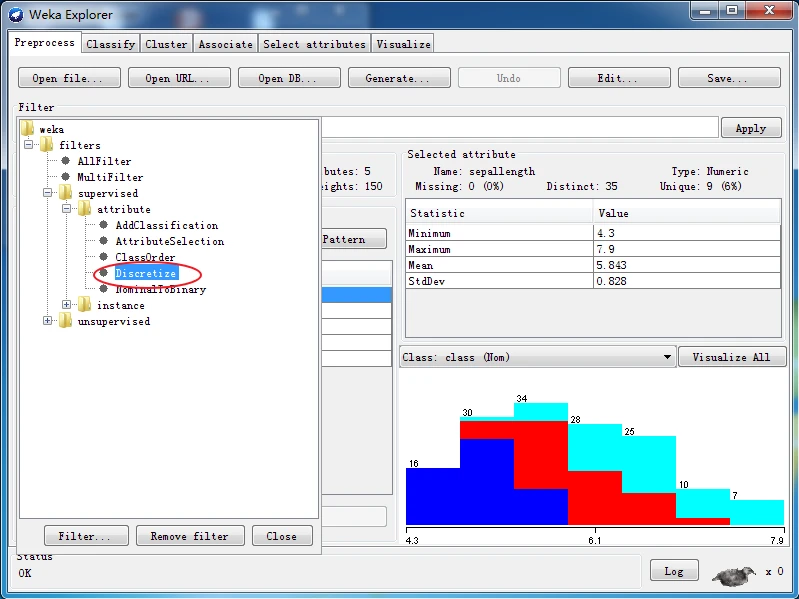
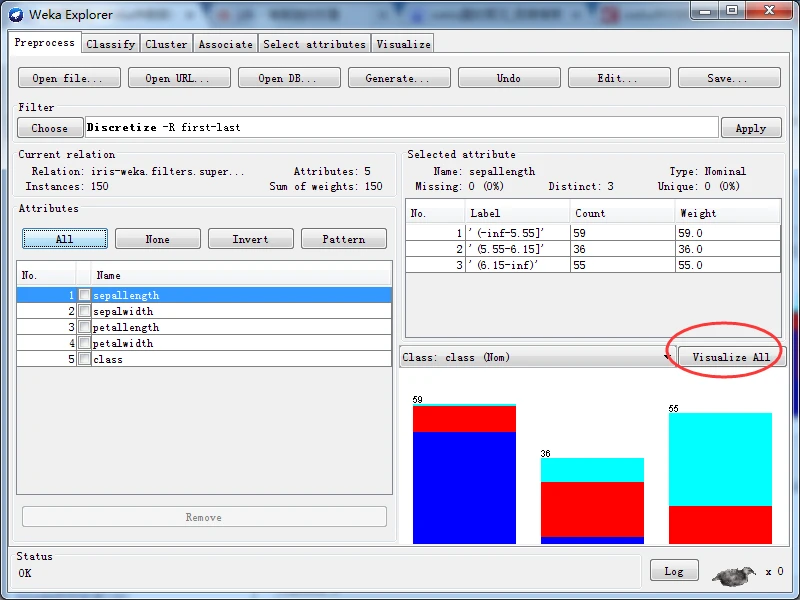
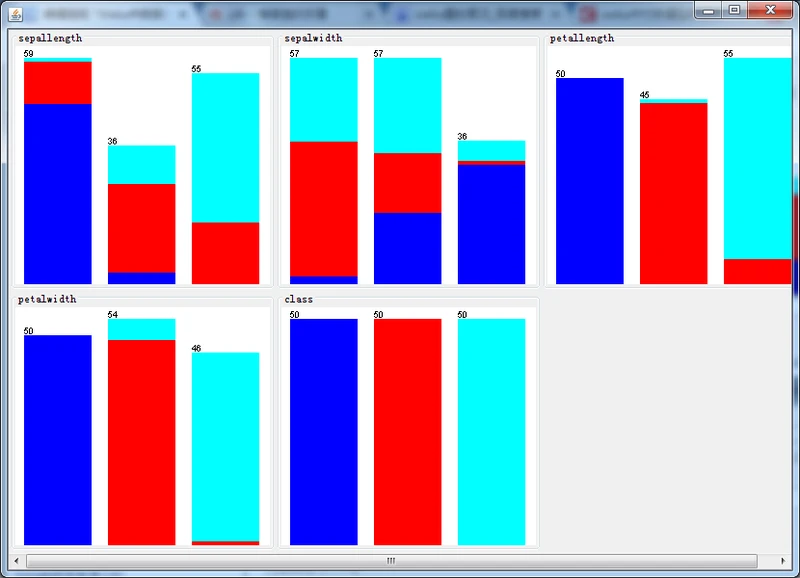
有监督离散化后的直方图
那么,上图中哪一个经过离散化后的属性最具有预测能力?
显然,只有petallength(花瓣长)和petalwidth(花瓣宽)最具竞争力,因为它们的每种分类都已经接近为同一种颜色。
再经仔细对比发现在前者中,有1个virginica实例错分到versicolor中,有6个实例versicolor错分到virginica中,因此共有7个错分的实例;
而后者,只有5个virginica实例错分到versicolor中,有1个versicolor实例错分到virginica 中,因此共有6个错分的实例。
从而得出结论:离散化后的petalwidth属性最具有预测能力。
通常将离散化后的属性编码为标称属性,每一个范围给定一个值。然而,因为范围是 有序的,离散化后的属性实际上是一个有序标量。
除了创建多元属性外,有监督和无监督两种离散化过滤器都能创建二元属性,只要将选项makeBinary设置为True即可。下图就是有监督的离散化方案创建二元属性后得到。
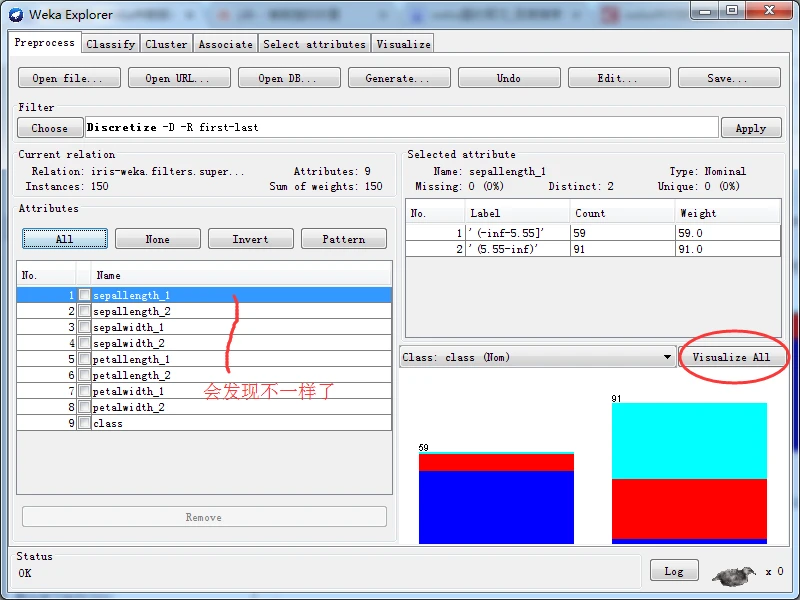
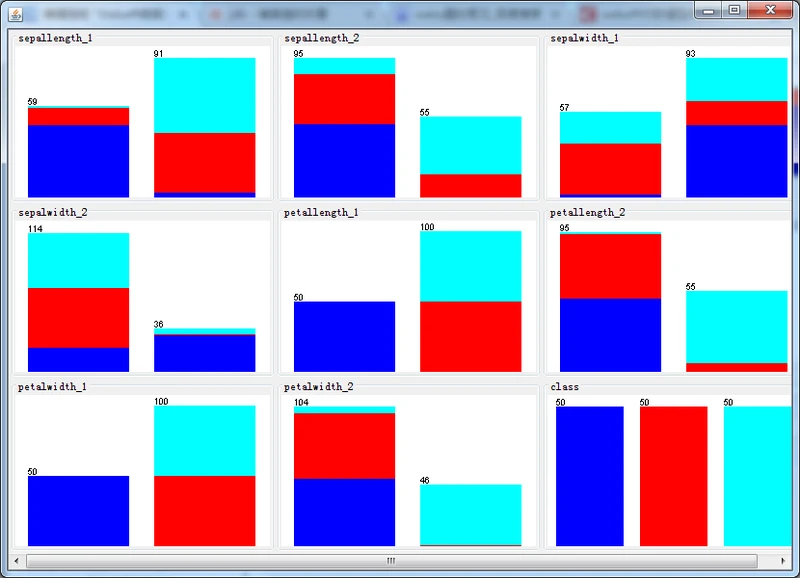
有监督二元离散化后的直方图
分类
分类就是得到一个分类函数或分类模型(即分类器),通过分类器将未知类别的数据对象映射到某一个给定的类别。
数据分类可以分为两步。第一步建立模型,通过分析属性描述的数据集,来建立反映其特性的模型。该步骤也称为有监督的学习,基于训练集而导出模型,训练集是已知类别标签的数据对象。第二步使用模型对数据对象进行分类。首先评估模型的分类准确度或其他指标,如果可以接受,才使用它来对未知类别标签的对象进行分类。
预测的目的是从历史数据记录中自动推导出对给定数据的推广描述,从而能够对事先未知类别的数据进行预测。分类和回归是两类主要的预测问题,分类是预测离散的值,回归的预测连续值。
Weka提供分类面板来构建分类器。如下图所示。
在分类面板的最上部是Classifier(分类器)子面板,子面板内有一个Choose按钮和一个文本框。按钮用于选择Weka提供的分类器;文本框用于显示当前选择的分类器的名称和选项。单击文本框会弹出一个通用对象编辑器对话框,与过滤器的对象编辑器对话框的功 能一样,可以用来设置当前分类器的选项。右击(或用Alt + ShifH单击)分类器文本输入框,就会弹出一个菜单,选择菜单项可以让用户修改设置,或将当前设置的字符串复制到剪贴板,或直接输入设置字符串,使用方法与过滤器的相似。
在分类面板的左部有Test options(测试选项)子面板。该子面板是为了设置测试模式, 将设置的选项应用到当前选择的分类器中。测试模式分为以下四种。
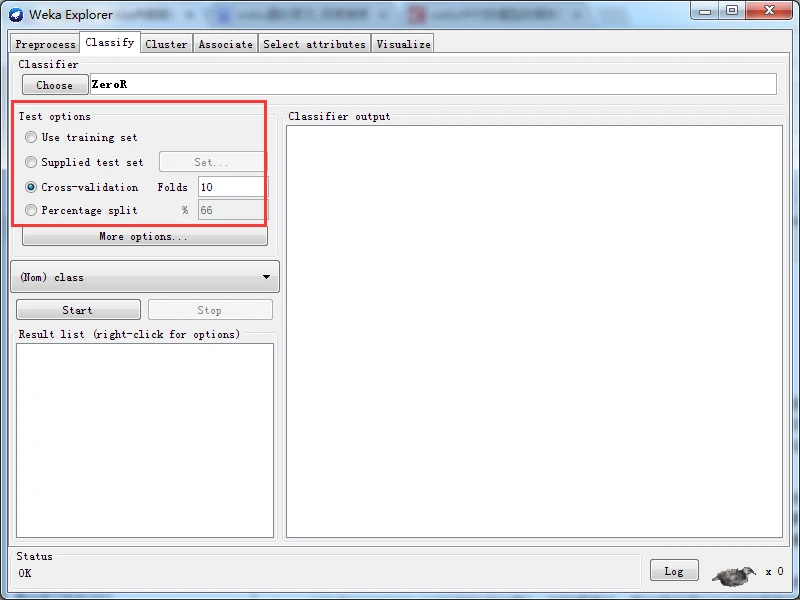
(1) Use training set(使用训练集)。直接将训练集实例用于测试,评估分类器预测类别的性能。
(2) Supplied test set(提供测试集)。从一个文件中加载一组实例,评估分类器预测类别的性能。单击Set按钮会弹出一个对话框,允许用户选择进行测试的文件。
(3) Cross-validation(交叉验证)。通过交叉验证评价分类器,在提示为Folds的文本框中输入交叉验证的折数。
(4) Percentage split(按比例分割)。在数据集中,取出特定百分比的数据用于训练,其 余的数据用于测试,评价分类器预测分类的性能。取出的数据量取决于用户在“%”文本 框中输入的值。
无论使用哪种测试模式作为评估方法,输出模型始终从全部训练数据构建而得。更多的测试选项可以通过单击More options按钮进行设置,如下图所示。
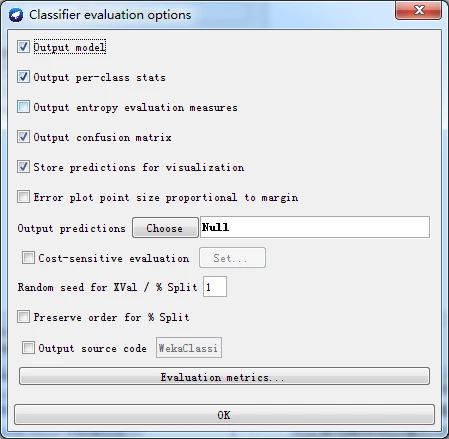
图 更多测试选项
更多的测试选项解释如下
(1) Output model(输出模型)。输出通过完整训练集得到的分类模型,以便能够浏览、 可视化等。默认选择此选项。
(2) Output per-class stats(输出每个类别的统计信息)。输出每个分类的査准率/查全率以 及True/False的统计信息。默认选择此选项。
(3) Output entropy evaluation measures(输出熵评估度量)。输出中包括熵评估度量。默认不选择此选项。
(4) Output confusion matrix(输出混渚矩阵)。输出中包含分类器预测得到的混淆矩阵。 各默认选择此选项。
(5) Store predictions for visualization(存储预测以便可视化)。保存分类器的预测结果,以便用于可视化。默认选择此选项。
(6) Output predictions(输出预测)。输出预测的评估数据。请注意,在交叉验证的情况 下,实例序号不对应于其在数据集中的位置。
(7) Output additional attributes(输出额外的属性)。如果伴随预测还需要输出额外的属性 (如,跟踪错误分类的1D属性),可以在这里指定该属性的索引。Weka通常支持指定范 围,first和last也是有效的索引,例如:“first-3,6,8,12-last”。
(8) Cost-sensitive evaluation(成本敏感评估成本矩阵用于评估错误率。Set按钮允许 用户指定所使用的成本矩阵。
(9) Random seed for XVal / % Split(XVal / %分割的随机种子)。为了评估目的而划分数 据之前,指定将数据进行随机化处理的随机种子。
(10) Preserve order for % Split(保持顺序按百分比分割)。将数据划分为训练集和测试集 之前禁止随机化,即保持原来的顺序。
(11) Output source code(输出源代码)。如果分类器能够输出所构建模型的Java源代 码,可以在这里指定类名D可以在Classifier output(分类器输出)区域打印代码。
在Weka中,进行训练后的分类器用于预测某个单一的类别属性,这就是预测的目标。一些分类器只能学习标称型类别的分类(分类问题),一些分类器只能学习数值型类别的分类(回归问题),还有一些分类器能学习两者。
默认情况下,数据集的最后一个属性是类别属性。如果想训练分类器来预测其他属性,单击Test options子面板下面的下拉列表框,选择其他属性作为类别属性。
2、分类器训练
设置好分类器、测试选项和分类属性后,单击Start按钮就启动学习过程。在Weka忙于训练分类器的同时,小鸟会站起来左右走动。用户随时可以单击Stop按钮终止训练过程。
训练结束后,右侧的分类器输出区域会显示训练和测试结果的文字描述,如下图所示。同时,在Result list(结果列表)中会出现一个新条目,后文再谈结果列表,先仔细分析分类器输出的文字描述。
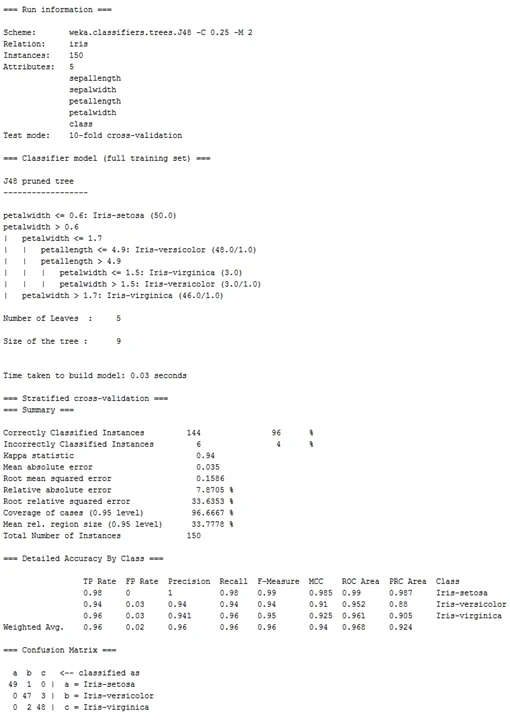
3、分类器输出
拖动Classifier output区域右侧的滚动条,可以浏览全部结果文本。在文本区域中按住Alt键和Shift键的同时单击,会弹出一个对话框,可以以各种不同的格式(目前支持BMP、JPEG、PNG和EPS)保存所显示的输出。当然,也可以调整探索者界面的大小,得到更大的显示面积。
输出分为以下几个部分。
(1) Run information(运行信息):提供处理过程所涉及的信息列表,如学习方案及选项(Scheme)、关系名(Relation)、实例(Instances)、属性(Attributes)和测试模式(Test mode)。
(2) Classifier model(full training set)(分类器模型(完整的训练集)):完整训练数据生成的分类模型的文字表述。本例选择J48决策树构建分类模型,因此以文字方式描述决策树。如果选择其他分类器模型,则显示相应的文字表述。
(3) 根据所选择的测试模式,显示不同文字。例如,如果选择十折交叉验证,显示Stratified cross-validation;如果选择使用训练集,显示Classifier model (full training set),等等。由于评估内容较多,将结果分解显示如下。
①Summary(总结)。一个统计列表,根据所选抒的测试模式,总结分类器在预测实例真实分类的准确度,其中:
• Comictly Classified Instances(正确分类的实例):显示正确分类的实例的绝对数里和百分比。
• Incorrectly Classified Instances(错误分类的实例):显示错误分类的实例的绝对数和百分比。
• Kappa statistic(kappa 统计):显示示kappa 统计量,[0,1]范围的小数。kappa 统计指标用于评判分类器的分类结果与随机分类的差异度。k=1表明分类器完全与随机分类相异,K=0表明分类器与随机分类相同(即分类器没有效果),K= -1表明分类 器比随机分类还要差。一般来说,Kappa统汁指标的结果是与分类器的AUC指 标以及准确率成正相关的,所以该伉越接近1越好。
• Mean absolute errror(平均绝对误差):品示平均绝对误差,[0,1]范围的小数。
• Root mean squared error(均方根设差}:显示均方根误差,[0,1]范围的小数。
• Relative absolute enor(相对绝对误差):显示相对绝对误整,百分数。
• Root relative squared error(相对均方根误差):显示相对均方根误差,百分数。
• Coverage of cases (0.95 levelX)(案例的覆盖度):显示案例的覆盖度,该值是分类器使用分类规则对全部实例的薄盖度,百分数越高说明该规则越有效。
• Mean rel. region size (0.95 level)(平均相对区域大小):显示平均相对区域大小, 百分数。
• Total Number of Instances(实例总数):品示实例总数。
②Dctai丨ed Accuracy By Class(按类别的详细准确性)。按每个类别分解的更详细的分类器的预测精确度。结果以表格形式输出,其中,表格列的含义如下,
• TP Rate(离阳性率):显示真阳性率,[0J]范IS的小数。
• FP Rate(假阳性率):51示假阳性率.队丨]范围的小数。另外,常使用TN相FN 分别代衣具阴性率和假阴性率。



4、分类算法介绍
分类和回归是数据挖掘和机器学习中极为重要的技术,其中分类是指利用已知的观测数据构建一个分类模型,常常称为分类器,来预测未知类别的对象的所属类别。分类和回归的不同点在于,分类的预测输出是离散型类别值,而回归的预测输出是连续型数值。因此,Weka将分类和回归都归为同一类算法。
本博客介绍常用的分类算法,包括线性回归、决策树、决策规则、支持向量机,将贝叶斯网络和神经网络放到后面博客书写。由于Weka实现的分类算法数量众多,特点各异,无法在较短篇幅中讲清楚,大家可根据自己的需要查阅附录介绍和相关资料。
1. 线形回归
线性回归(linear regression)是利用数理统计中的回归分析,来确定多个变量之间相互依赖的定量关系的一种统计分析方法,应用十分广泛。具体来说,它利用称为线性回归方程的最小二乘函数对一个或多个自变量(常表示为x)和一个标量型因变量(常表示为y)之间的关系进行建模,这种函数是一个或多个称为回归系数的模型参数的线性组合。只涉及一个自变量的称为简单线性回归,涉及多个自变量的称为多元线性回归。
线性回归的主要目标是用于预测。线性回归使用观测数据集的y值和x值来拟合一个预测模型,构建这样一个模型后,如果给出一个新的x值,但没有给出对应的y值,这时就可以用预测模型来预测y值。
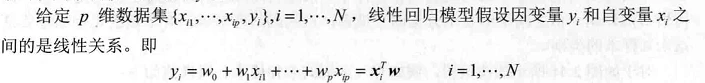
2. 决策树
决策树(decision tree)是一种预测模型,它包括决策节点、分支和叶节点三个部分。其中,决策节点代表一个测试,通常代表待分类样本的某个属性,在该属性上的不同测试结果代表一个分支,分支表示某个决策节点的不同取值。每个叶节点存放某个类别标签,表示一种可能的分类结果,括号内的数字表示到达该叶节点的实例数。
使用训练集用决策树算法进行训练,经过训练之后,学习方案只需要保存类似于如下图的树形结构,而不像最近邻学习等消极学习算法那样,不保存模型,只有在需要分类时才去查找与测试样本最为相近的训练样本。决策树对未知样本的分类过程是,自决策树根节点开始,自上向下沿某个分支向下搜索,直到到达叶节点,叶节点的类别标签就是该未知样本的类别。
对于下图所示的决策树,假如有一个新的未知样本,属性值如下:




3. 基于规则的分类器


4. 基于实例的算法
基于决策树的分类框架包括两个步骤:第一步是归纳步,由训练数据构建分类模型;第二步是演绎步,将模型应用于测试样本。前文所述的决策树和基于规则的分类器都是先对训练数据进行学习,得到分类模型,然后对未知数据进行分类,这类方法通常称为积极学习器(eager learner)。与之相反的策略是推迟对训练数据的建模,直到需要对未知样本进行分类时才进行建模,采用这种策略的分类器称为消极学习器(lazy learner)。消极学习器的典型代表是最近邻方法,其途径是找出与测试样本相对接近的所有训练样本,这些训练样本称为最近邻(Nearest Neighbor,NN),然后使用最近邻的类别标签来确定测试样本的类别。


5. 支持向量机
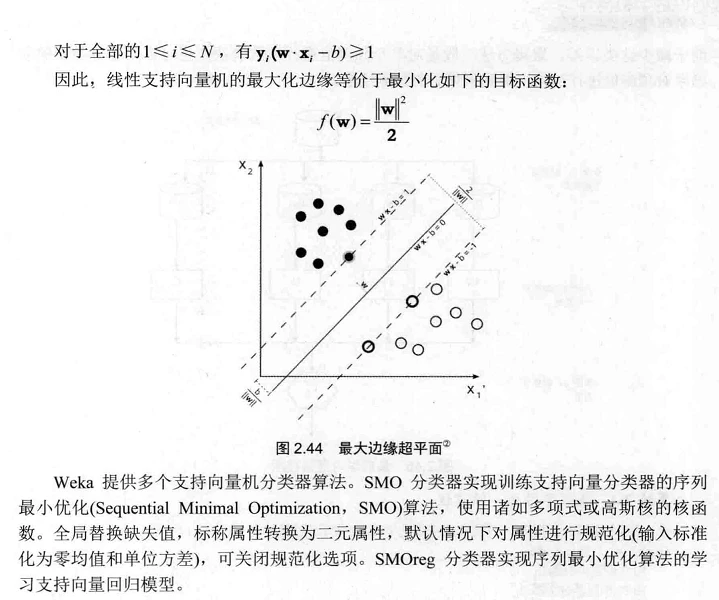
支持向量机(Support Vector Machine,SVM)分类器是一种有监督学习的方法,广泛地应用于统计分类以及回归分析。SVM的特点是能够同时最小化经验误差与最大化几何边缘。因此,支持向量机也被称为最大边缘分类器。
支持向量机技术具有坚实的统计学理论基础,并在实践上有诸多成功示例。SVM可以很好地用于高维数据,避免维数灾难。它有一个独特的特点,就是使用训练实例的一个子集来表示决策边界,该子集称为支持向量,这就是其名称的来历。


6. 集成学习
集成学习(ensemble learning)就是通过聚集多个分类器的预测结果来提高分类准确率。集成方法由训练数据构建一组基分类器(base classifier),然后通过每个基分类器的预测的投票来进行分类。一般来说,集成分类器的性能要好于任意的单个分类器,因为集体决策在全面可靠性和准确度上优于个体决策。




5 分类模型评估
1. 定性评估标准
一般来说,分类模型有如下评估标准。
(1) 预测的准确率:模型正确地预测新的或先前没见过的样本的类别标签能力。
(2) 速度:产生和使用模型的计算开销。
(3) 强壮性:对于有噪声或具有缺失值的样本,模型能正确预测的能力。
(4) 可伸缩性:给定很大的数据集,能有效地构造模型的能力。
(5) 可解释性:学习模型提供的理解和解释的层次。
预测的准确率常用于比较和评估分类器的性能,它将每个类别看成同等重要,因此可能不适合用来分析不平衡数据集。在不平衡数据集中,稀有类别比多数类别更有意义。也就是说,需要考虑错误决策、错误分类的代价问题。例如,在银行贷款决策中,贷款给违规者的代价远远比由于拒绝贷款给不违规者而造成生意损失的代价大得多;在诊断问题中,将实际没有问题的机器误诊为有问题而产生的代价比因没有诊断出问题而导致机器损坏而产生的代价小得多。



手把手教你使用Weka的分类器(完整)
- 1. 使用C4. 5分类器
- 2. 使用分类器预测未知数据
- 3. 使用决策规则
- 4. 使用线性回归
- 5. 使用用户分类器
- 6. 使用支持向量机
- 7. 使用元学习器
- 8. 深入研究离散化
- 9. 初识最近邻分类器
- 10. 分类噪声与最近邻学习
- 11. 研究改变训练集大小的影响
1、使用C4.5分类器(名称为J48)
本例使用C4.5分类器对天气数据集进行分类。
首先加载天气数据集,操作步骤为:启动探索者窗口,在预处理面板中单击Open file按钮,选择并打开data目录中的weather.nominal.arff文件,然后,单击Classify标签页切换到Classify面板。
从上面的学习中,我们可以自动,构建决策树的C4.5算法在Weka中是作为一个分类器来实现,名称为J48。单击Classfiy面板上部的Choose按钮,会出现一个对话框,显示不同类型的分类器。单击tress条目以展开其子条目,然后单击J48选择该分类器。与过滤器一样,分类器也按层次进行组织,J48的全名为weka.classifiers.tress.J48。
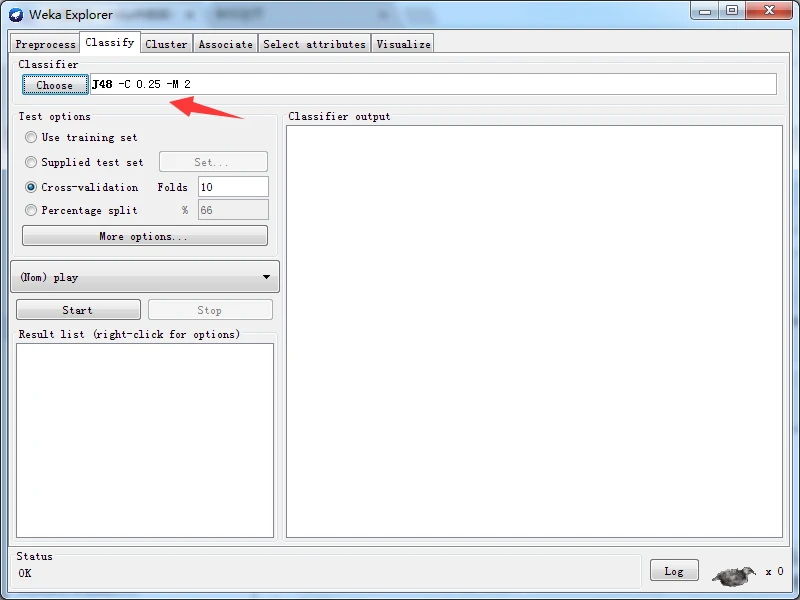
在Choose按钮旁边的文本框内,可以看到当前分类器及选项:J48 -C 0.25 -M 2。这是此分类器默认的参数设置。对于J48分类器,很少需要为获得良好的性能而更改这些参数。
为了便于说明,使用训练数据进行性能评估,训练数据在预处理面板就已经完成加载。使用训练数据进行评估并不是一个好方法,是因为它导致盲目乐观的性能估计。从分类面板中Test options(测试选项)部分,选择Use training set(使用训练集)选项,以确定测试策略。做好上述的准备之后,可以单击Start(开始)按钮,启动分类器的构建和评估,使用当前选择的学习算法----J48,通过训练集构建J48分类器模型。然后,使用构建的模型对训练数据的所有实例进行分类以评估性能,并输出性能统计信息,如下图所示。
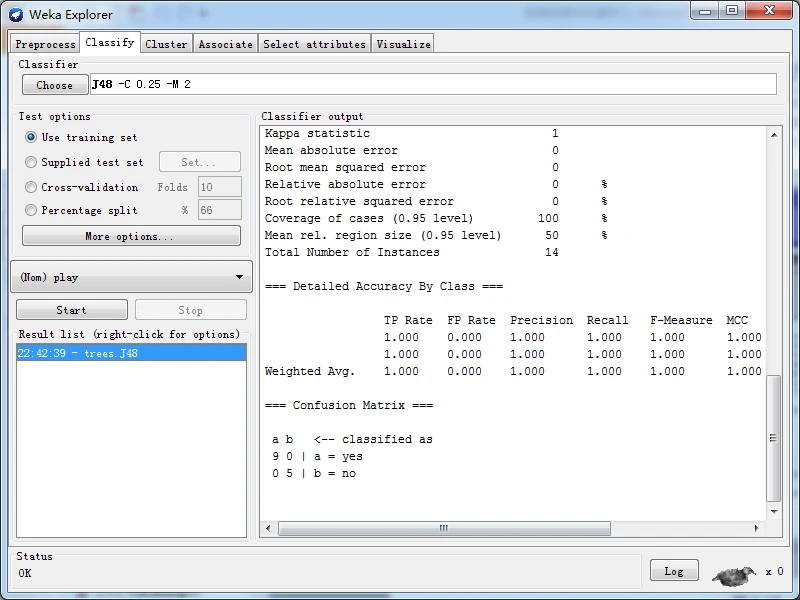
=== Run information === Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2 Relation: weather.symbolic Instances: 14 Attributes: 5 outlook temperature humidity windy play Test mode: evaluate on training data === Classifier model (full training set) === J48 pruned tree ------------------ outlook = sunny | humidity = high: no (3.0) | humidity = normal: yes (2.0) outlook = overcast: yes (4.0) outlook = rainy | windy = TRUE: no (2.0) | windy = FALSE: yes (3.0) Number of Leaves : 5 Size of the tree : 8 Time taken to build model: 0.03 seconds === Evaluation on training set === Time taken to test model on training data: 0.02 seconds === Summary === Correctly Classified Instances 14 100 % Incorrectly Classified Instances 0 0 % Kappa statistic 1 Mean absolute error 0 Root mean squared error 0 Relative absolute error 0 % Root relative squared error 0 % Coverage of cases (0.95 level) 100 % Mean rel. region size (0.95 level) 50 % Total Number of Instances 14 === Detailed Accuracy By Class === TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 yes 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 no Weighted Avg. 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 === Confusion Matrix === a b <-- classified as 9 0 | a = yes 0 5 | b = no