
1.是什么?
池化(Pooling)是深度学习中常用的一种操作,它用于减小特征图的尺寸并提取对输入特征具有鲁棒性的相关信息。池化操作是在特征图上进行的,通过将特征图划分为不重叠的区域,然后对每个区域进行汇聚操作来获得池化后的特征值。
常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化选择每个区域中的最大值作为该区域的池化结果,而平均池化计算每个区域中特征值的平均值作为池化结果。
池化操作的主要作用是减小特征图的尺寸,从而减少参数数量和计算量,同时具有平移不变性和部分尺度不变性。这些特性使得池化操作能够有效地提取图像、语音等数据的局部不变性特征。
2.为什么?
池化(Pooling)层和卷积层、全连接层一样,都是卷积神经网络的组成部分。
卷积神经网络中的卷积层会将卷积Filter应用于输入图像,以便创建特征映射来总结输入中这些特征的存在。
卷积层被证明是非常有效的,在深层模型中叠加卷积层可以让接近输入的层学习低层特征(如线条),在模型中更深(高)的层用于学习高阶或者更抽象的特征,如形状或特定对象。
卷积层特征映射输入的一个局限性是它们只能精确记录特征在输入层的位置。这意味着在输入图像中特征位置的小幅移动将导致不同的特征映射。这可以随着重新裁剪、旋转、移动以及输入图像的其他的微小变化而发生。
因此,我们将信号处理中所用的一种叫做下采样的方法应用于卷积神经网络用于解决上述问题。通过改变卷积在图像上的跨步长(stride),可以用卷积层实现下采样。一个更加robust和common的方法是使用池化层(pooling)。
主要功能有以下几点:
-
抑制噪声,降低信息冗余
-
提升模型的尺度不变性、旋转不变形
-
降低模型计算量
-
防止过拟合
3.怎么样?
3.1 在哪里池化
池化层是在卷积层之后的一个新的层。具体而言,在一个卷积层将非线性(例如:ReLU)应用到特征映射输出之后。例如,模型中的层可能看起来如下:
Input Image 输入图像
Convolutional Layer 卷积层
Nonlinearity Activation 非线性激活函数
Pooling Layer 池化层
在卷积层后添加池化层是一种常见的操作,在一个给定模型中可以出现一次或者多次。
3.2 池化方法
(1)Max Pooling(最大池化)
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。其定义如下:
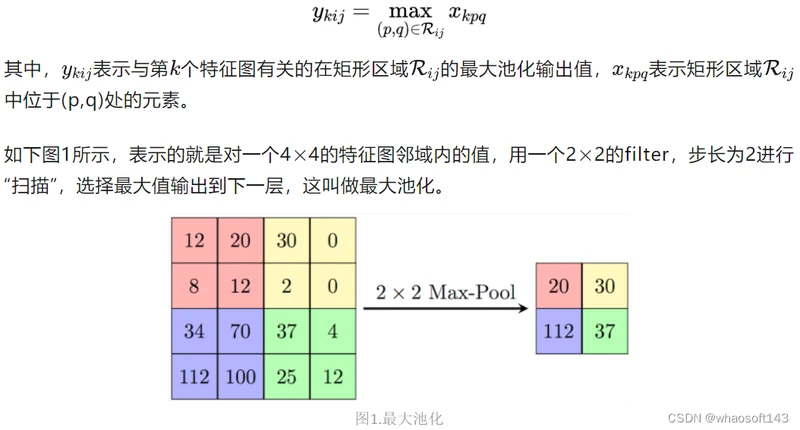
最大池化就是选择图像区域中最大值作为该区域池化以后的值,反向传播的时候,梯度通过前向传播过程的最大值反向传播,其他位置梯度为0。
使用的时候,最大池化又分为重叠池化和非重叠池化,比如常见的stride=kernel size的情况属于非重叠池化,如果stride<kernel size 则属于重叠池化。重叠池化相比于非重叠池化不仅可以提升预测精度,同时在一定程度上可以缓解过拟合。
非重叠池化一个应用的例子就是yolov3-tiny的backbone最后一层,使用了一个stride=1, kernel size=2的maxpool进行特征的提取。
示例
>>> import torch
>>> import torch.nn.functional as F
>>> input = torch.Tensor(4,3,16,16)
>>> output = F.max_pool2d(input, kernel_size=2, stride=2)
>>> output.shape
torch.Size([4, 3, 8, 8])
>>>(2)Average Pooling(平均池化)
平均池化(Average Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出所有元素的平均值。其定义如下:
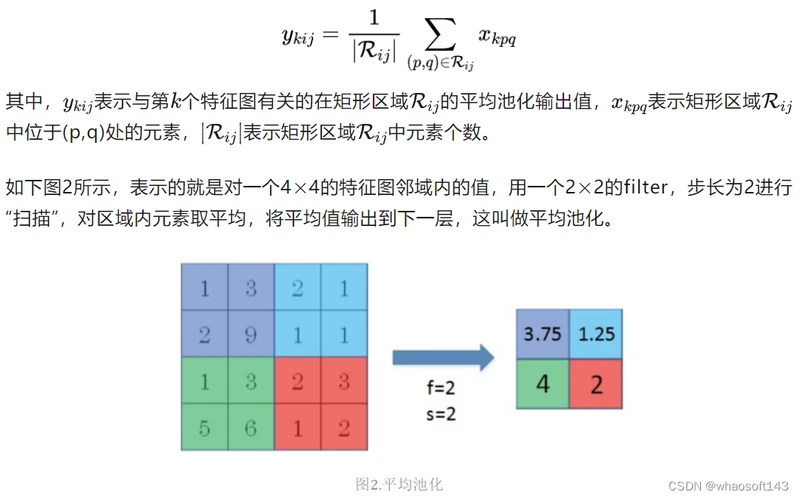
平均池化就是将选择的图像区域中的平均值作为该区域池化以后的值。
示例
>>> import torch
>>> import torch.nn.functional as F
>>> input = torch.Tensor(4,3,16,16)
>>> output = F.avg_pool2d(input, kernel_size=2, stride=2)
>>> output.shape
torch.Size([4, 3, 8, 8])
>>>(3)Global Average Pooling(全局平均池化)
论文地址: https://arxiv.org/pdf/1312.4400.pdf%20http://arxiv.org/abs/1312.4400.pdf
代码链接: https://worksheets.codalab.org/worksheets/0x7b8f6fbc6b5c49c18ac7ca94aafaa1a7
背景
在卷积神经网络训练初期,卷积层通过池化层后一般要接多个全连接层进行降维,最后再Softmax分类,这种做法使得全连接层参数很多,降低了网络训练速度,且容易出现过拟合的情况。在这种背景下,M Lin等人提出使用全局平均池化Global Average Pooling[1]来取代最后的全连接层。用很小的计算代价实现了降维,更重要的是GAP极大减少了网络参数(CNN网络中全连接层占据了很大的参数)。
定义
全局平均池化是一种特殊的平均池化,只不过它不划分若干矩形区域,而是将整个特征图中所有的元素取平均输出到下一层。其定义如下:
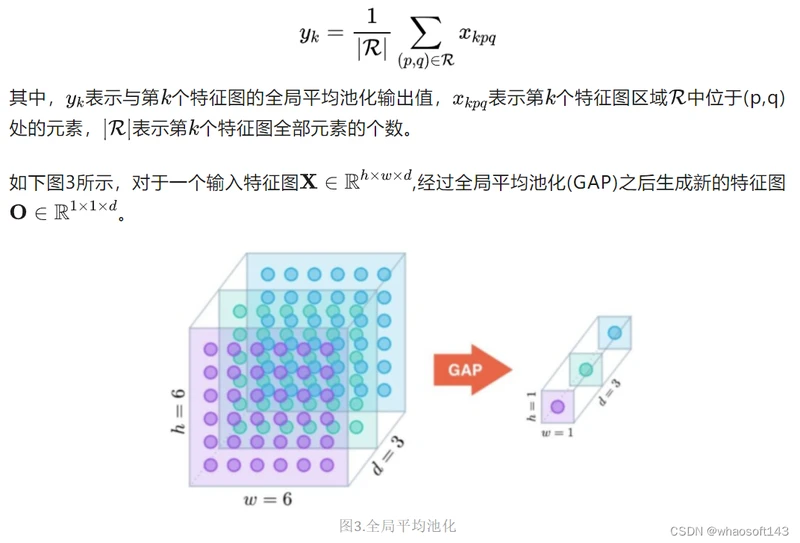
Gloabel Average Pooling 是NIN里边的做法,一般使用torchvision提供的预训练模型进行finetune的时候,通常使用Global Average Pooling,原因就是可以不考虑图片的输入尺寸,只与filter有关。
示例
>>> import torch
>>> from torch.nn import AdaptiveAvgPool2d
>>> input = torch.zeros((4,12,18,18)) # batch size, fileter, h, w
>>> gap = AdaptiveAvgPool2d(1)
>>> output = gap(input)
>>> output.shape
torch.Size([4, 12, 1, 1])
>>> output.view(input.shape[0],-1).shape
torch.Size([4, 12])
>>>(4)全局最大池化(Global max Pooling)
全局最大池化(Global Max Pooling)是一种常用的池化操作方法,用于降低特征图的空间维度。在全局最大池化中,将特征图中的每个通道的所有值取最大值,得到一个与通道数相同的向量,并将这些向量拼接在一起形成最终的特征向量。
全局最大池化的主要作用是提取图像或特征图中最显著的特征。通过取最大值,可以保留重要的特征并丢弃不重要的信息。这种操作对于图像分类、目标检测和图像分割等任务都有很好的效果。
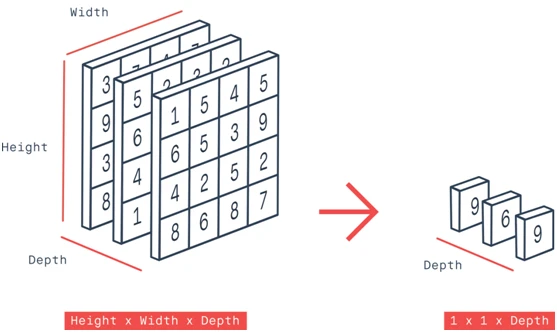
示例
# 全局最大池化
avg_pooling = torch.nn.AdaptiveMaxPool2d((1, 1))
B, C, H, W = input.size()
output = avg_pooling(input).view(B, -1)
print("全局最大池化:", output.size())
print(output, "\n")
(5)自适应平均池化层(Adaptive Average Pooling)
自适应平均池化(Adaptive Average Pooling)是一种对输入进行自适应调整大小的池化操作。在传统的平均池化中,我们需要指定池化操作的输出尺寸,而自适应平均池化则可以根据输入的大小自动决定输出的尺寸。
具体来说,自适应平均池化将输入张量划分成不同大小的区域,并对每个区域中的元素取平均值作为输出。每个区域的大小根据输入的尺寸和输出的尺寸进行自适应计算,从而达到自适应调整大小的效果。自适应池化Adaptive Pooling与标准的Max/AvgPooling区别在于,自适应池化Adaptive Pooling会根据输入的参数来控制输出output_size,而标准的Max/AvgPooling是通过kernel_size,stride与padding来计算output_size。
自适应平均池化在深度学习中常用于处理输入尺寸变化的情况,特别是当需要使用全连接层或者固定尺寸的卷积层时。通过自适应平均池化,可以使得网络对输入的大小更加鲁棒,不受固定尺寸限制。
示例
adaverage_pool = nn.AdaptiveAvgPool2d(output_size=(100,100)) # 输出大小的尺寸指定为100*100
pool_out = adaverage_pool(image_out)
(6)自适应最大池化(Adaptive Max Pooling)
自适应最大池化是一种池化方法,其目的是在不改变输入形状的情况下,通过自适应地更改池化大小在整个输入中找到最大值。
具体地说,它计算输入张量中每个通道的最大值,并使用这些通道的不同最大值对每个通道进行汇总,从而产生输出张量。池化大小可以在每个通道上是不同的。这使得自适应最大池化比传统最大池化更灵活,并且在处理不同大小的输入时特别有用。
(7) Mix Pooling(混合池化)
论文地址: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.678.7068&rep=rep1&type=pdf
定义:
为了提高训练较大CNN模型的正则化性能,受Dropout(将一半激活函数随机设置为0)的启发,Dingjun Yu等人提出了一种随机池化Mix Pooling[2] 的方法,随机池化用随机过程代替了常规的确定性池化操作,在模型训练期间随机采用了最大池化和平均池化方法,并在一定程度上有助于防止网络过拟合现象。其定义如下:
(8) 组合池化
组合池化则是同时利用最大值池化与均值池化两种的优势而引申的一种池化策略。常见组合策略有两种:Cat与Add。常常被当做分类任务的一个trick,其作用就是丰富特征层,maxpool更关注重要的局部特征,而average pooling更关注全局特征。
示例
def add_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return 0.5 * (x_avg + x_max)
def cat_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return torch.cat([x_avg, x_max], 1)(9)Stochastic Pooling(随机池化)
论文地址: https://arxiv.org/pdf/1301.3557
代码链接: https://github.com/szagoruyko/imagine-nn
定义
随机池化Stochastic Pooling[3] 是Zeiler等人于ICLR2013提出的一种池化操作。随机池化的计算过程如下:
先将方格中的元素同时除以它们的和sum,得到概率矩阵。
按照概率随机选中方格。
pooling得到的值就是方格位置的值。
假设特征图中Pooling区域元素值如下(参考Stochastic Pooling简单理解):
则这时候的poolng值为1.5。使用stochastic pooling时(即test过程),其推理过程也很简单,对矩阵区域求加权平均即可。比如对上面的例子求值过程为为:
说明此时对小矩形pooling后的结果为1.625。在反向传播求导时,只需保留前向传播已经记录被选中节点的位置的值,其它值都为0,这和max-pooling的反向传播非常类似。本小节参考Stochastic Pooling简单理解[4]。
(10) Power Average Pooling(幂平均池化)
论文地址: http://proceedings.mlr.press/v32/estrach14.pdf

(11)Detail-Preserving Pooling(DPP池化)
论文地址: https://openaccess.thecvf.com/content_cvpr_2018/papers/Saeedan_Detail-Preserving_Pooling_in_CVPR_2018_paper.pdf
代码链接: https://github.com/visinf/dpp
为了降低隐藏层的规模或数量,大多数CNN都会采用池化方式来减少参数数量,来改善某些失真的不变性并增加感受野的大小。由于池化本质上是一个有损的过程,所以每个这样的层都必须保留对网络可判别性最重要的部分进行激活。但普通的池化操作只是在特征图区域内进行简单的平均或最大池化来进行下采样过程,这对网络的精度有比较大的影响。基于以上几点,Faraz Saeedan等人提出一种自适应的池化方法-DPP池化Detail-Preserving Pooling[6],该池化可以放大空间变化并保留重要的图像结构细节,且其内部的参数可通过反向传播加以学习。DPP池化主要受**Detail-Preserving Image Downscaling[7]**的启发。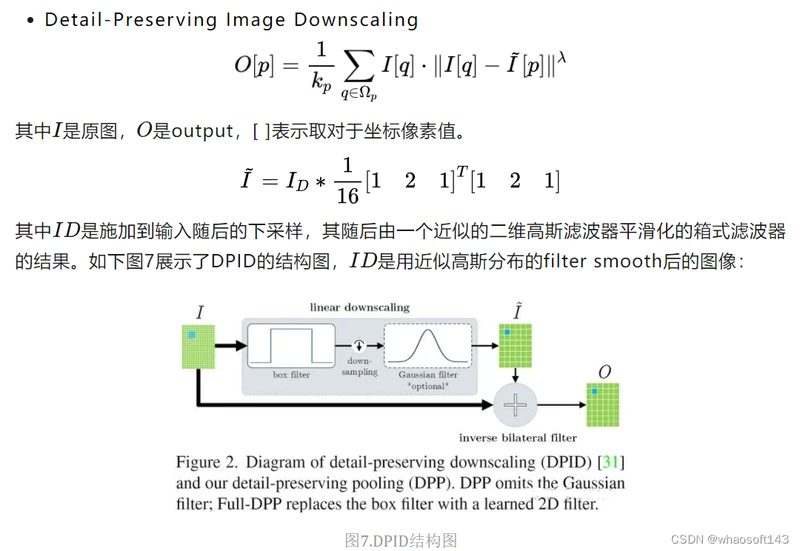
(12) Local Importance Pooling(局部重要性池化)
背景
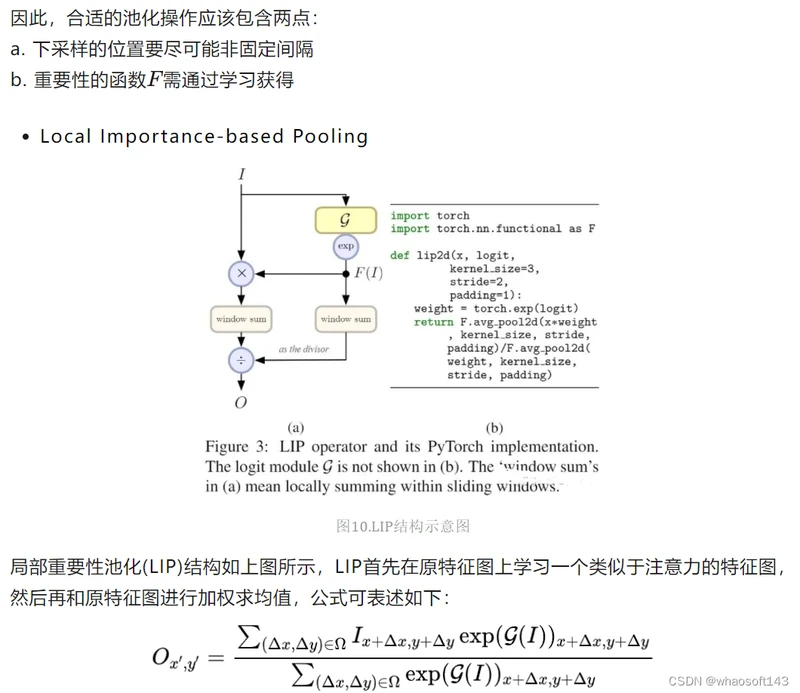
CNN通常使用空间下采样层来缩小特征图,以实现更大的接受场和更少的内存消耗,但对于某些任务而言,这些层可能由于不合适的池化策略而丢失一些重要细节,最终损失模型精度。为此,作者从局部重要性的角度提出了局部重要性池化Local Importance Pooling[8],通过基于输入学习自适应重要性权重,LIP可以在下采样过程中自动增加特征判别功能。
定义
池化操作可归纳为如下公式:
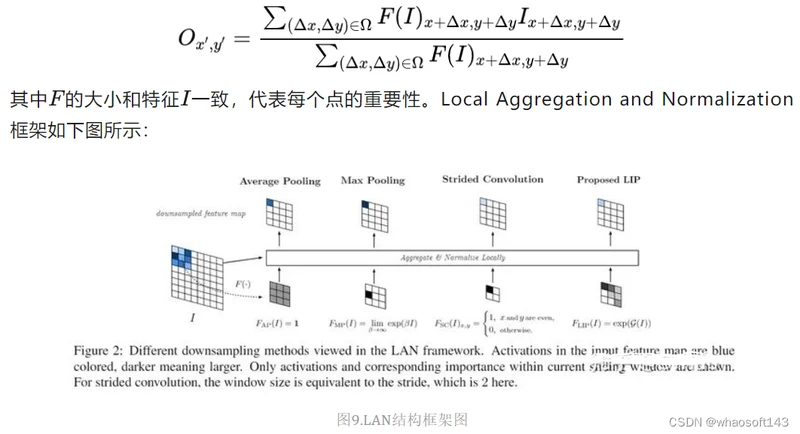
图中分别对应了平均池化,最大池化和步长为2的卷积。首先最大池化对应的最大值不一定是最具区分力的特征,并且在梯度更新中也难以更新到最具区分力的特征,除非最大值被抑制掉。而步长为2的卷积问题主要在于固定的采样位置。
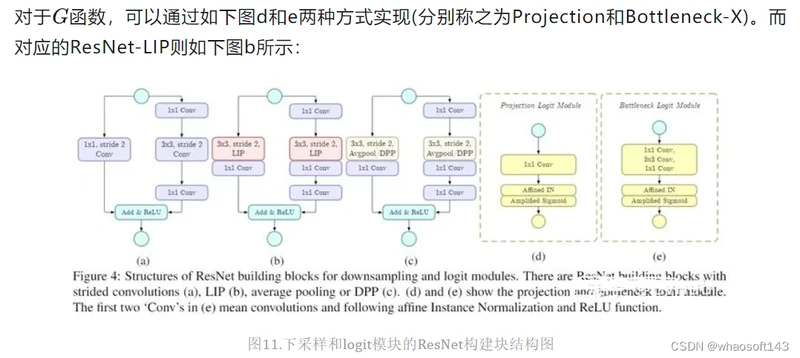
(13) Soft Pooling(软池化)
论文地址: https://arxiv.org/pdf/2101.00440
代码链接: https://github.com/alexandrosstergiou/SoftPool
背景
现有的一些池化方法大都基于最大池化和平均池化的不同组合,而软池化Soft Pooling[9] 是基于softmax加权的方法来保留输入的基本属性,同时放大更大强度的特征激活。与maxpooling不同,softpool是可微的,所以网络在反向传播过程中为每个输入获得一个梯度,这有利于提高训练效果。
定义
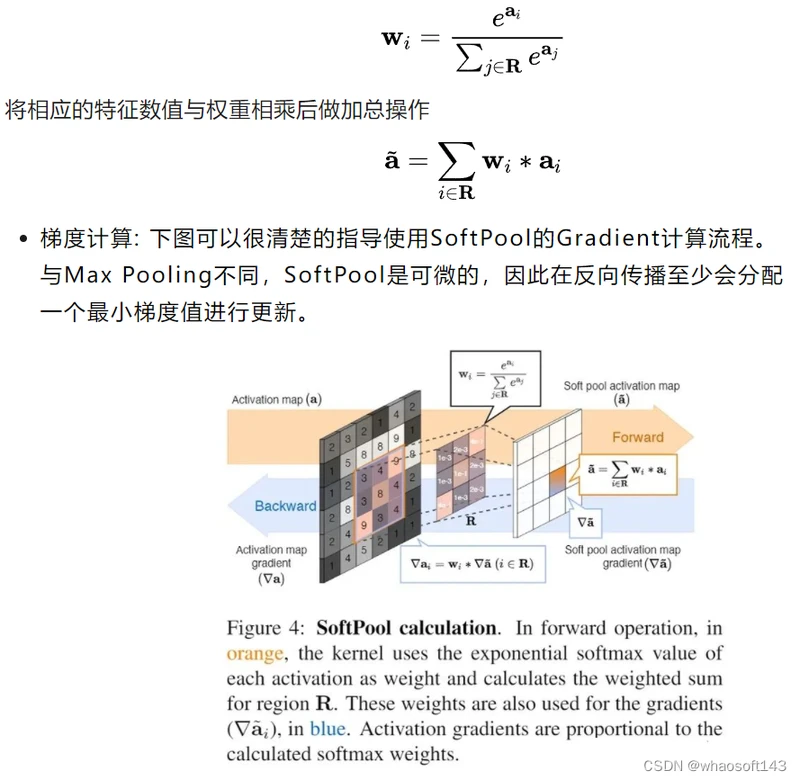
SoftPool的计算流程如下:
a. 特征图透过滑动视窗来框选局部数值
b. 框选的局部数值会先经过指数计算,计算出的值为对应的特征数值的权重
c. 将各自的特征数值与其相对应的权重相乘
d. 最后进行加总

这样的方式让整体的局部数值都有所贡献,重要的特征占有较高的权重。比Max pooling(直接选择最大值)、Average pooling (求平均,降低整个局部的特征强度) 能够保留更多讯息。
SoftPool的数学定义如下:
计算特征数值的权重,其中R为框选的局部区域,a为特征数值 whaosoft aiot http://143ai.com
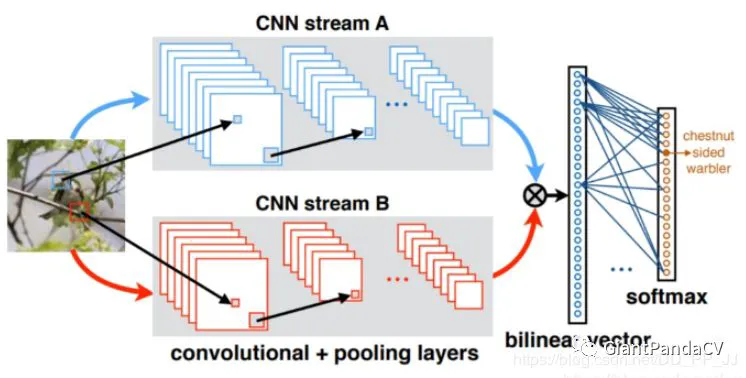
(14)双线性池化
Bilinear Pooling是在《Bilinear CNN Models for Fine-grained Visual Recognition》被提出的,主要用在细粒度分类网络中。双线性池化主要用于特征融合,对于同一个样本提取得到的特征x和特征y, 通过双线性池化来融合两个特征(外积),进而提高模型分类的能力。
主要思想是对于两个不同图像特征的处理方式上的不同。传统的,对于图像的不同特征,我们常用的方法是进行串联(连接),或者进行sum,或者max-pooling。论文的主要思想是,研究发现人类的大脑发现,人类的视觉处理主要有两个pathway, the ventral stream是进行物体识别的,the dorsal stream 是为了发现物体的位置。
论文基于这样的思想,希望能够将两个不同特征进行结合来共同发挥作用,提高细粒度图像的分类效果。论文希望两个特征能分别表示图像的位置和对图形进行识别。论文提出了一种Bilinear Model。
如果特征 x 和特征y来自两个特征提取器,则被称为多模双线性池化(MBP,Multimodal Bilinear Pooling)
如果特征 x = 特征 y,则被称为同源双线性池化(HBP,Homogeneous Bilinear Pooling)或者二阶池化(Second-order Pooling)。
示例
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization之后又有很多人出于对双线性池化存在的特征维度过高等问题进行各种改进,具体可以看知乎文章:https://zhuanlan.zhihu.com/p/62532887
(15)UnPooling
是一种上采样操作,具体操作如下:
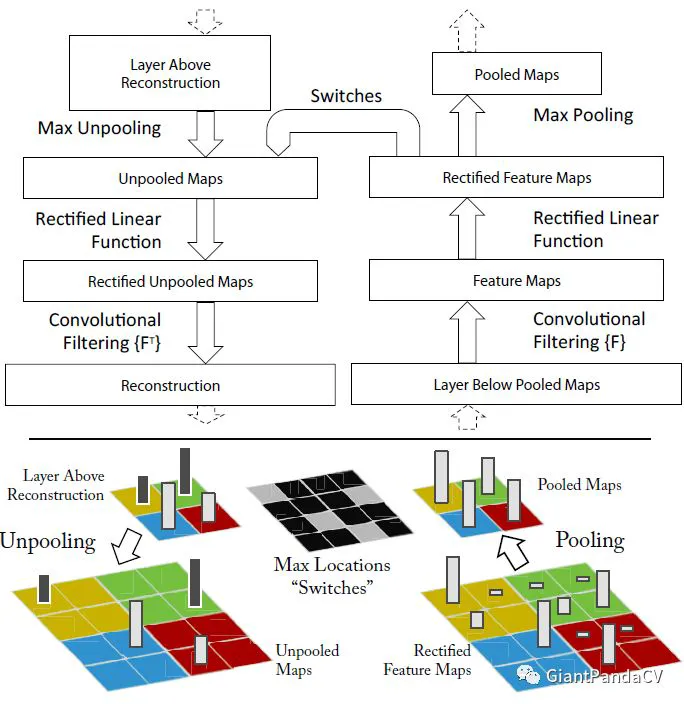
流程描述:
1.在Pooling(一般是Max Pooling)时,保存最大值的位置。
2.中间经历若干网络层的运算。
3.上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
UnPooling不完全是Pooling的逆运算,Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作;对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
参考:
【综述】盘点卷积神经网络中的池化操作
深度学习的9种池化方法
SAGPool - Self-Attention Graph Pooling 图分类 图池化方法 ICML 2019
全新池化方法AdaPool | 让ResNet、DenseNet、ResNeXt等在所有下游任务轻松涨点
比空间池化更好的条带池化方法
torch|全局池化层详解