
对象管理
对象,即Object。广义的说,对象就是“目标”,行为的受体,所以,任何客观的事物从广义上讲都可以成为对象。在计算机领域,对象是个专有名词。其定义是:一个(一组)数据结构,以及定义在其上的操作,也就是数据结构 +操作,这个跟我们程序设计的思想是一致的,所谓“基于对象的程序设计”和“面向对象的程序设计”的概念都是基于此的。Windows把文件和设备都看做特殊对象。
同样,我们将空间分成用户空间和系统空间,自然也就有内核对象(存在于内核之中)和用户对象(用户空间的)。从操作系统的角度来看,我们关心的当然是内核对象,并且如果一个内核对象只是用于内核本身,而不向用户空间开放,对于软件而言,那自然是没有多大意义的,所以我们关心的是对用户程序开放的,可以为用户程序所用的内核对象,当然,我们使用内核对象的媒介自然是系统调用,也即向用户开放的本质,是开放相应的系统调用接口。
常见的对象类型,以及对应的操作

 这些对象类型大都为对象的创建和打开配备了专门的系统调用。例如对象类型Key,就有NtCreateKey和NtOpenKey。但是对于NamedPipe类型,却又有些特殊,这个对象类型有专门的“创建”系统调用NtCreateNamedPipe,却没有专门“打开”的系统调用,而只是借用了NtOpenFile,读/写则借用了NtReadFile和NtWriteFile。除了NamedPipe还有很多对象,例如Device,Driver,等用于设备驱动的对象类型,这些对象类型也没有专门的系统调用,而是借用了NtOpenFile作为创建/打开的方法。
这些对象类型大都为对象的创建和打开配备了专门的系统调用。例如对象类型Key,就有NtCreateKey和NtOpenKey。但是对于NamedPipe类型,却又有些特殊,这个对象类型有专门的“创建”系统调用NtCreateNamedPipe,却没有专门“打开”的系统调用,而只是借用了NtOpenFile,读/写则借用了NtReadFile和NtWriteFile。除了NamedPipe还有很多对象,例如Device,Driver,等用于设备驱动的对象类型,这些对象类型也没有专门的系统调用,而是借用了NtOpenFile作为创建/打开的方法。
事实上,NtOpenFile是创建/打开对象的通用方法,凡是没有专门为其配备系统调用的对象类型,就都以NtOpenFile作为创建/打开的方法,并借用NtReadFile,NtWriteFile等本来用于文件操作的方法用来操作这些对象类型。
并且,不管是什么方法创建/打开的对象,关闭对象的方法都是NtClose,当然,尽管都用NtClose,但是在内核中实际执行的函数自然会因为对象类型的不一致而执行不同的函数。
对于几乎所有的对象,Windows内核都提供了一个统一的操作模式,就是先通过系统调用“打开”或创建目标对象,让当前进程与目标对象之间建立起连接,当然,在打开对象的时候要指定对象的类别,另一方面说明怎样找到具体的对象,即提供目标对象的**“路径名”。然后通过别的系统调用进行操作,最后通过系统调用"关闭"对象解除当前进程与目标对象的连接关系**。
建立连接是维持对于目标对象进行操作的上下文所必须的。在Windows的对象管理机制中,除少数例外以外,对于几乎所有对象的操作都是遵循先打开后操作最后关闭的统一模式。
内核在为当前进程打开目标对象后,会返回一个叫“Handle”的识别号,作为后续操作的依据。Windows内核中“对象”实质上就是数据结构,就是一些带有“对象头”(Object Head)的特殊数据结构。
任何对象的数据结构都由对象头和具体对象类型这两部分构成(大方向上)。但是,由于对象头的结构较为特殊,其中有些成分是可选的,所以实际上分成三部分。
- 其一是对象头OBJECT_HEAD数据结构
- 其二是具体对象类型的数据结构本身,根据对象类型本身的不同,数据结构不同,例如KEVENT,FILE_OBJECT
- 最后是几个作为可选项的附加信息(也就是所谓的可选成分),包括OBJECT_HEADER_CREATOR_INFO(关于创建者的信息,用来将所创建的对象挂入其创建者的对象队列),OBJECT_HEADER_NAME_INFO(载有对象名和目录节点指针),OBJECT_HEADER_HANDLE_INFO(关于句柄的信息),关于耗用内存配额的信息
三个部分按特殊的方式连在一片。按地址由低到高,首先当然是OBJECT_HEADER,它的上方(即高地址处)是具体对象类型的数据结构;附加信息是在OBJECT_HEADER的下面,即低地址处。
OBJECT_HEADER
先看下对象头的数据结构
//
// Object Header
//
typedef struct _OBJECT_HEADER
{
LONG_PTR PointerCount;
union
{
LONG_PTR HandleCount;
volatile PVOID NextToFree;
};
POBJECT_TYPE Type;
UCHAR NameInfoOffset;
UCHAR HandleInfoOffset;
UCHAR QuotaInfoOffset;
UCHAR Flags;
union
{
POBJECT_CREATE_INFORMATION ObjectCreateInfo;
PVOID QuotaBlockCharged;
};
PSECURITY_DESCRIPTOR SecurityDescriptor;
QUAD Body;
} OBJECT_HEADER, *POBJECT_HEADER;
Body显然是具体的对象的数据结构本身,其类型是QUAD,但事实上是不同的对象自然有不同的数据结构,所以它只是相当于一个占位置的,告诉我们Body在OBJECT_HEADER之后。NameInfoOffset,HandleInfoOffset, QuotaInfoOffset他们的类型是UCHAR,不难看出他们的位移是有限的,而ObjectCreateInfo和SecurityDescriptor相比之下则是指针,是独立存在的。
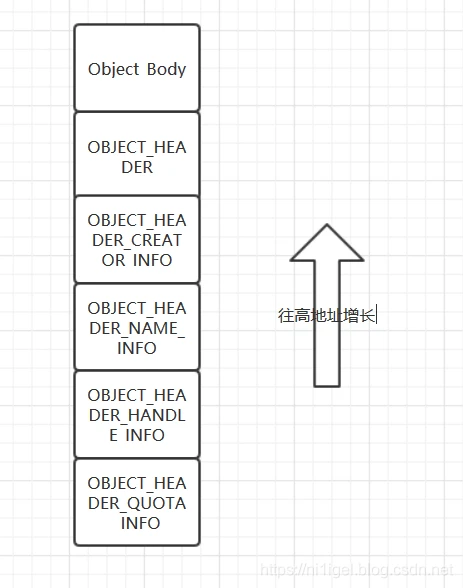 这样依次是配额信息,句柄信息,对象名信息,创建者信息,对象头信息,对象主体信息。因为附加信息都是可选的,而具体的数据结构大小又不定,将NAME_INFO等紧贴OBJECT_HEADER下面,8位字节就可以指定它的偏移了。注意的是,在对象头信息中没有说明Creator_Info的偏移,因为它的偏移根据OBJECT_HEADER-sizeof(OBJECT_HEADER_CREATOR_INFO),创建者信息的大小是固定的,一定是sizeof(OBJECT_HEADER_CREATOR_INFO)。
这样依次是配额信息,句柄信息,对象名信息,创建者信息,对象头信息,对象主体信息。因为附加信息都是可选的,而具体的数据结构大小又不定,将NAME_INFO等紧贴OBJECT_HEADER下面,8位字节就可以指定它的偏移了。注意的是,在对象头信息中没有说明Creator_Info的偏移,因为它的偏移根据OBJECT_HEADER-sizeof(OBJECT_HEADER_CREATOR_INFO),创建者信息的大小是固定的,一定是sizeof(OBJECT_HEADER_CREATOR_INFO)。
一些针对于获取该结构指定偏移的宏
#define OBJECT_TO_OBJECT_HEADER(o) \ //根据具体对象的数据结构,转换到OBJECT_HEADER处 CONTAINING_RECORD是根据第二个结构体和第三个结构体的一个成员以及作为第一个参数的该成员的真实地址,返回指向该结构体的一个指针
CONTAINING_RECORD((o), OBJECT_HEADER, Body)
#define OBJECT_HEADER_TO_NAME_INFO(h) \ //根据NameInOffset是否为空决定是否能找到该偏移 找到对象名结构信息
((POBJECT_HEADER_NAME_INFO)(!(h)->NameInfoOffset ? \
NULL: ((PCHAR)(h) - (h)->NameInfoOffset)))
#define OBJECT_HEADER_TO_HANDLE_INFO(h) \ //根据Handle偏移是否为空决定是否能找到该对象的句柄结构信息
((POBJECT_HEADER_HANDLE_INFO)(!(h)->HandleInfoOffset ? \
NULL: ((PCHAR)(h) - (h)->HandleInfoOffset)))
#define OBJECT_HEADER_TO_QUOTA_INFO(h) \ //根据内存配额信息获取配额结构信息
((POBJECT_HEADER_QUOTA_INFO)(!(h)->QuotaInfoOffset ? \
NULL: ((PCHAR)(h) - (h)->QuotaInfoOffset)))
#define OBJECT_HEADER_TO_CREATOR_INFO(h) \ //传入对象头信息,返回对象创建者信息 这个有点特殊 因为需要对象头Flag中有
((POBJECT_HEADER_CREATOR_INFO)(!((h)->Flags & \
OB_FLAG_CREATOR_INFO) ? NULL: ((PCHAR)(h) - \
sizeof(OBJECT_HEADER_CREATOR_INFO))))
#define OBJECT_HEADER_TO_EXCLUSIVE_PROCESS(h) \
((!((h)->Flags & OB_FLAG_EXCLUSIVE)) ? \
NULL: (((POBJECT_HEADER_QUOTA_INFO)((PCHAR)(h) - \
(h)->QuotaInfoOffset))->ExclusiveProcess))
创建一个对象并返回句柄后,创建该对象的进程就可以通过使用句柄访问它,这样对象可以是无名对象,但是在许多情况下对象名是必要的。
- 一个进程创建一个对象后,别的进程需要共享这个对象。而句柄是针对于特定进程而言的,所以别的进程就需要对象名来打开同一对象了。
- 同一个进程可能需要有访问同一个的对象的多个上下文(例如文件的读/写位置)。所谓“创建”对象,是在创建一个目标对象的同时创建一个上下文,此后每次需要一个新的上下文的时候,就需要再次“打开”同一对象,此时往往也需要对象名。
- 有些对象的内容是永久性的,例如磁盘上的文件,这次写入的可能要等将来的某个时候读出,而句柄显然不具备永久性,所以对象名显然是有必要的。
由于对象名在大多数情况下是必要的,所以需要对 对象名加以组织和管理。这就得需要对象目录,显然,只有有命名的对象才可以进入对象目录。
对象目录是有多个节点连接而成的树状结构,树的root是一个“目录”对象,即类型为OBJECT_DIRECTORY的对象。树中的每个节点都是一个对象,节点名就是对象名。除根结点之外,树中的中间节点都必须是目录对象或符号链接对象(符号链接对象的类型OBJECT_SYMBOLIC_LINK),而普通对象只能成为叶节点。对于对象目录中的任何节点,如果我们从根节点或某个中间节点出发,记下沿途的各个节点的节点名,并以分隔符“\”加以分割,就形成了一个“路径名”。若路径名的第一个节点是根结点,就是全路径名/绝对路径名,若是相对于某个中间节点而出发的,则是相对路径名。根节点的节点名是“\”,内核中对应的全局指针ObpRootDirectoryObject指向的就是根节点的数据结构。
看下目录节点对象的数据结构
typedef struct _OBJECT_DIRECTORY
{
struct _OBJECT_DIRECTORY_ENTRY *HashBuckets[NUMBER_HASH_BUCKETS];
#if (NTDDI_VERSION < NTDDI_WINXP)
ERESOURCE Lock;
#else
EX_PUSH_LOCK Lock;
#endif
#if (NTDDI_VERSION < NTDDI_WINXP)
BOOLEAN CurrentEntryValid;
#else
struct _DEVICE_MAP *DeviceMap;
#endif
ULONG SessionId;
#if (NTDDI_VERSION == NTDDI_WINXP)
USHORT Reserved;
USHORT SymbolicLinkUsageCount;
#endif
} OBJECT_DIRECTORY, *POBJECT_DIRECTORY;
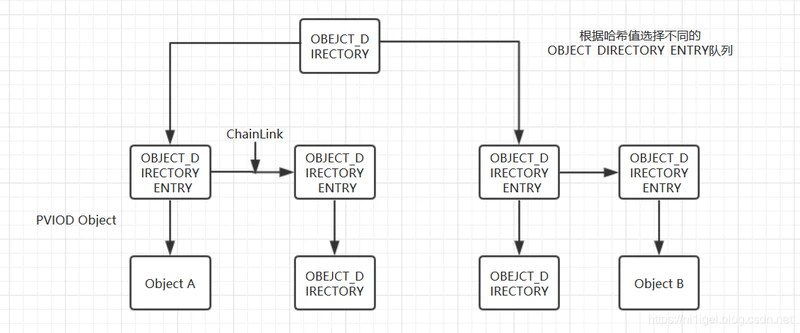
我们这里只关心第一个成员,它的数据结构是OBJECT_DIRECTORY_ENTRY *,这是个结构指针数组.是个散列表,数组中每个指针都可以用来维持一个"对象目录项"即OBJECT_DIRECTORY_ENTRY结构的队列.目录项结构本身并非对象,但是除根节点以外的节点都要靠目录项结构才能插入目录,所以这种结构起着类似于螺丝钉的作用.
typedef struct _OBJECT_DIRECTORY_ENTRY
{
struct _OBJECT_DIRECTORY_ENTRY *ChainLink;
PVOID Object;
#if (NTDDI_VERSION >= NTDDI_WS03)
ULONG HashValue;
#endif
} OBJECT_DIRECTORY_ENTRY, *POBJECT_DIRECTORY_ENTRY;
指针ChainLink用来构成队列,指针Object指向其所连接的对象.
除了根目录节点外,对象中的每个节点必须挂在某个目录节点的某个散列队列中.具体挂在哪一个队列取决于节点名(对象名)的哈希值。
所以总结一下,OBJECT_DIRECTORY中有n个OBJECT_DIRECTORY_ENTRY队列,具体挂在哪一个队列是由对象名的哈希值决定,OBJECT_DIRECTORY中的OBJECT_DIRECTORY_ENTRY队列中,每一个目录项可指向一个结点,也就是说OBJECT_DIRECTORY_ENTRY起着一个中转的作用,也就是螺丝钉的作用,也就意味着任何节点是挂靠在目录项中,目录项既可以指定一个具体的对象,自然也可以指定一个OBJECT_DIRECTORY,而该对象目录又会派生其他的OBJECT_DIRECTORY_ENTRY。这就是对象名所构成的树型结构。
可以这么理解,每一个目录结点是纵向连接,而目录项是横向连接的(队列)。
 只有两种对象可以充任中间节点,一种是对象目录,另一种是符号链接,符号链接使用全路径来链接到某个对象。符号链接的对象可以是目录节点,也可以是叶节点,或者是另一个符号链接节点。所以,从某种意义上而言,符号链接的作用是为一个路径名起了一个别名。
只有两种对象可以充任中间节点,一种是对象目录,另一种是符号链接,符号链接使用全路径来链接到某个对象。符号链接的对象可以是目录节点,也可以是叶节点,或者是另一个符号链接节点。所以,从某种意义上而言,符号链接的作用是为一个路径名起了一个别名。
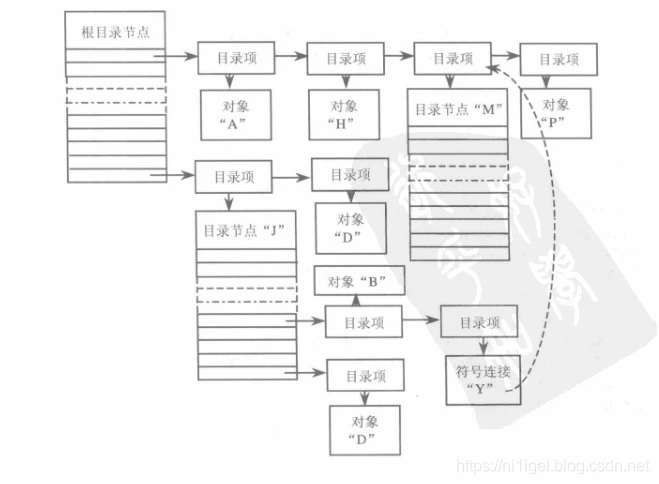 例如此图/M的别名,及符号链接名是/J/Y。
例如此图/M的别名,及符号链接名是/J/Y。
ObpLookupEntryDirectory
为了更好的理解对象目录的结构,我们看一下ObpLookupEntryDirectory。通过一个给定的节点名Name,这个函数在给定的Directory中寻找同名的节点。
/*++
* @name ObpLookupEntryDirectory
*
* The ObpLookupEntryDirectory routine <FILLMEIN>.
*
* @param Directory
* <FILLMEIN>.
*
* @param Name
* <FILLMEIN>.
*
* @param Attributes
* <FILLMEIN>.
*
* @param SearchShadow
* <FILLMEIN>.
*
* @param Context
* <FILLMEIN>.
*
* @return Pointer to the object which was found, or NULL otherwise.
*
* @remarks None.
*
*--*/
PVOID
NTAPI
ObpLookupEntryDirectory(IN POBJECT_DIRECTORY Directory,
IN PUNICODE_STRING Name,
IN ULONG Attributes,
IN UCHAR SearchShadow,
IN POBP_LOOKUP_CONTEXT Context)
{
BOOLEAN CaseInsensitive = FALSE;
POBJECT_HEADER_NAME_INFO HeaderNameInfo;
POBJECT_HEADER ObjectHeader;
ULONG HashValue;
ULONG HashIndex;
LONG TotalChars;
WCHAR CurrentChar;
POBJECT_DIRECTORY_ENTRY *AllocatedEntry;
POBJECT_DIRECTORY_ENTRY *LookupBucket;
POBJECT_DIRECTORY_ENTRY CurrentEntry;
PVOID FoundObject = NULL;
PWSTR Buffer;
PAGED_CODE();
/* Check if we should search the shadow directory */
if (!ObpLUIDDeviceMapsEnabled) SearchShadow = FALSE;
/* Fail if we don't have a directory or name */
if (!(Directory) || !(Name)) goto Quickie;
/* Get name information */
TotalChars = Name->Length / sizeof(WCHAR); //计算出结点名长度
Buffer = Name->Buffer;
/* Set up case-sensitivity */
if (Attributes & OBJ_CASE_INSENSITIVE) CaseInsensitive = TRUE; //若开启了大小写敏感
/* Fail if the name is empty */
if (!(Buffer) || !(TotalChars)) goto Quickie;
/* Create the Hash */
for (HashValue = 0; TotalChars; TotalChars--) //计算Name的哈希值
{
/* Go to the next Character */
CurrentChar = *Buffer++;
/* Prepare the Hash */
HashValue += (HashValue << 1) + (HashValue >> 1);
/* Create the rest based on the name */
if (CurrentChar < 'a') HashValue += CurrentChar;
else if (CurrentChar > 'z') HashValue += RtlUpcaseUnicodeChar(