
Spark 内存管理
堆内内存和堆外内存
作为一个 JVM 进程,Executor 的内存管理建立在 JVM(最小为六十四分之一,最大为四分之一)的内存管理之上,此外spark还引入了堆外内存(不在JVM中的内存),在spark中是指不属于该executor的内存。
堆内内存:由 JVM 控制,由GC(垃圾回收)进行内存回收,堆内内存的大小,由 Spark 应用程序启动时的 executor-memory 或 spark.executor.memory 参数配置,这些配置在 spark-env.sh 配置文件中。
堆外内存:不受 JVM 控制,可以自由分配
堆外内存的优点: 减少了垃圾回收的工作。
堆外内存的缺点:
堆外内存难以控制,如果内存泄漏,那么很难排查
堆外内存相对来说,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
堆内内存
Executor 内运行的并发任务共享 JVM 堆内内存,这些内存被规划为 存储(Storage)内存 和 执行(Execution)内存
一、Storage 内存:
用于存储 RDD 的缓存数据 和 广播(Broadcast)数据,主要用于存储 spark 的 cache 数据,例如RDD的缓存
二、Execution 内存:
执行 Shuffle 时占用的内存,主要用于存放 Shuffle、Join、Sort 等计算过程中的临时数据
三、用户内存(User Memory):
主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息
四、预留内存(Reserved Memory):
系统预留内存,会用来存储Spark内部对象。
五、剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。
Spark 对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存。
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存。
如果当前 Executor 内存不够用,可以分配到其他内存占用小的 Executor 上。
在一定程度上可以提升其他 Executor 的内存利用率,减少当前 Executor 异常的出现。
堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 1.6 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
这种模式不在 JVM 内申请内存,而是调用 Java 的 unsafe 相关 API 进行诸如 C 语言里面的 malloc() 直接向操作系统申请内存,由于这种方式不经过 JVM 内存管理,所以可以避免频繁的 GC,这种内存申请的缺点是必须自己编写内存申请和释放的逻辑。
Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小,单位为字节。堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
如果堆外内存被启用,那么 Executor 内将同时存在堆内和堆外内存,两者的使用互补影响,这个时候 Executor 中的 Execution 内存是堆内的 Execution 内存和堆外的 Execution 内存之和,同理,Storage 内存也一样。相比堆内内存,堆外内存只区分 Execution 内存和 Storage 内存。
spark内存分配
静态内存管理
在 Spark 最初采用的静态内存管理机制下,==存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定==的,但用户可以应用程序启动前进行配置,堆内内存的分配如图 所示:
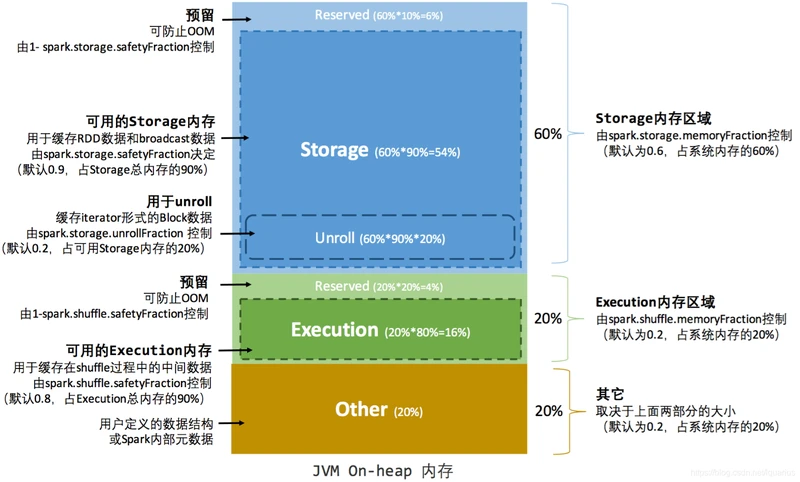
可用堆内内存空间计算:
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
堆外内存
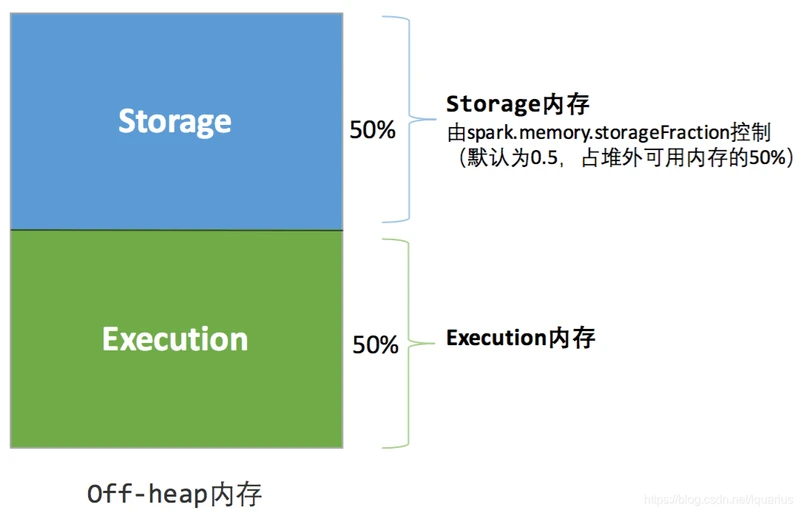
统一内存管理
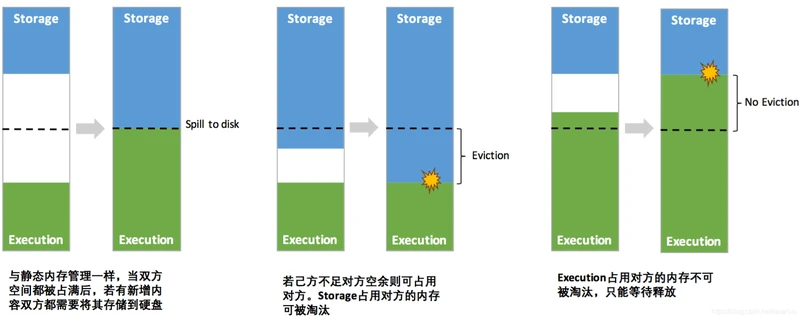
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,如图 所示
堆内
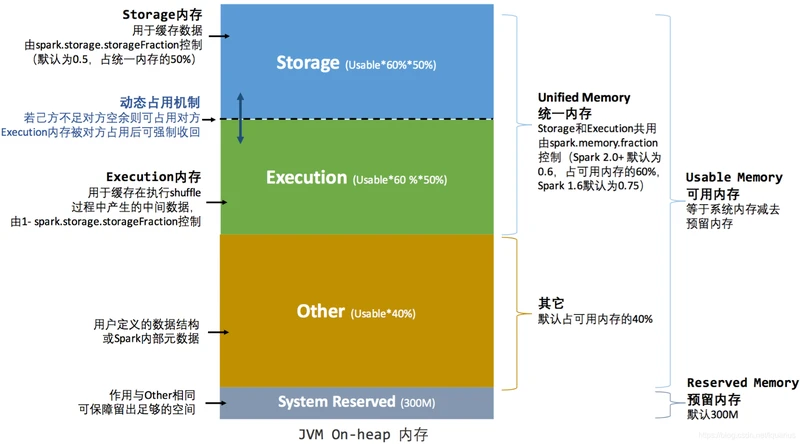
reservedMemory 在 Spark 2.2.1 中是写死的
堆外
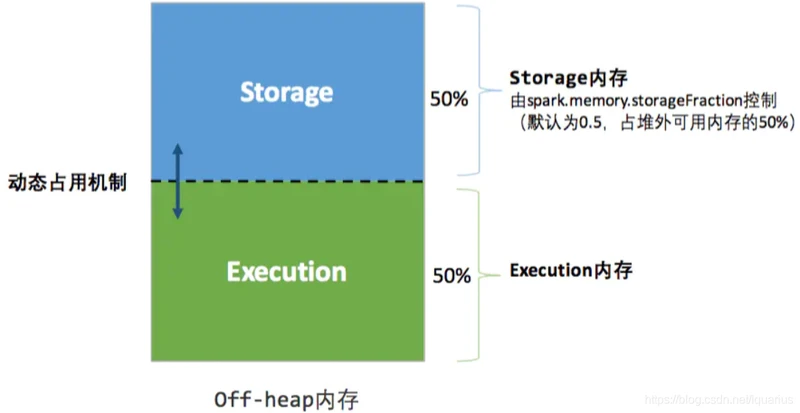
其中最重要的优化在于动态占用机制,其规则如下:
程序提交的时候我们都会设定基本的 Execution 内存和 Storage 内存区域(通过 spark.memory.storageFraction 参数设置);
在程序运行时,如果双方的空间都不足时,则存储到硬盘;将内存中的块存储到磁盘的策略是按照 LRU 规则进行的。若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
Execution 内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间,Storage 占用 Execution 内存的数据被回收后,重新计算即可恢复。
Storage 内存的空间被对方占用后,目前的实现是无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂;而且 Shuffle 过程产生的文件在后面一定会被使用到。
Task 之间内存分布
为了更好地使用使用内存,Executor 内运行的 Task 之间共享着 Execution 内存。具体的,Spark 内部维护了一个 HashMap 用于记录每个 Task 占用的内存。
当 Task 需要在 Execution 内存区域申请 numBytes 内存,其先判断 HashMap 里面是否维护着这个 Task 的内存使用情况,①如果没有,则将这个 Task 内存使用置为0,并且以 TaskId 为 key,内存使用为 value 加入到 HashMap 里面。之后为这个 Task 申请 numBytes 内存,②如果 Execution 内存区域正好有大于 numBytes 的空闲内存,则在 HashMap 里面将当前 Task 使用的内存加上 numBytes,然后返回;③如果当前 Execution 内存区域无法申请到每个 Task 最小可申请的内存,则当前 Task 被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒。
每个 Task 可以使用 Execution 内存大小范围为 1/2N ~ 1/N,其中 N 为当前 Executor 内正在运行的 Task 个数。一个 Task 能够运行必须申请到最小内存为 (1/2N * Execution 内存);当 N = 1 的时候,Task 可以使用全部的 Execution 内存。
比如如果 Execution 内存大小为 10GB,当前 Executor 内正在运行的 Task 个数为5,则该 Task 可以申请的内存范围为 10 / (2 * 5) ~ 10 / 5,也就是 1GB ~ 2GB的范围。
示例
-
只用了堆内内存
现在我们提交的 Spark 作业关于内存的配置如下:
–executor-memory 18g
由于没有设置 spark.memory.fraction(Storage 和 Execution 共用内存 占可用内存的比例,默认为0.6) 和 spark.memory.storageFraction(Storage 内存占 Storage 和 Execution 共用内存 比例,默认0.5) 参数,我们可以看到 Spark UI 关于 Storage Memory 的显示如下:
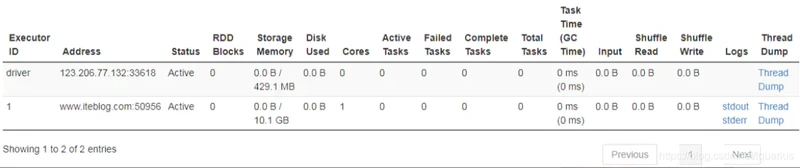
上图很清楚地看到 Storage Memory 的可用内存是 10.1GB,这个数是咋来的呢?根据前面的规则,我们可以得出以下的计算:
systemMemory = spark.executor.memory
reservedMemory = 300MB
usableMemory = systemMemory - reservedMemory
StorageMemory= usableMemory * spark.memory.fraction * spark.memory.storageFraction
把数据代进去,得出结果为:5.312109375 GB。
和上面的 10.1GB 对不上。为什么呢?这是因为 Spark UI 上面显示的 Storage Memory 可用内存其实等于 Execution 内存和 Storage 内存之和,也就是 usableMemory * spark.memory.fraction
我们设置了 --executor-memory 18g,但是 Spark 的 Executor 端通过 Runtime.getRuntime.maxMemory 拿到的内存其实没这么大,只有 17179869184 字节,这个数据是怎么计算的?
Runtime.getRuntime.maxMemory 是程序能够使用的最大内存,其值会比实际配置的执行器内存的值小。这是因为内存分配池的堆部分分为 Eden,Survivor 和 Tenured 三部分空间,而这里面一共包含了两个 Survivor 区域,而这两个 Survivor 区域在任何时候我们只能用到其中一个,所以我们可以使用下面的公式进行描述:
ExecutorMemory = Eden + 2 * Survivor + Tenured
Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured
- 用了堆内和堆外内存
现在如果我们启用了堆外内存,情况咋样呢?我们的内存相关配置如下:
spark.executor.memory 18g
spark.memory.offHeap.enabled true
spark.memory.offHeap.size 10737418240
从上面可以看出,堆外内存为 10GB,现在 Spark UI 上面显示的 Storage Memory 可用内存为 20.9GB,如下:

Spark 内存管理
总结
凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧。譬如,所以如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的 GC 垃圾回收,降低任务执行时的性能。
使用建议
首先,建议使用新模式,所以接下来的配置建议都是基于新模式的。
spark.memory.fraction:如果 application spill 或踢除 block 发生的频率过高(可通过日志观察),可以适当调大该值,这样 execution 和 storage 的总可用内存变大,能有效减少发生 spill 和踢除 block 的频率
spark.memory.storageFraction:为 storage 占 storage、execution 内存总和的比例。虽然新方案中 storage 和 execution 之间可以发生内存借用,但总的来说,spark.memory.storageFraction 越大,运行过程中,storage 能用的内存就会越多。所以,如果你的 app 是更吃 storage 内存的,把这个值调大一点;如果是更吃 execution 内存的,把这个值调小一点
spark.memory.offHeap.enabled:堆外内存最大的好处就是可以避免 GC,如果你希望使用堆外内存,将该值置为 true 并设置堆外内存的大小,即设置
spark.memory.offHeap.size,这是必须的
另外,需要特别注意的是,堆外内存的大小不会算在 executor memory 中,也就是说加入你设置了 --executor memory 10G 和 -spark.memory.offHeap.size=10G,那总共可以使用 20G 内存,堆内和堆外分别 10G。
Executor 实际内存
spark执行的时候,可以通过 spark.executor.memory 来设置executor所需的内存大小
spark.yarn.executor.memoryOverhead是executor所需的额外内存开销
默认为max(executorMemory * 0.10,最小值为384)
实际内存等于:executorMem= X+max(X*0.1,384)
var executorMemory = 1024 // 默认值,1024MB
val MEMORY_OVERHEAD_FACTOR = 0.10 // OverHead 比例参数,默认0.1
val MEMORY_OVERHEAD_MIN = 384
val executorMemoryOverhead = sparkConf.getInt("spark.yarn.executor.memoryOverhead",
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN))
// 假设有设置参数,即获取参数,否则使用executorMemoryOverhead 的默认值
val executorMem = args.executorMemory + executorMemoryOverhead
// 最终分配的executor 内存为 两部分的和
spark-submit --master yarn-cluster --name test --driver-memory 6g --executor-memory 6g
设置的executor-memory 大小为6g,executorMemoryOverhead为默认值,即max(6g*0.1,384MB)=612MB
那总得大小应该为6144MB+612MB=6756MB
然而实际的开销为 7168 MB
为什么?
这就涉及到了规整化因子。
规整化因子介绍
为了易于管理资源和调度资源,Hadoop YARN内置了资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,
如果应用程序申请的资源量小于最小可申请资源量,则YARN会将其大小改为最小可申请量,也就是说,应用程序获得资源不会小于自己申请的资源,但也不一定相等;
如果应用程序申请的资源量大于最大可申请资源量,则会抛出异常,无法申请成功;
规整化因子是用来规整化应用程序资源的,应用程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值,公式为==*ceil(a/b)b==,其中a是应用程序申请的资源,b为规整化因子。
比如,在yarn-site.xml中设置,相关参数如下:
yarn.scheduler.minimum-allocation-mb:最小可申请内存量,默认是1024
yarn.scheduler.minimum-allocation-vcores:最小可申请CPU数,默认是1
yarn.scheduler.maximum-allocation-mb:最大可申请内存量,默认是8096
yarn.scheduler.maximum-allocation-vcores:最大可申请CPU数,默认是4
对于规整化因子,不同调度器不同,具体如下:
FIFO和Capacity Scheduler,规整化因子等于最小可申请资源量,不可单独配置。
Fair Scheduler:规整化因子通过参数yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores设置,默认是1024和1。
通过以上介绍可知,应用程序申请到资源量可能大于资源申请的资源量,比如YARN的最小可申请资源内存量为1024,规整因子是1024,如果一个应用程序申请1500内存,则会得到2048内存,如果规整因子是512,则得到1536内存。
具体到我们的集群而言,使用的是默认值1024MB,因而最终分配的值为
ceil(6756/1024)*1024 = 7168
Client 和 Cluster 内存分配的差异
在使用Clietn 和 Cluster 两种方式提交时,资源开销占用也是不同的。
不管CLient或CLuster模式下,ApplicationMaster都会占用一个Container来运行;而Client模式下的Container默认有1G内存,1个cpu核,Cluster模式下则使用driver-memory和driver-cpu来指定;
cluster 提交命令 与 资源占用
spark-submit --master yarn-cluster --name testClient --driver-memory 6g --executor-memory 6g --num-executors 10
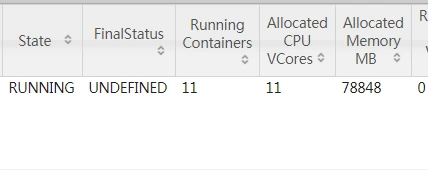
一共10个executor,加上一个am,共11个,每个都分配了7g,即7102411=78848
client 提交命令 与 资源占用
spark-submit --master yarn-client --name testClient --driver-memory 6g --executor-memory 6g --num-executors 10
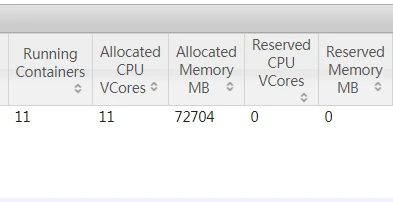
一共10个executor,加上一个am,共11个,每个都分配了7g,即7102411=78848