
Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
摘要
文中主要介绍了一种SCDA的无监督的检索方法,主要针对于细粒度检索任务。算法首先定位图片中主要的目标,这一步主要是摒弃背景或者其他噪音,保持主要的关注点。在当前的图像检索领域,SCDA取得了较好的结果。
简介
普通的图像检索主要是检索相似性,主要用内容,颜色以及形状进行检索。细粒度的检索主要检索同一类型的物体,比如动物中的同一物种,汽车之中的同一种类,细粒度检索面临的问题是,差别细微,但是姿态,旋转,大小变化很大。
使用与训练的模型,提取图像的卷积激活,SCDA方法能够决定有用的区域,这些区域可以量化成一个向量。
文中的主要贡献
- 文中提出一个简单有效方法来定位主要目标,不需要标签和bounding box。
- SCDA 不仅能够进行细粒度检索,对于一般的图像检索也能够有较好的效果
- SCDA的特征提取和视觉特性有很强的关联,这种关联优于对于深度激活。
相关工作
[26, 27, 28, 29, 30,32], 直接使用卷积网络将图像向量化,与之相反的我们的SCDA方法使用无监督的方法选择有用的信息域。
SCDA
Feature map代表通道卷积后的结果。Activations所有的feature map. Descriptor代表activations的d维向量。
给出一个图像I,大小H x W,经过卷积后产生w*h*d的feature map,然后我们将d维度作为,一个descriptor。于是我们就有了w*h的 descriptors。
选择卷积descriptors
SCDA与其他检索方法的区别在于,只是用预训练模型就能够挖掘深度卷积特征,这种特征能够有效的定位图像主要目标,所以本文的关键是descriptor的选择方法。
经过pool层,输入图片I使用一个三维的向量T进行表达,这是一种分布的表达,分布表达通过卷积编码获得,在深度学习中分布表达意味着不同形式表达间的内在联系,每一个concept 是神经网络激活的结果。每一个神经元参与多个concept的表达。
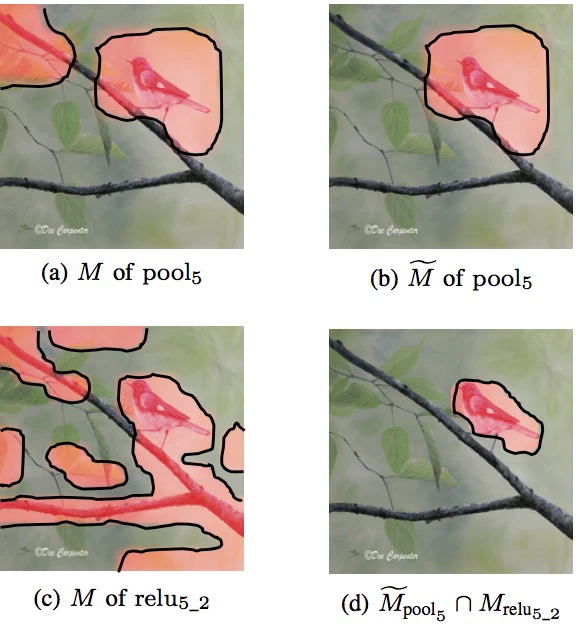
从512个feature maps 选择出一些,并将这些feature map覆盖到原始图片上,展示有意义的语义部分。有些展示的是目标对象,但是有些确实背景或者噪音。
同样的channel 的激活区域有些不一样,比如同一channel,第一张鸟图激活区域是尾巴,但是第二张图激活区域是头部。这样的话,选择出有用的descriptor是很有必要的。为了确定哪些descriptor是有用的,所以我们不能够只关注于单一的channel。
推荐算法
文中首先提出了一种评估质量和数量的方法,尽管单一的通道并没有用,但是当很多通道都在同一区域激活的话,那么这个区域是目标物体的概率较高。所以可以将所有channel相加。那么feature map 就h * w * d变成了h*w,被称为aggregation map
![]()
然后计算A 的平均值a那么就可以得到
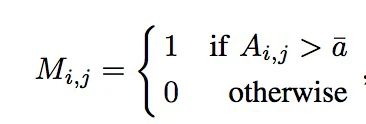
其中I, j 代表不同的位置。
然后使用bicubic差值方法,将M resize成和原图相同大小。 然后将M覆盖到原图之上,会发现虽然激活区域以目标物体为主,但是依然有一些噪音和背景被激活,为了能够去除这些噪音和背景,文中又提出了算法1。

将M变成一个高度目标激活的M~,其中M~可以用一下方式表达
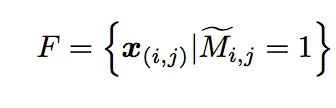
选择激活区域的质量评价如下,首先画出文中算法锁定区域所被包括的最小bounding box 并且在测试集合上评估这些预测的bounding boxes。

其中评价标准是,预测框与真实框IOU>50%的所占据的比例
聚合卷积Descriptors
经过对descriptor的选择
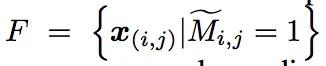
下面给出一些encoding和pooling的方法,之后介绍了本文的推荐方法。
VLAD方法,首先建立一个编码册,并使用聚类的方法,有k个知心
![]()
然后将xij 与最近的k个知心进行相减,得到
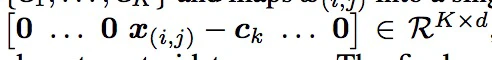
最后得到F等于
![]()
FV 算法,和VLAD算法类似,只不过取代k-means使用了混合高斯算法。
Pooling算法。上面这几种算法将descriptors变成了一个一维向量,然后进行匹配试验结果如下
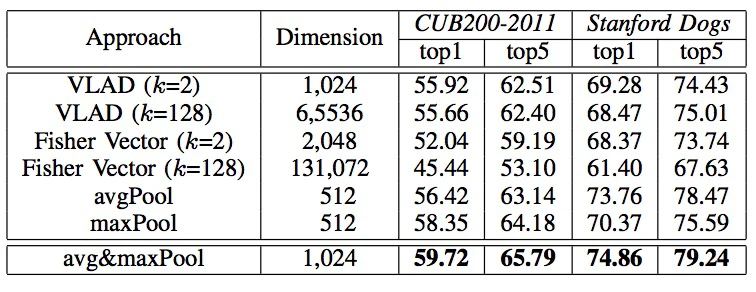
其中avg&maxPool表示将maxPool和avgPool一起concat,得到匹配的特征向量。
多层聚合接口
如果按照卷积后最后一层进行得到Mrelu5_2,,发现pool5后的卷积要比relu5_2的紧密度更好,所以可以将Mpool5 和Mrelu5_2结合到一起,其中将Mpool5上采样到Mrelu5_2大小。其中结合的方法是,既存在Mrelu5_2中激活又存在Mpool5中激活这作为最后的relu5_2 descriptors。然后将relu5_2 SCDA feature以及pool5的concat成一个向量
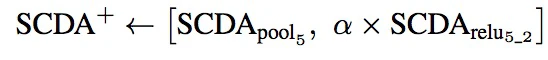
其中alpha 是0.5, 其后面也会跟一个L2 normalization
最后使用向量压缩的方法,对SCDA_flib+ feature 进行压缩,
附件一
VLAD算法
核心思想是积聚思想,主要应用在图像检索领域。其主要方法是训练一个小的码本,对每幅图的特征找到,最近的码本聚类中心,然后将特征与聚类中心的差值做累加,得到一个K*d的vald矩阵,其中k是聚类中心的个数,d表示向量的维度。
