IP反查域名
ip反查域名的三种方法,方法有很多,我这边只描述三种,也算是两种
1,在线网站 http://stool.chinaz.com/same
2,在线网站 https://site.ip138.com/
3,工具 https://github.com/Sma11New/ip2domain
以下以CSDN解析出来的IP 39.106.226.142为例,实际测试三种方法
 1,站长之家 http://stool.chinaz.com/same
1,站长之家 http://stool.chinaz.com/same
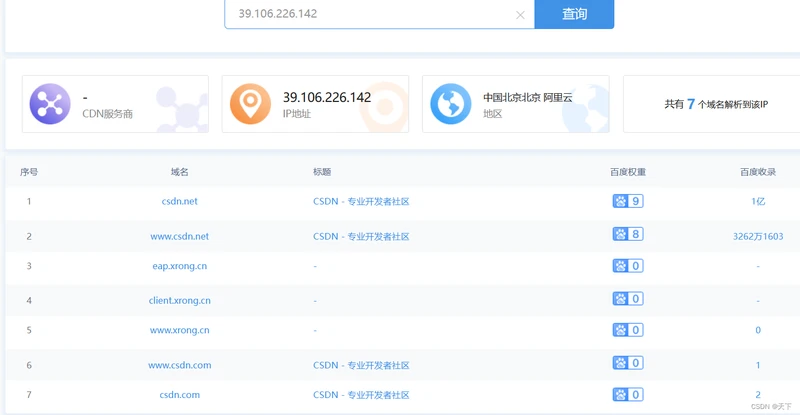
7个
2,查询网https://site.ip138.com/
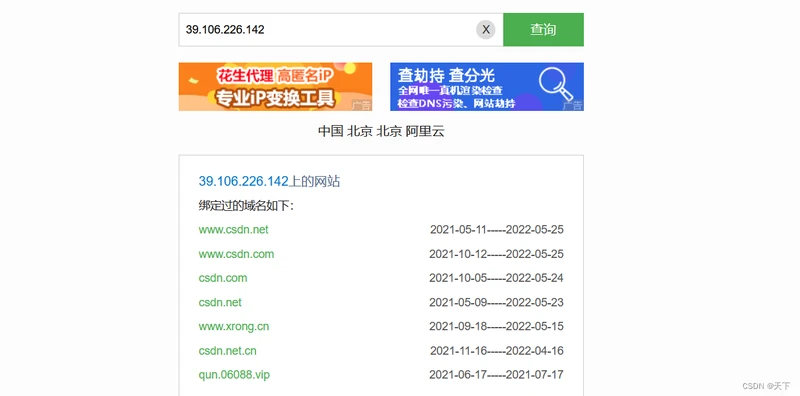
同样也是7个
3,ip2domain工具
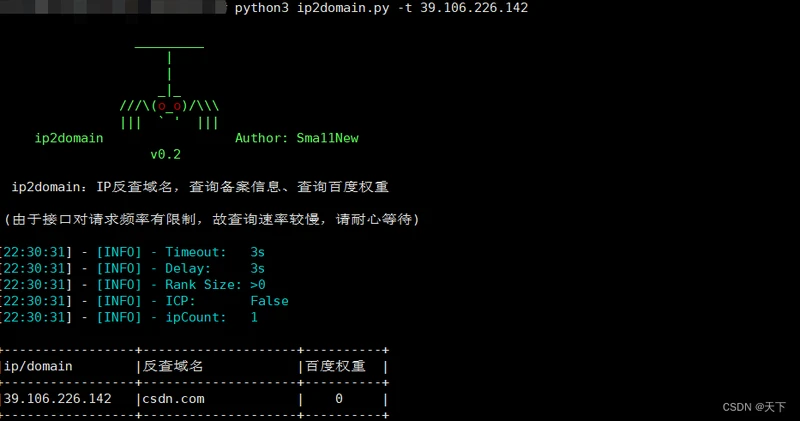 只有一个
只有一个
实际测试结果而言,ip2domain的效果比较拉胯,可能是因为接口过期等原因,此工具即时实在IP大数量需要反查的情况下,仍不具备相应优势,在测试其他网站时,百度,哔哩哔哩等,ip2domain一如既往,但是站长之家会比查询网显示出来的会多一些,个人测试过站长之家和查询网的数据包,站长之家的请求包,会带有一个token值,个人暂未解决,但是查询网并未有相应限制,使用requests和lxml即可成功获取,写了个简单的小脚本,只能说可以用,
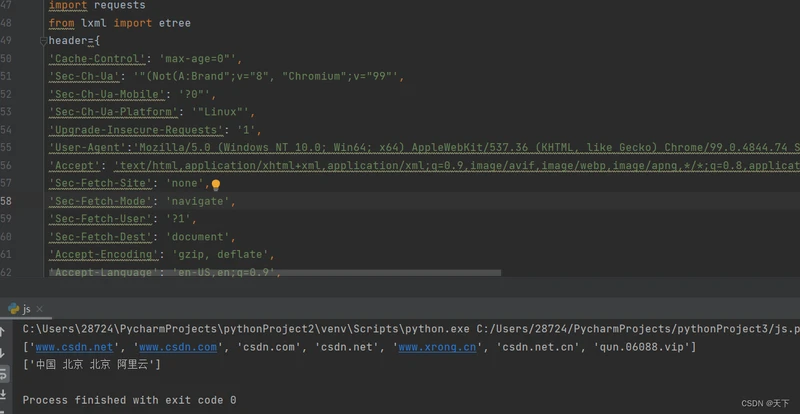
import requests
from lxml import etree
header={
'Cache-Control': 'max-age=0"',
'Sec-Ch-Ua': '"(Not(A:Brand";v="8", "Chromium";v="99"',
'Sec-Ch-Ua-Mobile': '?0"',
'Sec-Ch-Ua-Platform': '"Linux"',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9',
'Connection': 'close'
}
resul=requests.get("https://site.ip138.com/39.106.226.142/",verify=False,headers=header)
html = resul.text
htm=etree.HTML(html,etree.HTMLParser())
result=htm.xpath('//ul[@id="list"]/li/a[@target="_blank"]/text()') #获取a节点下的内容
result1=htm.xpath('//div[@class="result result2"]/h3/text()')
print(result1)
使用时需要修改https://site.ip138.com/39.106.226.142/ 后面的ip即可,还好可以用