CSV文件也称为逗号分隔值文件格式,它以纯文本形式存储表格数据。CSV是一种通用的、相对简单的文件格式,在商业和科学中被广泛应用。
一、读取CSV文件
read_csv() 和 read_table() 的主要参数如下:
path:表示文件系统位置、URL、文件型对象的字符串。sep或delimiter:对每行各个字段进行拆分的字符序列或正则表达式。header:用作列名的行号,默认为0(第一行),如果没有header行就应该设置为None。index_col:行索引的列编号或列名,可以是单个名称/数字或由多个名称/数字组成的列表(层次化索引)。names:用于结果的列名列表,与header=None结合使用。skiprows:需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。na_values:一组用于替换NA的值。comment:用于将注释信息从行尾拆分出去的字符。verbose:打印各种解析器输出信息。encoding:用于unicode的文本编码格式。squeeze:如果数据经解析后仅含一列,则返回Series。thousands:千分位分隔符。
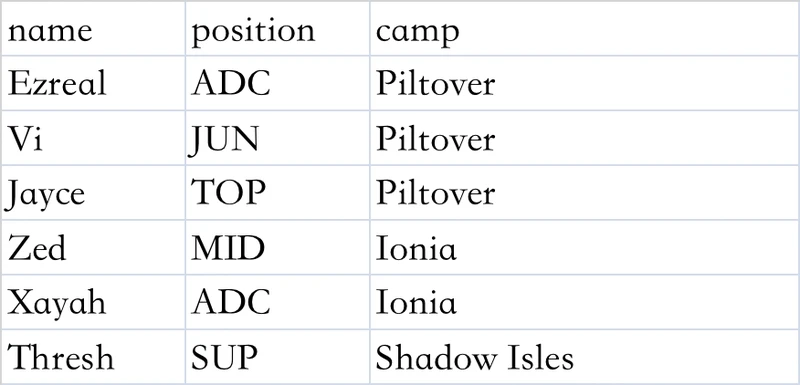
通过cat命令查看test.csv文件的内容:
os.system("cat ./test.csv")
name,position,camp
Ezreal,ADC,Piltover
Vi,JUN,Piltover
Jayce,TOP,Piltover
Zed,MID,Ionia
Xayah,ADC,Ionia
Thresh,SUP,Shadow Isles
使用 read_csv() 函数可以将CSV文件读入一个DataFrame中:
test_csv = pandas.read_csv("./test.csv")
print(test_csv)
name position camp
0 Ezreal ADC Piltover
1 Vi JUN Piltover
2 Jayce TOP Piltover
3 Zed MID Ionia
4 Xayah ADC Ionia
5 Thresh SUP Shadow Isles
也可以使用 read_table() 函数读取,但需要通过 sep 参数指定分隔符:
test_csv = pandas.read_table("./test.csv", sep=",") # sep也可以是一个正则表达式
print(test_csv)
name position camp
0 Ezreal ADC Piltover
1 Vi JUN Piltover
2 Jayce TOP Piltover
3 Zed MID Ionia
4 Xayah ADC Ionia
5 Thresh SUP Shadow Isles
在源文件没有列名时,可以通过 header 其分配缺省列名,也可以通过 names 自定义列名:
test_csv = pandas.read_csv("./test.csv", header=None)
print(test_csv)
print() # 换行
test_csv = pandas.read_csv("./test.csv", names=["first", "second", "third"])
print(test_csv)
0 1 2
0 name position camp
1 Ezreal ADC Piltover
2 Vi JUN Piltover
3 Jayce TOP Piltover
4 Zed MID Ionia
5 Xayah ADC Ionia
6 Thresh SUP Shadow Isles
first second third
0 name position camp
1 Ezreal ADC Piltover
2 Vi JUN Piltover
3 Jayce TOP Piltover
4 Zed MID Ionia
5 Xayah ADC Ionia
通过 index_col 可以将指定列作为DataFrame的索引:
test_csv = pandas.read_csv("./test.csv", index_col="name")
print(test_csv)
position camp
name
Ezreal ADC Piltover
Vi JUN Piltover
Jayce TOP Piltover
Zed MID Ionia
Xayah ADC Ionia
Thresh SUP Shadow Isles
通过 index_col 也可以定义层次化索引:
test_csv = pandas.read_csv("./test.csv", index_col=["camp", "position"])
print(test_csv)
name
camp position
Piltover ADC Ezreal
JUN Vi
TOP Jayce
Ionia MID Zed
ADC Xayah
Shadow Isles SUP Thresh
通过 skiprows 跳过文件的指定行:
test_csv = pandas.read_csv("test.csv", skiprows=[1, 2, 3])
print(test_csv)
name position camp
0 Zed MID Ionia
1 Xayah ADC Ionia
2 Thresh SUP Shadow Isles
通过 nrows 可以指定每次读取的行数:
test_csv = pandas.read_csv("test.csv", nrows=3)
print(test_csv)
name position camp
0 Ezreal ADC Piltover
1 Vi JUN Piltover
2 Jayce TOP Piltover
二、写入CSV文件
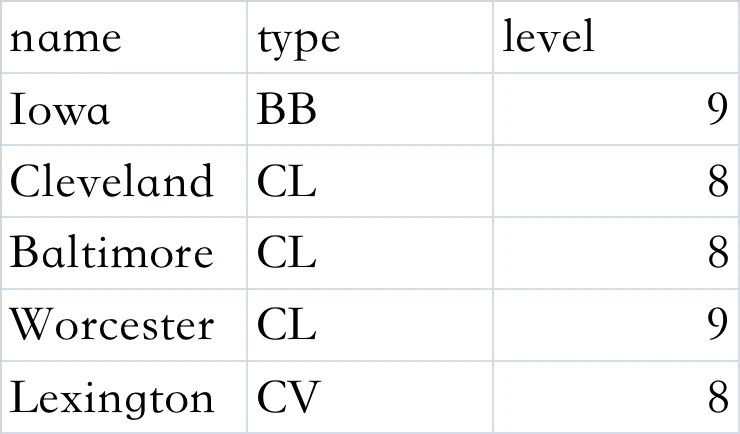
生成一个DataFrame:
data = {"name": ["Iowa", "Cleveland", "Baltimore", "Worcester", "Lexington"],
"type": ["BB", "CL", "CL", "CL", "CV"],
"level": ["9", "8", "8", "9", "8"]}
frame = pandas.DataFrame(data)
print(frame)
name type level
0 Iowa BB 9
1 Cleveland CL 8
2 Baltimore CL 8
3 Worcester CL 9
4 Lexington CV 8
利用DataFrame的 to_csv() 方法,我们可以将数据写入到一个以逗号分隔的文件中:
frame.to_csv("./ship.csv", index=False)
os.system("cat ./ship.csv")
name,type,level
Iowa,BB,9
Cleveland,CL,8
Baltimore,CL,8
Worcester,CL,9
Lexington,CV,8