
出处:2018年CVPR
0.论文的启发:
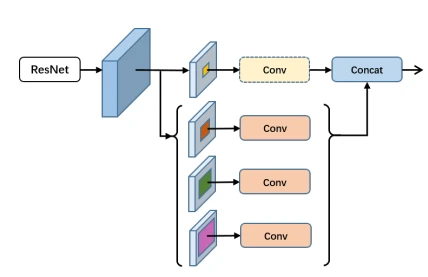
上述网络是PSPNet里使用的空间金字塔池化模型,但使用池化操作会有空间信息上的损失。而DeepLab使用空洞卷积会存在缺少局部信息和”griding”(卷积核退化)现象。因此作者并不使用空间金字塔池化和空洞卷积。
然后作者受parseNet的影响:
parseNet是额外使用一支分支来全局池化(下图粉色部分),把它作为全局特征,在特征(紫色部分)进行一系列卷积操作后再和粉色的部分结合到一起,parseNet把粉色部分和紫色部分结合在一起的方式是连接,但本论文(PAN)的代码则是直接把他们加在一起。
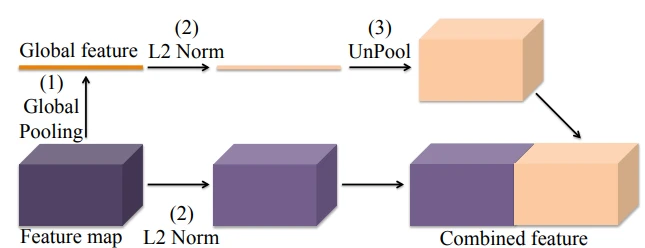
parseNet最大的贡献在于使用了全局语义信息(Global Context)来做分割,ParseNet可以直接对网络中任意一层进行全局池化得到一个代表全图特征的特征图,并利用这个特征图进行分割。
可是为什么加入了全局信息就会改善分割的结果呢?
对于CNN来说,由于池化层的存在,卷积核的感受野(Receptive Field)可以迅速地扩大,对于最顶层的神经元,其感受野通常能够覆盖整个图片。似乎底层的神经元是完全有能力去感知到整个图像的全部信息。但事实却并不是这样的。神经网络实际的感受野要远小于其理论上的感受野,并不足以捕捉到全局语义信息。
既然有了这样的现象,那很自然得就会想到加入全局信息去提升神经网络分割的能力。人们常说,窥一斑而知全豹,但这句话并不总是成立的,如果说你盯着一根杆子使劲看而不去关注它的环境位置顶部底座等信息,同样难以判断出来这根杆子是电线杆还是标志牌或者红绿灯,。就如同以下FCN的输出一样,充满了错误的分类结果 :

所以受次启发,PAN中的子模型FPA引入了这一Global context层。
一,PAN模型(Pyramid Attention Network for Semantic Segmenta
tion)
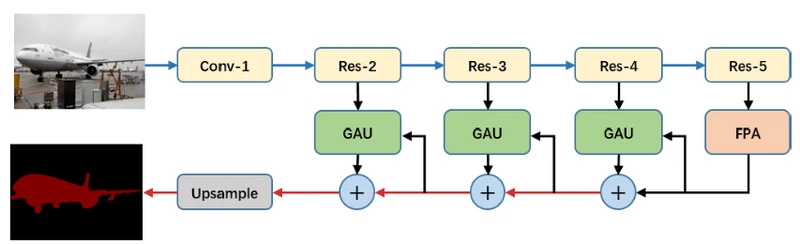
PAN模型也叫金字塔注意力模型,只要由FPA(特征金字塔注意力模块)和GAU两个模型组成:
FPA结构:
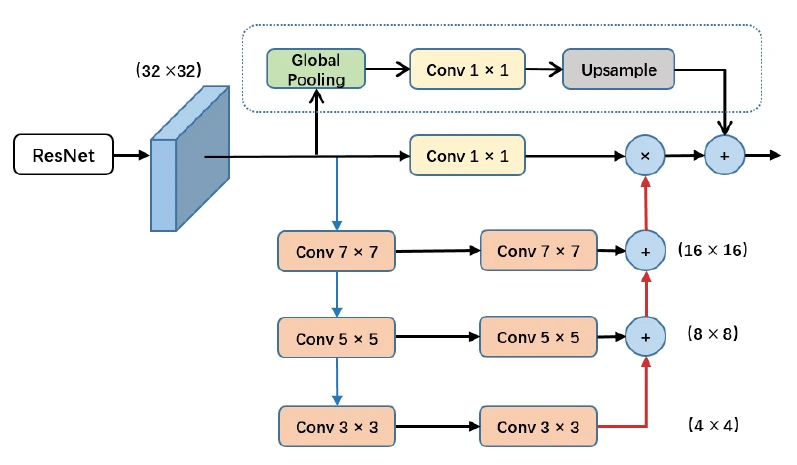
该模块能够融合来自 U 型网络 (如特征金字塔网络 FPN) 所提取的三种不同尺度的金字塔特征。为了更好地提取不同尺度下金字塔特征的上下文信息,我们分别在金字塔结构中使用 3×3, 5×5, 7×7 的卷积核。因为high-level的特征分辨率较小,故使用大的卷积核带来的计算负担不会太多。同时论文引入了全局池化分支用于进一步提升性能(虚线框部分)。
GAU结构:
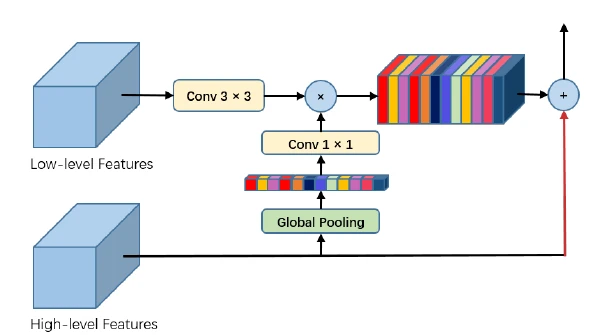
GAU是用在decode时候的单元,同样引入注意力机制,基本思路也就是high level feature map预测一个channel mask然后乘在low level shortcut上,具体实现如图。 具体来讲,使用3×33×3卷积用于对低级特征做通道处理,然后使用全局池化后的信息做加权,得到加权后的low-level特征,再上采样,然后再与high-level信息相加。
基于FPA和GAU,论文提出了完整的PAN架构,如下图:
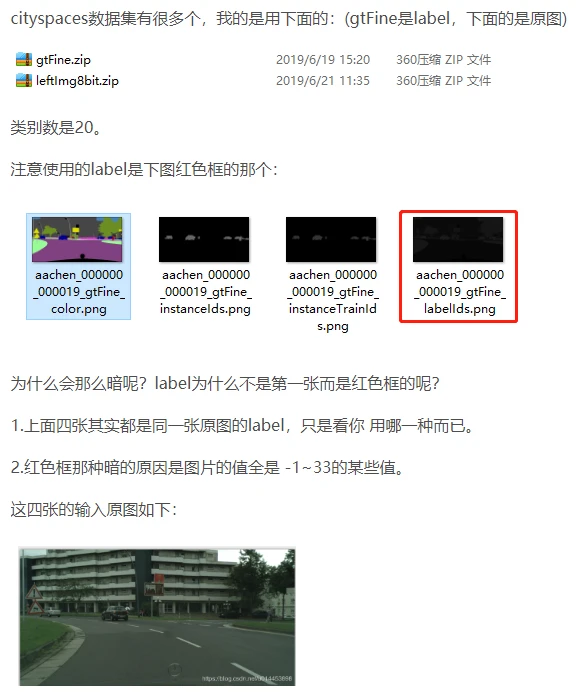
二,使用数据集:Cityspaces
三,模型效果:
输入:

输出:

四,代码链接:
https://github.com/Andy-zhujunwen/pytorch-Pyramid-Attention-Networks-PAN-/tree/master