
一、静态分支预测
静态分支预测就是不预测,每次在流水线的后续阶段,得到了分支指令实际方向和地址后再进行判断,若跳转,则清空流水线、若不跳转则继续执行。故静态分支预测的成功率是50%。
静态分支预测的方法中也会通过编译器提示的方式来进行,例如Linux内核编程中的likely()和unlikely(),就是告诉编译器,这条分支语句执行方向的偏好。
二、动态分支预测
2.1 方向预测
2.1.1 两位饱和计数器
最简单的动态预测方法是直接使用上次的分支结果,但这种方法如果在每次分支指令的方向都变化时,失败率是100%。
两位饱和计数器分支预测根据一条分支指令的前两次执行结果来预测本次方向,用如下状态机表示:
- Strongly taken:计数器饱和态,本次预测分支指令跳转。
- Weakly taken:计数器不饱和态,本次预测分支指令跳转。
- Weakly not taken:计数器不饱和态,本次分支指令预测不发生跳转。
- Strongly not taken:计数器饱和态,本次分支指令预测不发生跳转。
当状态机处于饱和态时,需要两次连续预测失败才能改变预测方向,若分支指令实际总朝一个方向时,预测正确率较高;若实际分支方向经常变化,则状态机不处于饱和状态,正确率较低。
使用基于两位饱和计数器的分支预测器,即使实际分支方向发生了偶尔的改变导致了预测失败,也会将这个变化被过滤掉,下一次预测依然按照原来的方向。
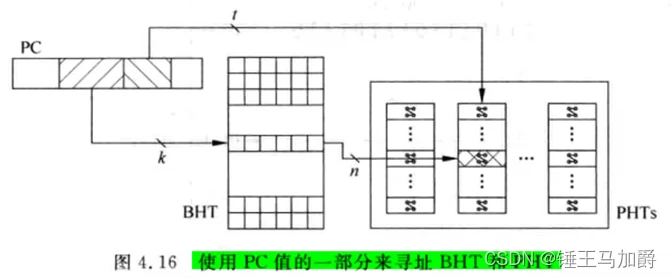
分支预测基于PC值,每一个PC值(每条指令)都应对应一个两位饱和计数器,但这样需要2bit·2^30大小(指令地址4B对齐)的存储器存储这些计数器的值,故普遍使用PC值的一部分来寻址饱和计数器
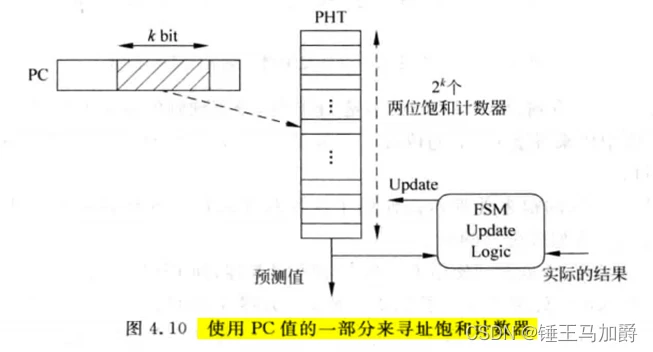
PHT表中存放着一部分PC值对应的两位饱和计数器的值,PHT使用PC值的一部分寻址(k bit)。
但这种寻址方式会使k部分相同的所有PC值使用同一个计数器的值,若这些k部分相同的指令中有多条分支指令,则可能会相互影响,称为别名。
- 中立的别名:两条别名的分支指令方向相同,则不会对预测准确度产生负面影响。
- 破坏性的别名:两条别名的分支指令方向不同,会使共用的两位饱和计数器一直处于不饱和态,降低了预测的准确度。
两位饱和计数器的PHT大小直接影响分支预测的准确度

当PHT大小为2KB(PC值的13位)时,分支预测准确度已达到93%。
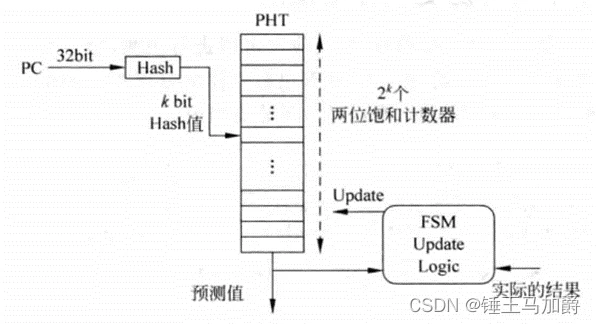
避免别名情况的发生可以采用哈希对PC值处理后再寻址,这样也可以节约空间,不是分支指令的指令所占据的PHT表项也能被利用,但需要处理哈希冲突的情况。
2.1.2 基于局部历史的分支预测
普通的两位饱和计数器预测正确率与初始状态也有一定关系。
若初始状态处于Weakly not taken,且该分支指令以101010…的规律执行,则此时两位饱和计数器一直在中间的两个不饱和态切换,分支预测的正确率为0。
当初始状态处于Strongly not taken,该分支指令以101010…的规律执行,正确率为50%;当初始状态处于Weakly not taken,该分支指令以010101…的规律执行,正确率也为50%。
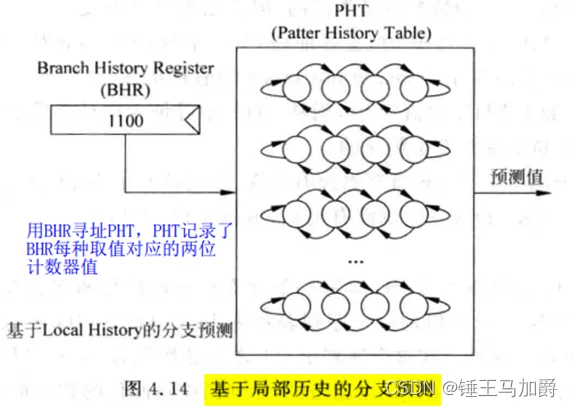
但101010…是一种有规律的执行序列,可以通过一个寄存器记录这条分支指令在过去的历史状态,这可以为分支预测提供一个参考,称为分支历史寄存器(BHR)。对一条分支指令来说,将它每次的跳转结果移进BHR就能记录其历史状态,一个n位宽的BHR可以记录过去n次的执行结果,并对每一个BHR使用一个两位饱和计数器记录它的规律,即用BHR的值去寻址PHT中的表项,其实只有一个饱和计数器,每次更新PHT表项时先读出来,更新后再写回,等效为每个BHR都有一个饱和计数器。
1、循环周期
如果一个序列中,连续相同的数最多有p位,那么这个序列的循环周期就是p,例如序列“11000_11000_11000…”因为有两个连续的1,三个连续的0,故循环周期是3而不是2;序列“00000111_00000111…”循环周期是5而不是3。
2、用两位饱和计数器捕捉BHR的规律
普通的基于两位饱和计数器的预测器的实质是每条分支指令仅对应一个两位饱和计数器,即用PC索引PHT表项,不能捕捉这条分支指令历史执行情况的规律。
基于局部历史的分支预测器的实质是为每条分支指令准备了多个两位饱和计数器,这些两位饱和计数器并不是像普通的预测器一样每执行一次就更新,而是根据BHR的值索引PHT的表项,BHR的值代表了该分支指令之前的多次历史执行结果,若一个BHR的值(历史结果序列)有规律,则该BHR对应的两位饱和计数器一定处于两个饱和态之一,从而可以根据BHR中的历史信息准确预测出下一条分支指令的跳转方向。
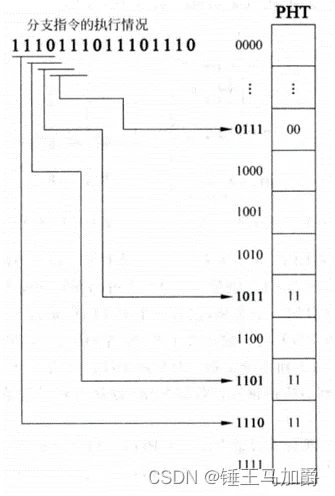
例如一个序列为“1100_1100_1100…”,循环周期为2,可以用两位的BHR记录,11后面必为0、00后面必为1、10后面必为0、01后面必为1;由于00和01后面必为1,所以这两个BHR对应的PHT表项中的两位饱和计数器都会停留在Strongly taken状态,同理10和11对应的两位饱和计数器都会停留在Strongly not taken状态。
但想要达到这样的饱和状态是需要时间的,这段时间称为训练时间,这段时间由于计数器没饱和,因此分支预测的准确率较低,但最终会逐步收敛。BHR的位宽越多,就需要更多的时间找到规律,训练时间更长,并且BHR需要PHT中有更多表项,存储器占用增加,但是更宽的BHR可以记录到该分支更多的历史信息,可提高分支预测的准确度。
如果一个for循环次数很小,例如“1110_1110_1110…”,循环周期为3,即任何宽度不小于3的BHR都可以对其进行预测,若使用一个4位的BHR(16个计数器),则预测过程如下:这个序列在4bit的BHR中会重复出现1110、1101、1011和0111,且1110后必为1、1101后必为1、1011后必为1、0111后必为0,因此对于这条分支指令来讲,只用了PHT中的4个计数器,其他12个都是浪费的。
每条分支指令都应该有自己对应的BHR和PHT表,由PC索引BHR,再由BHR索引其对应PHT中的计数器。实际中一般使用PC的一部分来寻址BHR,相对于一些PC会共用一个BHR;由于PHT占用存储空间很大,所以不可能含有很多张PHT,而是用PC的一部分(小于BHR的那部分),即多个BHR共用PHT。但因为使用了PC的一部分来寻址PHTs和BHT,可能会遇到别名的情况。
为了更大限度地节约PHTs占用的空间,一个极端情况是只有一张PHT表,这就不需要PC来寻址PHTs了,所有的BHR都寻址这一个PHR,但这会遇到冲突的情况,例如两条不同的分支指令对应着两个不同的BHR,但是BHR内容相同,对应到了PHT的同一个计数器,但下一个来的实际跳转结果可能两个BHR是不一样的,可能产生干扰。
对于一个BHR来说,只会用到PHT的少部分内容,这样可以多个BHR分别使用不同的部分,但也会出现下面两种冲突情况:
- 两条指令索引到了同一个BHR,也就对应到了PHT中同一个饱和计数器。
- 两条指令虽然索引到了不同的BHR,但BHR内容一样,也对应到了PHT中同一个饱和计数器。
解决办法:
可以将PC值和对应的BHR值进行一定处理再寻址PHT表。
将PC值进行哈希,再来寻址BHT,这样可以解决上述情况一,避免不同PC索引到同一个BHR。然后将获得的BHR值和PC值的一部分进行拼接,再去寻址PHT,这样可以一定程度上解决上述情况二,避免不同的BHR因值相同而索引到PHT的同一个计数器,将相同值的不同BHR通过PC值区分开。
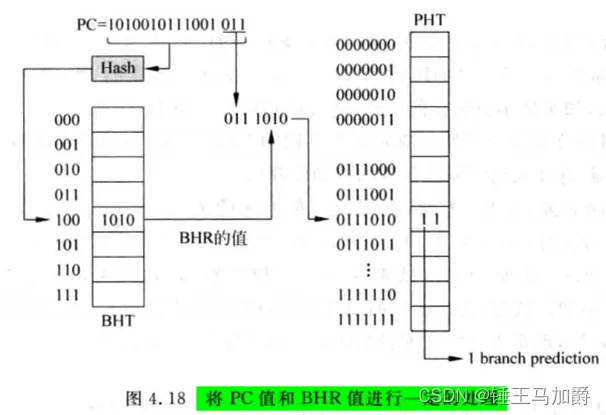
但上述的这种位拼接方式可能也会引入冲突,因为拼接的PC值也是一部分而已,若这部分相同,且正好BHR值也相同,那么还是会产生情况二的冲突。
针对这种情况,还可以使用异或法代替原来位拼接的那部分逻辑,如下图所示。
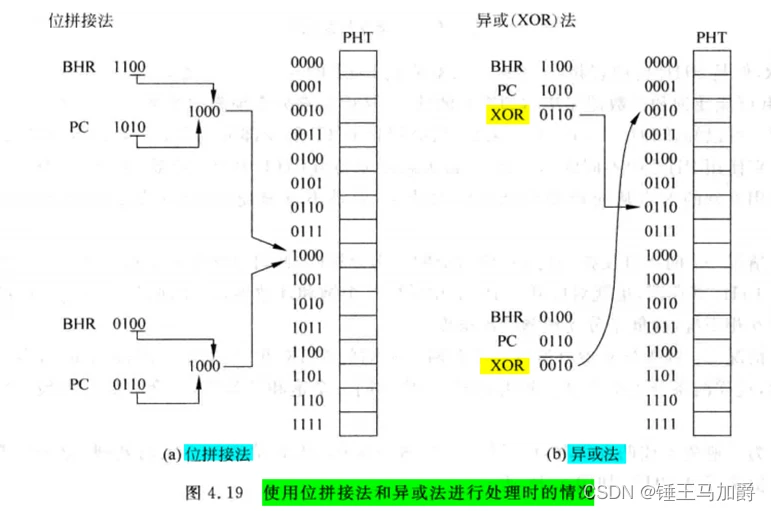
现实的处理器中会使用一些更复杂的算法以尽量避免PHT冲突的情况发生,但无法完全避免。
缺点:
现实中的处理器只能用有限位宽的BHR,这就会导致即使对有规律的分支指令,比如999次跳转和1次不跳转(至少999bit的BHR才能完美预测),也无法完美预测。
基于局部历史的分支预测器是根据分支指令自身在过去执行的情况来预测的,并没有考虑到这条分支指令之前的其他分支指令对于自身预测结果的影响。
2.1.3 基于全局历史的分支预测
基于局部历史的分支预测适用于自身有规律的,比如for循环、while循环;而基于全局历史的分支预测适用于与前面有联系的,比如if-else语句。这两种方法没有孰优孰劣,都有各自的适用场景。
如下面的C语言代码所示,如果分支b1、b2都执行了,那么分支b3永远不会执行,而只依靠局部历史预测是无法发现这个规律的,比如将b1和b2的结果也考虑进去。
- if(aa==2) /* b1 */
- aa = 0;
- if(bb==2) /* b2 */
- bb = 0;
- if(aa!=bb) /* b3 */
- {...}