1. P2P系统
- 既是客户端consumer也是服务器端
producer+consumer=prosumer - 任何时候都有加入或离开的自由
- 无限的peer diversity: 服务能力、存储空间 、网络带宽和服务需求
- 开放的广域无中心分布系统
2. 混合式P2P网络(第一代)
C/S式集中目录查询,P2P式下载
Peers连接到能提供共享内容的中心目录上,匹配请求与索引
文件直接在两个Peers间交换
2.1. P2P网络先驱 Napster
C/S式集中目录查询,P2P式下载
Peers连接到能提供共享内容的中心目录上,匹配请求与索引
文件直接在两个Peers间交换
Napster的缺点:
C/S的单点故障、系统瓶颈、可扩展性低
未考虑不同用户的能力差异、无鼓励机制
版权问题
2.2. 分片优化的BitTorrent
BT下载,首先需要一个种子文件,种子文件包含以下数据:
announce - tracker的URL(tracker是特殊的服务器,帮助peers之间联系)
info - 该条映射到一个字典,该字典的键将取决于共享的一个或多个文件:
name - 建议保存的文件名(一个文件)和目录名称(多个文件)
piece length - 每个文件块的字节数。通常256KB = 262144B
pieces - 每个文件块的SHA-1的集成Hash。因为SHA-1会返回160-bit的Hash,所以pieces将会得到1个160-bit的整数倍的字符串。
length - (只有一个文件时)文件的大小
files - (多个一个文件时)一个字典的列表(每个字典对应一个文件)与以下的键:
path - 一个对应子目录名的字符串列表,最后一项是实际的文件名称
length - 文件的大小(以字节为单位)
上载
某Peer想要共享文件或目录,则为该文件或目录生成一“种子”文件
然后把该“种子”上传到BT网站上
下载
需下载的Peer到BT网站上
找到所需种子根据种子信息进行下载
- 用户通过BT网站搜索文件,得到.torrent文件列表
- 用户选择列表中的一项或多项
每个被选.torrent文件会启动一项下载任务
通常.torrent会指向该文件对应的Tracker,而Tracker会把一部分用户信息给请求者 - 用户根据Tracker用户信息
与其它用户建立连接从它们下载文件分片,也提供分片 - 高速高效
并不总是和最初邻居交换分片,而是每隔一段时间从Tracker获得新的邻居
采用“阻塞算法”主动停止那些对自己无贡献的邻居,寻求更好的邻居
2.2.1. BitTorrent原理
协议
种子文件上传下载、Peers和Tracker间通信都是使用HTTP协议
各Peers间通信使用BitTorrent Peer协议(TCP)
问题
Tracker的单点失效
未对Peers身份认证
开发
BitTorrent协议公开,任何人可开发服务器端或客户端
国内流行BitComet,用Python语言开发
2.2.2. BitTorrent的阻塞算法
防止邻居仅仅下载不上传:每个用户一直保持4个邻居的疏通。每隔20秒(10+10)轮询,每隔10s决定将上传数据给自己速率最低的邻居设置为Choking状态,并保持该状态10s,10s足够TCP调整传输率到最大。如果还是处于Choking,就换邻居。
新的邻居加入后,可能会提高下载带宽,就找到了更好的邻居。那么一个新的用户,不拥有任何分片也就不能上传,会不会被一直Choking?
优化疏通(Optimistic unchoking):在任何时候,每个peer都拥有一个称为“optimistic unchoking”的连接,这个连接总是保持疏通状态,而不管它的下载速率是怎样。每隔30秒,重新计算一次哪个连接应该是“optimistic unchoking”。30秒足以让下载能力也相应的达到最大,这样即使是个新加入者,也有机会下载分片
2.3. 优缺点总结
拓扑结构:服务器仍然是网络的核心
底层协议:全部使用TCP,限制了链接的Peer数量
查询与路由简单高效:
Napster和BT的用户访问服务器;服务器返回文件索引或种子文件;用户再直接同另一Peer连接故路由跳数为O(1),即常数跳
容错、自适应和匿名性
服务器单点失效率高
自组织和自适应主要依靠服务器
服务器的存在使匿名性实际不可能
用户接入无安全认证机制
3. 无结构P2P网络(第二代)
过程:洪泛请求模式
每个Peer的请求直接广播到连接的Peers
各Peers又广播到各自连接的Peers
直到收到应答或达到最大洪泛步数(典型5-9步)
特点
可智能发现节点,完全分布式
大量请求占用网络带宽,可扩展性并不一定最好,
协议
Gnutella/KaZaA/eDonkey/Freenet使用该模式
消息协议:用于节点间相互发现和搜索资源
下载协议:用于两节点间传输文件(使用标准的HTTP协议:GET)
改进
Kazaa 设立Super-Peer客户软件,以集中大量请求
Cache最近请求
何为无结构或结构化P2P
根本区别在于每个peer所维护的邻居是否能够按照某种全局方式组织起来以利于快速查找。
无结构网络优点
将重叠网络看作一个完全随机图,结点之间的链路不遵循某些预先定义的拓扑来构建。
容错性好,支持复杂查询
结点频繁加入和退出,但对系统的影响小。
3.1. Gnutella
纯分布式对等
每个Peer即使服务器也是客户机
每个Peer监视网络局部的状态信息,相互协作
工作过程
原始加入:必须首先连接到一个“众所周知”几乎总是在线的【或称中介、自举、入口】节点(功能同一般Peer),进入Gnutella网
查询和应答消息采用广播或回播(Back-propagate)机制
每条消息被一个全局唯一16字节随机数编码为GUID(128 bit)
每个节点缓存最近路由的消息,以支持回播或阻止重广播
每条消息都有一个TTL数,每跳一次减少一次
3.1.1. Gnutella的问题与改进
由于Gnutella每个节点链接数量有限:
洪泛广播加重网络带宽负担,受TTL限制,消息只能达到一定范围,这又导致有些文件不能查询到
改进:分层P2P=增加超级节点负责查询消息的路由,构成P2P骨干网,叶节点只是通过超级节点代理接入
3.2. 基于超节点的KaZaA
基于FastTrack协议,主要用于MP3 music files共享
比Gnutella更早引入SuperNode
KaZaA是专有协议,对消息加密,存在超级和普通两类节点
超级:高带宽、高处理能力、大存储容量、不受NAT限制
普通:低带宽、低处理能力、小存储容量、受NAT限制
加入、上载与查询
普通节点选择一超级节点作为父节点加入,并维持半永久TCP连接
将自己贡献的文件元数据、描述符上传给它,并生成Hash值
父超节点根据文件描述符关键字查询,返回文件所在IP地址+元数据
3.3. eDonKey/eMule/Overnet
eDonKey,2000年, Jed McCaleb创立专注文件下载
与BT类似,文件分块下载;内容Hash作完整性验证,服务器为核心
BT是基于文件、由 Tracker服务器来查询、搜索和跟踪用户;但eDonKey是基于用户的类似KaZaA的超级节点。
3.4. 无结构网络P2P总结
容错性与自适应
幂率特性对随机节点失效有高容错性
自适应:检测邻居在线否
超级节点列表定期更新
可扩展性
改造洪泛提高可扩展性
安全性与匿名性
无结构不易追踪
增强机制—复制
查询分布:均匀、Zipf
复制份数:均匀、依查询概率比例、方根复制
优势和缺陷
高容错性和良好自适应性,较高安全性和匿名性
路由效率低/可扩展差/准确定位差
4. 结构化P2P网络(第三代)
所谓结构化P2P,核心是采用DHT作为P2P节点和资源的组织方式:
Distributed Hash Table
普通的Hash Table中key和value保存在一台主机上,而DHT把key和value保存在分散的节点上,并通过Hash Table方法进行插入和查询。
DHT的特点
能自适应结点的动态加入/退出
有着良好的可扩展性、鲁棒性
结点ID分配的均匀性和自组织能力。
确定性拓扑结构可精确发现
4.1. DHT
1)一致性hash
The consistent hash function assigns each node and resource an mbit identifier using a base hash function such as SHA-1.
假设资源以(ObjectID,Info)方式保存,每个节点有NodeID,那么NodeID和ObjectID在同一空间
所以一致性hash可以非常方便的建立node和资源之间关系,即哪些node保存了哪些资源可以很容易查询到。
2)结构化路由
节点加入:开始时,获得一个NodeID,连接一个“bootstrap”节点,加入P2P网络
发布资源:生成资源的ObjectID,查找和ObjectID距离最近的N个Node,向这N个node广播新资源信息,告诉这些节点,我有某某资源
资源搜索:找到最靠近资源的N个node(使用NodeID 和ObjectID来计算距离远近),向这些node发送资源查询信息,如果有这个资源的详细信息,就返回给客户端,否则返回离资源更近的node列表给客户端,直到查询到资源提供者信息。
资源下载:如果没查到资源提供者信息,且没有更近的node了,那就说明这个资源没有提供者,如果找到资源提供者信息(NodeID,ip,port)后,向这个资源提供者请求
多个节点有相同资源,那么资源搜索得到一个资源提供者列表,可以开始P2P的下载
结构化路由和洪泛路由的区别:有目的、有针对性的路由
4.2. Chord
环形P2P网络
Chord:优美而精确的P2P网络
在N个节点的网络,每个节点保存O(logN)个其它节点的信息
在O(logN)跳内可找到存储数据对象的节点
节点离开或加入网络时,保持Chord自适应所需消息数O(log2N)=O((logN)2)
可提供数据对象的存储、查询、复制和缓冲
在其上构架有协同文件系统CFS(Cooperative File System)
4.2.1. 工作原理
4.2.1.1. ID的分配
通过hash函数(如SHA-1) (Secure Hash Standard)
NodeID=H(node属性)=H(IP地址/端口号/公钥/随机数/或其组合)
ObjectID=H(object属性)=H(数据名称/内容/大小/发布者/或其组合)
SHA-1的长度值m=160 Bits,从而保证其唯一性和几乎不重复性,故nodeID/objectID均可在[0…2^m)中选取
4.2.1.2. 索引的分配
NodeID从小到大、顺时针排列于1个环上
数据对象k(即ObjectID=k)也按环上顺时针方向,分配到节点k或第一个比k大 (因为环,需要mod 2^m ) 的节点上。这个节点称为Successor(k)节点
形式化表示 Successor(objectk) = nodek 或 nodex ,x是现存网上顺时针第一个大于k的节点
4.2.1.3. 节点路由表的分配
按上述后继关系,Chord显然可以正确工作
但查询效率低下,比如要找ObjectID=K的资源,首先要询问K节点是否存在,然后找K+1,最坏情况要顺序查询O(N)个节点。
所以Chord引入finger table来优化, finger table实际类似路由表:使每步更快接近目的节点
指向表:finger table
每个node存储大小为m的路由表(finger table),以减少路由跳数
节点n的路由表中,第i项指向节点 s = Successor(n+2^i-1),1≤i≤m
故s是在顺时针方向到节点n的距离至少为2^(i-1)的第一个节点:记作n.finger[i].node
除了对象k有Successor,节点n也有Successor节点就是n.finger[1].node
一个路由表项还包括相关节点的NodeID和IP地址、端口号
特点
每节点只保存很少其它节点信息,且对离它越远的节点所知越少
节点不能从自己的路由表中直接看出对象k的后继节点
4.2.1.4. 查找资源(不修改finger)
有了finger table后,就可以快速查找一个key的Successor:
假设k是ObjectID,要找到保存k的Succesor(k)节点,从n节点开始查找 (n可以是任意一个节点)
节点n在自己的路由表中寻找在k之前且离k最近的节点j,让j去找离k进一步最近的节点,如此递归下去,j将离k越来越近,最终找到n’
n’就是在k之前而且离k最近的节点
那么n’的Successor就是要找到的节点Succesor(k)
4.2.1.5. 新节点加入(修改finger)
论文在一个新节点加入到Chord后,为了更新finger table,每个节点除了Successor还有一个Predecessor节点
前驱节点:Predecessor(n)
在节点n之前,不等于n且离n最近的节点Predecessor(n)
4.2.1.6. Chord中节点离开
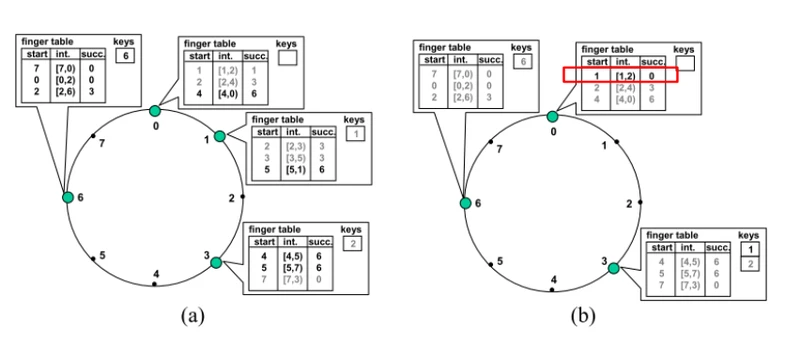
左图Node 6加入每个节点路由表的变化(灰色是不变)
右图Node 1离开每个节点路由表的变化(论文中错误标记为Node 3)
(另外:Node 1离开后,Node 0的finger table第一项应该是3)
4.2.2. 协同文件系统CFS简介
CFS是以Chord作为基础的P2P只读文件存储系统
依靠Chord作为其分布式HASH表,提供高效、容错和负载均衡的文件存储和获取
系统由文件系统FS、分布式散列表DHash和底层定位散列表Chord三层构成
每个节点既是服务器又是客户机
功能说明
FS:高层,从DHash层获取数据块,将这些块转换成文件,给更高层文件系统接口
DHash:中间层,分布和缓存数据块以负载平衡,复制数据块以容错,通过服务器选择来减少延迟,用Chord定位数据块
Chord:底层,维护路由表,定位数据块所在的服务器。每个服务器就是Chord的一个节点
4.2.3. Chord:总结
简单、精确,但要求
每个节点的后继节点始终准确
每个对象k的后继节点始终承担k的索引
查询与维护代价
查询代价:m项的平均间隔 delta = [2^0+ 2^1+… +2^m-1]/m ;设经J跳命中,覆盖节点数≤2^m ;故 J*delta≤2^m ;故有J≤m = O(log N) ;一次查询的路由平均跳数为O(logN)
维护代价:节点的进/出,自适应到最新状态需O(log2N)
缺点:
没有实际使用(只有一个文件共享应用)
不支持非精确查找
finger table有冗余
维护finger table(加入/退出)代价比较高
Chord的问题
(1):finger table有冗余
以 2^i 为跨度来寻找路由表中的后继节点,这会在 finger 中产生一定的冗余量,即节点稀疏的时候,路由容易冗余
(2):路由维护开销大
节点加入:Chord需要环形拓扑中的任意一个节点来协助完成,且加入过程包括新节点本身的Join操作和修改其他节点finger表两个阶段;
节点失效的处理:Chord需要周期性对节点的前继节点和后继节点进行探测,并按照节点加入时的算法重建Finger表;
对于节点退出的处理:Chord采取了将节点的退出当作为失效来处理的方式。
4.3. 结构化P2P网络Kademlia
Kademlia和Chord类似,属于常数度P2P网络
路由、定位、自组织方式与前4种区别不大
每个节点的“度”(连接数)是固定的,与规模无关
维护固定路由表项,仍能达到O(logN)跳的指数定位效率
路由表固定导致网络自适应开销减少
更容错实用的结构化网络Kademlia
路由方法类似Chord
加入、离开节点更加简单
4.3.1. 节点间的异或距离
定义两个节点x,y(ID值表示)的“异或”距离(非欧距离)
节点与数据对象都用SHA-1分配160 Bits ID,
对象索引由与objectID最接近的nodeID负责,“最接近”由XOR距离度量
d(x,y)=x⊕y,如1011⊕0010=1001=9 > 1011⊕1010=0001=1
异或距离的性质:
合理性: d(x,x)= 0
非负性: d(x,y)≥ 0
对称性: d(x,y) = d(y,x) ,对任何x,y,且 x≠y. (Chord不具备)
三角不等式: d(x,y)+d(y,z)≥ d(x,z)
因为d(x,z) = d(x,y)⊕d(y,z)
对任意 a≥0, b≥0 , a+b≥ a⊕b
单向性:任意节点x和距离d,系统中仅有唯一节点一y满足d(x,y)=d
单向性保证相同数据的定位最终将会汇聚于相同的路径
传递性:显然 if d1≥d2 and d2≥d3 ,then d1≥d3 成立
4.3.2. 异或距离结构性好处
按当前节点ID与所有其它节点ID间XOR距离大小排队,知道目标结点ID后,就很容易计算出目标节点在这条队列中的位置;
如果给定一个异或距离,你也能很容易从这条队列里找出与该距离最接近的那些结点
与自己前缀相似度越高的结点离自己越近(异或之后高位为0)
4.3.3. K-桶路由表
K-buckts:每节点维护一个路由表,它由logN(N为最大节点数)个k桶构成
实质是一个链表集,每节点 0≤i<160个桶;每桶内装Max个(10或20)记录=(序号i,到自己的异或距离[2i—2i+1),节点信息)
节点信息 = <IP,端口,节点ID >三元组
表项以访问时间排序,最久(least-recently)访问的放在尾部,最近(mostrecently)访问的放在头部
4.4. BitCoin和区块链
4.4.1. 非对称加密
Bitcoin使用椭圆曲线算法,一把私钥可以推出唯一的公钥,反之不行。
4.4.2. 交易
通过关联一个密钥的方式将钱赋予一个新的所有者。
4.4.3. 比特币区块
多个比特币交易会打包在一个区块中,每个区块大小是1Mbyte
每个交易都会有一个唯一的ID,在区块的tx数组中
每个交易vin中包含的比特币数量减去vout中的比特币数量就是交易费
4.4.4. 比特币区块链
比特a区块链接为一个单链表
每个区块中保存了前一个区块hash值,因此任何人想要篡改链中一个区块,会导致破坏整个区块 链,被P2P网络其他节点发现。
比特币网络中矿工负责打包区块,任何人都可以成为矿工。
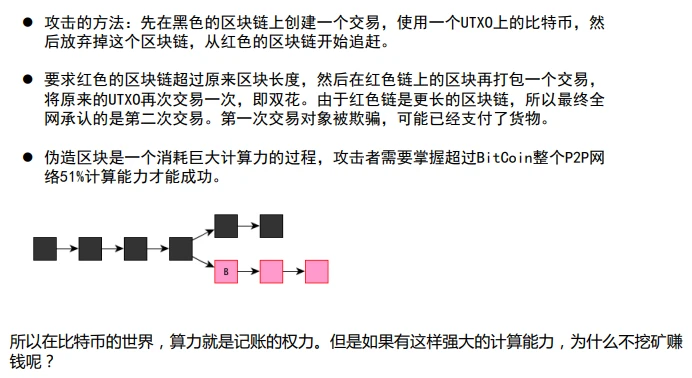
如果不同矿工如右图在不同链上打包区块怎么?全网承认的是最长链(工作量最大)
矿工都可以竞争打包过程,关键是看谁先计算出一个合法的nonce,让当前区块hash值前面有规定个数的0(比如5个)
0的个数由全网hash能力决定,每隔一段时间调整,大概十分钟能计算成功。
打包成功的矿工,交易费归他所有。
4.4.5. 区块链竞争