
1.基本原理篇
- 直觉上:我们递归构建随机划分树,所有实例均被划分即构建完毕;异常值,比较早的被划分,在树中路径长度比较短。论文中,提到了一个测试,如下图
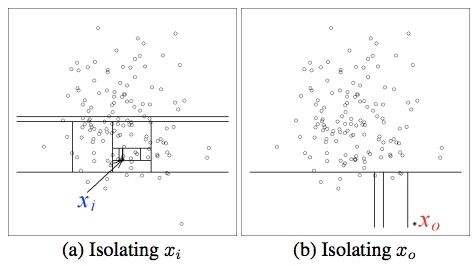
从高斯分布中随机生成135个点,上图中正常点xi需要12次随机的划分,而异常的点x0只需要4次划分。
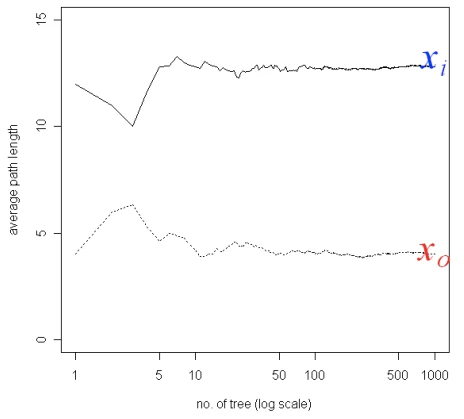
树的数量与xi,x0两个点平均划分长度的关系,可以看到随着树的增加,正常点和异常点的划分路径长度更加稳定
- isolation tree:T 是一个外节点(没有child) 或者是一个内部节点,包含测试和两个子节点;测试包含两个属性q和p,其中q表示具体某个维度的值,p表示对该维度切分的阈值,min(q) < p < max(q)
- 二叉树:内部节点有n-1个,那么外部节点就有n个,总节点数有2n-1个
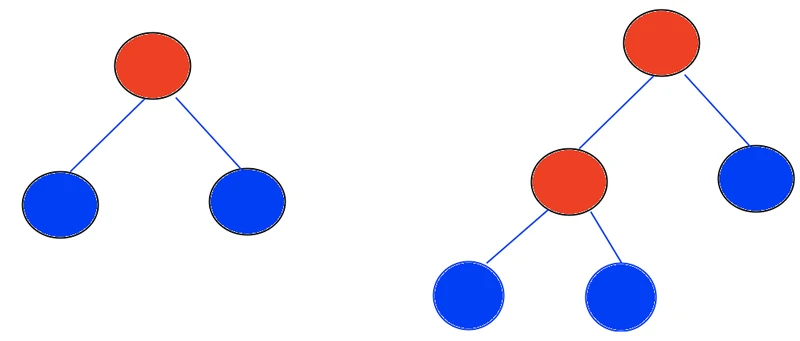
红色表示内部节点,蓝色表示外部节点,满足 外部节点数-内部节点数=1
线性增长
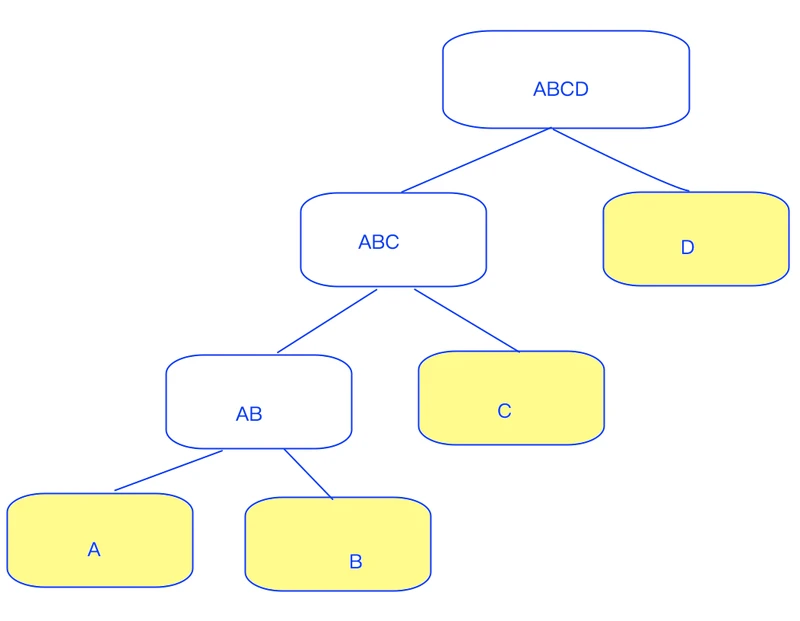
- path length:记为h(x) , x从树的根节点走到外节点的路径;下图中黄色节点ABCD均为外节点,h(D)=1,h(A)=3
- anomaly score:
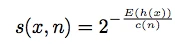
c(n) 主要作用是对h(x)做归一化,否则随着n越大,树的深度一般越深; 因为itrees的结构跟binary search tree的结构是一样的,所以h(x) 平均路径的估计采用n次不成功的搜索的平均路径,具体值为
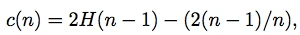
H(i) 是调和级数,可以用ln(i)+0.577来估计
- 根据s(x,n)公式:
- 若E(h(x))->c(n); 那么 s(x,n)->0.5;说明数据集不一定有异常值
- 若E(h(x))->n-1,那么s(x,n)->0;说明x是正常的
- 若E(h(x))->0,那么s(x,n)->1;说明x的平均路径很短,那么x为异常的可能性非常高
2.特点
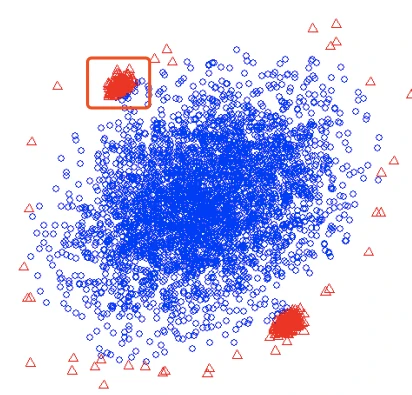
- 不需要大量正常的样本,值需要小样本就可以建模; 相反,大样本会减弱识别异常值的能力;paper中举了一个例子,基于Mulcross数据集,当用全量的数据4096个进行建模的时候,auc只为0.67;从中抽样128个,auc可以达到0.91,为什么呢?看下图,异常点的也非常聚集,密度高啊!
3.与其他经典算法的比较
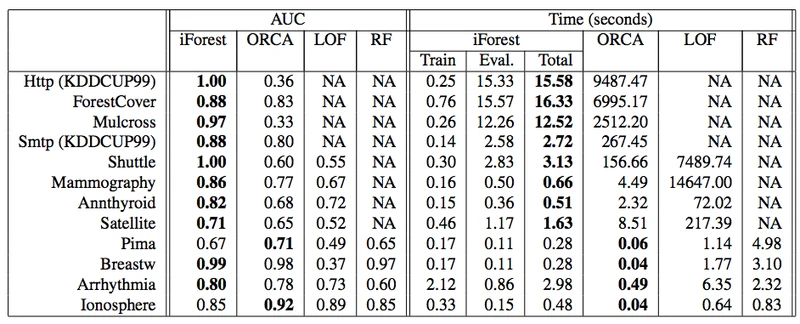
- 从上表中发现,iforest在大部分的数据集中,auc表现比较好;
- 从上表中发现,iforest的运行速度更加高效;
4.效率分析
- 基于Http 和 ForestCover两份数据集,发现auc在小样本的时候就收敛了;在http这个集中,采样数为128 ,在forestcover数据集中,采样数为512的时候,auc就收敛了。后续随着样本数的增加,auc提升不明显了;
具体结果见下图
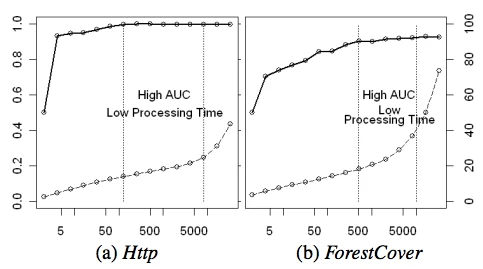
5.是否只用正常样本来做训练?
- paper中也做了一个试验,基于Http和ForestCover两份数据集,当训练样本中包含异常值的时候,测试集上的auc比 训练样本中不包含异常值的时候更高一些;
6.高维检测能力
- 高维的挑战在于,点在高维空间是非常稀疏的,距离度量通常是无效的
- paper中又做了一个测试,用Mammography和Annthyroid数据集,最多增加506个随机的服从01均匀分布的特征,作为模拟的噪声,整个数据集总共为512维(原始数据集是6维);首先通过峰度系数来计算每个特征的值,进行排序。我们按照这个排序,不断增加特征,主要是观察增加1~506个特征情况下,iforest的异常检测能力;当增加的维度(增加了6维)接近原始数据集维度的时候,auc表现比较好;具体见下图
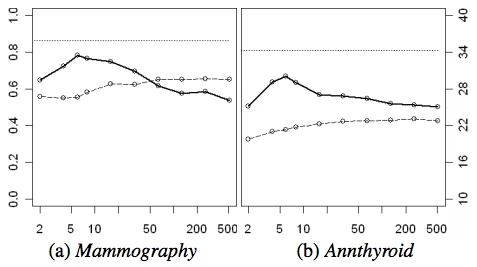
点实线为auc,点虚线为运行时间,最上面的横虚线为iforest在原始数据集上(6维)的auc,效果比12维要好;
7.实现工具
reference:https://scikit-learn.org/dev/modules/generated/sklearn.ensemble.IsolationForest.html
| 参数 | 参数说明 |
| n_estimators | 因为是ensemble,该参数表示树的数量,默认是100 |
| max_samples | 默认是auto,每颗树的样本数;返回是 256与样本数的最小值;或者可以 自己个数(int),或者样本数的占比(float) |
| contamination | 默认是auto,阈值跟原始论文一样;或者自己指定异常的比例 |
| max_features | 每课树的特征数,这个需要自己来指定;因为api默认为1,一般不大适用 |
| bootstrap | 如果是true,表示有放回的抽样;如果是false的话,表示无放回抽样 |
| n_jobs | 默认是None,-1表示使用所有的进程数, |
| random_state | 是否要固定随机种子,因为iforest算法中有很多随机的部分,比如特征的选择和切分都是随机的 |
|
|
|
| estimators_ | 每颗训练好的树的集合 |
| estimators_samples | 每棵树的样本集 |
| max_samples_ | 实际的样本数 |
| offset_ | 实际异常得分-offset,作为判断异常的界限 |
8.实现demo
>>> from sklearn.ensemble import IsolationForest
>>> X = [[-1.1], [0.3], [0.5], [100]]
>>> clf = IsolationForest(random_state=0).fit(X)
>>> clf.predict([[0.1], [0], [90]])
array([ 1, 1, -1])