
//个人学习记录,如有错误请指正
//大部分图片公式来源于《hand on machine learning with scikit-learn and tensorflow》
//部分公式来源于互联网
这一节,我们不研究任何新的单一模型,而在已有的模型上打开一个新的思路:我们如何能够将这些模型综合在一起,并且综合它们的长处,以提升预测能力。这便是这一节所要讲的集成学习方法。
投票分类
投票分类主要用于分类预测,其思想十分简单,第一个分类器有不到1/2的概率出错,于是我们选择多个不同的预测能力在1/2以上的分类器一起参与预测,最终让他们投票决定最后的分类的结果,被预测最多的类别作为预测结果。这种被称为硬投票。
这里,我们去证明当每个分类器预测概率大于1/2,且分类器之间相互独立时,分类器数量越多,我们预测成功的概率越大。我们用n表示分类器数量,p表示单个分类器预测成功的概率,n个分类其中X个分类器预测正确的情况符合二项分布(n,p),从中,我们可以认为,P(X>=n/2)为整个集成分类器分类成功的概率。之后我们进行如下证明。
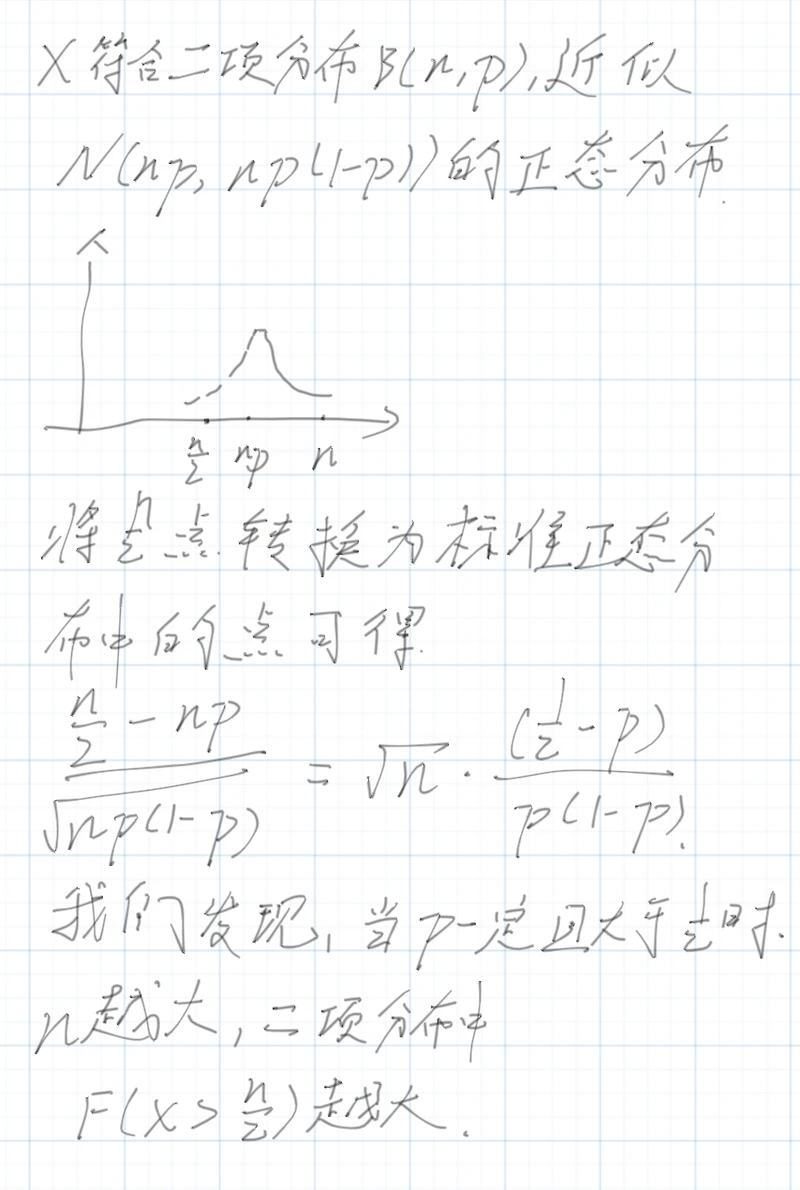
证明中,我们先将二项分布近似为正态分布,并且将点n/2映射到标准分布中,我们发现,n越大,P(X>n/2)概率越大,硬投票方法的有效性得证。
还有一种方式被称为软投票,它并不让每个分类器都直接给出预测类别,而让分类器给出对每个类别的预测确信度,最后找出确信度最高的一个类别。
而对于投票分类,我们既可以选择单一的模型,也可以选择多种模型的混合。在选择单一模型时,有下面这两种训练方法。
Bagging和Pasting
因为各个模型的核心都是相同的,因此为了在模型间制造出差异,让他们做到相互独立,我们需要让他们拥有不同的训练集,因此这两种方法实际上都是对训练集的划分方法。Bagging(装袋)指有放回抽样,每个分类器都从整个训练集中随机出去一部分作为训练子集。而Pasting(粘贴)主要是无放回抽样,它将整个训练集分为多个互斥子集,然后分给各个分类器作为训练集。
在这种集成学习模型下,其模型的偏差通常是相似的,但是常常拥有较小的方差,在训练上比较稳定,更难过拟合。
下面我们会看见更加复杂的集成方法,他们都具有一个特点,各个分类器之间的训练是有顺序的,后面训练的分类器往往依赖于前面的分类器的结果。
适应性提升(Adaboost)
适应性提升和梯度提升都具有一个特点,那就是他们的分类器要尝试弥补前一个分类器的不足,因此叫做“提升”。
适应性提升给予了每个实例和分类器权重,并且在一个分类器分类完成以后更新权重。最初每个实例的权重都是平均的。
在一个分类器训练完成以后,我们再用它在训练集上进行预测,同时得到分类器的权重。
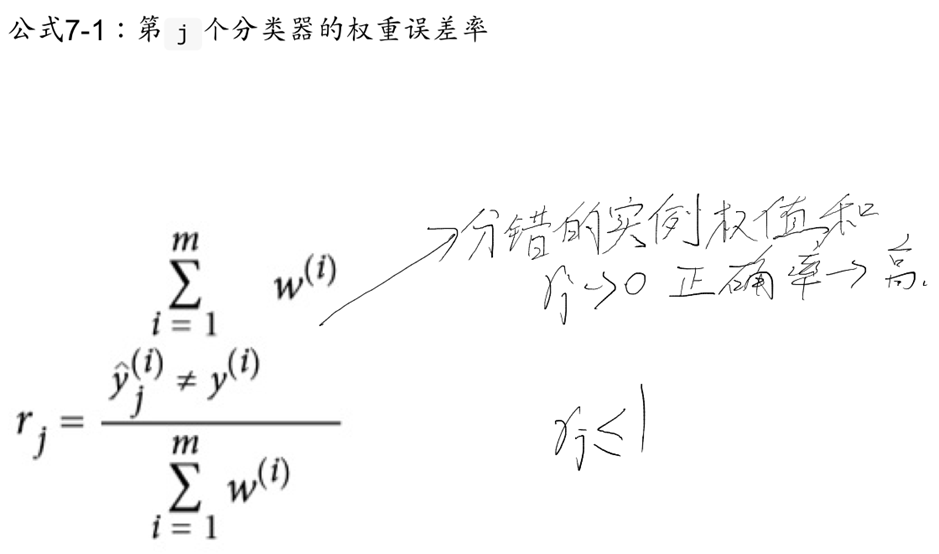

可见如果一个分类器预测正确的数量越多,它的权值越高,它预测正确的实例的权值越高,那它的权值也会越高。
接着我们更新实例的权值。

可以发现如果分类器权值超过0(rj超过1/2),那么被误分实例的权值会被提升,而如果分类器本身权值小于0,则误分实例的权值会下降。这种情况下,如果一个分类器表现还算良好,那么它所犯的错误就会因为权值较高更容易被后面的分类器弥补。
这样迭代下去,在分类器数量足够多,或者找到足够好的分类器之后,训练就会停止。
梯度提升
梯度提升与适应性提升类似,但是主要用于回归任务。
在梯度提升中,每一个分类器需要尝试去弥补上一个分类器的残差(预测值和真实值的差)。因此实际上每个分类器都在尝试学习预测上一个分类器留下的残差。最终将这些分类器的所有预测值加总,便得到最终结果。
Slacking
Slacking的思路比较独特,Slacking是分层的,每一次以上一层的输出(第一层的输入就是最初的输入)为输入,对预测值进行学习预测。
总体过程如下图所示。
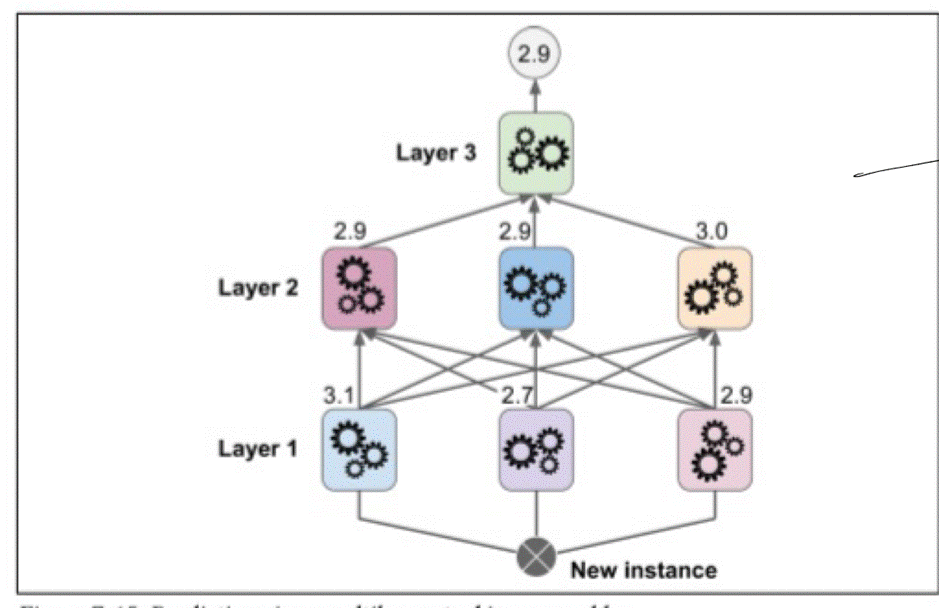
Slacking每一层在预测并且给下一层提供输入的时候采用的是非训练集。例如上图一共有三层,因此我们将训练集分为互斥的三个子集,A、B、C。第一层用A训练,然后预测B得到输出,作为第二层的输入,第二层由以此输入进行训练。最后再用C经过第一层、第二层的预测得到输出作为最后一层的输入,最后一层用此数据进行训练后得到最后的模型。
这个Slacking是不是很像神经网络呢?