
TAMER——Training an Agent Manually Via Evaluative Reinforcement
如今,尽管计算机系统及技术在许多方面已经超越人类,但在许多领域和任务中,人类的专业知识仍然是必不可少的。而TAMER正是这样一个框架,使得人类的知识可以对计算机模型进行训练,以达到节约训练成本,迅速收敛的效果。
一、什么是TAMER?
TAMER是由Bradley等人于2008年提出的一种学习框架Training an Agent Manually Via Evaluative Reinforcement,该框架将人类专家引入到Agents的学习循环中,可以通过人类向Agents提供奖励信号(即指导Agents进行训练),从而快速达到任务目标。
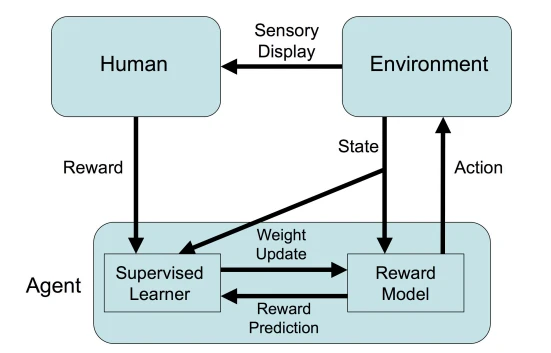
二、为什么要使用TAMER?它有什么优势?
尽管强化学习等技术在各个领域大放异彩,但是仍然存在着许多问题,比如收敛速度慢,训练成本高等特点。然而,在现实世界中,许多任务的探索成本很高。比如,某些任务可能会导致Agents的材料消耗巨大,出现死亡等风险。在金融市场中,一次错误的交易很可能会引起重大的损失。所以,如何加快训练效率,是如今强化学习任务待解决的重要问题之一。
而TAMER则可以将人类的知识通过奖励信号的方式训练Agent,使其快速收敛。它与Advice-taking agents, learning by human example等其它的人类参与训练的框架相比,它并不需要训练人员具有非常强的专业知识以及编程技术,更加简单易于实现。在传统的Advice-taking agents方法中,训练者往往要求与领域相关的专业技术、编程技术,并且需要向计算机提供奖励信号的原因。learning by human example同时也需要训练者具有很强的专业能力。而TAMER很多时候则仅仅需要培训人员简单的辨别好或者坏。
三、TAMER需要满足的条件是什么?
1.任务是确定性的。
2.两次操作之间有足够的时间让培训师提供反馈。
四、TAMER的执行过程
我觉得在论文中的伪代码很容易理解,所以我想通过解释伪代码的形式来展示TAMER框架的执行过程。
TAMER框架由3个部分组成,它们分别是RunAgent(), UpdateRewardModel(), ChooseAction().
其中:
- RunAgent()负责整体代码的初始化以及运行
- UpdateRewardModel()负责对人类给予的奖励信号的权重向量进行更新
- ChooseAction().负责选择下一步Agent的动作
下面将详细说明:
①RunAgent()

如图所示,
t
t
t表示为时间,也可以理解为迭代的当前次数,Agent每选择一个动作至整个loop完成后,t都会+1。在RunAgent()函数中,
t
t
t初始化为0。
w
⃗
\vec{w}
w 表示人类给予的奖励信号的权重向量。
f
t
−
1
⃗
\vec{f_{t-1}}
ft−1表示t-1时刻的状态特征(可以理解为t-1时刻的状态,这个状态被当成一个个的特征进行表示,比如在俄罗斯方块中,这个特征向量中则可以包含每一列的高度以及各列之间的高度差)。
f
t
−
2
⃗
\vec{f_{t-2}}
ft−2表示t-2时刻的状态特征。
w
⃗
\vec{w}
w ,
f
t
−
1
⃗
\vec{f_{t-1}}
ft−1,
f
t
−
2
⃗
\vec{f_{t-2}}
ft−2维度相等,都被初始化为对应数量的0向量。如Algorithm 1的第5行所示,首先从ChooseAction()中选取一个action并执行。
第6行 takeaction()代表执行这个动作。
第8行,之后整个执行过程进入了一个循环。
第10行,从人类的反馈中得到
r
t
−
2
{r_{t-2}}
rt−2,getHUmanFeedback()这个函数因任务的不同而有所不同。
第11,12行,如果
r
t
−
2
{r_{t-2}}
rt−2不等于0,即这个环节有人类的指导信号,则继续更新奖励信号权重向量
w
⃗
\vec{w}
w 。如果为0,则表明可能这一轮的循环中,人类并没有给出奖励建议或者说并没有参与指导,则不会更新
w
⃗
\vec{w}
w 。
②UpdateRewardModel()

在12行的时候,主函数调用了Algorithm 2,即UpdateRewardModel(),它的输入参数为人类奖励信号
r
t
−
2
{r_{t-2}}
rt−2,
w
⃗
\vec{w}
w ,
f
t
−
1
⃗
\vec{f_{t-1}}
ft−1,
f
t
−
2
⃗
\vec{f_{t-2}}
ft−2,以及学习率
α
\alpha
α。
第二行,
Δ
f
t
−
1
,
t
−
2
⃗
\vec{\Delta f_{t-1, t-2}}
Δft−1,t−2为
f
t
−
1
⃗
\vec{f_{t-1}}
ft−1,
f
t
−
2
⃗
\vec{f_{t-2}}
ft−2的差值,它代表着两个状态之间的变化情况。
第三行,
p
r
o
j
e
c
t
e
d
R
e
w
t
−
2
projectedRew_{t-2}
projectedRewt−2表示为预测的奖励。为输入的奖励权重
w
⃗
\vec{w}
w 与
Δ
f
t
−
1
,
t
−
2
⃗
\vec{\Delta f_{t-1, t-2}}
Δft−1,t−2的累加乘积。(即如果
f
t
−
2
⃗
\vec{f_{t-2}}
ft−2有20个状态特征,那么则有20个特征与
w
⃗
\vec{w}
w的乘积累加)
第四行,由人类提供的奖励信号减去预测的奖励信号,则可以得到它们之间的一个误差。
第5,6行,通过这个误差,对新的奖励权重进行更新。
③ChooseAction()

在主函数(RunAgent())第12行完成后,回到主函数第13行,调用ChooseAction()函数,它的作用是选择下一步动作。
在这个函数中,需要输入的是当前状态
s
t
s_t
st以及奖励向量
w
⃗
\vec{w}
w
第一行,
g
e
t
F
e
a
t
u
r
e
V
e
c
(
s
t
)
getFeatureVec(s_t)
getFeatureVec(st)的作用是从状态
s
t
s_t
st中获取状态特征
f
t
⃗
\vec{f_t}
ft
第2,3,4,5,6行,从该状态中执行所有动作并计算预期奖励。
第三行中
T
(
s
t
,
a
)
T(s_t,a)
T(st,a)为状态转移方程(已知的),它可以通过当前的状态以及所执行的操作得到t+1时刻执行a操作的状态
s
t
+
1
,
a
⃗
\vec{s_{t+1},a}
st+1,a
第四行通过状态特征转化方程得到t+1时刻执行a操作的状态特征
f
t
+
1
,
a
⃗
\vec{f_{t+1},a}
ft+1,a
第五行得到
f
t
+
1
,
a
⃗
\vec{f_{t+1},a}
ft+1,a与
f
t
⃗
\vec{f_t}
ft的差值(类似UpdateRewardModel()中的第二行)
第六行则利用该差值计算t时刻执行每个动作后的预测奖励
p
r
o
j
e
c
t
e
d
R
e
w
a
projectedRew_{a}
projectedRewa
最后,ChooseAction()函数的返回值即是另
p
r
o
j
e
c
t
e
d
R
e
w
a
projectedRew_{a}
projectedRewa最大的动作a。
之后,返回到主函数执行其余操作,执行动作a,得到新的state,并更新 f t − 1 ⃗ \vec{f_{t-1}} ft−1, f t − 2 ⃗ \vec{f_{t-2}} ft−2。
以上就是TAMER框架执行的全部过程。
四、总结
TAMER框架使人类参与到Agent训练过程中成为可能,它与传统强化学习技术的区别是它考虑的仅仅是即时奖励,而强化学习技术则考虑长远的收益。它具有收敛速度快,训练成本低的特点。但是同时,也有学者论证,它的长期学习能力并不如强化学习。所以将各种技术融合可能才是未来的趋势。
原文地址:
https://www.cs.utexas.edu/~bradknox/papers/icdl08-knox.pdf