
声明:本文首发于CSDN,禁止未经许可的任何形式转载,可咨询文末的责编。
多机房架构存在的原因
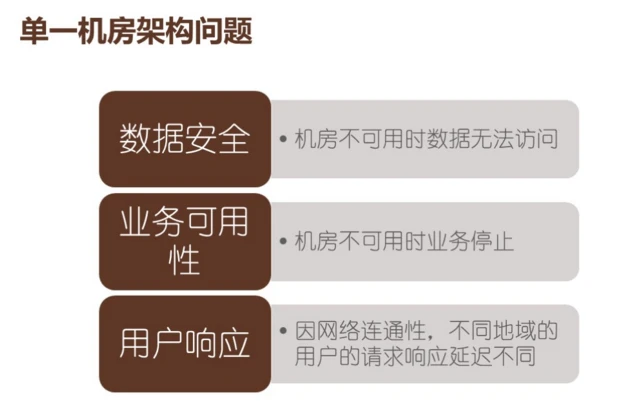
单机房一旦死机,断电、维护根本无法挽回整个数据,想离线读取等都不行。当一个机房不可用,所有的业务就都不可用。荔枝 FM 要求业务离用户最近,南方的用户连南方的机房,北方的用户连北方的机房,国外的用户连国外的机房。大陆的网络和国外的网络有一定的隔离性,如果没有做多机房的连通性,数据的传输和实时性就会有问题。

跨机房的作用是为了备份,一个机房的数据放在另一个机房是异地多活。上面是数据容灾,下面的是业务容灾,第三个是让服务离用户最近。这是荔枝 FM 做跨机房的原因。

做过数据备份的各位一定知道CAP理论。2000年加州伯克利大学认为分布式系统有一致性,所有节点在任何时间都可以访问到最新的数据副本;每个请求都能收到一个响应,无论是成功还是失败,必须有服务器的响应,而不是TCP超时、TCP断开等;其中一个区挂了,不影响其他分区。
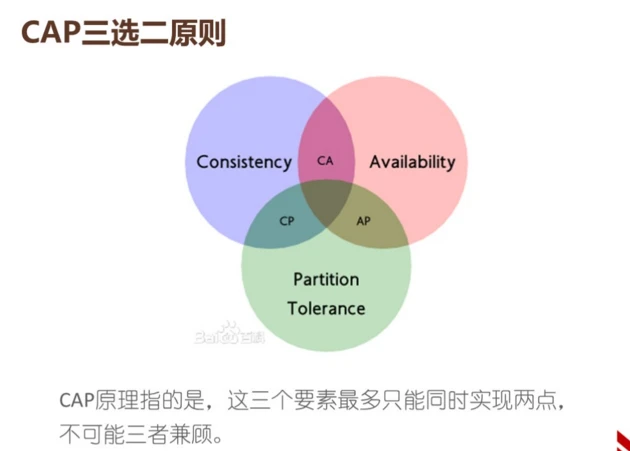
这三个特性无法共存,只能取两点,牺牲另一点。
AC模型,可用性+强一致性,牺牲了分区容忍性。比如MySQL Cluster集群,内部还是可以用的,MySQL集群提供两阶段提交事务方式,保证各节点数据强一致性。MySQL的集群无法忍受脱离集群独立工作,一旦和集群脱离了心跳,节点出问题,导致分布式事务操作到那个节点后,整个就会失败,这是MySQL的牺牲。
CP模型,一致性+分区容忍,牺牲了可用性。Redis客户端Hash和Twemproxy集群,各Redis节点无共享数据,所以不存在节点间的数据不一致问题。其中节点大了,都会影响整个Redis集群的工作。当Redis某节点失效后,这个节点里的所有数据都无法访问。如果使用3.0 Redis Cluster,它有中心管理节点负责做数据路由。
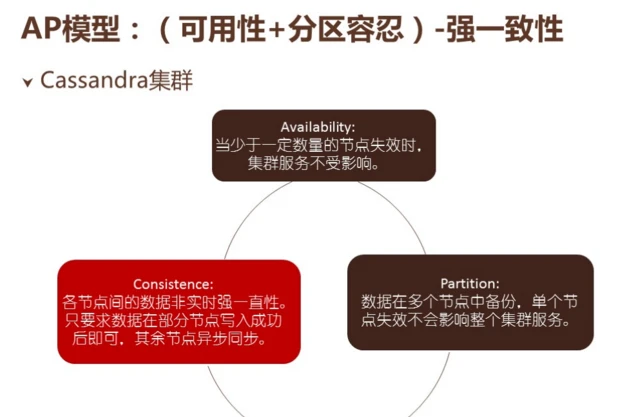
AP模型,可用性+分区容忍性,牺牲了强一致性。荔枝 FM用Cassandra集群时,数据可以访问,数据能备份到各个节点之间,其中一个节点失效的话,数据还是可以出来的。而分布式事务的各个节点更新了提交了只是其中一部分节点,底层继续同步,这是AP模型。
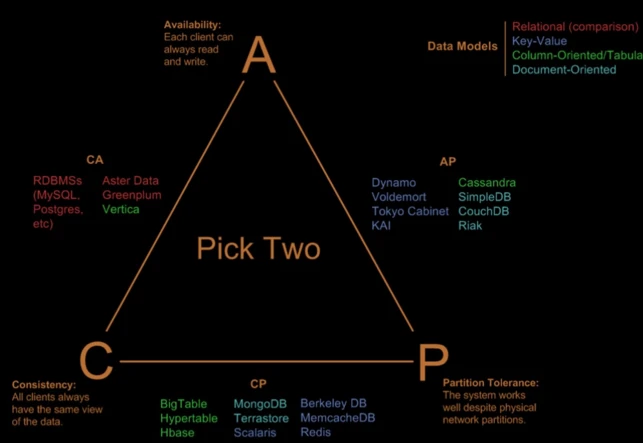
AC是高可用性和高强制性,所有的关系型数据库、PG等都是强一致性,牺牲了分区容忍性。MongoDB和BerkeleyDB的可用性比较差。AP模型缺少了强一致性。

互联网行业模型。不同的业务类型要求不同的CAP模型,CA适用于支付、交易、票务等强一致性的行业,宁愿业务不可用,也不能容忍脏数据。互联网业务对于强一致性不高,发个帖子要审核,没人看到无所谓。发一个音频要进行编码审核才能看到。

Base模型是什么?eBay工程师提出大规模分布式系统的实践总结,在ACM上发表文章提出 Bash 理论是基本可用、软状态和最终一致性。不要求实时一致性,但一定要实现最后一点。
基本可用(Basically Available)。分布式系统在故障时允许损失可用性,保证核心业务可用。音频直播或是做活动时,当业务量非常大的时候可以降级。做游戏也是,在战斗的时候最关心数值的增长,看了多少人都无所谓,缓解核心内容的压力。
软状态(Soft State)。允许系统中出现的中间状态,中间状态不会耽误可用性。在写代码、编程业务的设计上,必须容忍有一定的临时数据同步,考虑到全局锁和数据多版本的对比,把各个节点的相关数据都上锁,这是一个悲观锁,一旦写任务,其他人都能改我的数据,这是比较悲观的心态。
而数据多版本,类似于乐观锁,导致其他人和我方数据冲突的机会并不是那么多,只要在提交的时候发现版本不一样,更新一下,汇总数据就可以了。做好业务上的隔离,多数情况都属于多版本,技术都能解决,不一定要把所有的东西都锁死。允许有一定的临时数据。最终一致性,在临时上的数据不一样,数据同步也是要花时间的。
随着时间的迁移,不同节点的数据总是向同一个方向有一个相同的变化,这是Bash模型。这种模型非常适合互联网业务的发展。
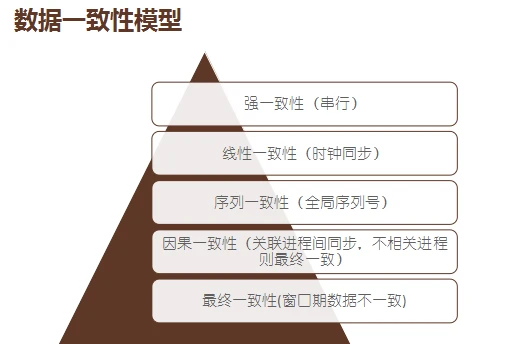
数据一致性模型。允许窗口期数据不一致,互相关联的数据要同步。序列一致性,全局按照序列顺序来做。线性一致性,每一个时间的时钟要同步,时间序列是严格的,按顺序的。最后是强一致性,一个时间只能实行一个任务。这比较适合于互联网,所以荔枝 FM 选择了最终执行。
系统业务调研
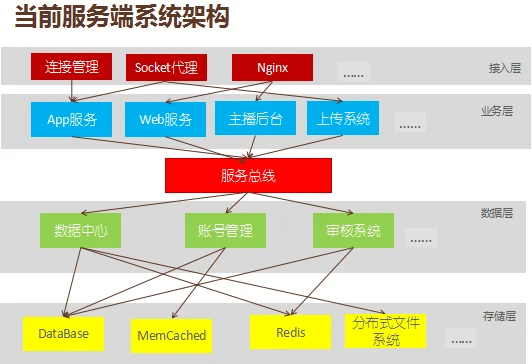
简单介绍下荔枝FM的系统架构。客户端接入代理,往上到服务器。服务器专门对手机进行业务处理,后面是数据中心,数据中心后面是存储,有Redis、MySQL和Memcached,这是一个简要的结构。变成一个分层的结构,分层结构和大家的业务差不多,首先是接入层,接入层负责连接管理、Socket代理、Nginx,Socket代理专门对连接状态进行管理。业务层,比如手机服务、网站服务、后台以及各种各样的业务层。下面有服务总线,接下来是数据层,专门对数据逻辑进行管理。最下面的是存储层,比如有数据库、Bash、Memcached、Redis。

业务数据分析。荔枝 FM 要求跨机房同步,一是资源文件,向用户上传的音频、图象、头像、图片,数据量非常大。数据量一旦不同步,用户会反应比较强烈。比如用户发表评论,发表完不见了,用户会很紧张,会不停的刷,想找出是软件问题还是网络问题。因此这点的优先级非常高。荔枝 FM 用了机房专线,它的故障率比较低,响应时间也比较低。后备限制公网,用两种策略进行传输。
架构设计
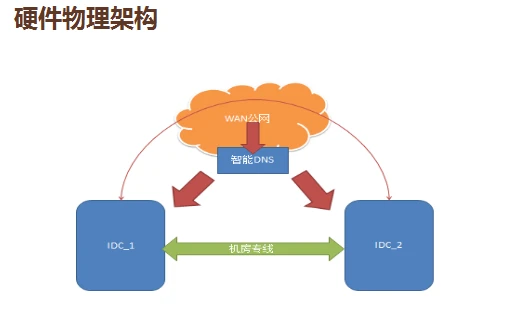
荔枝 FM 有两大IDC机房,一是绿色的机房专线,这是高速通道,二是红色的公网,类似于国道,比较便宜,这里有两个机房,为了离用户更近,因此选择用智能DNS看用户的机房。
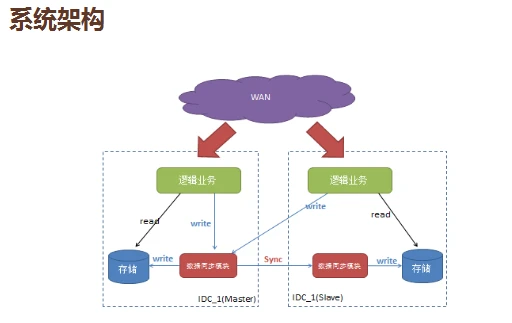
系统架构方面。两个业务数据之间怎么进行管理?我们设置了一个主机房,Master和Slave,所有的业务都是读自己机房内部的,都会往Master方向写,然后同步在同一个机房,了解读业务比写业务高几个数量级。主机房在北京,北方的用户直接写在自己的本机,然后回应。南方会把请求发到北京机房,异步传输回来同步到南方的机房里。
机房内部怎么做?我们提供了数据访问层API,封装了下面所有同步,程序员和开发人员不用担心,下面都有Data Store接管。代理服务器可以根据你的类型往本地的存储性能去读。它会区分用户写、数据库写还是好友写,分发到不同的DS服务端,处理完成告诉用户 OK了。另一步进行分发,到另一个机房同步,是读写分离的系统架构。
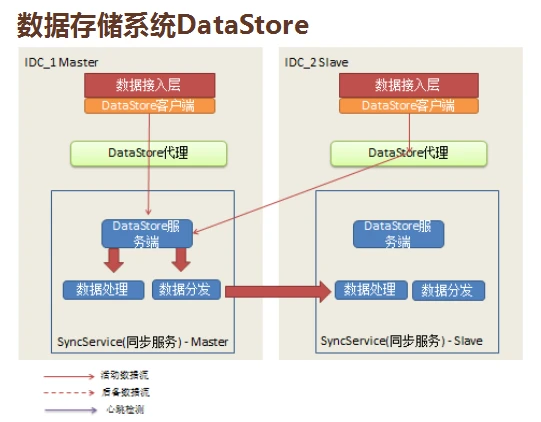
接入层、客户端,通过代理往DS服务端写数据,资源分发同步。失效怎么办?左边的Master是主的,由DS代理进行检测,如果没响应,马上切换到另一个机房,穿到另一个机房里,把数据写到Slave,等到这个机房的数据恢复后,再手动切换回来,这是主失效。
重失效的话,会将它缓存起来放在文件里,等恢复后,再推送数据缓存过去。最麻烦的是老链问题,两头是活的,中间链断了,南北之间IDC链路,不管是专线还是公网都有可能会抽风,心跳检测出问题后,两边会独立写。DS代理认为这边服挂了,Slave认为主挂了,直接把数据往这边写。当线路恢复时,两边同步数据,要尽量避免数据冲突,这时候系统监控到底是哪一个链路出问题,果断关闭,减少数据冲突的风险。
由于配置服务器把所有配置发放到服务器里,监控、报警、数据报告会通过邮件、微信的手段告诉运维人员和开发人员,运维数据中心把所有的日志导入到数据库,更方便技术团队进行分析。
最佳实践
首先把坑总结出来:一是数据切分,当数据量到达一定的情况,一定会出现分片,分片有两种,一是用户库、电台库、数据库;二是ID,尾数1是1,尾数2是2。

这种情况可以先纵切,一来对开发来说比较简单,带来的改观比较大,对压力的改善也比较大,纵切横切。当业务分得不能再分时,就要进行横切了,把所有ID进行Hash拆分。数据只改不删。尽管开了MySQL的Lock,里面没有任何的办法手动回滚。用户投诉一个月内有效。异步能提高系统的响应,改善系统的使用效率,避免现场挂死,但会增加一定的编程复杂度。对此,荔枝 FM 有一套比较简单的异步接口,进行异步操作。
所有的外部RO操作都有可能,业务量大的时候连写日志都会导致业务受影响,任何IO操作都要考虑到慢的可能性。复杂的逻辑处理也是异步,比如登录,对要访问第三方平台的数据,和第三方进行较验、检查。

要提高程序的可测试性,需要有测试驱动。出问题后马上跑测试驱动,发现业务问题还是数据受影响了。写好代码提交后,会不会对旧的有影响。运行日志统一收集,分布式系统的业务可能会分发到各个不同的节点,把所有的数据拿出来统一监控。可以马上了解并及时响应,而不需要人肉去查看。

持续逻辑对一致性可容忍。如insert之后马上select刚插入的记录,由于读写分离,有可能是无法读取刚生成的记录。中间没有时间允许重复数据,这就没有数据出来,所以不能用这种方式去做。

关于幂等操作,分布式系统有三种状态,成功、失败和超时。超时非常难搞,可能是请求处理了,但没有响应,也有可能根本没处理,调用者根本不知道是哪种情况。如果操作不幂等,客户端会出现数据失败和冲突。
每次同一个操作都不会影响数据,都会产生同一个结果。同一个ID记录,用Replace或是insert把新的技术代替原来的技术。这点不能一概而论,需要看场景,它的效率比较低。

虽然在内网里感觉不到,但在两个IDC之间是有网络延迟的,对比很明显。要先拉一个请求,发送端发一个回应。推,不管对方要不要,都直接发送。技术团队测试过北京和广东之间的正常值是40毫秒,加一个请求的话达到了80毫秒,这种效率是不能容忍的。
推的问题是“我推给你,你不一定能接受”。接收只是写日志,执行由另一个来做,即使接收了还要记录。下一次再连上来,告知发送者再次接收。

监控很重要,由于链路、老链问题,CPU、内存、磁盘、网络、文件描述服务、读写IO位置等任何一个环节出问题都会导致系统卡,每发现一个卡的节点就要增加一个监控,每查处一个就加一个监控。
业务进程监控。所有的错误与警告日志、内存泄露、命令响应速度,慢的比例比较大的时候就要报警了。
存储系统监控。像数据库、缓存的操作量、并发量、慢查询。服务监控包括消息拨测、网络拨测。
实时报警。邮件、IM、短信,让技术人员可以及时收到。而报告,日报、周报、月报、分时曲线、峰值、高水位和低水位,这些影响的是扩容和增加业务量的时机。运营和产品增加了某个活动,程序员很多时候是不知道的,因此当沟通出现问题时,业务上有什么峰值的活动,技术这边可以通过这些马上了解,而不是靠业务人员口头通知。

业务架构要易于随时扩展和缩减。首先,遇到瓶颈时,能迅速扩容,加一台机器。其次,一定要对上层业务透明。第三,加机器或节点必须增加配置或是更改配置,配置完成后重启激活。强硬的中断和重启,对大量的业务有非常大的损坏。做游戏时,量不是用钱买能回来的,按照老板的说法:失效一分钟,几十万量钱都没了。第四,要提供一键式操作预案,只需要一次点击即可。这让每一步都胆战心惊,错一个字母或者多一个空格都可能会出现不可预估的后果。

架构师相当于产品经理,用户相当于程序员,产品为用户服务。封装好的API一定要简单易用,而不是注册、初始化、挂监听,一个API简单明了。
此外,要与业务解耦。业务要和整体的的框架剥离,技术团队会根据业务优化,但尽量不要让业务关心我们的架构变动,减少依赖。配置一定要简单,约定优于配置,引入这个框架要配置一大堆东西。如果不知道这个配置有什么用,程序员就不敢配。因此我们提供一个默认配置,只要直接引用包就能用,至于你要个性化的属性或操作,可以看文档和接口。这样能更好的适应业务的灵活变动,让程序员更快地根据业务迭代去做开发。
分享人:刘耀华,荔枝FM架构师,负责荔枝FM服务端系统架构设计与实施,以及数据中心异地多活方案的设计。对服务端系统架构进行分布式集群、高可用、负载均衡等有多年经验与心得。
架构技术实践系列文章(部分):
- 沈剑:58同城数据库架构最佳实践
- UPYUN的云CDN技术架构演进之路
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构
本文整理自荔枝FM架构师刘耀华日前在“UPYUN架构与运维大会·深圳站” 上的主题演讲。UPYUN 架构与运维大会是国内领先的新一代云CDN服务商UPYUN独家主办的大型技术会议。大会面向全国运维和架构从业者,邀请业内一线的架构师和运维专家进行纯干货分享,旨在推动各项运维技术、产品架构等在互联网和移动互联网的研发和应用。
(责编/钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,交流探讨可加微信qshuguang2008,备注姓名+公司+职位)
「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008入群,备注姓名+公司+职位。