
我们上次在说HTTP版本区别的时候说了,在HTTP1.0的时候加入了报头,报头中包含了很多信息。报头分为两种:一种是请求报头一种是响应报头,自然就是一个是请求的时候发送的一个是响应的时候发送的。
-
请求报头由四部分构成请求行、请求头、空格和请求数据
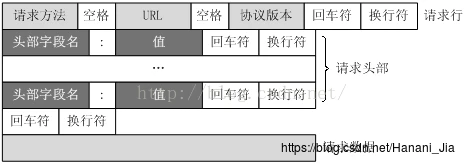
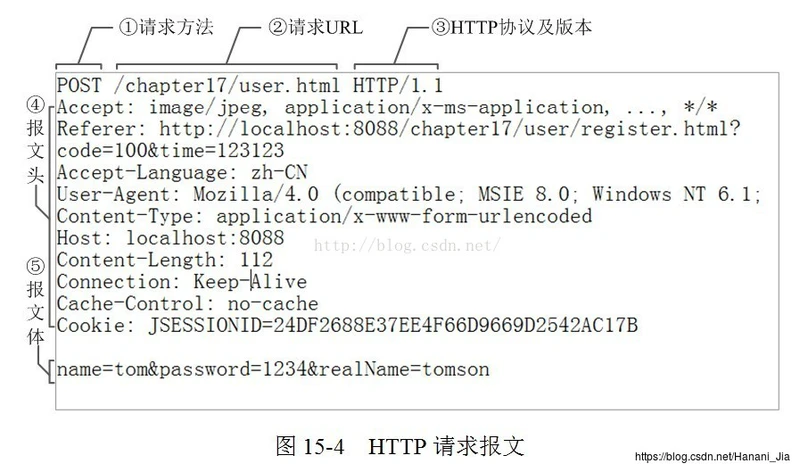
这里我们看当你访问百度的时候的请求报头
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer:https://www.baidu.com/s?wd=HTTP%20%E5%8D%8F%E8%AE%AE%E6%9C%89%E5%87%A0%E7%A7%8D%E5%92%8C.....
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: zh-CN,zh;q=0.8
Cookie: BIDUPSID=670A04B660AAF2716D3120BEAF946A11; BAIDUID=2454D4.... RA-Ver: 3.0.8 RA-Sid: CA623F7A-20150914-060054-2b9722-5fde41
第一行是GET / HTTP/1.1 这一行指出了请求的方法是GET协议的版本是HTTP1.1。
第二行是Host在HTTP是1.1版本时,是必须指明host的,不存在还会报出错误。
第三行Connection: keep-alive 是让我们的链接保持长链接状态,这样节省了建立新链接的时间消耗
第四行User-Agent指明了我们发送请求的客户端的信息例如版本等信息
第五行Accept列出了当前浏览器可以接受的数据类型例如上边的html、tesxt、image等等
第六行Referer是浏览器告诉服务器它是从哪个资源来访问的这个界面的,也就是说这里边包含一个URL,用户就是从这个URL来访问当前界面的。
第七行Accept-Encoding表明浏览器可以解码的数据编码方式,这里有个gzip有些网站就支持返回gzip编码的HTML页面这样的话可以减少很多的下载时间。
第八行的Accept-Language表明浏览器希望接受的语言类型
第九行的Cookie这是网络中的一种机制,通过这个文件可以由浏览器向服务器带去数据。
并不是说所有的请求报头都是完全按照这个格式,请求报头中有很多个选项,例如Range:Range头域可以请求实体的一个或者多个子范围。例如表示头500个字节:bytes=0-499,这也就实现了我们之前所说的HTTP1.1的请求部分资源和断点续传的特性。例如Pragma:指定“no-cache”值时无论是否代理服务器中存在缓存,都要向源服务器发送请求等等。
所以通俗来说请求报头就是在浏览器也就是客户端向服务器请求数据的时候提出的一些要求和想要告知服务器的一些信息。
-
响应报头则是服务器在响应浏览器的时候服务器给浏览器的一些信息,同样响应报头也是由响应行、响应头、响应体三部分来组成的。
