
文本识别技术(OCR)可以识别收据、名片、文档照片等含文字的图片,将其中的文本信息提取出来,代替了人工信息录入与检测等操作,降低了输入成本,快速、方便,提升产品的易用性。
随着技术的发展,OCR已经深入生活的诸多方面。交通场景下,主要用于车牌识别,便于停车场管理、智能交通、移动警务等;生活场景下,主要用于证照识别,便于提取身份证、银行卡、护照、结婚证、户口本、营业执照等证照图像的文字信息,还可对街景路牌进行识别;票据场景下,主要用于发票凭证识别,便于银行、税务等大量票据表格录入及长期存储;其他场景下,可以利用OCR对书籍、报告、简历、合同等文件进行识别,将纸质文件电子化,便于保存和查看。
Demo

HMS Core机器学习服务OCR能力在2020年01月15日首次上线,为开发者们提供了丰富的API接口,HMS Core OCR能力支持任意角度的文本识别,对横竖排、弯曲文本精准识别的同时,还能对文本段落进行准确划分,对文本内容精确定位。为了保证一些卡证、票据的隐私性,HMS Core OCR能力还支持端侧和云侧推理,端侧适合相机或视频画面实时处理,图片中稀疏文本识别,当调用端侧接口时,可识别中文(简体)、日文、韩文、拉丁语(包括英文、西班牙文、葡萄牙文、意大利文、德文、法文、俄文)10个语种;云侧对文字识别精度要求高,适合图片中稀疏文本识别、文档图片密集文本识别,当调用云侧接口时,可以识别中文(简体)、英文、西班牙文、葡萄牙文、意大利文、德文、法文、俄文、日文、韩文、波兰文、芬兰文、挪威文、瑞典文、丹麦文、土耳其文、泰文、阿拉伯文、印地文19个语种,核心语种的识别精度达到行业顶尖水平。
基于用户需求和技术进步,HMS Core 机器学习服务OCR能力进行了升级优化:端侧模型轻量化、准确率提升。
能力演进:
1、端侧模型轻量化:文本识别端侧10个语种能力增强(模型层面)
KPI不变,端侧模型轻量化压缩42%,运行所占内存从之前版本的19.4M降到11.1M左右。
模型的轻量化将模型体积缩小,并且可以轻量化展示,内存占比小,运行更加流畅。
2、准确率提升:云侧OCR能力演进(中文模型)
云侧OCR中文识别准确率从87.62%提升到92.95%,高于行业平均水准,竞争力大幅提高。
技术描述:
OCR是通过检测纸上的字符,以检测暗、亮的方式确定其形状,而后用字符识别法将形状翻译成计算机文字的过程。即针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
由于通用领域中存在大量弯曲文本的情况,算法团队通过重新设计文本检测模型,在横向文本的基础上,增加了任意旋转角度、弯曲文本的支持,使得在出行、广告牌等场景下的准确率和易用性大大增加。
文本识别还支持纯端侧推理,在涉及各类卡证、票据等隐私信息的场景下,相比云侧服务更加安全、可靠。考虑到端侧设备的算力、功耗等因素,算法团队通过巧妙的模型框架设计、量化、剪枝等技术,在保证识别精度的情况下,将识别模型压缩到商用的标准,保证用户的使用体验。
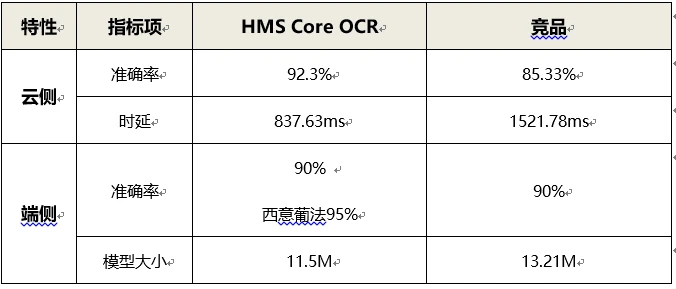
竞品对比:
OCR能力演进后,端侧和云侧的识别准确率都在业界属于领先地位。
云侧平均准确率高于竞品约7%,时延仅为竞品的55%。
端侧平均准确率和模型体积均优于竞品,一些小语种的准确率甚至达到95%。
优化更新:
- 基于现在市面上OCR能力大多只针对印刷体字符, HMS Core机器学习服务正在进行通用手写体识别能力的开发(手写体识别、手写体+印刷体混合识别)。
- 加入更多语种,预计新增罗马尼亚语、马来语、菲律宾语等。
- 预计新增版面分析功能(PDF重排),机器学习服务支持多种内容识别处理功能,提升自身AI能力竞争力。
为了满足众多场景需要,HMS Core会不断开发新功能帮助开发者构建多元化应用,后续新增功能以华为HMS Core机器学习服务联盟官网为准。
了解更多详情>>
访问华为开发者联盟官网
获取开发指导文档
华为移动服务开源仓库地址:GitHub、Gitee
关注我们,第一时间了解 HMS Core 最新技术资讯~