
自动预处理方法对于处理大量公开可用的EEG(脑电图)数据库至关重要,但由于我们缺乏用于比较这些方法的数据质量指标,因此最佳方法仍然未知。在这里,我们设计了一个简单但稳健的EEG数据质量度量标准,用于评估两个实验条件之间在100毫秒刺激后时间范围内的显著通道百分比。由于EEG中的容积传导现象,如果没有噪音,大多数与大脑活动相关的电位(ERP)应该在每个单一通道上都可见。通过使用三个公开可用的EEG数据集,我们发现,除了高通滤波和坏通道插值外,自动数据校正对显著通道的百分比没有影响或显著降低了该百分比。参考和先进的基线去除方法对性能有显著不利影响。拒绝不良数据段或试验不能弥补统计能力的损失。自动独立成分分析(ICA)拒绝眼睛和肌肉活动未能可靠地提高性能。我们使用先进的开源EEG软件(EEGLAB、FieldTrip、MNE和Brainstorm)比较了优化的预处理EEG数据流程,以最大化ERP的显著性。结果显示,只有一个流程明显优于单纯的高通滤波数据处理。本文发表在Scientific Reports杂志。(可添加微信号19962074063获取原文及补充材料,另思影提供免费文献下载服务,如需要也可添加此微信号入群)。
引言
脑电图(EEG)是一种相对低成本的脑成像方式,允许收集大量数据,因此,自动预处理方法对于处理大量公开可用的EEG数据库至关重要。然而,EEG数据通常带有噪音,并经常受到来自环境或参与者的干扰。参与者的眼动以及面部、颌部和颈部肌肉收缩产生的头皮电位大约是大脑信号幅度的10倍,需要被去除。一种去除噪音的策略是在事件相关电位(ERP)范式中重复呈现刺激。另一种补充策略是使用数字信号处理来去除干扰。
目前,大多数软件推荐的去除EEG干扰的方法是由EEG研究专家对原始EEG数据进行视觉检查。这个过程既耗时又不精确。关于什么是EEG干扰并没有共识,因此一个研究者的数据清洗可能与另一个研究者的不同。其中一个原因是EEG数据存在很大的个体间变异性,因此EEG信号的幅度可能因参与者而异。理想情况下,多个研究者会清洗同一组数据,他们的汇总选择将被用于数据清洗。这种评审者间的一致性是EEG数据拒绝的黄金标准。然而,实施评审者间的一致性是困难的。手动清洗多个受试者的EEG数据需要好几天的时间。据我们所知,只有一个带有多个评审者标记拒绝的数据集已经发布。我们使用了这个数据集来确定哪种自动干扰检测方法产生了最佳结果,并发现所选算法与每个人类之间的一致性更高,而人与人之间的一致性则较低。
在等待更多这样的手动标记数据集来测试自动预处理和清洗流程时,我们可以使用其他方法来评估预处理数据质量,特别是实验条件下大脑反应的幅度。多元宇宙分析(Multiverse analyses)是朝这个方向迈出的一步,尽管它们仍然依赖于预定义的事件相关电位(ERPs)。在本文中,我们开发了一种通用方法,用于评估在不同刺激条件下检测大脑反应差异的统计功效。我们使用这种方法来确定过滤、参考、在不同软件中排除干扰以及基线去除是如何影响EEG数据的统计显著性的。最后,我们设计并比较了不同开源软件包中的一系列自动化处理流程。
方法
数据质量指标
对于图1,我们对数据进行了0.5 Hz的高通滤波(我们使用了默认的EEGLAB汉明窗同步FIR滤波器,该滤波器是Firfilt插件(v2.6)的一部分,具有0.5 Hz的高频截止和默认参数),并提取了3秒的时期(从-1秒到2秒),没有进行基线去除。我们计算了每个受试者在每个潜在时延(以50毫秒为增量)处的随机重采样的50个时期中显著通道的数量,并进行了20,000次重复(补充图1)。然后,我们计算了每个潜在时延处的中位数和中位数绝对偏差(MAD)。为了找到最显著的窗口,我们平滑了中位数值(大小为3的移动平均滤波器)并取了最大值。最大效应量的100毫秒窗口被定义为该潜在时延加上和减去50毫秒。
对于图2、3、4和5,我们对上面选定的100毫秒时间窗口内的电位进行了平均。为了加快处理速度并与标准ERP分析实践保持一致,我们提取了1秒(从-0.3秒到0.7秒)而不是3秒的时期(“基线”部分除外)。由于没有去除基线期,数据时期的长度不影响数据质量度量(除非拒绝连续数据部分,在这种情况下,可能会提取更多的1秒时期而不是3秒时期)。对于每个通道和每个受试者,我们从每个条件中随机选择了50个时期(可替换),并使用非配对t检验(EEGLAB的ttest_cell函数)计算了条件之间显著通道的百分比(p < 0.05)。我们重复了这个过程20,000次,以获得每个受试者的显著通道的平均百分比(每个受试者一个值)。
在比较预处理方法时,我们的零假设是各种方法之间没有差异。我们计算了方法之间的成对差异(以受试者为案例),并使用20,000次自举法计算了置信区间和显著性(这相当于使用配对t检验,尽管与t检验不同,它不要求数据呈正态分布)。当某种拒绝方法为某些受试者去除了太多的试验时(见下文),我们在计算显著性时忽略了它们。
数据清理和显著性计算
一些方法涉及数据清理,这些方法标记了不良的数据试验。对于这些方法,由于显著性受试验次数的影响,我们没有使用50个试验进行自举,而是使用剩余的数据试验次数来计算显著通道的百分比——除了在讨论部分,我们使用50个试验进行自举,以评估拒绝方法是否能够提取一组良好的试验(大多数都能)。当使用所有剩余的数据试验来计算显著性时,我们检查了我们的性能指标是否饱和,以及是否所有电极都是显著的。对于Go/No-go和Oddball数据集,大约一半的受试者在高通滤波后的数据中达到了80%的显著通道。然而,没有一个受试者达到了100%,即使这个值超过了90%(所有数据集中只有四个这样的受试者),EEGLAB流程有时仍然可以提高性能。如果给定条件和给定受试者的不良数据试验的百分比超过了总试验次数的75%,我们就忽略了这个受试者。在比较方法时,如果剩余的受试者数量少于4,不计算显著性。
我们将所有显著效应四舍五入到最接近的百分比。P值是未校正的,但我们不报告任何高于0.01的显著p值——0.01和0.05之间的p值被报告为趋势——当一个图中的比较次数少于5时,考虑到Bonferroni类型的多重比较校正。
计算平台
我们在Expanse上执行了所有的计算,这是位于San Diego Supercomputer Center的高性能计算资源,是Neuroscience Gateway的一部分。在Expanse上,我们使用了MATLAB 2020b和Python 3.8。除了故障排除时,所有的计算都是在非交互模式下使用SLURM工作负载管理器运行的。我们总共使用了大约10,000个核心小时来进行我们的比较。
数据
数据可用性
所有数据都在OpenNeuro.org和NEMAR.org网站平台上公开可用,具体的公共数字对象标识符为:https://doi.org/10.18112/openneuro.ds002680.v1.2.0, https://doi.org/10.18112/openneuro.ds002718.v1.0.5, https://doi.org/10.18112/openneuro.ds003061.v1.1.1。
Go/No-go 数据集
这个实验是一个视觉分类任务,其中14名参与者在看到一张短暂闪烁的动物照片时做出反应。50%的照片包含从不同角度拍摄的动物图像,另外50%的照片不包含动物或人类的图像。图像以随机间隔的动物图片呈现20毫秒,间隔为1.8-2.2秒。我们比较了正确的目标——对动物的go反应——和正确的干扰物——对非动物图像的no-go反应。为了减少需要处理的数据量,我们只使用了两个录制会话中的一个(会话1),平均包括228个目标(标准差:17个目标)和235个干扰物(标准差:10个干扰物)。数据以1000 Hz的速度获取,并使用MATLAB的重采样函数重新采样到250 Hz进行后续分析。
Face 数据集
这个多模态数据集包含了由Elekta MEG机器获取的EEG数据,并已经在多篇出版物中使用,包括开源软件包的比较。18名参与者对连续呈现的面部照片的对称性进行了判断。一个固定的十字形呈现随机持续时间在400和600毫秒之间,之后刺激(面部或打乱的面部)被叠加随机持续时间在800和1000毫秒之间。在1700毫秒的刺激间隔期间,显示了一个中心的白色圆圈。这个任务是附属的,用于维持参与者的参与度,因为实验的目标是比较不同类型的面孔:熟悉的、不熟悉的和打乱的。这里我们比较了熟悉和打乱的面孔。我们使用了一个专为EEG研究量身定做的数据集版本,其中每个受试者的六个运行被连接在一起,数据被重新采样为250 Hz。每个受试者看到了150个熟悉的和150个打乱的面孔。这个数据集包含四个非EEG通道,我们在所有分析中都忽略了它们。
Oddball 数据集
在这个实验中,13名参与者通过按下按钮来响应不频繁的奇异声音(1000 Hz的70毫秒;试验的15%)和频繁的标准声音(500 Hz的70毫秒;试验的70%)以及不频繁的白噪声(70毫秒持续时间;试验的15%)。刺激间隔从0.9到1.1秒随机选择。对于每个受试者的三个数据块(或运行),这里只分析了一个运行以加速计算。对于其中一个受试者,第一次运行被截断,所以我们处理了第二次运行。我们只考虑了对奇异目标和标准非目标的正确反应(对奇异刺激的行为反应和对标准刺激的反应缺失)。平均有92个正确的目标(标准差:25)和518个正确的非目标(标准差:8)。数据在使用BIOSEMI重采样程序处理之前被数字化重新采样为256 Hz。这个数据集包含15个辅助通道,除了参考(这五个辅助通道用于在图3中重新参考数据:左和右乳突、左和右耳垂和鼻子)外,在所有分析中都被忽略。
滤波
作为图2中的参考滤波器,我们使用了ERPLAB v9.030的pop_basicfilter方法,该方法允许设计一个稳定的滤波器,最低频率可达0.01 Hz(使用默认的ERPLAB roll-off参数值的4阶Butterworth滤波器)。对于补充图2,在EEGLAB中,我们使用了Firfilt插件(v2.6)的默认Hamming窗口同步FIR滤波器,高频截止为0.5 Hz和默认参数(滤波器的阶数是根据信号采样频率自动计算的)。这个滤波器也用于“去除电源噪声”、“参考”、“人工干扰排除方法”和“基线”部分的所有分析。对于MNE,我们使用了默认的滤波器(原始对象的filter方法的线性FIR滤波器,高通滤波器为0.5,没有低通滤波器——所有其他参数设置为默认)。对于Brainstorm,我们使用了process_bandpass函数,带有一个FIR高通滤波器为0.5,没有低通,以及所有默认参数(2019年FIR滤波器版本,这是默认设置)。对于FieldTrip,我们使用了高通滤波的默认设置(4阶Butterworth滤波器)。
去除电源噪声
对于陷波线性滤波器,我们使用了EEGLAB 2022.1的pop_eegfiltnew函数,通带边缘为48和52,以及默认参数(250 Hz数据的FIR滤波器阶数为415,2 Hz过渡带宽,零相位,非因果,截止频率在—6dB的49到51 Hz)。
重新参考
听觉Oddball数据集是用额外的通道录制的,以测试重新参考方法:乳突、耳垂和鼻子。这些额外的通道是在BIOSEMI放大器的辅助通道(EXG 1-5)中记录的,没有包括在任何其他分析中。我们使用了EEGLAB(v2022.1)的pop_reref方法来将数据参考到这些通道。我们还使用了PREP流程的performReference函数(带有默认参数),该函数使用RANSAC算法计算一个稳健的参考。
自动化干扰排除
EEGLAB clean_rawdata通道排除
我们使用了EEGLAB的clean_rawdata插件(v2.7)来检测坏通道,相关性阈值范围从0.15到0.975(见表1)。clean_rawdata的所有其他数据排除方法都被禁用了。低于相关性阈值的通道使用球面样条(EEGLAB 2022.1的pop_interp函数)进行插值。
EEGLAB clean_rawdata ASR排除
我们使用了EEGLAB的clean_rawdata插件(v2.7)来检测坏的数据段,阈值范围从5到200(见表1)。该插件使用Artifact Subspace Reconstruction(ASR)方法来检测和纠正坏的数据部分。我们只使用了ASR的干扰检测方法来移除坏的数据段(这是EEGLAB离线处理的默认设置),并没有对它们进行纠正。clean_rawdata的所有其他数据排除方法都被禁用了。
EEGLAB ICLabel眼动和肌肉排除
我们使用了Infomax(Picard插件v1.0)和EEGLAB 2022.1的默认参数进行了独立成分分析(ICA)。EEGLAB自动将Picard的最大迭代次数设置为500,而不是100。ICLabel(v1.4)是一种能够基于它们的地形图和活动来检测干扰性ICA成分的机器学习算法。每个成分都被分配到7个类别中的1个的概率,其中包括肌肉和眼动干扰类别。我们应用了ICLabel的默认方法,使用概率阈值范围从0.5到0.9来检测眼和肌肉干扰。当测试其他ICA算法(runica、AMICA、FastICA、sobi;补充图7)时,我们使用了它们在EEGLAB或EEGLAB插件中的实现,并使用了默认参数值。
FieldTrip ft_artifact_zvalue干扰参数
我们使用了函数ft_artifact_zvalue(2022年8月7日的FieldTrip版本)来移除干扰。我们遵循了在线教程(https://www.fieldtriptoolbox.org/tutorial/automatic_artifact_rejection/;2022年8月8日的版本)并使用了代码片段来移除EOG(电眼图)和肌肉干扰。为了检测眼动,我们使用了前额通道AF7、AF3、Fp1、Fp2和Fpz(Oddball数据集),AF3、AF4、AF7、AF8和Fpz(Face数据集),通道Fp1和Fp2(Go/No-go数据集)。我们保留了教程中的所有其他参数(trlpadding = 0; artpadding = 0.1; fltpadding = 0; 4阶Butterworth滤波器和使用Hilbert方法)。我们使用了2到15 Hz的频率范围,如FieldTrip教程中推荐的,并改变了z分数阈值从1到6。为了检测肌肉干扰,我们将通道更改为T7、T8、TP7、TP8、P9和P10(Oddball和Face数据集)以及T5、T6、CB1和CB2(Go/No-go数据集)。我们使用了默认的9阶Butterworth滤波器和boxcar参数为0.2,但将频率范围从100到110 Hz(这个滤波器的上边缘比FieldTrip教程中的要低,以适应我们较低的数据采样率)并改变了z分数阈值从1到6。注意,计算在一部分通道上的z分数可能对MEG(磁脑电图)比对EEG(电脑电图)更有相关性:对于EEG,带有噪声的通道数量可能取决于参考。高频噪声在MEG中也可能比在EEG中更强,在EEG中可能被模糊掉。
Brainstorm坏段检测
我们使用了Brainstorm(2022年8月5日的版本)的功能来检测数据的坏部分(菜单项“检测其他干扰”,对应于命令行函数process_evt_detect_badsegment)。我们改变了低频和高频干扰检测的灵敏度从1到5(唯一允许的值)。我们还使用了Brainstorm函数来检测坏的数据试验(process_detectbad)并改变了阈值从200到5000(表1)。
MNE Autoreject 参数
我们使用了Python 3.8上的MNE 1.1.0,以及默认的科学和绘图库,还有MNE库中的eeglabio 0.0.2和Autoreject 0.3.1。在MNE自身中,我们没有找到任何函数来自动拒绝坏的数据段或坏的通道。Autoreject插件允许纠正和拒绝坏的数据。尽管它不是MNE的官方部分,但是它是由MNE的核心开发者制作的。在联系其他MNE核心开发者后,没有提出其他替代方法。与其他具有可调参数的干扰排除方法不同,Autoreject自动扫描参数空间以拒绝最佳数量的通道和坏的数据区域。该算法已在四个EEG数据集上进行了验证,并且至少有一个其他团队使用了默认参数进行了应用。我们遵循了在线文档(https://autoreject.github.io/stable/auto_examples/plot_autoreject_workflow.html;2022年8月8日)并使用了教程中的1到4个通道进行插值。Autoreject教程中的另一个参数是拟合的脑电时段数(epoch数)。建议的方法使用前20个脑电时段来加速计算。我们尝试使用了前20个脑电时段和脑电时段(表1)。
流程
所有流程的通用处理
在每个软件包中,都使用了默认的方法应用了0.5 Hz的高通滤波(EEGLAB、MNE和Brainstorm使用有限脉冲响应滤波器,FieldTrip使用Butterworth滤波器;参见过滤方法部分)。
HP 0.5 Hz 流程
我们使用了EEGLAB默认的FIR 0.5-Hz高通滤波器,没有其他预处理。参见过滤方法部分。
EEGLAB 流程
我们使用了默认的FIR 0.5-Hz高通滤波器,然后进行电极线噪声检测和插值(4个标准差阈值;“干扰排除方法”部分),clean_rawdata通道相关性去除(0.9的相关性阈值),clean_rawdata ASR拒绝(阈值为20),然后进行ICA,接着是ICLabel,用于肌肉和眼睛的概率阈值为0.9。
FieldTrip 流程
我们使用了默认的Butterworth 0.5 Hz高通滤波器。FieldTrip的一步ft_preprocessing函数会过滤数据时段(epoch)而不是先过滤原始数据然后提取数据时段,这导致了性能不佳(补充图2),因此我们使用了多步骤方法,先过滤数据然后使用ft_redefinetrial函数提取脑电时段。我们用4 dB的阈值拒绝了具有高和低频干扰的数据时段,这是FieldTrip教程中的默认设置(参见“FieldTrip ft_artifact_zvalue干扰参数”和“干扰排除方法”部分)。
Brainstorm 流程
我们使用了默认的Brainstorm 0.5-Hz高通滤波器,并以灵敏度级别5拒绝了低和高频干扰(“干扰排除方法”部分)。我们以200的阈值拒绝了坏的试验(“干扰排除方法”部分)。
MNE 流程
我们使用了默认的MNE 0.5-Hz高通滤波器,并使用Autoreject拒绝和修复干扰(用于拟合过程的试验次数为20;“干扰排除方法”部分)。
HAPPE 流程
HAPPE(Highly Automated Pipeline for Preprocessing EEG,高度自动化的EEG预处理流程)是基于EEGLAB的处理流程,它使用MARA EEGLAB插件通过ICA(独立成分分析)拒绝干扰,并使用FASTER EEGLAB插件来插值坏的数据段。虽然它是一个集成的流程,但它允许用户设置一个峰对峰原始数据阈值,单位为微伏。我们尝试了从50到150微伏的这个阈值范围,每次增加10微伏,但没有发现阈值之间或与没有阈值有显著差异,所以我们将阈值设置为100。我们使用了默认的重新参考设置,该设置计算一个平均参考(不重新参考不是一个选项)。我们修改了核心代码,将高通滤波器的截止频率降低到0.5 Hz(而不是默认的1 Hz),以使其与其他流程的第一步预处理相匹配。我们禁用了cleanline插件来去除线噪声,因为它在某些数据集上产生了错误。我们进行了其他一些小的修改,以便能够处理Go/No-go、Face和Oddball数据集,并发布了HAPPE流程的2.0版本供其他人使用。与其他流程不同,这个流程会自动重新参考数据,这可能解释了它在图5中的性能不佳。
结果
我们使用随机重采样的试验(每个条件50次试验)来评估两个感兴趣条件之间显著的EEG通道百分比(参见“方法”部分;参见补充图1中的图示),并分析了三个公开可用实验的数据(补充表1)。第一个实验(Go/No-go)是一个视觉分类任务,参与者被指示在看到一张短暂闪烁的动物照片时做出反应。在这个任务中,我们比较了正确动物目标(50%)和正确干扰物(50%)之间的大脑诱发电位。在第二个实验(Face)中,我们比较了参与者在执行面部对称性判断任务以维持他们注意力时呈现的熟悉和打乱的面部的大脑诱发电位。在第三个实验(Oddball)中,参与者必须对间隔频繁的标准声音(70毫秒,频率为500赫兹)之间的奇异声音(70毫秒,频率为1000赫兹)做出反应(参见“方法”部分)。
我们对数据进行了0.5 Hz的高通滤波,提取了数据时期(从-1秒到2秒),没有进行基线去除,并在每个潜在时延处使用50个随机重采样时期计算了显著通道的平均数量(参见“方法”部分)。然后,我们寻找了具有最高显著性的100毫秒窗口。我们发现每个数据集中最大效应量的潜在时延有所不同(图1):Go/No-go(350-450毫秒)、Oddball(400-500毫秒)和Face(250-350毫秒)。这个范围是针对每个数据集定制的,用于评估不同信号预处理方法的有效性。
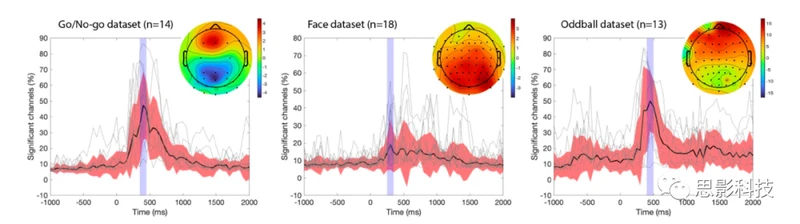
图1:三个公开可用实验中时间跨度内显著电极的百分比
该图展示了两种条件(视觉Go/No-go:动物目标与非动物干扰项;面部:熟悉面孔与打乱面孔;听觉Oddball:奇异声音与标准声音)的事件相关电位。这些电位是从0.5 Hz的高通滤波原始数据中提取的。在每个潜伏期的50毫秒增量中,计算了20,000个随机重采样的50个试验条件下显著电极的平均百分比。
-
黑色曲线表示中位数,
-
红色区域表示中位数绝对偏差,
-
灰色曲线显示了每个数据集中单个受试者的显著通道百分比。
蓝色区域表示最大效应量的100毫秒区域,这可能对应于Go/No-go和Oddball数据集的反应相关活动。每个实验的头皮地形图使用μV(微伏)刻度显示。
预处理方法
高通滤波
是否存在一个理想的频率截止点来高通滤波EEG数据?随着截止频率的降低,线性滤波器的长度增加,这使得在低于0.5 Hz的频率下对EEG进行滤波变得不切实际。因此,我们使用了4阶Butterworth滤波器来评估最佳的高通滤波截止频率(使用ERPLAB包;参见“方法”部分)。我们测试了0.01 Hz、0.1 Hz、0.25 Hz、0.5 Hz、0.75 Hz和1 Hz的滤波器。与所有其他预处理步骤相比,滤波对显著通道的百分比有最重要的影响。它分别提高了面部(Face)数据集13%、奇异(Oddball)数据集47%和Go/No-go数据集57%的性能。最佳的滤波是面部(Face)数据集的0.1 Hz、奇异(Oddball)数据集的0.5 Hz和Go/No-go数据集的0.75 Hz。高于0.1 Hz的滤波器与视觉Go/No-go和听觉Oddball数据集的无滤波相比有显著的改善(p < 0.0001),并且也与0.01 Hz滤波器相比有显著的改善(p < 0.0001)。尽管在两个数据集(Go/No-go和Oddball;两种情况下p < 0.0001)中,0.01 Hz和0.5 Hz的滤波器之间存在显著差异,但面部(Face)数据集并非如此,这可能是因为在EEG采集过程中应用了一个滤波器(参见讨论)(图2)。
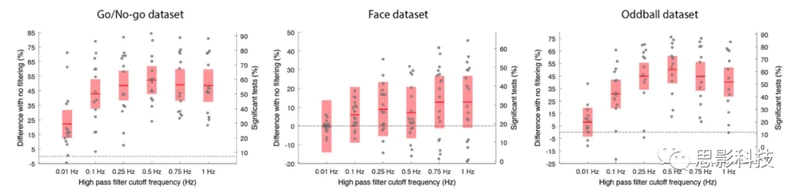
图 2. 高通滤波截止频率对与无滤波条件下三个数据集显著通道百分比的影响。
红色区域表示95%的置信区间,点表示个体受试者。每个面板右侧的纵坐标刻度表示显著测试的百分比。它是通过将左侧纵坐标刻度平移无滤波条件下显著通道的平均百分比来获得的。
不是所有的滤波器都是相同的
大多数软件包都有各种选项和参数来设计滤波器,测试它们所有的是不切实际的。我们测试了公开可用的软件包EEGLAB、MNE、Brainstorm和FieldTrip中的默认滤波器(参见“方法”部分和补充图2),并将它们与补充图2中的参考滤波器进行了比较。在Oddball数据集中,ERPLAB参考滤波器的表现优于所有其他滤波器(p < 0.0001),但在Face和Go/No-go数据集中则没有。
对于Go/No-go数据集,MNE滤波器的表现明显不如ERPLAB参考滤波器(p < 0.0001)、Brainstorm滤波器(p < 0.005)和EEGLAB滤波器(趋势在p = 0.02)。MNE滤波器在Face数据集中的表现不如EEGLAB滤波器(p < 0.002)。
对于FieldTrip,我们尝试了两种方法:一步预处理,我们意识到它过滤了原始数据的时域,以及多步预处理,它允许在提取数据时域之前过滤原始数据。对于Oddball数据集,应用于数据时域的FieldTrip滤波器与参考滤波器相比,显著电极的百分比减少了高达25%(p < 0.0001),应该避免使用。
我们使用默认的EEGLAB滤波器(参见“方法”部分)在所有分析中对所有数据集的数据进行0.5 Hz的高通滤波,在“去除线噪声”、“参考”、“拒绝伪迹方法”和“基线”部分中——包括使用MNE、Brainstorm和FieldTrip软件包的那些。
去除线噪声
有多种方法可以去除或最小化EEG数据中的线性噪声(参见“方法”部分;补充图3)。最常见的方法是使用带阻滤波器(也称为陷波滤波器)滤除线噪声频率。我们使用了FIR陷波滤波器和IIR陷波滤波器(参见“方法”部分),并观察到任何数据集的显著通道百分比都没有变化——请注意,视觉Go/No-go数据集已经进行了陷波处理(补充表1)。
我们还测试了cleanline EEGLAB插件,该插件估算并去除正弦线噪声,以及Zapline-plus EEGLAB插件,该插件结合了频谱和空间滤波以去除线噪声。这些方法与不去除线噪声相比没有显著差异,除了Face数据集,其中它们导致了小而显著的性能下降(cleanline p < 0.001)或趋势性能下降(Zapline-plus p < 0.02)。
我们还根据其在线噪声频率处的活动分布拒绝了嘈杂的通道(参见“方法”部分)。我们插值了那些比其他通道具有更多1、1.25、1.5、2、3和4个标准差的线噪声的通道(参见“方法”部分)。对于Go/No-go数据集,拒绝嘈杂的通道导致了显著的性能提升(所有测试的标准差值p < 0.002),其中1个标准差的阈值对于Face数据集(平均拒绝了17%的通道)产生了最佳结果,对于Auditory Oddball数据集则是1.25个标准差的阈值(平均拒绝了17%的通道)。
对于我们的最终流程(参见“优化流程”部分),我们选择了默认的4个标准差的阈值,这导致了Face和Oddball数据集的显著改善(两种情况下p < 0.005),并且拒绝的通道百分比适中(根据数据集,平均为1%到6%)。
参考(Referencing)
图3显示了使用Oddball数据集的不同参考进行比较,对于该数据集,可以测试比其他数据集更多的参考蒙太奇(参见Go/No-go和Face数据的补充图4)。对于这个数据集,所有重新参考都显著降低了显著通道的百分比(所有情况下p < 0.005),包括使用通道插值来去除伪迹的PREP参考(参见“方法”部分)。
对于Go/No-go数据集,所有参考类型都观察到了性能的趋势下降(p < 0.09或更低),Face数据集也注意到了非显著的下降。对于Oddball数据集,中位数、平均数、REST和PREP参考降低了性能最少,尽管它们并不比其他参考方法显著更好,除了环状参考。鼻子参考引入了最高的可变性(图3)。
环状参考的菊花链(一种特定的电极布局或参考方式)蒙太奇也明显低于Go/No-go、Face和Oddball数据集的中位数、平均数、REST和PREP参考(所有情况下的显著性或趋势p < 0.02)。
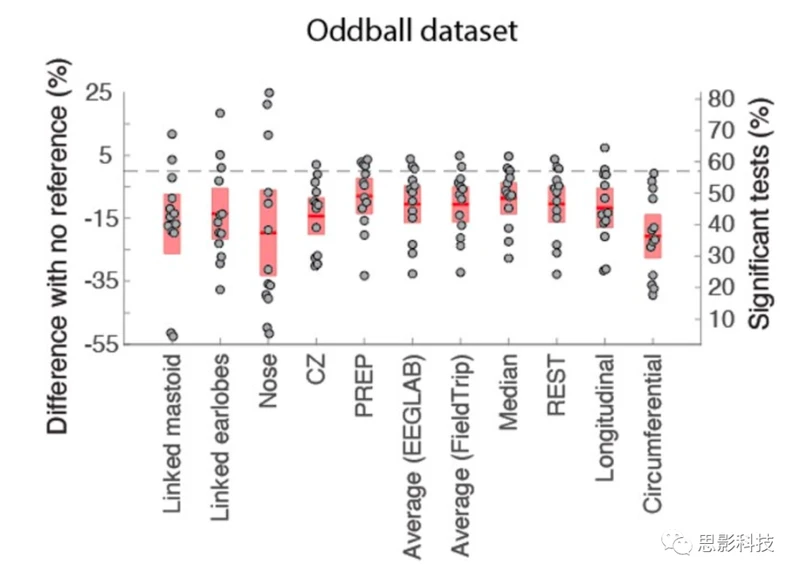
图3:参考对与内部BIOSEMI参考(CMS/DRL)相比显著通道数量的影响。
对于所有参考,原始数据首先在0.5 Hz处进行高通滤波(参见“方法”部分)。红色区域表示95%的置信区间,点表示受试者。关于纵坐标尺度的详细信息,请参见图2。
伪迹剔除方法
我们使用与“高通滤波”、“电源噪声去除”、“参考”和“伪迹剔除方法”各节相同的方法来评估自动EEG伪迹剔除的性能,这些方法不会移除数据试验,例如EEGLAB clean_rawdata通道剔除和EEGLAB ICLabel眼动和肌肉剔除。然而,对于移除试验的方法,我们必须使用所有试验而不是重新抽样50个试验来计算显著性,因为我们的目标是评估这些方法在移除不良试验后能否增加显著通道的百分比(参见“方法”节)。
EEGLAB clean_rawdata通道剔除
核心插件clean_rawdata用于检测与0.15到0.975的相关阈值范围内的不良通道(参见“方法”节和补充图5A)。更高的相关阈值在剔除通道方面更为激进。我们发现,对于面部数据集,0.95的相关阈值导致了与不进行通道剔除相比显著的2%的改进,剔除了7%的通道。对于奇异数据集,最佳相关性是0.97,剔除了29%的通道,性能提高了15%。为了避免剔除太多的通道,对于最终的EEGLAB流程(“优化流程”节),我们选择使用90%,这导致了面部和奇异数据集的显著性能提升(p=0.003和p<0.0001,分别),并根据数据集剔除了3%到12%的通道。
EEGLAB clean_rawdata ASR剔除
核心插件clean_rawdata用于使用伪迹子空间重建(ASR)方法的第一步检测不良数据段(参见“方法”节和补充图5B)。用于ASR的阈值范围从5到200(表1)。没有ASR值导致性能显著提高。低阈值5倾向于为奇异数据集的所有受试者拒绝100%的试验。由于ASR剔除并没有显著降低显著通道的百分比,对于最终的EEGLAB流程(“优化流程”节),我们选择了默认值,即20。
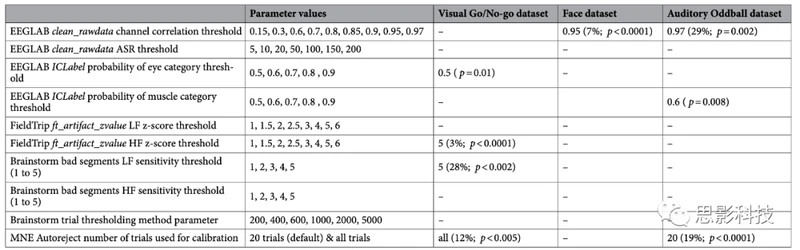
表1.旨在全面评估最流行的开源EEG数据分析软件包(EEGLAB、FieldTrip、Brainstorm和MNE)中不同的自动伪迹剔除方法。
所有数据剔除方法首先对数据进行了0.5 Hz的高通滤波(参见“方法”节)。表中的“显著通道的百分比”是与仅进行0.5 Hz高通滤波的原始数据进行比较的。对于每种方法,表中都会指出测试过的参数范围。然后,对于每个数据集,第一个值表示最优参数,第二个值(括号内)是被拒绝的试验的百分比(或对于EEGLAB clean_rawdata通道相关方法,是插值通道的百分比),后面跟着p值(参见“方法”节)。p值用于评估该方法是否显著改善了数据质量,或者是否显著优于仅进行高通滤波的基准方法。
EEGLAB ICLabel眼动和肌电剔除
首先应用了独立成分分析(ICA)到EEG数据(使用Picard插件;参见“方法”部分和补充图6)。然后应用了ICLabel来检测与眼动或肌电成分类别有关的异常值,阈值范围从概率0.5到0.9。对于眼动异常值,我们发现在Go/No-go数据集中使用ICA有一定的趋势优势(所有从50%到90%的阈值,p < 0.05,最小的p值为0.01在50%)。对于肌电异常值,在Oddball数据集中,我们发现使用ICA有显著优势(阈值0.6,p = 0.008)。在最终的EEGLAB流程(“优化流程”部分)中,我们使用了默认值,即0.9。我们还在其他常用于EEG数据的ICA算法(runica、AMICA、FastICA和SOBI)上测试了ICLabel,但没有一个显著提高了性能(参见补充图7)。
FieldTrip ft_artifact_zvalue 使用FieldTrip的ft_artifact_zvalue函数自动检测异常值(参见“方法”部分)。我们改变了z分数阈值,从1到6(表1和补充图8)。对于低频,我们没有观察到显著的性能提升。对于Oddball数据集,低于4的阈值显著降低了性能(p < 0.0005)。对于高频,阈值5或6提高了Go/No-go数据集的性能(p < 0.0001),但降低了Oddball数据集的性能(p < 0.001)。在最终的FieldTrip流程(“优化流程”部分)中,我们将低频和高频的阈值都设置为4,这是FieldTrip教程中推荐的(参见“方法”部分)。
Brainstorm不良片段检测 在Brainstorm中,我们使用了一个函数来检测不良数据部分(参见“方法”部分和补充图9)。该函数允许找到低频或高频异常值,灵敏度水平从1到5不等。对于低频,灵敏度5显著提高了Go/No-go数据集的性能(p < 0.002)。灵敏度值1和2也导致了显著的性能提升(p < 0.003),但拒绝了一个或多个受试者。对于其他数据集,没有显著差异,除了Oddball数据集中灵敏度值1,该值拒绝了11/14的受试者。考虑到这种方法的激进性,我们在最终的Brainstorm流程中使用了最低的灵敏度5。对于高频异常值,在1和2的水平上,任何数据集的任何受试者都没有剩余的试验。水平5,即最不激进的灵敏度值,为Oddball数据集提供了趋势改善(p < 0.005),拒绝了19%的试验。我们在最终的Brainstorm流程(“优化流程”部分)中使用了这个阈值。
Brainstorm不良试验检测
在Brainstorm中,我们还使用了一个函数来检测不良数据试验(process_detectbad),阈值从200到5000不等(参见“方法”部分和补充图9)。没有一个值导致性能显著增加或减少。在最终的Brainstorm流程(“优化流程”部分)中,我们使用了200的阈值。
MNE Autoreject
我们使用了MNE和Autoreject插件库(参见“方法”部分和补充图10)。Autoreject扫描参数空间以寻找最优值,主要的自由参数是用于拟合数据的时期数。我们使用了20个时期和所有时期(大约从300到600个时期,取决于数据集)(补充图10),并没有观察到两者之间有显著差异。在最优的MNE流程(“优化流程”部分)中,我们使用了前20个时期来加速计算,正如Autoreject教程中建议的(参见“方法”部分)。
基线
我们测试了从100到1000毫秒的预刺激基线时段是否影响显著通道的百分比(图4)。应用预刺激基线并没有显著提高任何一个数据集的性能。事实上,对于所有基线,性能都显著下降或呈趋势下降—p < 0.025,在所有情况下,除了在Oddball数据集中从500到1000毫秒的基线。性能最多下降的是较短的基线,对于所有数据集中的400毫秒基线,性能显著下降了3%到6%(图4),以及在Go/No-go和Oddball数据集中,400毫秒和1000毫秒基线之间有显著的性能下降(p = 0.001,在两种情况下)。
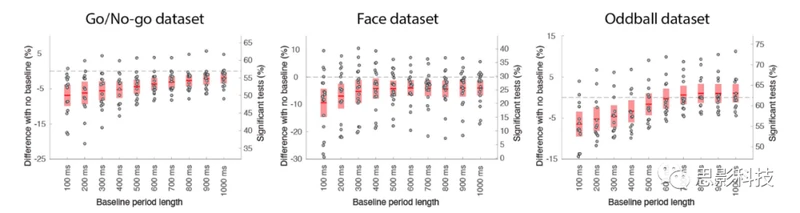
图4:基线时段对与无基线相比显著通道数量的影响。
红色区域表示95%的置信区间,点表示个体受试者。有关纵坐标刻度的详细信息,请参见图2。
这些结果与事件相关电位(ERP)研究中的标准做法相矛盾,尽管如果数据没有经过0.5 Hz的高通滤波,结果可能会有所不同。为了解决这个问题,我们比较了两种方法。我们比较了Luck和合作者使用0.01 Hz的滤波器和200毫秒的预基线间隔(基线方法),与使用0.5 Hz的滤波器和无基线(补充图11)的方法。对于所有三个数据集,使用基线方法导致了显著且大幅度的性能下降:Go/No-go数据集下降了30%(p < 0.0001),Face数据集下降了8%(趋势在p = 0.02),Oddball数据集下降了42%(p < 0.0001)(补充图11)。如补充表1所示,Face数据集在记录时经过了0.1 Hz的高通滤波,我们观察到的8%的性能下降可能会更高,如果没有这样做的话。
优化流程
对于每个开源软件包,我们基于“异常值剔除方法”部分中呈现的结果构建了一个最优流程。该部分指出了我们如何为每种异常值剔除方法选择参数。在预处理流程结束时,提取了时期,并计算了性能(参见“方法”部分)。与“高通滤波”、“去除线噪声”、“参考”、“异常值剔除方法”等部分不同,其中EEGLAB始终用于过滤原始数据和提取数据时期,所有流程都是在每个软件包中独立实现的,这意味着没有使用其他工具箱的代码。目标是为每个软件包的用户提供一个最优的、集成的、自包含的流程—流程在GitHub上公开可用(https://github.com/sccn/eeg_pipelines)。这些流程被优化以最大化显著通道的百分比,因此不应用参考(“参考”部分)和基线(“基线”部分)(参见“方法”部分)。
尽管使用了最保守的可用设置来剔除异常值,Brainstorm流程对某些受试者拒绝了所有试验(图5;Go/No-go:n = 4;Face:n = 14;Oddball n = 1)。这可能是因为Brainstorm是为MEG处理量身定做的,其中异常值的幅度可能有所不同。FieldTrip流程未能处理某些数据集(Go/No-go:n = 3;Face:n = 4),其中锁时事件潜伏期没有落在数据样本上。FieldTrip和Brainstorm工具的开发者已经被通知了这些问题,我们期望他们会解决这些问题。
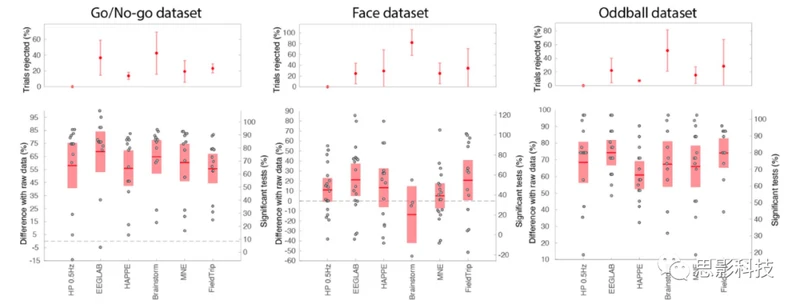
图5:与未处理的原始数据相比,三个数据集的不同自动化流程显著通道的百分比。
上面的面板显示了被拒绝试验的百分比和标准偏差。下面的面板显示了与未处理的原始数据相比显著通道的百分比。红色区域表示95%的置信区间,点表示个体受试者。有关纵坐标刻度的详细信息,请参见图2。
对于Go/No-go和Oddball数据集,所有流程都比没有预处理的情况下导致了更高百分比的显著电极(p < 0.0001)。总体而言,EEGLAB流程表现最好。它在Face(p < 0.004)和Oddball数据集(p = 0.0008)上表现优于高通0.5 Hz流程。HAPPE、Brainstorm、Fieldtrip和MNE流程在任何数据集上都没有比高通0.5 Hz流程表现得更好。EEGLAB流程在Face数据集的所有其他流程的两两比较中表现显著更好(p < 0.006,除了FieldTrip),并且在Oddball数据集上表现优于所有其他流程(p < 0.005,除了Brainstorm)。Fieldtrip在Go/No-go数据集上表现显著优于HAPPE(p = 0.01)。我们没有注意到其他任何两两显著的比较。
我们没有为任何流程实施微调。重要的是要注意,我们使用了大多数流程的推荐值(参见“方法”部分)。例外情况如下:(1)对于EEGLAB,通道相关性设置为0.9,而不是默认的0.85(“异常值剔除方法”部分)。(2)对于HAPPE,我们使用了150微伏的阈值。(3)对于Brainstorm,低频和高频异常值剔除的灵敏度降低到5,而不是3(默认值),并且试验拒绝设置为更保守的-200到200微伏范围,而不是-100到100微伏范围(默认值);对于FieldTrip和MNE,我们使用所有默认参数值(参见“方法”部分)。
讨论
在之前的报告中,我们使用了由clean_rawdata拒绝的数据百分比和ICLabel隔离的大脑成分数量作为数据质量的指标。然而,由于它们是现有处理流程的一部分,因此这些方法不能用作基准来评估EEG数据的真实质量和基准流程。
在这份报告中,我们使用了一个受到之前工作启发的数据指标,其中研究人员计算了在oddball范式中达到显著性所需的显著试验次数。然而,这是在单个电极上进行的,我们观察到结果会根据所选的参考而有很大的不同。由于容积传导,条件之间的强烈差异效应可能在大多数电极上可见并且显著,因此我们选择在所有电极上计算显著性。图1证实了这一假设:对于几名受试者,他们超过80%的电极在感兴趣的窗口中显示出显著性。我们的程序对参考的选择也是不可知的,不依赖于试验次数或通道数量(参见“方法”部分)。除了查看条件之间的差异外,也可以测试与基线相比的绝对ERP幅度差异。然而,最大化ERP幅度和多个通道上的显著性可能在认知上并不相关。通过比较条件,我们的质量指标保证对研究人员来说是相关的。
滤波增加了Go/No-go和Oddball数据集的显著通道百分比约50%。对于Face数据集,过滤导致了非显著的改善,可能是因为在数据收集时高通滤波器为0.1 Hz(补充表1)。在比较软件实现时,FieldTrip过滤器在Oddball数据集中的性能最初较低(补充图2)。我们意识到,当提供过滤设置和时期信息时,FieldTrip预处理函数在过滤数据之前提取数据时期。在与FieldTrip开发人员咨询后,对于使用FieldTrip进行的所有分析,我们使用了一个替代的多步骤实现,允许我们在原始数据被过滤后提取时期。
我们发现唯一影响显著通道百分比的电源噪声去除是对噪声通道的插值。陷波滤波没有显著效果。在cleanline和Zapline-plus中的频谱和空间插值甚至对Face数据集的性能产生了负面影响。Go/No-go数据可能具有有效去除电源噪声的硬件陷波滤波器,因为去除噪声通道不再影响性能(补充表1;补充图3)。当显著时,电源噪声校正的性能改善是微小的(在几个百分点的数量级上),与高通滤波的效果相反,后者导致两个数据集的性能提高了约50%。除了数据可视化和频域中多重比较的群集校正外,在预处理EEG数据时,离线去除电源噪声可能不是一个关键步骤。
我们发现,在所有三个数据集中,重新参考并没有增加显著通道的百分比。最好的情况是,中位数、平均数、REST和PREP参考导致某些数据集性能的非显著下降。再次,这与EEG社区的信念相反,在那里有对最佳EEG参考的不懈寻求。我们的结果令人惊讶,因为这三个数据集使用了不同的参考(Go/No-go数据的Cz,Face数据的鼻子,和Oddball数据的BIOSEMI内部参考)。Face数据集的鼻子参考已知会引入特别是在高频率下的伪迹,现在在EEG研究中很少使用。BIOSEMI的Oddball数据集的原始信号被认为不适合离线数据分析,BIOSEMI公司建议选择一个离线参考以增加40 dB额外的CMRR(共模抑制比)(https://www.biosemi.com/faq/cms&drl.htm)。Go/No-go数据集的Neuroscan Cz参考也是EGI公司的常用参考。然而,将Oddball数据集的数据重新参考到Cz并没有提高性能(图3)。这些结果可能表明模拟参考和数字重新参考在噪声抑制方面存在根本性差异,并需要更多的研究来了解两者之间的差异。数据重新参考和先前数据过滤(在我们的案例中是0.5 Hz高通)之间的相互作用也应该被调查。
我们观察到,如果数据在0.5 Hz或以上进行高通滤波,那么在事件相关分析中应省略减去平均基线活动。减去基线活动对数据质量没有效果或有负面效果,特别是当基线短于500 ms时。Lutz及其合作者认为过滤会扭曲ERPs,应该使用基线去除代替。虽然确实ERPs会被扭曲,但我们发现,当使用Lutz提出的短基线时,数据质量急剧下降,导致Oddball数据集中某些受试者几乎所有电极都不显著(补充图11)。
关于伪迹剔除,我们的结果并不是人们对基础(简单阈值)和更高级数据清洗方法所期望的。几乎没有一个方法导致显著的性能提升,即使观察到改善,效果也是微弱的,并且在数据集之间没有一致性。当重新抽样50个数据试验而不是使用所有试验来计算显著性时,我们观察到剔除试验导致大多数方法的显著改善,这意味着这些方法确实能够剔除不良试验。例如,使用50个数据试验的自助法与ASR,阈值为10,对Face和Oddball数据集的性能有所提高(两种情况下p < 0.0001),尽管大约60%到80%的试验被剔除。使用50个数据试验的自助法,Brainstorm对高频伪迹的敏感性提供了显著的改善(所有数据集中p < 0.004,剔除了19%到45%的试验),MNE Autoreject也提供了显著的改善(Go/No-go:p = 0.005和剔除了12%的试验;Oddball:p < 0.001和剔除了19%的试验)。然而,如表1所示,当对所有剩余试验进行自助法时,情况并非如此:剔除不良试验通常未能弥补试验数量减少和与未剔除任何试验的对照条件相比的统计功效下降。
尽管ICA增加了显著通道的百分比,但它并没有系统地这样做(表1)。然而,在使用伪迹剔除方法时,除了显著通道的数量外,还有更多需要考虑的因素。例如,ICA和ICLabel移除了与眼睛和肌肉运动相关的伪迹,这些伪迹影响头皮地形图,可能为可视化(补充图12)和随后的源定位提供优势。
EEGLAB管道表现最好,并且与所有数据集的数据过滤相比有显著改善,显著通道数量增加了5%(Go/No-go)到17%(Oddball)和18%。这可能是由于用于剔除和插值不良通道的方法,因为ICA和ASR方法的效果有限(“伪迹剔除方法”部分)。所有其他管道与过滤数据相比没有改善。有人可能会争辩说,我们有一个双重挖掘问题,因为我们优化了管道,然后重新计算了显著性。为了解决这个问题,我们将EEGLAB管道恢复到所有默认参数(v2022.0),这只改变了通道相关性的阈值,从0.9变为0.85。与基础管道的差异对于Go/No-go数据集不再显著。对于Face(p = 0.004)和Oddball数据集(p = 0.0008),仍然显著。
我们无法在我们的比较中包括所有现有的管道。PREP管道是用于构建EEG管道的EEGLAB插件。PREP管道包含基于阈值的自动EEGLAB伪迹剔除,我们选择不进行测试,因为我们在其他软件(Brainstorm,FieldTrip)中测试了类似的方法。PREP管道还包含一种执行稳健参考的方法,我们在比较重新参考方法时包括了这一点(图3)。APICE管道是另一个我们没有测试的EEGLAB管道,因为它是专为婴儿EEG量身定做的。EEGLAB还包含29个带有伪迹剔除方法的插件,包括FASTER和MARA,这是两种流行的自动EEG处理方法。尽管我们没有直接评估这些算法,但它们被包括在HAPPE管道中。
我们展示了使用非主观的、与任务相关的度量来评估数据质量的有效性,该度量可用于指导EEG预处理。使用这一度量,我们还显示了对于在实验室条件下获得的相对干净的EEG,预处理技术对数据质量影响甚微。这可能不适用于在其他条件下获得的更嘈杂的数据。我们希望未来的工作能继续发展这一提出的方法,以揭示EEG、MEG和iEEG的自动信号处理的新时代。