20230811在WIN11下使用python3批量将中英文的SRT格式的字幕合并
2023/8/11 8:35
缘起:将google翻译成为的简体中文字幕和剪影/RP2023直接通过语音OCR获取的SRT格式的英文字幕合并成为中英文的字幕!
由于已经解决了UTF8的编码问题,ANSI/GBK编码的合并问题本文就不提供了!
有兴趣的同学可以参照修改!
1、回顾:J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3批量将TXT文件转换为SRT文件
utf8txt2srt3all.py
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
#cn+en_file = file.replace('.txt', '.cn+en.srt')
cn3en_file = file.replace('.txt', '.cn+en.srt')
#en4cn_file = file.replace('.txt', '.en+cn.srt')
orig_srt_en_file = file.replace('.txt', '.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
#f2=open(new_file,"wb")
f2 = open(new_file, "w", encoding="UTF-8")
f3 = open(cn3en_file, "w", encoding="UTF-8")
temp = 1
xuhao = 1;
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
for line in lines:
if temp == 1:
f2.write(str(xuhao))
f2.write(str('\n'))
f3.write(str(xuhao))
f3.write(str('\n'))
temp=0
else:
if len(line) == 1:
temp=1
xuhao = xuhao+1
f2.write(line)
f3.write(line)
f2.close()
f3.close()
2、前导:
偶然的发现:对于SRT字幕,貌似对时间轴的顺序,播放器会重新整理/排序!
也就是你可以将最开始的字幕放到最后面也没有问题!
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
#cn+en_file = file.replace('.txt', '.cn+en.srt')
cn3en_file = file.replace('.txt', '.cn+en.srt')
#en4cn_file = file.replace('.txt', '.en+cn.srt')
orig_srt_en_file = file.replace('.txt', '.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
#f2=open(new_file,"wb")
f2 = open(new_file, "w", encoding="UTF-8")
f3 = open(cn3en_file, "w", encoding="UTF-8")
temp = 1
xuhao = 1;
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
print(lines)
with open(orig_srt_en_file, "r", encoding="UTF-8") as f3_en:
lines_en = f3_en.readlines()
print(lines_en)
for line in lines:
if temp == 1:
f2.write(str(xuhao))
f2.write(str('\n'))
f3.write(str(xuhao))
f3.write(str('\n'))
temp=0
else:
if len(line) == 1:
temp=1
xuhao = xuhao+1
f2.write(line)
f3.write(line)
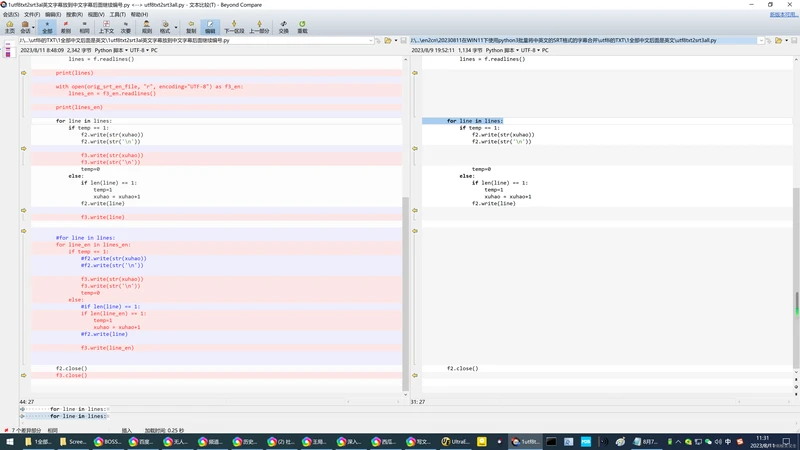
#for line in lines:
for line_en in lines_en:
if temp == 1:
#f2.write(str(xuhao))
#f2.write(str('\n'))
f3.write(str(xuhao))
f3.write(str('\n'))
temp=0
else:
#if len(line) == 1:
if len(line_en) == 1:
temp=1
xuhao = xuhao+1
#f2.write(line)
f3.write(line_en)
f2.close()
f3.close()
结果:
1
00:02:12,766 --> 00:02:16,099
泰勒·鲍勃和玛丽安·泰勒和我在一起
2
00:02:16,100 --> 00:02:16,900
一秒
1138
01:23:55,966 --> 01:23:58,133
我爱你
1139
01:24:13,700 --> 01:24:15,133
为我
1140
00:02:12,766 --> 00:02:16,099
Taylor Bob and Marianne Taylor here with me
1141
00:02:16,100 --> 00:02:16,900
one second
2277
01:23:55,966 --> 01:23:58,133
i love you
2278
01:24:13,700 --> 01:24:15,133
for me
3、现在需要合并中英文字幕,
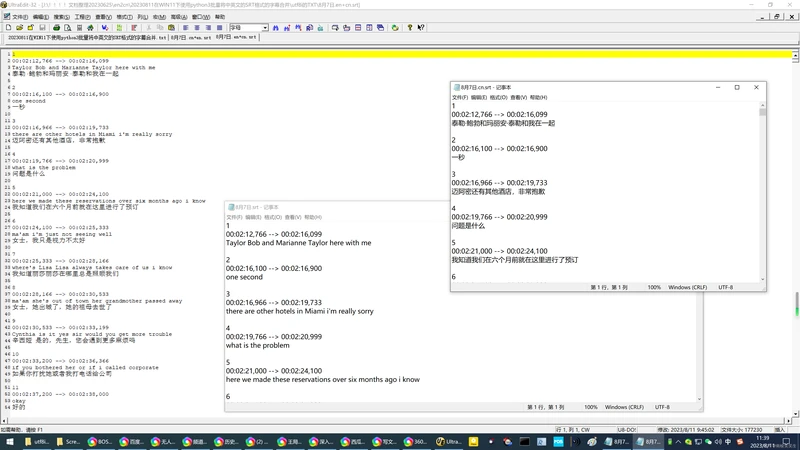
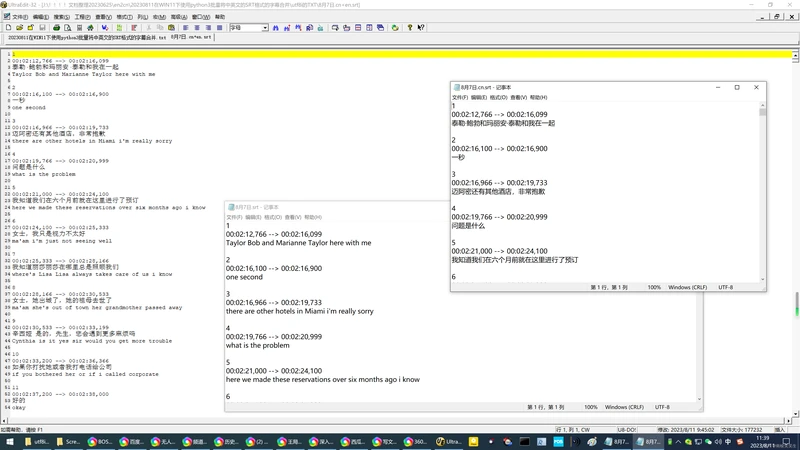
英文字幕:8月7日.srt
1
00:02:12,766 --> 00:02:16,099
Taylor Bob and Marianne Taylor here with me
2
00:02:16,100 --> 00:02:16,900
one second
中文字幕:8月7日.cn.srt
1
00:02:12,766 --> 00:02:16,099
泰勒·鲍勃和玛丽安·泰勒和我在一起
2
00:02:16,100 --> 00:02:16,900
一秒
合并之后的结果:
1
00:02:12,766 --> 00:02:16,099
泰勒·鲍勃和玛丽安·泰勒和我在一起
Taylor Bob and Marianne Taylor here with me
2
00:02:16,100 --> 00:02:16,900
一秒
one second
问题点:
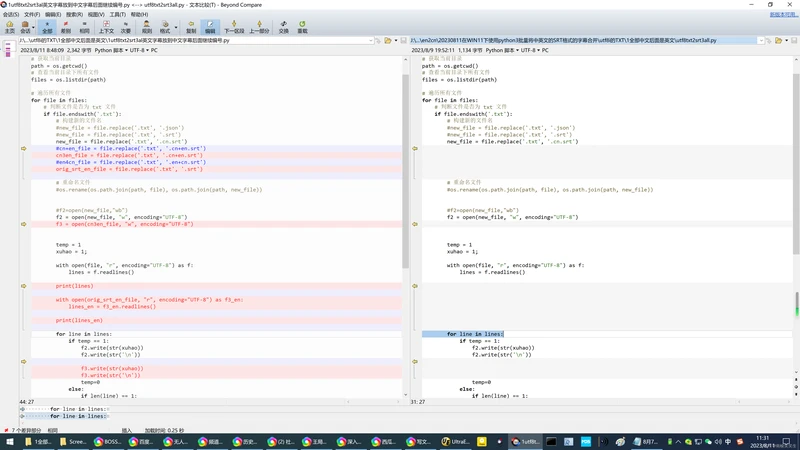
1、google翻译的简体中文的SRT格式的字幕是有问题的,需要也被翻译了!需要修正:utf8txt2srt3all.py
2、加入英文字幕,但是需要干掉三行:空格行、序号行、时间轴行!
cn5en6utf8txt2srt3all.py
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
#cn+en_file = file.replace('.txt', '.cn+en.srt')
cn3en_file = file.replace('.txt', '.cn+en.srt')
#en4cn_file = file.replace('.txt', '.en+cn.srt')
orig_srt_en_file = file.replace('.txt', '.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
#f2=open(new_file,"wb")
f2 = open(new_file, "w", encoding="UTF-8")
f3 = open(cn3en_file, "w", encoding="UTF-8")
temp = 1
xuhao = 1;
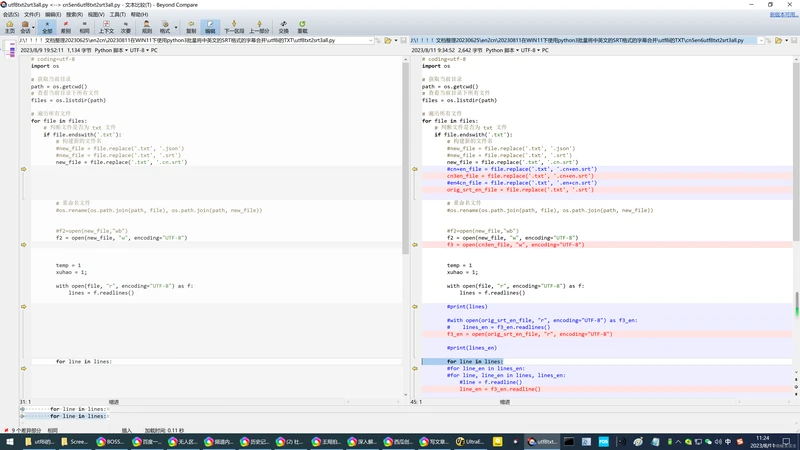
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
#print(lines)
#with open(orig_srt_en_file, "r", encoding="UTF-8") as f3_en:
# lines_en = f3_en.readlines()
f3_en = open(orig_srt_en_file, "r", encoding="UTF-8")
#print(lines_en)
for line in lines:
#for line_en in lines_en:
#for line, line_en in lines, lines_en:
#line = f.readline()
line_en = f3_en.readline()
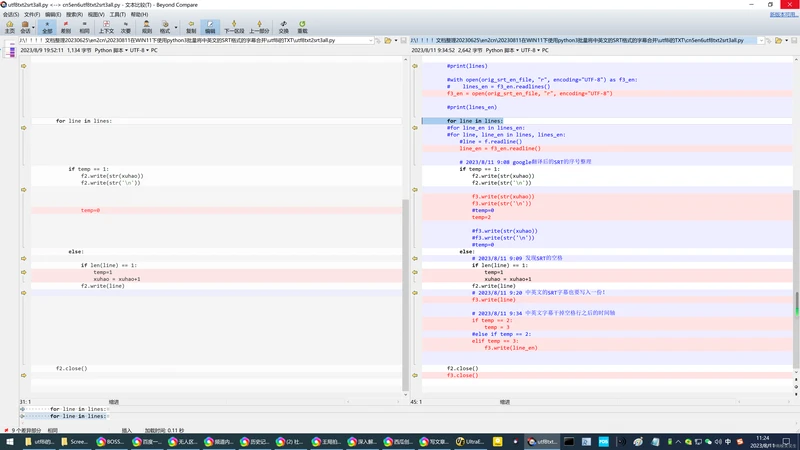
# 2023/8/11 9:08 google翻译后的SRT的序号整理
if temp == 1:
f2.write(str(xuhao))
f2.write(str('\n'))
f3.write(str(xuhao))
f3.write(str('\n'))
#temp=0
temp=2
#f3.write(str(xuhao))
#f3.write(str('\n'))
#temp=0
else:
# 2023/8/11 9:09 发现SRT的空格
if len(line) == 1:
temp=1
xuhao = xuhao+1
f2.write(line)
# 2023/8/11 9:20 中英文的SRT字幕也要写入一份!
f3.write(line)
# 2023/8/11 9:34 中英文字幕干掉空格行之后的时间轴
if temp == 2:
temp = 3
#else if temp == 2:
elif temp == 3:
f3.write(line_en)
f2.close()
f3.close()
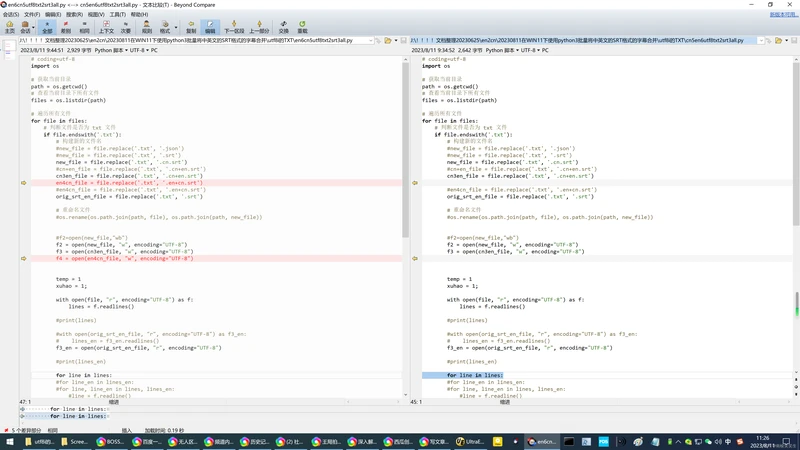
4、第三种方法:
英文在前,中文在后!
J:\!!!!文档整理20230625\en2cn\20230811在WIN11下使用python3批量将中英文的SRT格式的字幕合并\utf8i的TXT\en6cn5utf8txt2srt3all.py
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
#cn+en_file = file.replace('.txt', '.cn+en.srt')
cn3en_file = file.replace('.txt', '.cn+en.srt')
en4cn_file = file.replace('.txt', '.en+cn.srt')
#en4cn_file = file.replace('.txt', '.en+cn.srt')
orig_srt_en_file = file.replace('.txt', '.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
#f2=open(new_file,"wb")
f2 = open(new_file, "w", encoding="UTF-8")
f3 = open(cn3en_file, "w", encoding="UTF-8")
f4 = open(en4cn_file, "w", encoding="UTF-8")
temp = 1
xuhao = 1;
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
#print(lines)
#with open(orig_srt_en_file, "r", encoding="UTF-8") as f3_en:
# lines_en = f3_en.readlines()
f3_en = open(orig_srt_en_file, "r", encoding="UTF-8")
#print(lines_en)
for line in lines:
#for line_en in lines_en:
#for line, line_en in lines, lines_en:
#line = f.readline()
line_en = f3_en.readline()
f4.write(line_en)
# 2023/8/11 9:08 google翻译后的SRT的序号整理
if temp == 1:
f2.write(str(xuhao))
f2.write(str('\n'))
f3.write(str(xuhao))
f3.write(str('\n'))
#f4.write(str(xuhao))
#f4.write(str('\n'))
#temp=0
temp=2
#f3.write(str(xuhao))
#f3.write(str('\n'))
#temp=0
else:
# 2023/8/11 9:09 发现SRT的空格
if len(line) == 1:
temp=1
xuhao = xuhao+1
f2.write(line)
# 2023/8/11 9:20 中英文的SRT字幕也要写入一份!
f3.write(line)
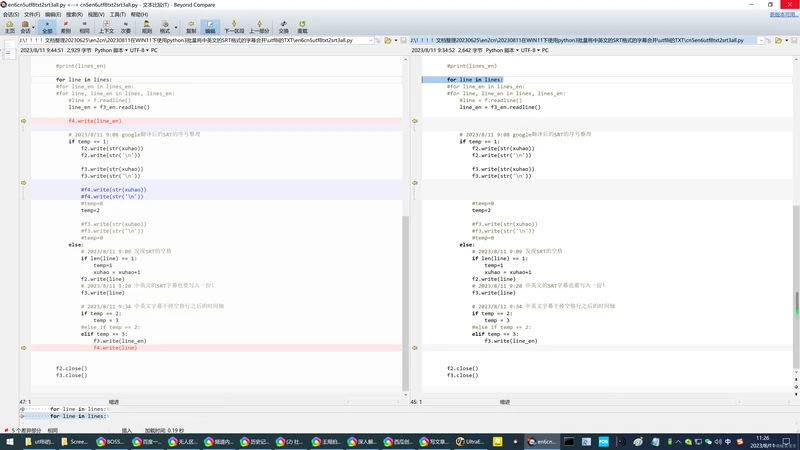
# 2023/8/11 9:34 中英文字幕干掉空格行之后的时间轴
if temp == 2:
temp = 3
#else if temp == 2:
elif temp == 3:
f3.write(line_en)
f4.write(line)
f2.close()
f3.close()