
业界流传着这样一句话"时间换空间,空间换时间",用这句话来形容HashMap非常的合适,其内部用一个大数组存储所有的value,并根据key直接计算出value应该存储在那个索引,如图:例如(key的hash值为假设)key="a" value="张三"的数据就存在索引index=1处,key="b" value="李四"的数据就存在索引index=3处
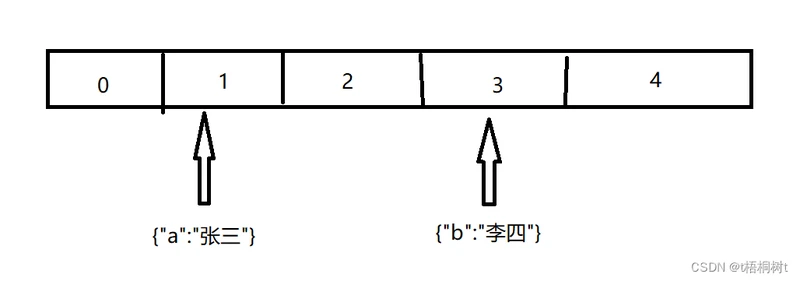
key索引的计算
key的索引计算很简单,以"a"为例,就是字符串"a"的hash值,故此我们经常使用String 作为 key,因为String 已经正确覆写equals方法.但如果我们放入的key 是一个自己写的类,就必须保证正确覆写equals方法.相同的key 对象(使用equals判断时返回true)必须要计算出相同的索引,否则,相同的key每次取出value就不一定对
通过key计算索引的方式就是调用key对象的hashCode()方法,它返回一个int整数.HashMap正是通过这个方法直接定位key对应的value的索引,继而直接返回value.
HashMap源码默认原始大小为16,那么问题就来了,我们定义的key计算后的hash值如果是超过了这个界限怎么办?hashCode()返回的int返回高达±21亿,先不考虑负数,HashMap内部使用的数组得有多大
其实这个问题也不低担心无论它的hashCode()有多大,都可以简单地通过:
int index = key.hashCode() & 0xf; //0xf = 15

 如上,我们得知字符串"王哈哈"的hash值为29119947,它跟15与完以后结果变成了11,这对于程序员来说理解起来不难,因为这个与的操作是在二进制的基础上与的
如上,我们得知字符串"王哈哈"的hash值为29119947,它跟15与完以后结果变成了11,这对于程序员来说理解起来不难,因为这个与的操作是在二进制的基础上与的
0001 1011 1100 0101 0101 1100 1011 (29119947的二进制)
1111 (15的二进制)
1011 (结果,十进制结果为 11)
那么如果超过了初始长度怎么办?
HashMap会在内部自动扩容,每次扩容一倍,即长度为16的数组扩展为长度为32,相应的,需要重新计算hashCode() 索引位置.那么如上例子的计算方式就会变为
0001 1011 1100 0101 0101 1100 1011 (29119947的二进制)
0001 1111 (31的二进制)
1011 (结果,十进制结果为 11)注意这里只是恰巧两个结果一样,并不是所有的结果都一样
由于扩容会导致重新分布已有的key-value,所以,频繁扩容对HashMap的性能影响很大.如果我们确定要使用一个10000个key-value的HashMap,更好的方式是创建HashMap时就指定容量: Map<String,Integer> map = new HashMap<>(10000);
虽然指定容量是10000,但是HashMap内部的数组长度总是 (2^n),因此,实际数组长度被初始化为比10000大的16384((2^14))
装了阿里巴巴代码公约插件的效果版应该都注意到过这个提示

此时看似完美,但还有一个问题,那就是有一些key计算后的hash值是一样的 我们就假设"a" 和"b" 这两个key 最终计算出的索引都是3,那么,在HashMap的数组中,实际存储的不是一个Person实例,而是一个List,它包含 两个Entry,一个是"a"的映射,一个是"b"的映射:
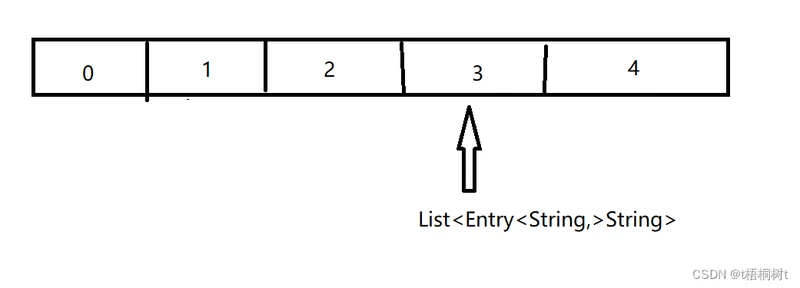
HashMap内部通过"a"找到的实际上是List<Entry<String,Person>>,它还需要遍历这个list,并找到一个Entry,它的key字段是"a",才能返回对应的Value