Backbone—— Neck —— Head
1.Backbone:翻译为骨干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络经常使用的是resnet VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
2.Neck:是放在backbone和head之间的,是为了更好的利用backbone提取的特征。
4.Bottleneck:瓶颈的意思,通常指的是网网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
2.Head:head是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。
Backbone结构分类
主要分成三类:CNNs结构, Transformer结构(如ViT及衍生算法,比如PVT),CNNs+Transformer结构。
前两者比较如下图所示:
零、 Image Classification on ImageNet 排行榜
见网址ImageNet Benchmark (Image Classification) | Papers With Code
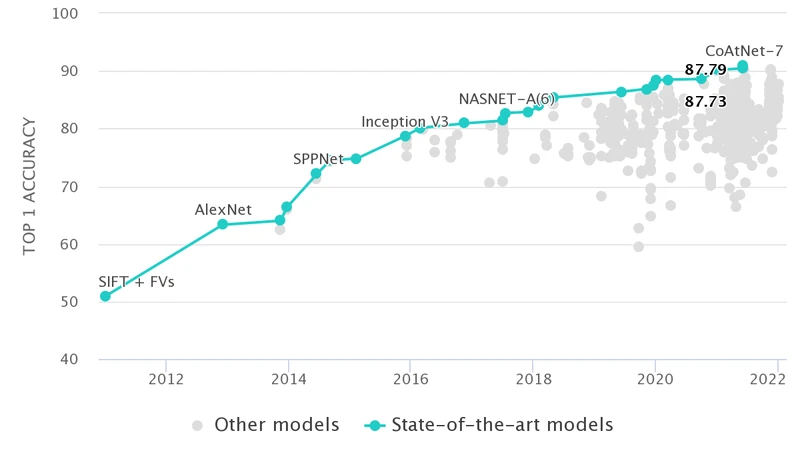
可以从该排行榜中挖掘主流的Backbone及其应用效果。
一、普通(非轻量化)CNNs结构Backbone
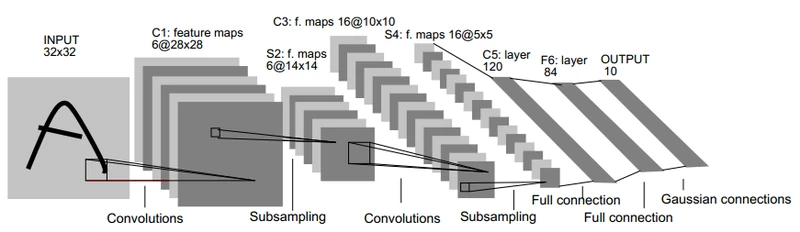
1. LeNet5:(1998)
https://ieeexplore.ieee.org/document/726791
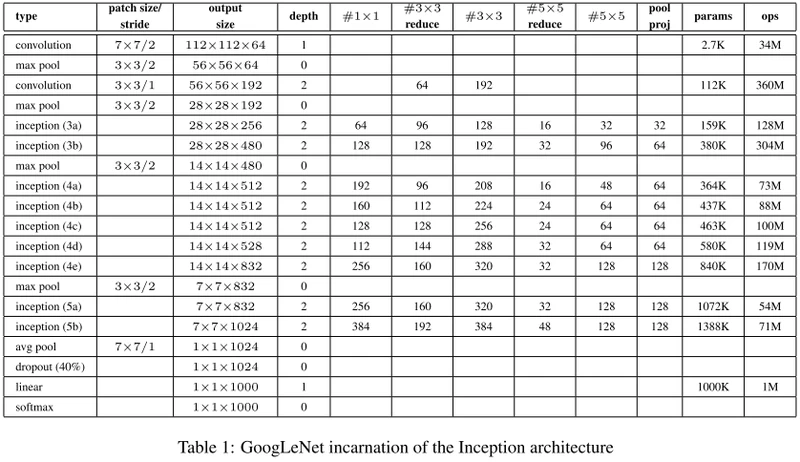
1998年,Yann LeCun等提出的LeNet5,用于手写数字识别的卷积神经网络。LeNet5一共有5层:2个卷积层(conv1,conv2)+3个全连接层(fc3,fc4,fc5),基本架构为:conv1->pool1->conv2->pool2->fc3->fc4->fc5->softmax,总共有60k参数。
| Name | Output | Kernel-Size | Padding | Stride | Channel |
| Input | 32*32 | / | / | / | 1 |
| Conv | 28*28 | 5*5 | 0 | 1*1 | 6 |
| Pool-ave | 14*14 | 2*2 | 0 | 2*2 | 6 |
| Conv | 10*10 | 5*5 | 0 | 1*1 | 16 |
| Pool-ave | 5*5 | 2*2 | 0 | 2*2 | 16 |
| Conv | 1*1 | 5*5 | 0 | 1*1 | 120 |
| FC | / | / | / | / | 84 |
| Output | / | / | / | / | N |
2. AlexNet:(2012)
https://dl.acm.org/doi/10.1145/3065386
2012年,Alex Krizhevsky等提出AlexNet。AlexNet是LSVRC-2012的冠军网络,在ImageNet LSVRC-2012的比赛中,取得了top-5错误率为15.3%的成绩。AlexNet一共有8层:5个卷积层(conv1,conv2,conv3,conv4,conv5)+3个全连接层(fc6,fc7,fc8),基本架构为:conv1->pool1->conv2->pool2->conv3–>conv4->conv5->pool5->fc6->fc7->fc8->softmax,总共有60M参数。
AlexNet 的突破点主要有:
- 网络更大更深,LeNet5(具体可以参考动图详细讲解 LeNet-5 网络结构) 有 2 层卷积 + 3 层全连接层,有大概6万个参数,而AlexNet 有 5 层卷积 + 3 层全连接,有6000万个参数和65000个神经元。
- 使用 ReLU 作为激活函数, LeNet5 用的是 Sigmoid,虽然 ReLU 并不是 Alex 提出来的,但是正是这次机会让 ReLU C位出道,一炮而红。关于激活函数请参考我的另一篇博客 深度神经网络中常用的激活函数的优缺点分析。AlexNet 可以采用更深的网络和使用 ReLU 是息息相关的。
- 使用 数据增强 和 dropout 来解决过拟合问题。在数据增强部分使用了现在已经家喻户晓的技术,比如 crop,PCA,加高斯噪声等。而 dropout 也被证明是非常有效的防止过拟合的手段。
- 用最大池化取代平均池化,避免平均池化的模糊化效果, 并且在池化的时候让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
| Name | Output | Kernel-Size | Padding | Stride | Channel |
| Input | 224*224 | / | / | / | 3 |
| Conv | 55*55 | 11*11 | 0 | 4*4 | 96 |
| LRN | 55*55 | 5 | / | / | 96 |
| Pool-max | 27*27 | 3*3 | 0 | 2*2 | 96 |
| Conv | 27*27 | 5*5 | 2*2(SAME) | 1*1 | 256 |
| LRN | 27*27 | 5 | / | / | 256 |
| Pool-max | 13*13 | 3*3 | 0 | 2*2 | 256 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 384 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 384 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 256 |
| Pool-max | 6*6 | 3*3 | 0 | 2*2 | 256 |
| FC+Dropout | / | / | / | / | 4096 |
| FC+Dropout | / | / | / | / | 4096 |
| Output | / | / | / | / | N |

3. VGG:(2014)
https://arxiv.org/abs/1409.1556v1
牛津大学视觉组/Google DeepMind提出来的。现在来看这个网络结构还是非常简单明了的:
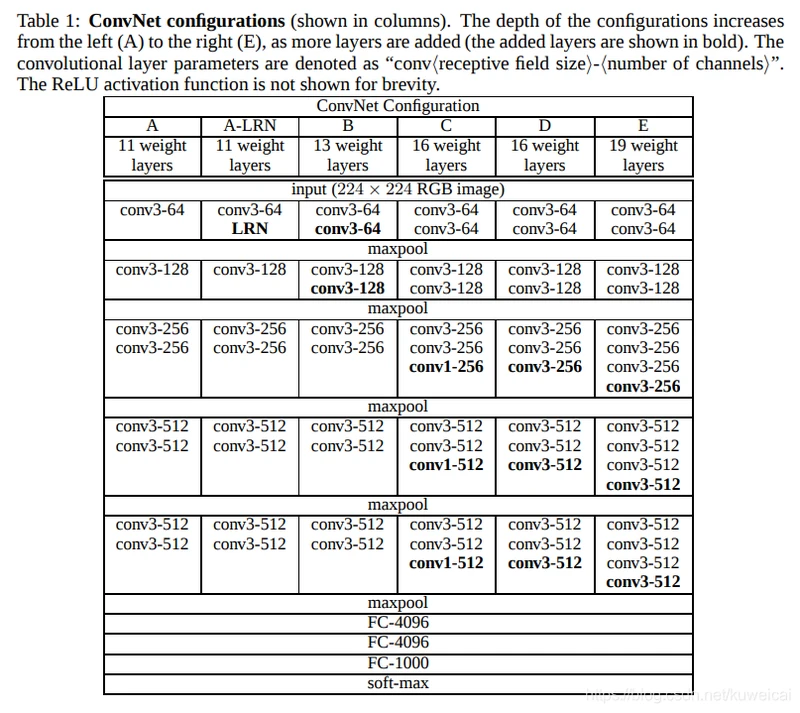
在但是 VGGNet 主要的突破在于:
-
选用比较小的卷积核(3x3),而之前无论 AlexNet 还是 LeNet5 都是采用较大的卷积核,比如 11x11, 7x7。而采用小卷积核的意义主要有两点,一是在取得相同的感受野的情况下,比如两个3x3的感受野和一个5x5的感受野的大小相同,但是计算量却小了很多,关于这点原文中有很详细的解释,建议直接看原文;第二点是两层3x3相比一层5x5可以引入更多的非线性,从而使模型的拟合能力更强,这点作者也通过实验进行了证明。其实这里还有一个优点就是采用小的卷积核更方便优化卷积计算,比如Winograd算法对小核的卷积操作有比较好的优化效果。
-
引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
-
训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
-
采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
-
在预测时:采用Multi-Scale策略,图像放缩至S,在最后一个卷积层,通过滑动窗口方法,分别获得各个窗口内特征的分类,再将所有分类求平均;
-
在训练时:采用数据增强方法:缩放至不同尺度(Multi-Scale),随机裁剪(Multi-Crop)为224*224,增加数据量,防止过拟合;
4. GoogLeNet(InceptionNet)系列
GoogLeNet 有多个版本(V1到V4),可以参考 :图像分类丨Inception家族进化史「GoogleNet、Inception、Xception」。
GoogLeNet 也叫 Inception net,因为 GoogLeNet 中的核心组成部分就是 inception module。另外值得一提的是 GoogLeNet 的名字有向 LeNet 致敬的意思。GoogLeNet 参加了2014年的 ImageNet 挑战赛,并取得分类任务第一名的成绩。GoogLeNet 相比 VGG 来说网络深度更进一步,达到了 22 层,另外在宽度上也做了拓展,但是参数量却小得多,而且效果也很不错.
YOLO V1 的主干网络就是基于 GoogLeNet 的。
先上Paper列表:
大体思路:
- [v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
- [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
- [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
- [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
- Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
- v2的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
- v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
- v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。
4. 1 Inception-v1(GoogleNet): (2015)
《Going Deeper with Convolutions》https://arxiv.org/abs/1409.4842
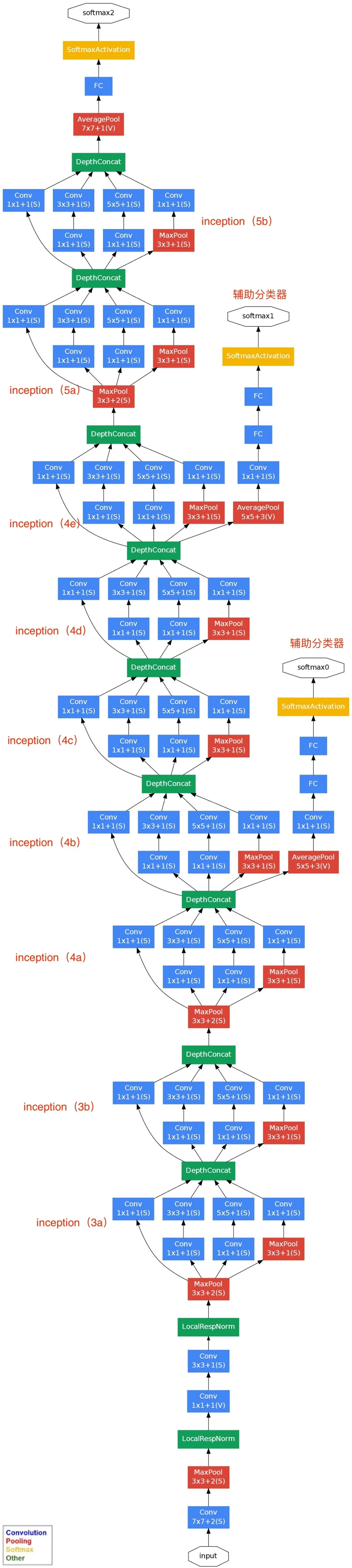
核心创意思想:如下图所示,由于图像的突出部分可能有极大的尺寸变化,这为卷积操作选择正确的内核大小创造了困难,比如更全局的信息应该使用大的内核,而更局部的信息应该使用小内核。不妨在同一级运行多种尺寸的滤波核,让网络本质变得更"宽"而不是”更深“。

于是,就提出Inception模块(左),具有三种不同的滤波器(1x1,3x3,5x5)和max pooling。为降低计算量,GooLeNet借鉴Network-in-Network的思想,用1x1卷积降维减小参数量(右)。可在保持计算成本的同时增加网络的深度和宽度。
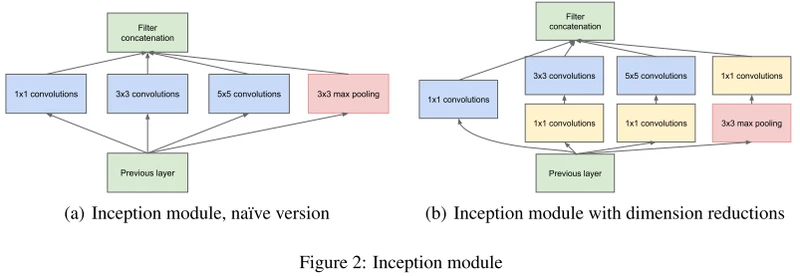
Inception控制了计算量和参数量的同时,获得了很好的性能,top-5错误率6.67%,只有约500万的参数量,Alexnet有6000万的参数。
GoogLeNet的关键点:
1、采用多分支结构(多分支分别计算,再级联结果),模块化结构(Inception)
2、采用1x1卷积的主要是为了减少维度;
3、使用average pooling(平均池化)来代替FC(全连接层);
4、为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
网络结构说明:
- GoogLeNet具有9个Inception模块,22层深(27层包括pooling),并在最后一个Inception模块使用全局池化。
- 由于网络深度,将存在梯度消失vanishing gradient的问题。
- 为了防止网络中间部分消失,作者提出了两个辅助分类器auxiliary classifiers,总损失是实际损失和辅助损失的加权求和。
# The total loss used by the inception net during training.
total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
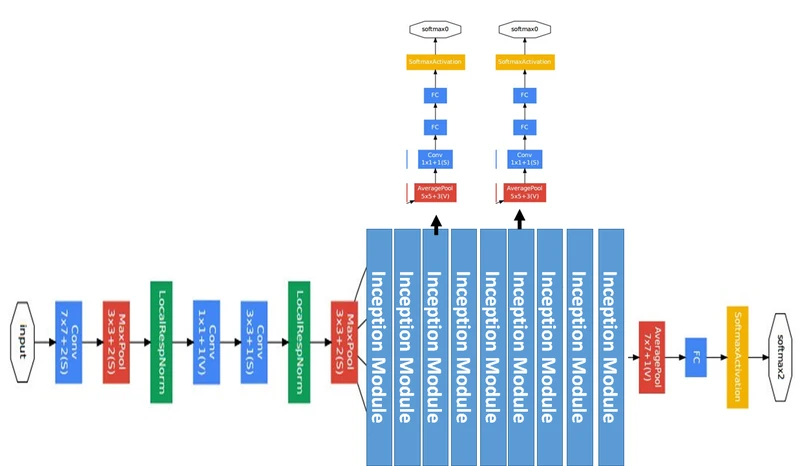
Inception Module中,1*1的卷积比例最高,3*3和5*5的卷积比例稍低,整个网络会有多个Inception Module。我们希望靠后的Inception Module可捕捉更高阶的抽象特征,因此靠后的Inception Module的卷积的空间集中度应该降低,这样可捕获大面积的特征。靠后的Inception Module中,3*3和5*5的占比更多。
4.3 Inception-v2 (2015,更确切地说是BN-inception)
涉及到两篇论文:
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
《Rethinking the Inception Architecture for Computer Vision》
google这边对于inception v2是属于哪篇论文有些不同观点,本博客是以下面第二种解释为准:
- 在《Rethinking the Inception Architecture for Computer Vision》中认为:基于inception v1进行结构的改进是inception v2;在inception v2上加上BN是inception v3;
- 在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中将《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》认为是inception v2(即inception v1 上进行小改动再加上BN);《Rethinking the Inception Architecture for Computer Vision》认为是inception v3
从google实现的Inception V1源码可以看出V2的改进主要是以下两点:
-
使用了Batch Normalization。BN带来的好处有: 对每一层的输入做了类似标准化处理,能够预防梯度消失和梯度爆炸,加快训练的速度;减少了前面一层参数的变化对后面一层输入值的影响,每一层独立训练,有轻微正则化效果
-
用两个3x3Convolution替代一个5x5Convolution。
另外一些细微的改变有:
- Inception 3模块的数量从原来啊的两个变为三个;
- 在Inception模块内部有的使用Max Pooling 有的使用Max Pooling;
- 两个Inception模块群之间没有明显的池化层,采用步长为2 的卷积代替,例如3c 和4e 层concatenate之前。