
2019.04.07 更新
清明把手头事情大致也办得差不多了,接下来就要开始忙课程上的项目了。本来打算今晚开始把tensorflow跟pytorch捡起来赶紧复习一下的了,可惜有时候人就是贱骨头,还是想要做一些自己“更感兴趣”的事情。选择了某B视频网站的登录尝试模拟登录。
为什么会选择去对付某B视频网站,主要想试试看能不能解决掉滑动验证码这个一直想尝试的问题。考虑到现在登录验证的方式往往更新得很快,因此这篇博客相对来说的时效性较强,我决定开始做一个持续更新的博客。
下面这段代码可以完成模拟滑动的操作,虽然并不能恰好补掉缺块。因为是从类中摘出,需要修正?
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
def login(self,):
browser = webdriver.Firefox()
browser.get(self.loginURL)
#browser.switch_to_frame('x-URS-iframe')
while True:
browser.find_element_by_id("login-username").send_keys(self.username)
browser.find_element_by_id("login-passwd").send_keys(self.password)
#xpath = "//li[@class='item gc clearfix']"
#li = browser.find_element_by_xpath(xpath)
#ActionChains(browser).click_and_hold(on_element=li).perform()
#input("已经点击了li标签了...")
xpath = "//div[@class='gt_slider_knob gt_show']"
try:
time.sleep(1)
div = browser.find_element_by_xpath(xpath)
break
except:
browser.refresh()
continue
ActionChains(browser).click_and_hold(on_element=div).perform()
html = browser.page_source
with open("3.txt","w") as f:
f.write(html)
input()
#input()
#time.sleep(0.15)
time.sleep(0.5)
ActionChains(browser).move_to_element_with_offset(to_element=div,xoffset=220,yoffset=22).perform()
"""
html = browser.page_source
with open("1.txt","w") as f:
f.write(html)
"""
time.sleep(0.5)
input("点击登录...")
xpath = "//a[@class='btn btn-login']"
browser.find_element_by_xpath(xpath).click() # 点击登录按钮
input("点击退出调试...")
browser.quit()
现在问题在于怎么处理那张缺了一块的图片,这个问题相当有趣,某B的网站设计员还动了点歪脑筋,居然把图片给切成几十块给打散再拼起来了,暂时我还没有找到辅原图片的JS代码,只能拿到被打散的图片?

如果解决了图片复原的工作,接下来就是开始判断缺块在哪里了。这件事情我感觉注定很有意思。
2019.04.08
刚了一晚上,真的是浪费时间,还好给这玩意儿刚掉了。
简单说一下思路了,在页面上审查元素就可以看到其实原图片也被划分为多个切片,而每个切片对应一个div标签,该div标签中的style属性下的background-position字段下的两个数字表明了这个切片在昨天那张碎碎图中的位置,因此复原图片的事情就一目了然了?
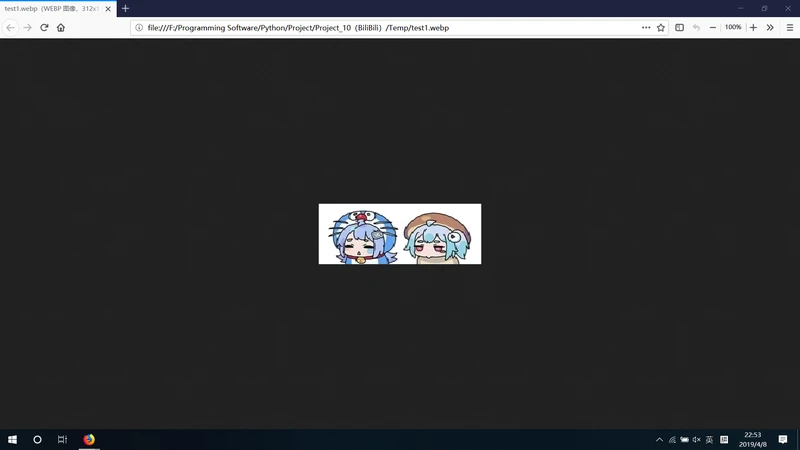
简单贴一张复原好的图片,全部代码在今天更新的结尾?
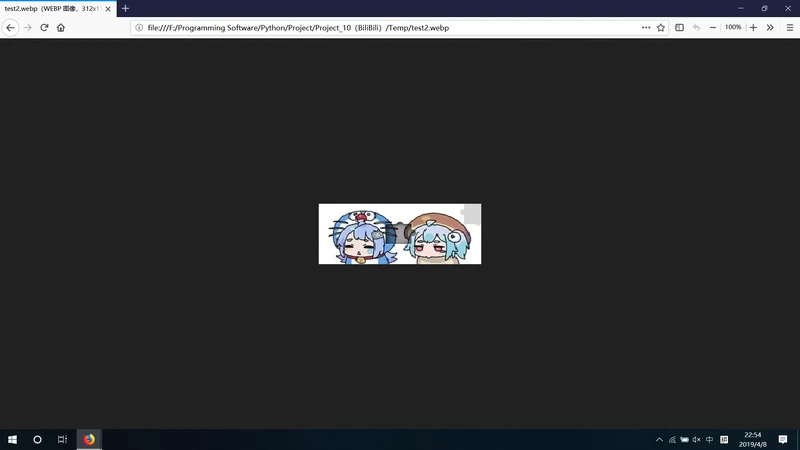
同理可以复原有缺块的图片?
接下来就是如何确定缺块位置。这两张图片都是116×312×3的矩阵,当然其实这两个图片没有缺块的部分的RGB值也不完全相同,因为我需要知道缺块在列宽上的位置,因此我选择将图片的RGB矩阵按列索引,在RGB三维上依次计算两张图片的余弦相似度SR、SG、SB,然后统计(3-SR-SG-SB)的值,得到了如下的图表?
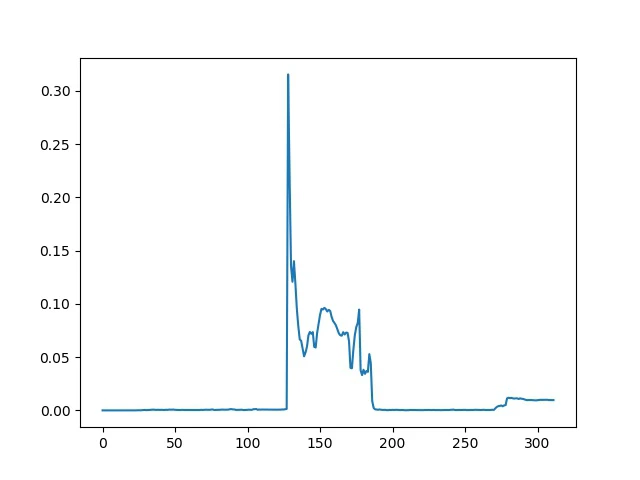
多试几次可以知道这张图的样子都差不了太多,高峰自然是缺块,另外最右边还有点突起的就是迷惑性缺块(虽然并没有什么用)。这里需要确定缺块的左边缘,多次尝试后结论是取数值前10大的横坐标,然后取他们中最小的横坐标即可;
当然问题还是有的,我一开始这么做始终对不上,后来终于发现这复原的图片跟网站上原图还是有区别的,显然长宽都被拉伸或压缩了。我的测试结果是移动min(index[:10])/1.15 - 10基本可以以较大的概率通过测试(1.15是放缩比例,移动的初始点距离图片左边缘的距离)。
事情当然没有这么简单,尽管这样可以完美补掉缺块,但是滑动验证码的精髓就在于它还能识别是否为真人操作。你一下子移过去重合缺块显然暴露了你开挂的本质,我后来又尝试到了之后来回抖一抖,还是不行。
查了一下大家的方法千奇百怪,甚至有用先匀加速再匀减速的方法去搞,然而我试了都不行,最后我经过多次尝试得到的方法是:先一下子划一半的距离,然后random.randint(5,9)px一步步往前走,距离目标少于10px时一步步1px走到终点。到了终点再来回5px抖一下就完事了。注意每次操作之间的时间间隔设置为random.uniform(0.5,1)s即可。
时间很急,写的也很急,直接给代码了吧?
import re
import os
import sys
import time
import json
import numpy
import pandas
import random
from PIL import Image
from requests import Session
from bs4 import BeautifulSoup
from selenium import webdriver
from matplotlib import pyplot as plt
from selenium.webdriver.common.action_chains import ActionChains
class BiliBili():
def __init__(self,
username="你的手机号",
password="你的密码",
userAgent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0",
): # 构造函数
""" 类构造参数 """
self.username = username
self.password = password
self.userAgent = userAgent
""" 类常用参数 """
self.workspace = os.getcwd() # 类工作目录
self.date = time.strftime("%Y%m%d") # 类构造时间
self.tempFolder = "Temp" # 存储临时文件的文件夹
self.mainURL = "https://www.bilibili.com/" # BiliBili主页
self.loginURL = "https://passport.bilibili.com/login" # 用户登录页面
self.options = webdriver.FirefoxOptions() # 火狐驱动配置
self.session = Session()
self.headers = {"User-Agent": userAgent}
""" 类初始化 """
self.session.headers = self.headers.copy()
self.options.add_argument("--headless") # 设定无头浏览器的配置
if not os.path.exists("{}\\{}".format(self.workspace,self.tempFolder)):
string = "正在新建文件夹以存储临时文件..."
print(string)
os.mkdir("{}\\{}".format(self.workspace,self.tempFolder)) # 新建文件夹存储临时文件
def login(self,): # 用户登录
def download_verifying_picture(divs,name): # 下载滑动验证图片
style = divs[0].attrs["style"]
index1 = style.find("(")
index2 = style.find(")")
url = eval(style[index1+1:index2])
html = self.session.get(url).content
with open("{}\\{}\\{}.webp".format(self.workspace,self.tempFolder,name),"wb") as f: f.write(html)
def recover_picture(divs,name): # 设法复原下载好的图片(该函数默认切片是两行)
index = []
for div in divs: # 遍历所有切片(52片)
style = div.attrs["style"]
index1 = style.find("background-position") # 寻找背景图的切片坐标
temp = style[index1+21:-1].strip().replace("px","").replace("-","").split()
temp = [int(i) for i in temp]
index.append(temp)
image = Image.open("{}\\{}\\{}.webp".format(self.workspace,self.tempFolder,name))
image = numpy.asarray(image) # 图片转矩阵
imageRe = numpy.zeros(image.shape) # 初始化复原图片矩阵
total = len(index) # 获取总切片数
Xaxis,Yaxis,Zaxis = image.shape # 获取图片三维信息(116×312×3)
X = int(2*Yaxis/total) # 每个切片的列宽(12px)
Y = int(Xaxis/2) # 每个切片的行高(58px)
index = [[int((indice[0]-1)/X),int(indice[1]>0)] for indice in index]
for i in range(total): # 遍历切片复原
x1 = index[i][0]*X # 切片实际左坐标
x2 = x1+X # 切片实际右坐标
y1 = index[i][1]*Y # 切片实际上坐标
y2 = y1+Y # 切片实际下坐标
a = int(Y) # 切片原横坐标
b1 = int((i%(total/2))*X) # 切片原上坐标
b2 = int((i%(total/2))*X+X) # 切片原下坐标
""" 判断当前切片是第几行(目前按照默认是前26个为第一行切片,后26个为第二行切片来做的) """
if i<total/2: imageRe[:a,b1:b2,:] = image[y1:y2,x1:x2,:] # 第一行
else: imageRe[a:,b1:b2,:] = image[y1:y2,x1:x2,:] # 第二行
imageRe = Image.fromarray(imageRe.astype("uint8")) # 图片格式的文件矩阵元素一定为uint8
imageRe.save("{}\\{}\\test{}.webp".format(self.workspace,self.tempFolder,name))
def find_block_space(width=53,zoo=1.15,plot=True): # 寻找缺块位置(默认参数width为缺块的列宽像素)
"""
这里的方法非常简单:
我本来是想可能需要用到opencv,
但是我发现因为已知复原图片的数据,
所以直接将图片数据的列向量计算相似度即可,
相似度最差的地方即为缺块;
另外观察发现图片的像素为行高59&列宽53,
共312px列中前53小的相似度列取中间位置应该即可;
"""
image1 = numpy.asarray(Image.open("{}\\{}\\test1.webp".format(self.workspace,self.tempFolder)))
image2 = numpy.asarray(Image.open("{}\\{}\\test2.webp".format(self.workspace,self.tempFolder)))
Xaxis,Yaxis,Zaxis = image1.shape # 获取图片三维信息(116×312×3)
errors = [] # 记录312列宽上每个列向量的非相似度值
for i in range(Yaxis):
total = 0
for j in range(Zaxis):
X = numpy.array([image1[:,i,j]]).astype("int64")
Y = numpy.array([image2[:,i,j]]).astype("int64").T
normX = numpy.linalg.norm(X,2)
normY = numpy.linalg.norm(Y,2)
dotXY = numpy.dot(X,Y)[0,0]
error = 1.- (dotXY/normX/normY) # 这里我选择累积RGB在(1-余弦相似度)上的值
total += error
errors.append(total)
tempErrors = errors[:]
tempErrors.sort(reverse=True)
index = [errors.index(i) for i in tempErrors[:width]] # 计算排序后对应的索引排序(根据图像的结果来看应该前width的索引是至少近似连续的自然数)
if plot:
plt.plot([i for i in range(len(errors))],errors)
plt.savefig("{}\\{}\\error.jpg".format(self.workspace,self.tempFolder))
return min(index[:10])/zoo-10
def get_track(xoffset): # 获取一条路径
tracks = []
x = int(xoffset/2) # 先走一半(很关键,不走不给过)
tracks.append(x)
xoffset -= x
while xoffset>=10:
x = random.randint(5,9)
tracks.append(x)
xoffset -= x
for i in range(int(xoffset)): tracks.append(1) # 最后几步慢慢走
return tracks
while True:
browser = webdriver.Firefox() # 驱动火狐浏览器
browser.get(self.loginURL) # 访问登录页面
interval = 1. # 初始化页面加载时间(如果页面没有加载成功,将无法获取到下面的滑动验证码按钮,林外我意外的发现有时候竟然不是滑动验证,而是验证图片四字母识别,个人感觉处理滑动验证更有意思)
while True: # 由于可能未成功加载,使用循环确保加载成功
browser.find_element_by_id("login-username").send_keys(self.username)
browser.find_element_by_id("login-passwd").send_keys(self.password)
xpath = "//div[@class='gt_slider_knob gt_show']" # 滑动验证码最左边那个按钮的xpath定位
try:
time.sleep(interval) # 等待加载
div = browser.find_element_by_xpath(xpath)
break
except:
browser.refresh()
interval += .5 # 每失败一次让interval增加0.5秒
print("页面加载失败!页面加载时间更新为{}".format(interval))
ActionChains(browser).click_and_hold(on_element=div).perform()
html = browser.page_source # 此时获取的源代码中将包含滑动验证图片以及存在缺块的滑动验证图片
soup = BeautifulSoup(html,"lxml") # 解析页面源代码
div1s = soup.find_all("div",class_="gt_cut_fullbg_slice") # 找到没有缺块的验证图片52个切片
div2s = soup.find_all("div",class_="gt_cut_bg_slice") # 找到存在缺块的验证图片52个切片
div3 = soup.find("div",class_="gt_slice gt_show gt_moving") # 找到那个传说中的缺块
download_verifying_picture(div1s,1) # 下载无缺块
download_verifying_picture(div2s,2) # 下载有缺块
recover_picture(div1s,1) # 复原无缺块
recover_picture(div2s,2) # 复原有缺块
xoffset = find_block_space()
"""
这里有个相当细节的地方:
我不知道为什么,如果连续两次使用move_by_offset,
后一次的move_by_offset会先将前一次的move_offset再执行一次,
然后才会执行当次move_offset,
所以这个轨迹要动点脑子才行;
"""
tracks = get_track(xoffset)
total = 0
for track in tracks:
print(track)
total += track
ActionChains(browser).move_by_offset(xoffset=track,yoffset=random.randint(-5,5)).perform()
time.sleep(random.randint(50,100)/100)
ActionChains(browser).move_by_offset(xoffset=5,yoffset=random.randint(-5,5)).perform()
ActionChains(browser).move_by_offset(xoffset=-5,yoffset=random.randint(-5,5)).perform()
time.sleep(0.5)
ActionChains(browser).release(on_element=div).perform()
time.sleep(3)
xpath = "//a[@class='btn btn-login']" # 登录按钮的xpath定位
browser.find_element_by_xpath(xpath).click() # 点击登录按钮
html = browser.page_source
time.sleep(1.)
soup = BeautifulSoup(html,"lxml")
title = soup.find("title")
if str(title.string[4])=="弹":
print("登录失败!")
browser.quit()
else:
print("登录成功!")
return
if __name__ == "__main__":
bilibili = BiliBili()
bilibili.login()
接下来可能就是要做后续的爬虫部分了,说实话很想一直做做这些事情,但是生活里总有其他事情不得不去做。这边就告一段落了,什么时候有时间再回来接着写了。
附一张登录成功的图片,希望之后回来这代码还能用吧【小电视 苦恼】

分享学习,共同进步!
2019.05.22
前几天去网页端看了看居然又改了,原先点出验证图片的按钮一开始就在页面上,现在需要输入用户名密码后点击登录才会弹出图片。虽然区别并不是很大,但是这改得也太不走心了,没什么区别好像。。。
2019.07.15
近期偷闲准备再做一些。
目前登录方式相对于20190408的区别在于一下几点:
- 次序上是先输入用户名密码, 点击登录后才会出现验证码图片;
- 验证码图片的元素结构变化, 没有小切片, 并且无法获取原图链接, 这大大增加了复原的难度(而且我还找不到);
- 滑动按钮并未改变, 因此看起来是极验自身升级了, 因为近期爬虫无登录需求, 不打算攻破这种验证码, 认为在识别上有一定难度;
主要忽然想要做一个NLP方向的事情,针对评论信息做点事情,第一步开始爬取评论信息,顺带就把B站的爬虫开始做起来了。因为事情稍微与标题有区别,将要重新写一篇博客。