
什么是模板引擎?
概括来说:将数据按照特定的方式转化为视图(html)的一种技术。
举个例子,将图中的data数据转化为 视图(html)结构数据。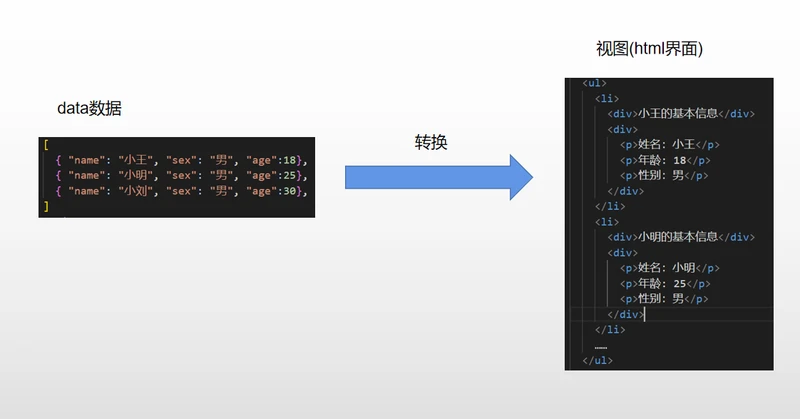
搬一下网上的概念:模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的文档。
模板引擎的核心原理就是两个字:替换。将预先定义的标签字符替换为指定的业务数据,或者根据某种定义好的流程进行输出。
Mustache模板引擎
Mustache介绍
Mustache是一款非常经典的前端模板引擎,是一套轻逻辑的模板语法。它可以来处理HTML,配置文件,源代码等文件。它把模板中的标签展开成给定的映射或属性值。这里的轻逻辑是指模板里面没有if语句,else语句,for循环语句,只有模板标签。
mustache 是 “胡子”的意思,因为它的嵌入标记{{}}非常像胡子。
mustache是最早的模板引擎库,比Vue诞生的早多了,它的底层实现机理在当时是非常有创造性的、轰动性的,为后续模板引擎的发展提供了崭新的思路。{{}}也被Vue沿用。
在前后端分离的技术架构中,前端模板引擎是一种可以被考虑的技术选型,随着前端三大框架(Angular、React、Vue)的流行,前端的模板技术已经成了标配。Mustache的价值在于稳定性和经典。
官网:https://mustache.github.io/mustache.5.html
Mustache的安装与使用
任何能够使用JavaScript的地方都可以使用mustache.js渲染模板。包括浏览器或者像node、CouchDB 这样的服务器环境。
Mustache安装
npm install mustache --save
Mustache使用
简单使用
我们来看一个简单的例子
import mustache from "mustache/mustache.mjs";
let view = {
title: "Joe",
calc: function () {
return 2 + 4;
}
};
let output = mustache.render("{{title}} spends {{calc}}", view);
console.log(output);
// Joe spends 6
通过上面的实例我们可以看到mustache使用{{和}}作为标记的界定符。Vue里面的双大括号语法参考了mustache的实现。mustache通过占位符来表示动态数据的位置。例如,一个{{title}}表示一个占位符,将在渲染的过程中被对应的数据替换。数据可以是简单的变量,也可以是对象的属性。
迭代列表
上面例子只是比较简单的情况,在实际的开发中,经常会出现嵌套,循环的情况,之前说到过mustache是一套轻逻辑的模板语法,里面没有for循环,为了解决这个问题,mustache提供了{{#condition}}...{{/condition}}和 {{#list}}...{{/list}}的语法,我们可以根据条件和迭代列表来渲染内容。其中双括号中的#代表条件或循环的开始,/代表结束,中间的内容就代表着循环体。
再看个例子
//引入Mustacha
import mustache from "mustache/mustache.mjs";
let template =
`<ul>
{{#arr}}
<li>
<div>{{name}}的基本信息</div>
<div>
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>`;
let view = {
arr:[
{ name: "小王",sex: "男",age: 18},
{ name: "小明",sex: "男",age: 25},
{ name: "小刘",sex: "男",age: 30}
]
}
let output = mustache.render(template,view);
console.log(output);
控制台输出:反引号法可以保留空格
从上面可以看到 mustache以一种非常简洁的方式生成了动态的内容。
Mustache解析数据规律
mustache引擎执行过程
通过上面的实例可以看到我们将只要渲染的数据和模板文件传递给Mustache模板引擎,引擎会自动的解析模板文件并根据数据进行渲染,生成最终的结果。那么模板引擎是如何实现这一过程的呢?看下这张图。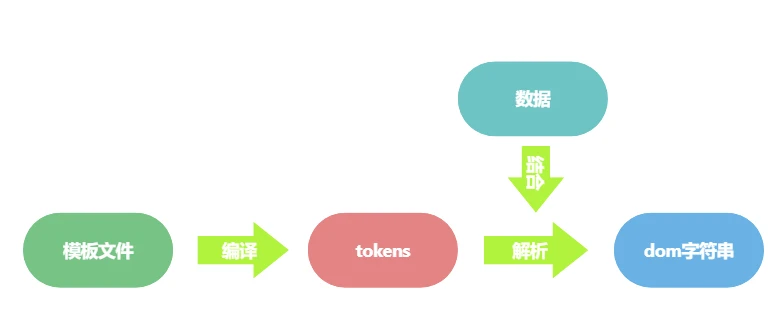
在这个过程中引擎会先将模板文件编译成tokens,然后再把tokens结合数据渲染成dom结构的字符串。也就是说它主要实现了两件事
- 将模板文件编译成tokens形式
- 将tokens结合数据,生成dom的字符串
tokens是什么
在mustache模板引擎中tokens是最重要的部分,它是连接模板文件和数据的桥梁。它本质是一个JS的嵌套数组,主要功能是将模板文件转化为JS可以操作的数据格式。
无循环嵌套情况
举个例子,如果模板文件是<h1>Today {{title}} spends {{calc}} dollar</h1>,那它经过编译后生成的tokens就是这种嵌套数组形式。
如上图所示,模板文件实际上就是一个纯文本文件,我们可以把它当做一个长字符串。在这个长字符串中以双括号{{}}为标记进行切割,切割后的一个个片段就是一个个token,用一个数组来存储token的信息。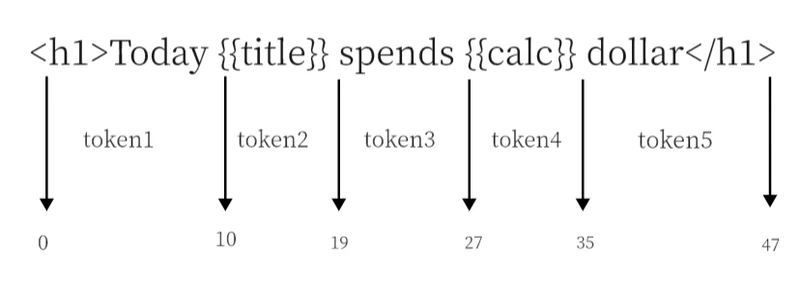
如图所示,每一个token元素对应一个数组,数组第一个元素存储token的类型,主要有text和name两种类型,text指代纯文本内容,不含标签,占位符和相关的控制结构。name指代{{}}双括号中的内容。,第二个元素存储对应的内容,第三和第四个元素是token字段的开始位置和结束位置,[0,10)左闭右开。
循环嵌套情况
上面的模板文件中是不包含迭代的,对于有嵌套循环的情况,Mustache模板引擎将循环嵌套部分当做一整个token,然后再将这整个token分割为一个个的小token。如下图所示:
上图中的模板文件是用 模板字符串(反引号) 包裹的,可以保留空格和换行,所以解析后的tokens中有空格和换行符\n。据图可以看到整个循环部分被当做一个token,token数组的第一个值是#表示这个token是迭代或条件token,第二个值就是迭代的列表或条件,第三、第四个值分别表示迭代条件的开始位置与结束位置,第五个值表示迭代的内容,作为一个tokens,套入其中。第六个值则是整个迭代结束的位置。
调试mustache模板引擎
我现在安装的mustache插件是最新版本,版本号为:4.2.0,引入的js文件的路径为:node_modules/mustache/mustache.js,找到js文件中的 parseTemplate 方法,其主要作用是生成tokens,修改代码,在控制台输出其生成的tokens。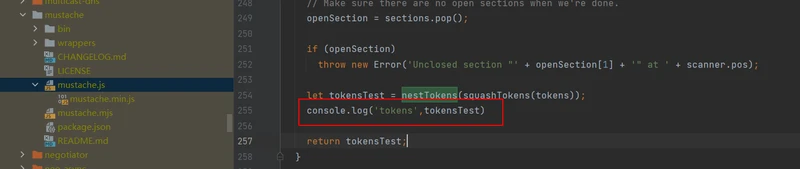
引入修改后的js文件,测试下
//引入Mustacha
import mustache from "mustache/mustache.js";
//创建一个模板
let template =
`<ul>
{{#arr}}
<li>
<div>{{name}}的基本信息</div>
<div>
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>`;
let view = {
arr:[
{ name: "小王",sex: "男",age: 18},
{ name: "小明",sex: "男",age: 25},
{ name: "小刘",sex: "男",age: 30}
]
}
let output = mustache.render(template,view);
控制台输出: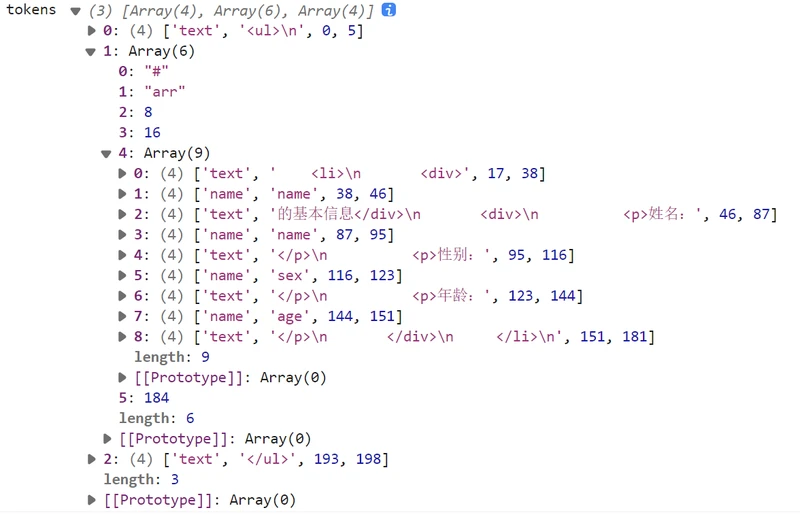
mustache模板引擎将模板字符串解析成tokens的规则我们已经了解清楚了,接下来尝试手动实现这个过程。
Mustache实现模板文件到tokens的转变
根据上面的介绍,我们已经了解到Mustache模板引擎解析数据的规律,接下来我们就需要用代码来实现模板文件到tokens的转变。
简单情况
最终目标
先看一下模板文件,我们需要将{{...}}中的内容提取出来,并将其转化为二维数组。在本次实现过程中token对应数组['text','<h1>Today',0,10]第三,第四元素未起到作用,所以我们只实现前两位['text','<h1>Today']
实现思路分析
1,想要提取模板字符串中的{{}}包裹的数据,必须要遍历模板字符串,来逐个查找。
2,设置一个指针pos,用来标记遍历模板字符串时的进度位置。
3,指针pos将模板字符串分割成两部分:已扫描字符串,待扫描字符串(包含pos指向的字符)。
4,指针pos向右移动,直到首次找到待扫描字符串前两位字符是{{时暂停扫描或未找到直接扫描完成。
5,如若匹配到待扫描字符串前两位字符是{{,并将此次扫描的字符串加入数组。注意,在{{符号前面的字符串的类型为text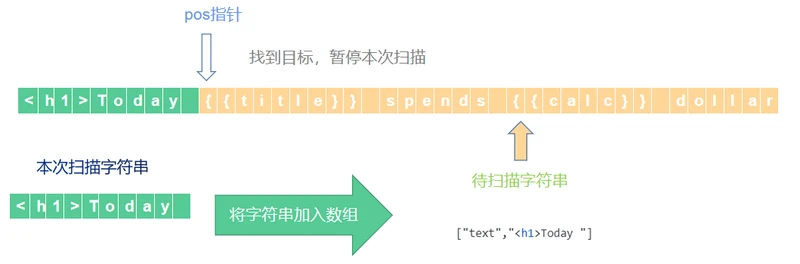
6,存储数据后继续扫描,并直接将指针pos前移两位。
7,继续扫描,直到首次找到待扫描字符串前两位字符是}}时暂停本次扫描或未匹配到直接扫描完毕。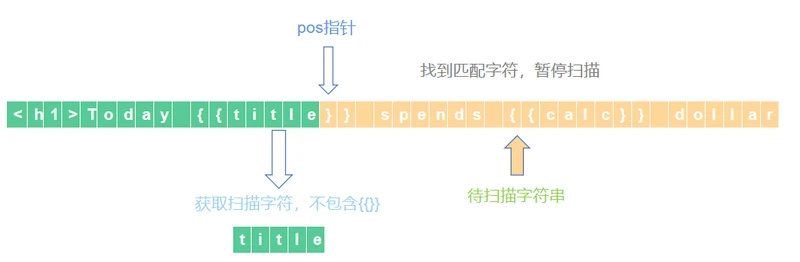
8,找到匹配元素后,将本次扫描数据存入数组中。并将指针pos后移两位。 注意在{{}}之前的字符串类型为name。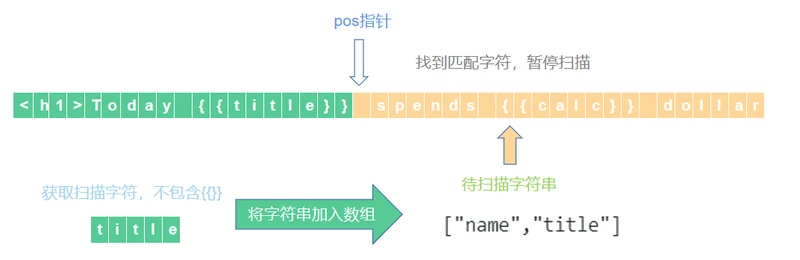
9,继续扫描,依次循环执行第4,5,6,7,8步的操作,直到字符串扫描结束。
代码实现
创建Scanner类,主要用作扫描模板字符串。
/**
* Scanner 类主要作用是扫描模板字符串
* 以'{{' 和 '}}'分隔,将字符串分离开来。
*/
export default class Scanner{
constructor(template){
//存储模板信息
this.template = template;
//初始标记位
this.pos = 0;
//待扫描字符串
this.tail = this.template;
}
/**
* 匹配 {{ }} 等串,并使指针pos前进2位,
* @param re
* @returns {string|*}
*/
scan(re){
this.startIndex = this.pos;
//匹配匹配待字符串中是否有 re
let match = this.tail.match(re);
//如果没有匹配到或匹配位置不是在头部,返回空字符串
if(!match || match.index !== 0){
return "";
}
//获取被匹配的字符 re
let string = match[0];
//待匹配字符串去掉被匹配的字符 re
this.tail = this.tail.substring(string.length);
//pos指针前进被匹配字符的长度
this.pos += string.length;
//返回被匹配字符re
return string;
}
/**
* 扫描模板字符串
* @param re
* @returns {string}
*/
scanUntil(re){
//search方法,用于检索字符串中指定的子串,或检索与正则表达式相匹配的子串,
//返回子串第一次出现的位置,没有匹配到则返回-1
//index 是匹配子串的位置, match是被被扫描的字符串
let index = this.tail.search(re),match;
switch(index){
//未匹配到,待匹配字符串被扫描完毕
case -1:
match = this.tail;
this.tail = "";
break;
//在字符串头部匹配到
case 0:
match = "";
break;
default:
match = this.tail.substring(0,index);
this.tail = this.tail.substring(index);
}
//指针pos前进扫描字符的长度
this.pos += match.length;
//返回扫描的字符串
return match;
}
/**
* 判断模板字符串是否扫描完成
* @returns {boolean}
*/
eos(){
return this.tail == '';
}
}
创建parseTemplateToTokens方法,将模板字符串转化为tokens。
//引入扫描器
import Scanner from "./Scanner";
export default function parseTemplateToTokens(template){
let tokens = [];
//创造一个扫描器实例
let scanner = new Scanner(template);
let word;
while(!scanner.eos()){
//匹配首次出现的{{,并获取匹配到的字符串
word = scanner.scanUntil('{{');
//将匹配字符串存入数组
if(word != ""){
tokens.push(['text',word]);
}
//指针pos后移
scanner.scan('{{');
word = scanner.scanUntil('}}');
if(word !=""){
tokens.push(['name',word]);
}
scanner.scan('}}');
}
return tokens;
}
测试:
import parseTemplateToTokens from "./parseTemplateToTokens";
let template = "<h1>Today {{title}} spends {{calc}} dollar</h1>";
let tokens = parseTemplateToTokens(template);
console.log(tokens);
控制台打印:
嵌套循环情况
最终目标
模板文件中有嵌套循环的部分,即将{{#...}}和{{/...}}之间的模板代码作为一个token存储起来,如图所示:
循环部分对应的token类型区别text和name,以#区分,内容存储在一个数组里面,作为token里面的第三个元素。循环嵌套部分的代码按照无嵌套循环的情况处理。
实现思路分析
以之前简单情况为基础,在其上面继续深入。以之前的处理逻辑,转换的结果如下
根据循环部分的规则,token的类型应该为#,我们需要做一下处理,将循环部分与非循环部分区分开。对parseTemplateToTokens方法做一下更改。
import Scanner from "./Scanner";
export default function parseTemplateToTokens(template){
...
while(!scanner.eos()){
...
//对{{}}内的数据做判断,是循环部分还是普通情况
word = scanner.scanUntil('}}');
if(word != ""){
//判断是否有循环
if(word[0] == "#"){
tokens.push(['#',word.substring(1)]);
}else if(word[0] == '/'){
tokens.push(['/',word.substring(1)]);
}else{
tokens.push(['name',word]);
}
}
scanner.scan('}}');
}
return tokens;
}
更改后测试结果为:
接下来,我们需要将循环的部分放到一个token里面,如下图所示:
将方框内的数据转化为一个数组,可以利用栈的思想,遇#入栈,遇/出栈。
实现思路过程:
创建三个数组:
nestTokens 主要用来存储修改后的tokens,
sections数组作为栈,存储循环,条件数据。
collector数组作为搜集器,搜集循环里面的数据。
初始时,nestTokens和collector指向同一个数组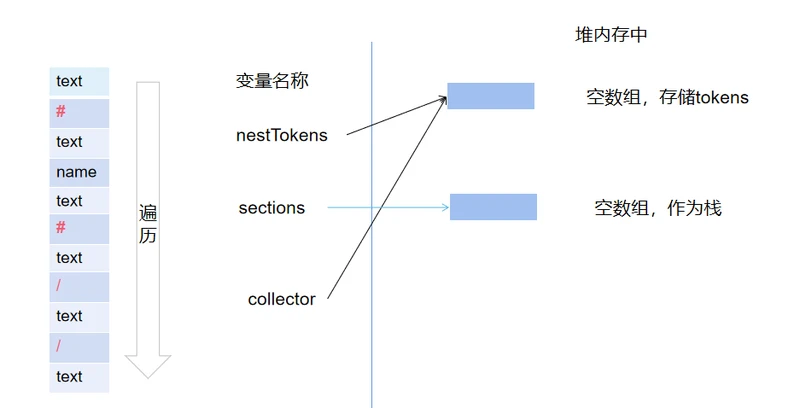
开始循环,正常情况,遇到text,name类型,使用collector.push(),方法添加进数组。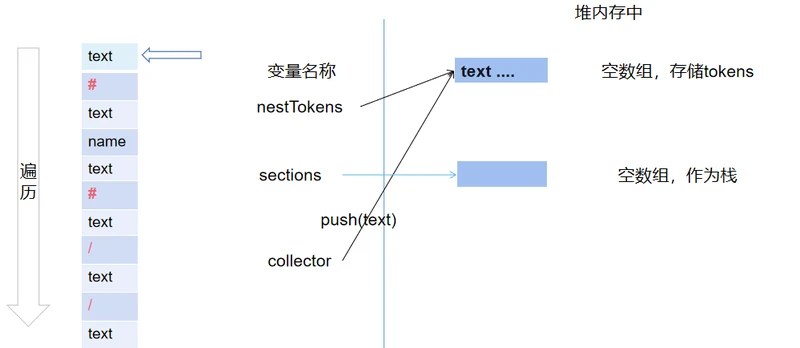
遇到#号,第一步,先将数据进栈。第二步,通过collector将数据添加到数组中。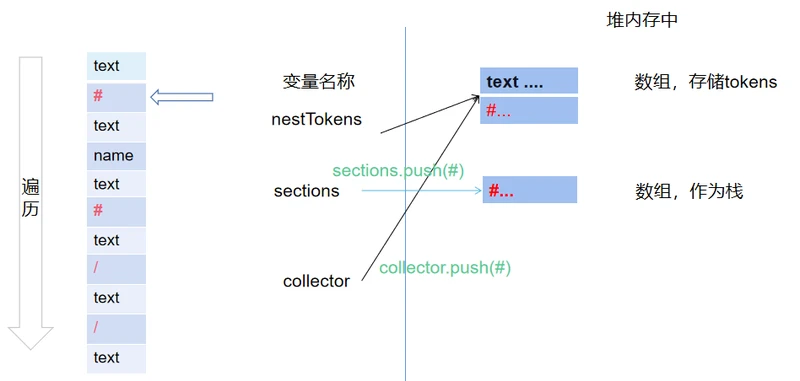
第三步,创建一个新数组存储循环部分数据,并将新数组作为类型为#数据的第三个元素,同时,将collector指向新数组。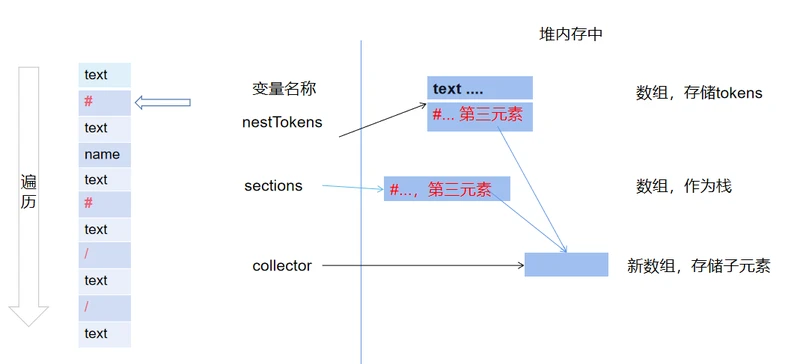
继续遍历,执行之前的操作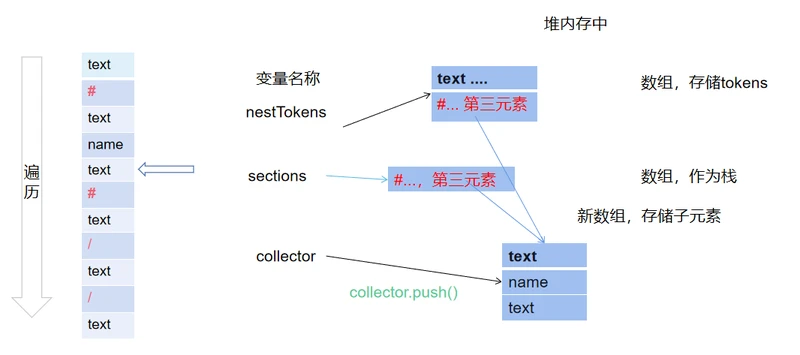
遇到#还是执行之前的操作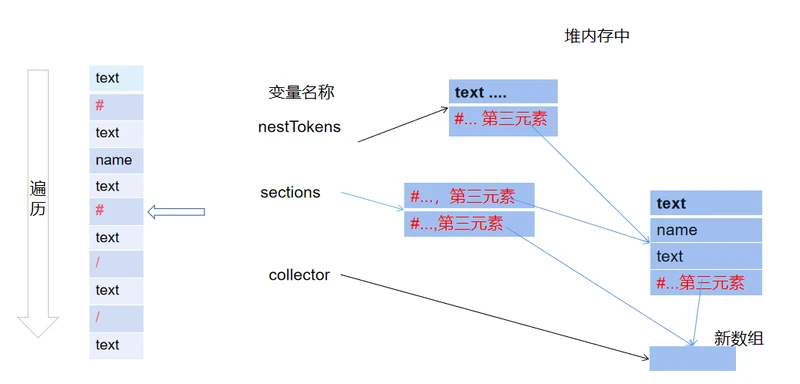
遇到/类型的token数据,表示一个循环结束,其之前的状态如下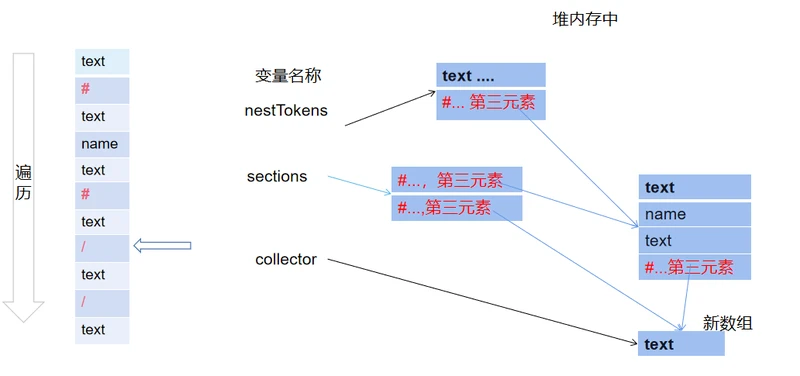
在这步需要执行的操作有:将section最近加入的元素弹出,并将collector指向上一层。这里指回上一层,是根据section里面的数据来判断的。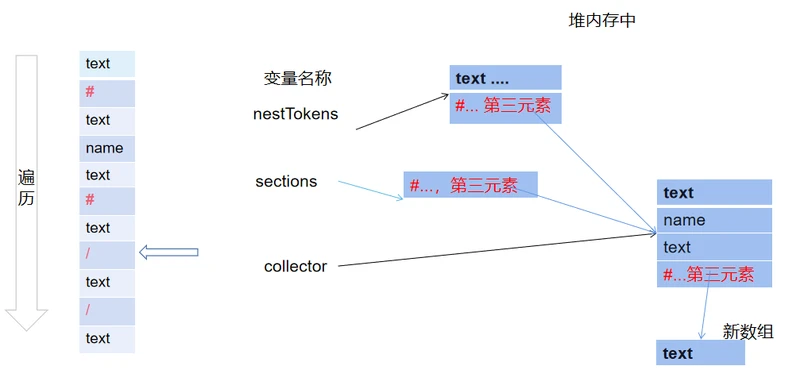
之后,继续执行,得到最终结果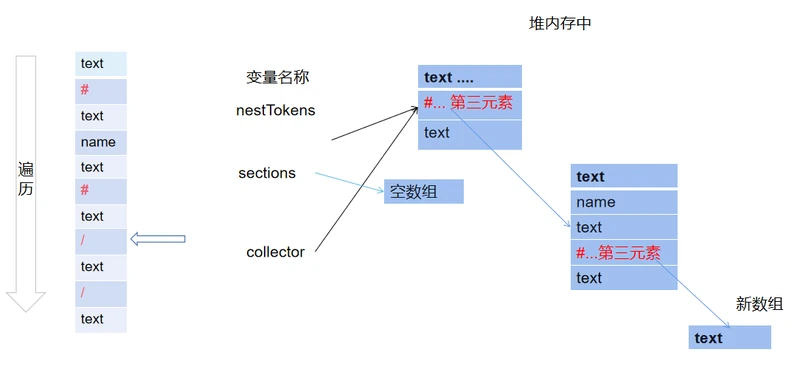
代码实现
创建nestTokens方法,实现对tokens的压缩。
export default function nestTokens(tokens){
//创建一个数组,存储修改后的tokens
let nestTokens = [];
//创建一个栈,存储循环,条件数据
let sections = [];
//创建一个搜集器,搜集循环里面的数据
let collector = nestTokens;
for(let i = 0; i<tokens.length; i++){
let token = tokens[i];
switch(token[0]){
case "#":
//入栈
sections.push(token);
//收集器collector收集数据
collector.push(token);
//改变收集器collector指向,之后可以将循环内数据存放到token中
collector = token[2] = [];
break;
case "/":
//遇到/就出栈
sections.pop();
//每次出栈说明该层循环遍历完成,改变collector的指向,将其指回上一层
collector = sections.length>0? sections[sections.length-1][2]:nestTokens;
break;
default:
collector.push(token);
break;
}
}
return nestTokens;
}
在parseTemplateToTokens中引入 nesTokens方法
import Scanner from "./Scanner";
import nestTokens from "./nestTokens";
export default function parseTemplateToTokens(template){
...
return nestTokens(tokens);
}
测试结果
let template =
`<ul>
{{#arr}}
<li>
<div>{{name}}的基本信息</div>
<div>
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
<p>
爱好:{{#hobbies}}
<span> {{.}} </span>
{{/hobbies}}
</p>
</div>
</li>
{{/arr}}
</ul>`;
let data = {
arr:[
{ name: "小王",sex: "男",age: 18,hobbies:["篮球","羽毛球"]},
{ name: "小明",sex: "男",age: 25,hobbies: ["王者荣耀","决斗连接"]},
{ name: "小刘",sex: "男",age: 30,hobbies: ["冲浪","滑雪"]}
]
};
import parseTemplateToTokens from "./parseTemplateToTokens";
let tokens = parseTemplateToTokens(template);
console.log(tokens);

至此,我们完成了从模板文件到tokens的转变,只剩下将tokens与数据结合生成对应的html。
Mustache实现tokens与数据的结合
关于将tokens与data结合生成html片段的代码我就不详细讲解了,不是很复杂,创建一个renderTemplate函数实现这个功能。
代码:
export default function renderTemplate(tokens,data){
let templateStr = "";
for(let i = 0;i<tokens.length;i++){
let token = tokens[i];
switch(token[0]){
case "text":
templateStr += token[1];
break;
case "name":
templateStr += lookup(data,token[1]);
break;
case "#":
case "^":
templateStr += parseArray(token,data);
break;
default:break;
}
}
return templateStr;
}
/**
* 将token转换成字符串
* @param token
* @param data
*/
function parseArray(token,data){
let tmpStr = "";
let childrenTokens = token[2];
let childData = [];
if(!data.hasOwnProperty(token[1])){
return tmpStr;
}else{
childData = data[token[1]];
for(let i=0; i<childData.length; i++){
tmpStr += renderTemplate(childrenTokens,childData[i]);
}
}
return tmpStr;
}
/**
* 取出data中对应的数据值
* @param data
* @param valueName
*/
function lookup(data,valueName){
let temp = data;
if(typeof temp == 'string' && valueName == '.'){
return temp;
}
let nameArr = valueName.split(".");
if(nameArr.length >0){
for(let i = 0;i<nameArr.length;i++){
temp = temp[nameArr[i]];
}
return temp;
}
}
测试
创建一个Mustache类,传入模板文件和数据,返回匹配好的字符串
import parseTemplateTOTokens from "./parseTemplateToTokens";
import renderTemplate from "./renderTemplate";
export default class Mustache{
constructor(template,data){
this.template = template;
this.data = data;
}
render(){
const {template,data} = this;
//获取token
let tokens = parseTemplateTOTokens(template);
//将token与数据结合
let templateStr = renderTemplate(tokens,data);
return templateStr;
}
}
将字符串挂载到界面上
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="app"></div>
<script>
let template = `<ul>
{{#arr}}
<li>
<div>{{name}}的基本信息</div>
<div>
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
<p>爱好:{{#hobbies}}<span> {{.}} </span>{{/hobbies}}</p>
</div>
</li>
{{/arr}}
</ul>`;
let data = {
title: "Joe",
calc:"6",
mentality:{
positive:"good"
},
arr:[
{ name: "小王",sex: "男",age: 18,hobbies:["篮球","羽毛球"]},
{ name: "小明",sex: "男",age: 25,hobbies: ["王者荣耀","决斗连接"]},
{ name: "小刘",sex: "男",age: 30,hobbies: ["冲浪","滑雪"]}
]
};
setTimeout(()=>{
let mustache = new Mustache(template,data);
let node = document.getElementById('app');
node.innerHTML = mustache.render();
},500)
</script>
</body>
</html>
界面显示: