
一、PR曲线
1.PR曲线的基本介绍
PR曲线(Precision-Recall Curve)是用来评估分类模型性能的一种常见方法。它是基于分类模型对不同阈值下的预测结果进行排序,并计算精确率(Precision)和召回率(Recall)之间的关系而得到的基本曲线。
精确率表示分类器在所有被预测为正例中真正为正例的比例,可以通过以下公式计算:
精确率P=TP/(TP+FP)
召回率表示分类器在所有实际为正例中正确预测为正例的比例,可以通过以下公式计算: 召回率R=TP/(TP+FN)
PR曲线横轴:召回率,纵轴精确率。分类器在不同阈值下会得到一系列不同的精确率和召回率值,通过将这些值以召回率为横坐标、精确率为纵坐标绘制成曲线,即为PR曲线。曲线上每个点表示了在对应召回率下的最大精确率值。当P=R时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以PR曲线越靠近右上角性能越好。
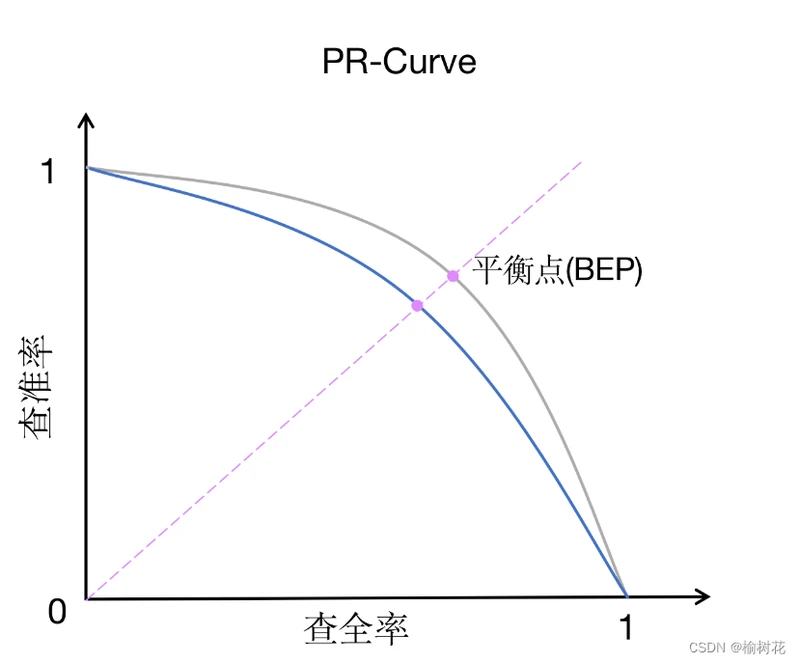
PR曲线的面积越大,表示分类模型在精确率和召回率之间有更好的权衡,性能越好。常用的评估指标是PR曲线下的面积,即PR AUC(Area Under the PR Curve),范围在0到1之间,数值越大越好。
2.PR曲线的绘制
- 准备数据:首先需要有一个分类模型,并使用这个分类模型对一组样本进行预测。对于每个样本,需要知道其真实标签和预测概率。
- 排序预测结果:根据预测概率,对样本进行排序,通常将预测概率从高到低排列。为后面的计算精确率与召回率提供基础。
- 计算精确率与召回率:从最高概率开始,逐个将阈值设为当前概率,计算得到相应的精确率和召回率。重复此过程,知道最低概率。记下每个阈值下的精确率和召回率。
- 绘制PR曲线:将得到的精确率和召回率值作为坐标点,绘制PR曲线。横轴表示召回率,纵轴表示精确率。可以通过连接这些坐标点,获得平滑的PR曲线。
- 计算PR AUC:将PR曲线下方的面积计算出来,即可得到PR AUC。
3.PR图像绘制实例
1.利用Scikit-learn机器学习库中的函数,生成了一个包含5000个样本和2个类别的数据集,包含一些特征和相应的类别标签,为训练和评估机器学习模型提供训练集。并且对数据进行划分训练集与测试集。
# 生成分类数据集
X, y = make_classification(n_samples=5000, n_classes=2, random_state=42)
print("x:")
print(X)
print("y:")
print(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
2.选择分类器
使用LogisticRegression 类构建一个逻辑回归模型,并将其命名为 model。然后,使用训练集数据 X_train 和对应的标签 y_train 来训练模型。
逻辑回归是一种常见的分类算法,在二分类问题中表现出色。它通过拟合一个S形曲线(也称为逻辑函数)来预测二分类问题中的类别。训练过程通常使用最大似然估计等方法来调整模型参数,使得模型能够预测正确的类别。
# 训练逻辑回归模型
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)3.首先使用训练好的模型对测试集样本进行预测,得到每个样本为正例的概率值,这部分代码使用了predict_proba函数。然后,使用NumPy中的argsort函数对预测概率进行排序,并将排序结果保存到sort_indices中。[::-1]表示倒序排列,即从大到小排列。
接下来,通过将测试集的真实标签y_test按照与sort_indices相同的顺序进行排序,得到y_test_sorted,这样可以与预测概率值y_scores_sorted一一对应。这样处理之后,我们就可以得到按照预测概率从高到低排列的测试集样本及其对应的真实标签。
# 对测试集进行预测并计算得分
y_scores = model.predict_proba(X_test)[:, 1]
# 根据预测概率进行排序
sort_indices = np.argsort(y_scores)[::-1]
y_test_sorted = y_test[sort_indices]
y_scores_sorted = y_scores[sort_indices]接着计算正例个数与负例个数
# 计算正例个数和负例个数
num_positives = np.sum(y_test)
num_negatives = len(y_test) - num_positives4.在for循环的作用下,通过公式P=TP/(TP+FP)计算精确率与R=TP/(TP+FN)计算召回率,并计算PR曲线下面积。
# 初始化PR曲线的变量
precisions = []
recalls = []
# 遍历不同阈值,计算对应的精确率和召回率
for i in range(len(y_scores_sorted)):
threshold = y_scores_sorted[i]
y_pred = np.where(y_scores_sorted >= threshold, 1, 0)
true_positives = np.sum(np.logical_and(y_pred == 1, y_test_sorted == 1))
false_positives = np.sum(np.logical_and(y_pred == 1, y_test_sorted == 0))
precision = true_positives / (true_positives + false_positives)
recall = true_positives / num_positives
precisions.append(precision)
recalls.append(recall)
# 计算PR曲线下方的面积
pr_auc = np.trapz(precisions, recalls)5.根据数据绘制PR曲线图
# 绘制PR曲线
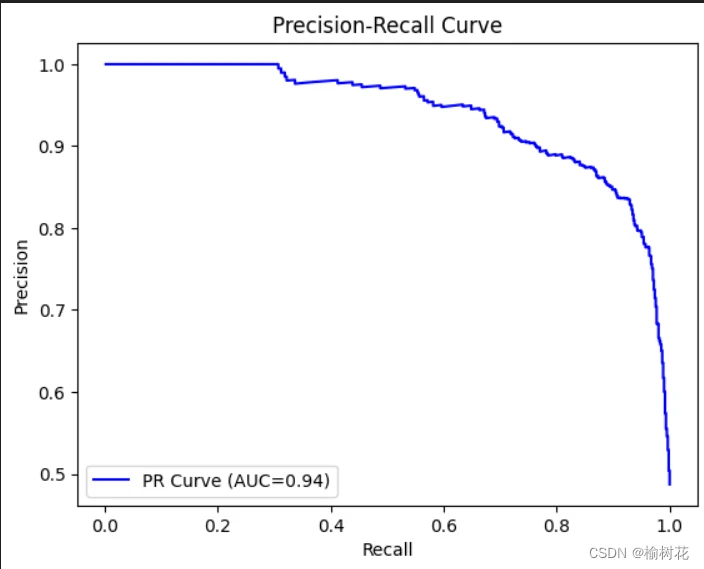
plt.plot(recalls, precisions, color='blue', label=f'PR Curve (AUC={pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.show()6.PR实验结果图:
二、ROC曲线
1.ROC曲线的基本介绍
ROC曲线(Receiver Operating Characteristic Curve)是用来评估二分类模型性能的一种常见方法。它是基于分类模型对不同阈值下的预测结果进行排序,并计算真正率(True Positive Rate,即召回率)和假正率(False Positive Rate)之间的关系而得到的曲线。
真正率指分类器在所有实际为正例中正确预测为正例的比例,可以通过以下公式计算: 真正率 = TP / (TP + FN)
假正率指分类器在所有实际为负例中错误预测为正例的比例,可以通过以下公式计算: 假正率 = FP / (FP + TN)
ROC曲线横轴表示假正率(FPR),纵轴表示真正率(TPR)。分类器在不同阈值下会得到一系列不同的真正率和假正率值,通过将这些值以假正率为横坐标、真正率为纵坐标绘制成曲线,即为ROC曲线。曲线上每个点表示了在对应假正率下的最大真正率值。因此ROC曲线越靠近左上角性能越好。
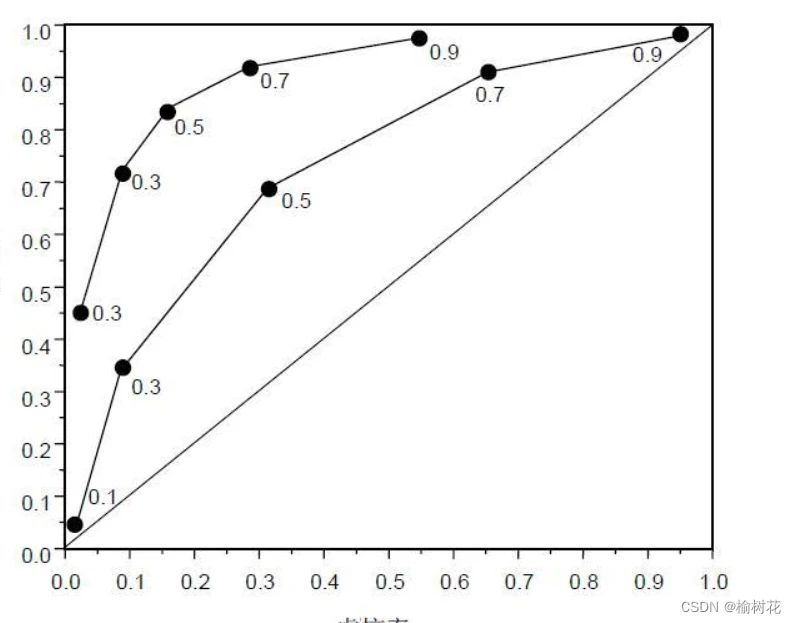
ROC曲线的面积越大,表示分类模型在FPR和TPR之间有更好的权衡,性能越好。常用的评估指标是ROC曲线下的面积,即ROC AUC(Area Under the ROC Curve),范围在0到1之间,数值越大越好。
2.ROC曲线的绘制
- 准备数据:首先,您需要有一个分类模型,并使用该模型对一组样本进行预测。对于每个样本,您需要知道其真实标签和预测概率(或分数)。
- 排序预测结果:根据预测概率(或分数),将样本进行排序,通常将预测概率从高到低排列。这将为之后计算真正率和假正率提供基础。
- 计算真正率和假正率:从最高概率开始,逐个将阈值设为当前概率,计算得到相应的真正率和假正率。重复此过程,直到最低概率。记下每个阈值下的真正率和假正率
- 绘制ROC曲线:将得到的真正率和假正率值作为坐标点,绘制ROC曲线。横轴表示假正率,纵轴表示真正率。可以通过连接这些坐标点,获得平滑的ROC曲线。
- 绘制对角参考线:在绘制ROC曲线时,通常会在图上绘制一条从原点(0,0)到(1,1)的对角参考线,表示随机猜测模型的性能。
- 计算ROC AUC:计算ROC曲线下方的面积,即ROC AUC。ROC AUC越大,表示分类模型的性能越好。
3.ROC图像绘制实例
1.利用Scikit-learn机器学习库中的函数,生成了一个包含5000个样本和2个类别的数据集,包含一些特征和相应的类别标签,为训练和评估机器学习模型提供训练集。并且对数据进行划分训练集与测试集。
# 生成分类数据集
X, y = make_classification(n_samples=5000, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)2.选择分类器
使用LogisticRegression类构建一个逻辑回归模型,并将其命名为 model。然后,使用训练集数据 X_train 和对应的标签 y_train 来训练模型。
# 训练逻辑回归模型
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)3.对测试集进行预测并根据预测概率进行排序。具体来说,该代码首先使用训练好的模型对测试集样本进行预测,生成每个样本为正例的概率。然后使用NumPy中的argsort函数对预测概率进行排序,并将排序结果保存到sort_indices中。[::-1]表示倒序排列,即从大到小排列。最后,将测试集的真实标签y_test按照与sort_indices相同的顺序进行排序,以便后续计算性能指标。
# 对测试集进行预测并计算得分
y_scores = model.predict_proba(X_test)[:, 1]
# 根据预测概率进行排序
sort_indices = np.argsort(y_scores)[::-1]
y_test_sorted = y_test[sort_indices]
y_scores_sorted = y_scores[sort_indices]接着计算正例个数与负例个数
# 计算正例个数和负例个数
num_positives = np.sum(y_test)
num_negatives = len(y_test) - num_positives
4.遍历不同阈值,计算对应的真正例率和假正例率
# 初始化ROC曲线的变量
tpr = [0] # 真正例率(True Positive Rate)
fpr = [0] # 假正例率(False Positive Rate)
# 遍历不同阈值,计算对应的真正例率和假正例率
for i in range(1, len(y_scores_sorted)):
threshold = y_scores_sorted[i]
y_pred = np.where(y_scores_sorted >= threshold, 1, 0)
true_positives = np.sum(np.logical_and(y_pred == 1, y_test_sorted == 1))
false_positives = np.sum(np.logical_and(y_pred == 1, y_test_sorted == 0))
tpr.append(true_positives / num_positives)
fpr.append(false_positives / num_negatives)
# 计算ROC曲线下方的面积
roc_auc = np.trapz(tpr, fpr)
5.绘制ROC曲线
# 绘制ROC曲线
plt.plot(fpr, tpr, color='red', label=f'ROC Curve (AUC={roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()6.ROC曲线实验结果图:
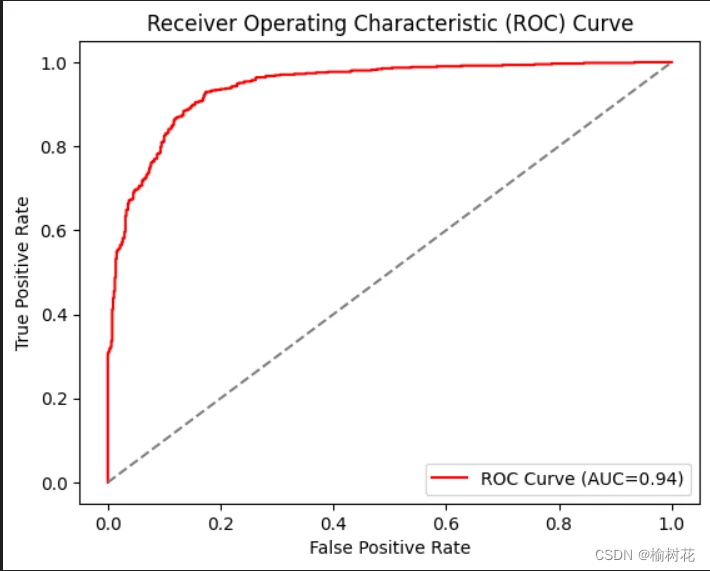
三、总结
1.PR曲线和ROC曲线的关系:
PR曲线和ROC曲线都能评价分类器的性能。如果分类器a的PR曲线或ROC曲线包围了分类器b对应的曲线,那么分类器a的性能好于分类器b的性能。
2.PR曲线和ROC曲线有什么联系和不同:
相同点:
- 1.评估二分类模型:ROC曲线和PR曲线都用于评估二分类模型的性能。
- 2.都展示了性能随阈值变化的趋势:两种曲线都可以显示一个模型在不同阈值下的性能变化趋势,帮助选择适当的阈值。
- 3.可以使用曲线下方的面积作为评估指标:两种曲线下方的面积可以作为衡量模型性能的指标,ROC曲线下方的面积为AUC(Area Under the Curve),PR曲线下方的面积为AP(Average Precision)。
不同点:
- 1.横纵轴的定义不同:ROC曲线的横轴是假正例率(FPR),纵轴是真正例率(TPR);PR曲线的横轴是召回率(Recall),纵轴是精确率(Precision)。
- 2.评估指标侧重点不同:ROC曲线关注的是真阳性率和假阳性率之间的平衡,即模型在不同阈值下正确分类正例和负例的能力;PR曲线关注的是精确率和召回率之间的平衡,即模型在不同阈值下找出正例的能力。
- 3数据分布不均衡情况下效果不同:当数据存在严重的类别不平衡问题时,两种曲线的形状可能会有差异。ROC曲线对类别之间的平衡性更为优势,而PR曲线对于不平衡类别更敏感。