
1、awk题 输出第二列重复的所有整行
awk题:如下文本内容
1 zhangsan
2 lisi
3 zhangsan
4 lisii
5 a
6 b
7 c
8 d
9 a
10 b
要求:输出第二列重复的所有整行,即输出结果:
1 zhangsan
3 zhangsan
5 a
9 a
6 b
10 bawk '{a[$2]++;if(a[$2]==1){b[$2]=$0};if(a[$2]==2){print b[$2]"\n"$0}}' aaa
如果有重复2行以上的:
awk '{a[$2]++;if(a[$2]==1){b[$2]=$0};if(a[$2]==2){print b[$2]"\n"$0}else if(a[$2]>2){print $0}}' aaa | sort -t " " -k2
其他方法 (明天再整理整理 2020年8月30日23:38:15)
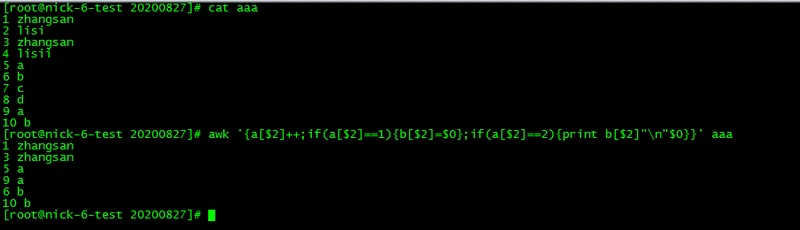
1、
for i in `awk '{print $2}' awk1.txt | awk 'a[$0]++'`; do grep -w $i awk1.txt ; done;
该方法有局限性,如果有3行重复的话。则不是想要的结果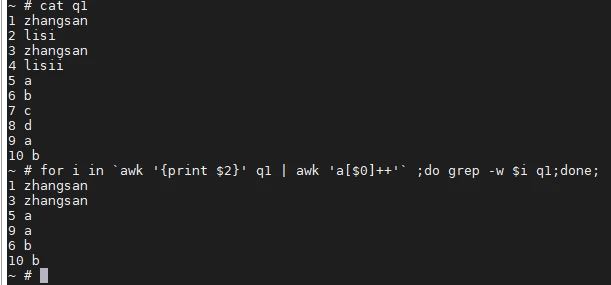
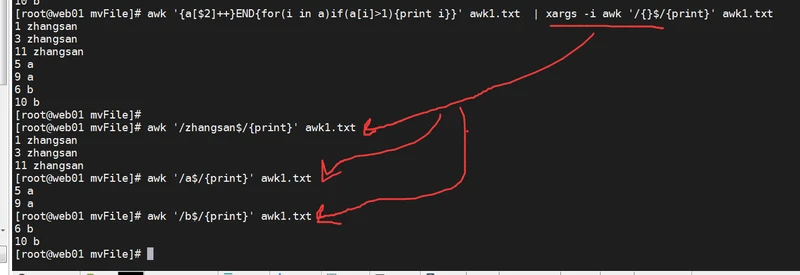
2、
awk '{a[$2]++}END{for(i in a)if(a[i]>1){print i}}' awk1.txt | xargs -i awk '/{}$/{print}' awk1.txt
前面出现两次及两次以上的内容,/{}$/ 的 $是锚定结尾
(本方法也适用于重复3条以上的数据)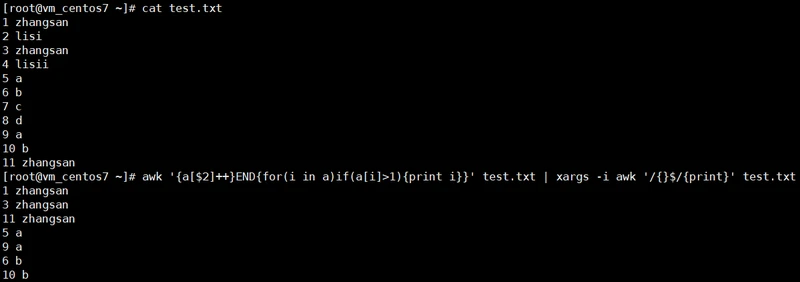
3、

2、sed更换文本中的ip 和 port
需求:
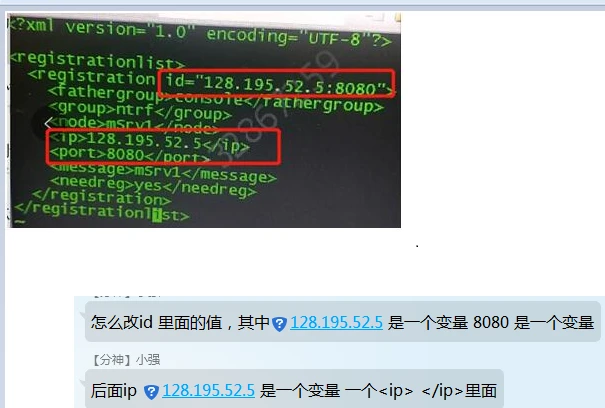
答案:
文本内容:
<registrationlist>
<registration id="128.195.52.5:8080">
<fathergroup>console</fathergroup>
<group>ntrf</group>
<node>mSrv1</node>
<ip>128.195.52.5</ip>
<port>8080</port>
<message>mSrv1</message>
<needreg>yes</needreg>
</registration>
</registrationlist>
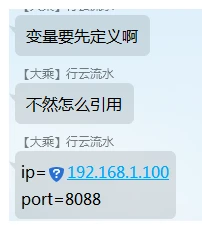
ip=192.168.1.100
port=8088
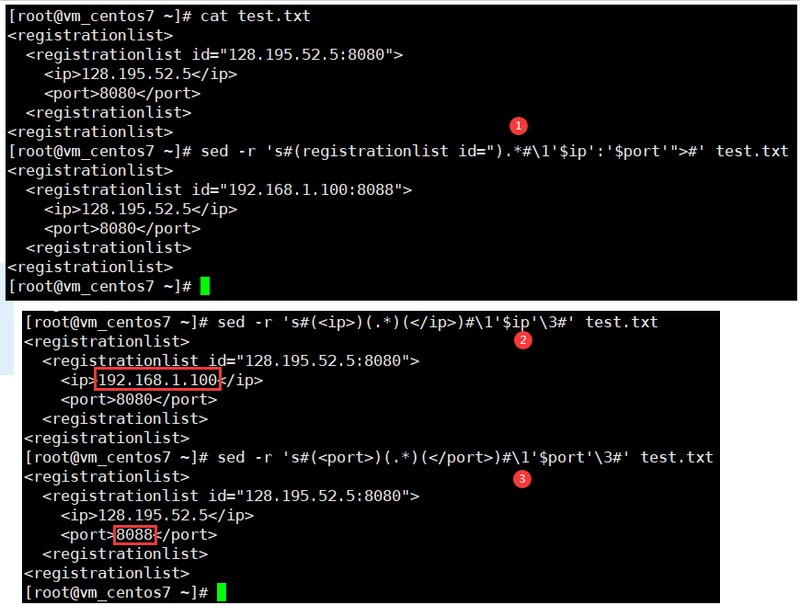
#step 1 :
sed -r 's#(registration id=").*#\1'$ip':'$port'">#' ipTest.txt
#sed -r 's#(registration id=").*(">)#\1'$ip':'$port'\2#' ipTest.txt
#step 2 :
sed -r 's#(<ip>)(.*)(</ip>)#\1'$ip'\3#' ipTest.txt
#step 3 :
sed -r 's#(<port>)(.*)(</port>)#\1'$port'\3#' ipTest.txt
#step 2 和 step 3 合并写成一行
sed -r 's#(<ip>)(.*)(</ip>)#\1'$ip'\3#;s#(<port>)(.*)(</port>)#\1'$port'\3#' ipTest.txt
=========分割线=====
#如果单纯改端口: 将aaaaaa改成对应端口号即可
sed -r 's#(<registration id="([0-9]+.){3}[0-9]+:).*(">)#\1aaaaaaaaa\3#' test1.txt
本次问题,对分组,后向引用的运用又增加了一些。
另一个需求:

<endpoint id="console" type="http" uri="/ntrf" sec-node-id="108032" default="true">
uri="/ntrf" /ntrf 这个值怎么改掉
uri="/ntrf" 比如变成 uri="/1234"
sec-node-id="108032" 108032 这个值怎么改掉
sec-node-id="108032" 比如变成 sec-node-id="1234"



3、获得当月的最后一 天
1、
cal | grep -Poz '\d+(?=\s*$)'
(注意grep的版本,如果是低版本, -z没效果)
2、
cal | perl -0anE'}{say pop@F'
3、
cal | awk 'NR==7{print $NF}'
4、
date -d "-$(date +%d) days +1 month" +%d
5、
date -d "$(date +%Y-%m-01) -1 day +1 month" +"%d"4、符合条件的打印出来,不符合则打印err
1、
awk '{print ($NF>2?$NF:"err")}' 1.txt
2、
awk '{if($NF>2"")print $NF;else print "err"}' 1.txt
3、
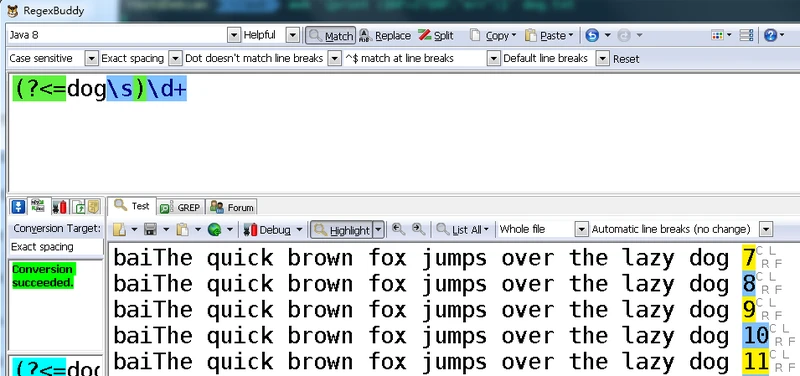
perl -lne 'if(/(?<=dog\s)\d+/){if($&>2){print $&}else{print "err"}}' 1.txt
(perl是没学过,但他是用零宽断言取最后的数字,然后做if判断)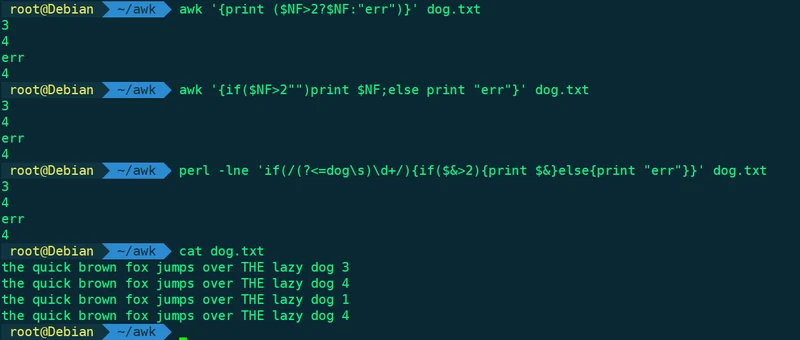
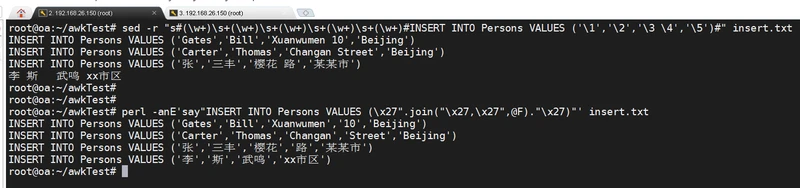
5、将数据拼接insert语句
Gates Bill Xuanwumen 10 Beijing
Carter Thomas Changan Street Beijing
张 三丰 樱花 路 某某市
李 斯 武鸣 xx市区1、自己写的 (写固定了,有局限性)
sed -r "s#(\w+)\s+(\w+)\s+(\w+)\s+(\w+)\s+(\w+)#INSERT INTO Persons VALUES ('\1','\2','\3 \4','\5')#" insert.txt
大佬给的建议是:两三个替换组合在一起也行,^替换成你那一长串字符,每个单词结尾替换成',',末尾替换成'),肯定是可以的,而且可以帮sed绕开每列不固定的问题。
三个替换写在一起就行了:开头,中间,结尾 写三个替换s###;s###g;s###
2、大佬写的perl (很强)
perl -anE'say"INSERT INTO Persons VALUES (\x27".join("\x27,\x27",@F)."\x27)"' insert.txt效果:
晚上根据大佬给的思路,写出的对应的指令:
sed -r "s#(\w+)\s#\1','#g;s#(\w+$)#\1')#;s#^(\w+)#INSERT INTO Persons VALUES ('\1#g" test
顺序是 末尾 -> 中间 -> 开头
最开始是 开头-> 中间-> 末尾。 这样有问题,第二个 s### 。把开头第一个 添加的字符串也加上 ','
=============
sed -r "s#^(\w+)\s+#INSERT INTO Persons VALUES ('\1','#g" test --开头
sed -r "s#(\w+)\s#\1','#g" test 中间单词
sed -r "s#(\w+$)#\1')#g" test --末尾
写法2

最开始的写法(但结果有误):

other:
[A-z]会匹配[,\,],^,-,`这6个字符,加个大小写字母,一共58个字符,不是52个各位尽量少用,尤其是如果文本内容很多,自己没办法概览全文的时候。加这6个字符其实是有意义的,也不是随便乱想

sed追加内容

2>/dev/null 可去掉下图红框的提示

取path的值:
<?xml version="1.0" encoding="UTF-8"?>
-
<FUSE xsi:noNamespaceSchemaLocation="../../schemas/sra-fuser.v2.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2018-01-22">
<File timestamp="2017-11-28T01:56:57" path="http://ftp-trace.ncbi.nlm.nih.gov/blast/db/cloud/2018-01-22/nr.00.phd" size="146765" name="nr.00.phd"/>
<File timestamp="2017-11-28T01:56:57" path="http://ftp-trace.ncbi.nlm.nih.gov/blast/db/cloud/2018-01-22/nr.00.phi" size="3504" name="nr.00.phi"/>1、
grep -oP '(?<=path=").*?(?=")' test1.txt
2、
grep -oP '(?<=path=")[^"]+' test1.txt
3、
grep -oP 'path="\K[^"]+' test1.txt