
1、Logistic回归分类
在研究X对于Y的影响时:
- 如果Y为定量数据,那么使用多元线性回归分析;
- 如果Y为定类数据,那么使用Logistic回归分析。
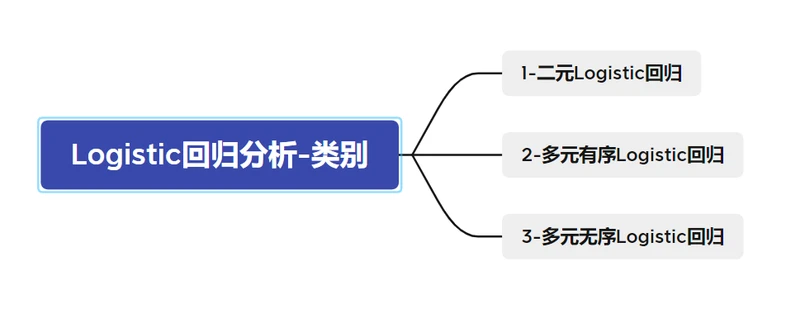
结合实际情况,可以将Logistic回归分析分为3类:
- 二元Logistic回归分析
- 多元有序Logistic回归分析
- 多元无序Logistic回归分析
Logistic回归分析用于研究X对Y的影响,并且对X的数据类型没有要求,X可以为定类数据,也可以为定量数据,但要求Y必须为定类数据,并且根据Y的选项数,使用相应的数据分析方法。
- 如果Y有两个选项,如有和无、是和否,那么应该使用二元Logistic回归分析;
- 如果Y有多个选项,并且各个选项之间可以对比大小,例如,1代表“轻度”,2代表“中度”,3代表“重度”,这3个选项具有对比意义,数值越高,代表样本的严重程度越高,那么应该使用多元有序Logistic回归分析;
- 如果Y有多个选项,并且各个选项之间不具有对比意义,例如,1代表“唱”,2代表“跳”,3代表“Rap”,4代表“篮球”,数值仅代表不同类别,数值大小不具有对比意义,那么应该使用多元无序Logistic回归分析。
2、二元逻辑回归
因变量为二分类变量,自变量可以为连续型变量也可以为分类变量,预测自变量和因变量之间的显著关系。
使用二元Logistic回归模型前,需判断是否满足以下七个研究假设:
- 假设1:因变量即结局是二分类变量。
- 假设2:有至少1个自变量,自变量可以是连续变量,也可以是分类变量。
- 假设3:每条观测间相互独立。分类变量(包括因变量和自变量)的分类必须全面且每一个分类间互斥。
- 假设4:最小样本量要求为自变量数目的15倍,也有一些研究者认为样本量应达到自变量数目的50倍
- 假设5:连续的自变量与因变量的logit转换值之间存在线性关系。
- 假设6:自变量间不存在共线性。
- 假设7:没有明显的离群点、杠杆点和强影响点。
参考链接:https://www.zhihu.com/question/34502688/answer/329779658
2.1 二元逻辑回归分析步骤
在进行二元logistic回归分析之前,需要进行一些准备工作,来提高分析结果的准确性。准备工作包括进行分析项即自变量的确定、多重共线性判断、以及变量处理三方面。
2.1.1 确定分析项(自变量的确定)
因为影响因素比较多,并不能确定单个影响因素是否会对因变量产生影响,为了筛选确实对因变量有影响的自变量进行分析,可以在进行二元logistic回归分析之前就单个因素的影响情况进行分析(非必要步骤)。根据影响因素类型不同,可以分别进行方差分析(t检验)、卡方检验进行分析。
- 连续变量使用方差分析
- 分类变量使用卡方检验
从方差分析和卡方检验的结果来看,如果显著性差异P<0.05,则对此变量予以保留,但并不是P>0.05的变量都要摒弃,一般我们可以将显著性水平P值放宽至0.1、0.2都可以,这是为了以防遗漏重要因素,当然也可以在不满足显著性水平的自变量中挑选现实中或临床上觉得有意义的指标,但是纳入模型的自变量不是越多越好,原因如下:
- 当自变量过多的时候,为了避免回归模型过拟合,因此我们会基于P值差异性检验选择变量,这种方法通过设定一个P值阈值(如0.1、0.2)来筛选变量,只有那些P值小于阈值的变量才会被包括在模型中。这种方法可以帮助简化模型,减少不必要的变量,但也可能排除一些实际上对模型预测有贡献的变量。
- 如果将所有自变量放入模型,这种方法可能会包括所有可能影响因变量的变量,但这也可能导致模型过拟合,即模型在训练数据上表现良好,但在新的、未见过的数据上表现不佳。此外,过多的自变量可能导致模型解释性差,因为很难确定哪些变量真正对结果有显著影响。
- 有效纳入分析的数据量不能过少,一般我们认为数据量至少是自变量数目的5~10倍。
2.1.2 多重共线性判断
在模型纳入模型时,纳入的变量也要考虑到变量之间的多重共线性,如果模型中的变量之间存在高度相关性,可能需要考虑移除一些相关性高的变量,以减少模型的复杂性,原因如下:
- 影响模型稳定性:多重共线性意味着模型中的两个或多个自变量高度相关。这会导致模型的参数估计不稳定,小的数据变化可能导致估计系数的大幅度波动。
- 降低模型解释能力:当存在多重共线性时,很难确定是哪一个自变量对因变量有显著影响,因为它们之间的影响可能会相互掩盖。这降低了模型的解释能力,使得研究者难以解释模型结果。
- 影响模型预测能力:由于参数估计的不稳定性,多重共线性可能会降低模型的预测准确性。模型可能在训练数据上表现良好,但在新的、未见过的数据上表现不佳。
- 统计显著性问题:多重共线性可能导致统计检验的P值不准确,使得原本不显著的变量被错误地认为显著,或者相反,显著的变量被错误地忽略。
- 模型复杂性:多重共线性可能导致模型过于复杂,包含不必要的变量,这不仅增加了模型的计算成本,也可能使得模型难以理解和应用。
为了判断多重共线性,常用的统计量包括方差膨胀因子(Variance Inflation Factor, VIF)和容忍度(Tolerance)。VIF值大于10通常被认为是严重的多重共线性。如果发现模型中存在多重共线性,可以采取以下措施:
- 移除相关性高的变量:从模型中移除一些高度相关的自变量。
- 合并变量:如果两个变量高度相关,可以考虑将它们合并为一个新的变量。
- 增加样本量:有时候,增加样本量可以减轻共线性问题。
- 使用主成分分析(PCA)或因子分析:这些方法可以减少变量的数量,同时保留大部分信息。
在进行二元逻辑回归之前,确保模型中没有严重的多重共线性,可以帮助提高模型的稳定性、解释能力和预测能力。
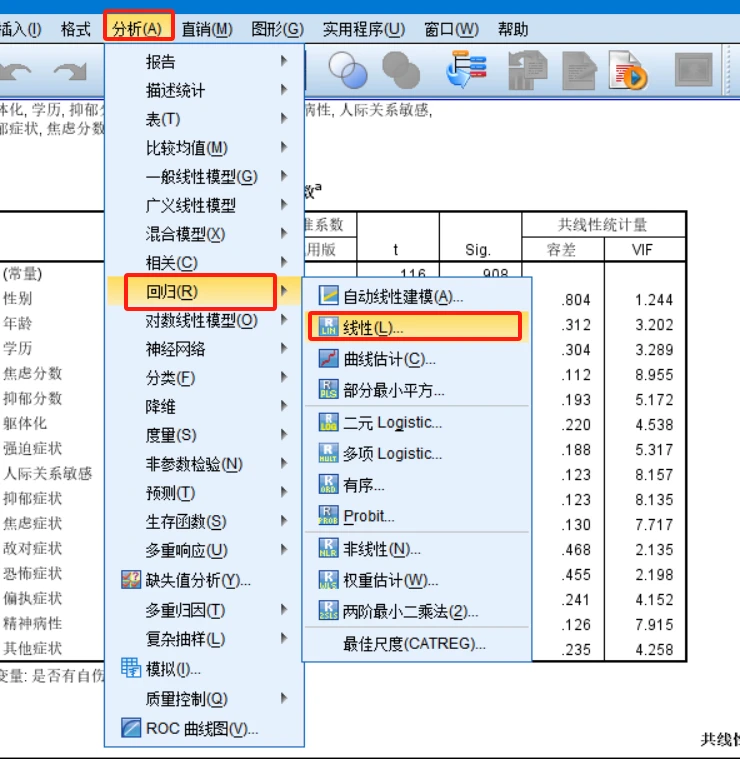
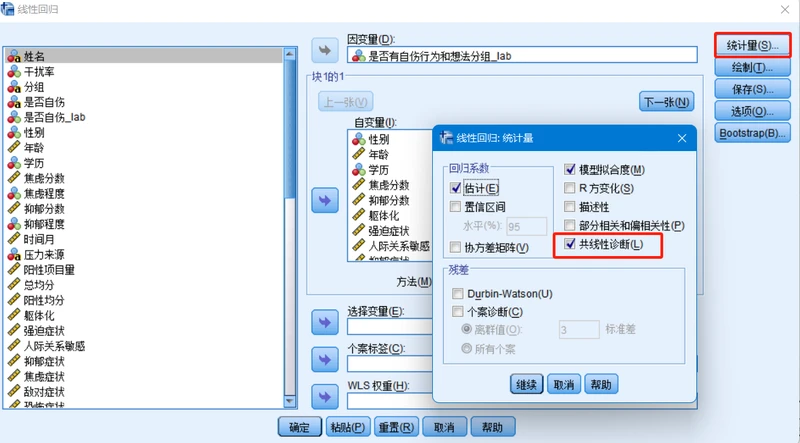
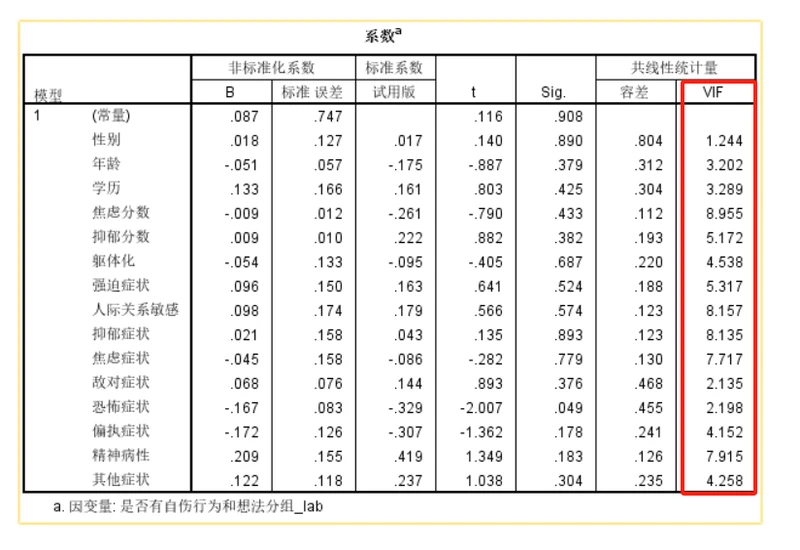
共线性诊断SPSS流程:
- 1、分析–>回归–>线性
- 2、填入因变量 --> 填入自变量 --> 统计量 --> 勾选共线性诊断
- 3、结果展示
从上表可以看出,VIF值均小于10,说明模型并不存在共线性问题。如果存在共线性问题可使用岭回归或者逐步回归进行解决。
2.1.3 数据预处理
在进行二元逻辑回归之前,进行数据预处理是一个关键步骤,原因包括:
- 提高模型准确性:通过预处理,可以确保数据的质量,减少噪声和异常值的影响,从而提高模型的预测准确性。
- 处理缺失值:数据集中的缺失值会影响模型的训练。预处理可以帮助决定如何处理这些缺失值,例如通过删除、填充或使用模型预测缺失值。
- 变量转换:某些变量可能需要转换(如对数转换、标准化、归一化等)以满足线性回归模型的假设,或者改善变量与因变量之间的关系。
- 处理异常值:异常值可能会扭曲模型的参数估计。通过识别和处理异常值,可以避免这些极端值对模型的影响。
- 变量选择:通过预处理,可以进行变量选择,移除不相关或冗余的变量,从而简化模型并减少多重共线性的风险。
- 编码分类变量:逻辑回归模型通常需要数值输入,因此需要将分类变量(如性别、种族等)转换为数值形式,如使用哑变量编码。
- 平衡数据集:在二元逻辑回归中,如果数据集中的两个类别(如0和1)分布极不平衡,可能需要进行过采样或欠采样来平衡数据集,以避免模型偏向于多数类。
- 理解数据结构:预处理过程中的数据探索可以帮助研究者更好地理解数据的结构和潜在问题,为模型的建立提供指导。
- 提高计算效率:清洗和预处理数据可以减少不必要的计算,提高模型训练的效率。
- 确保模型假设:逻辑回归模型有一些基本假设,如线性关系、独立性等。预处理可以帮助确保数据满足这些假设,从而使得模型结果更可靠。
数据哑变量处理:
- 因变量0-1编码:二元logistic回归分析要求因变量必须用数字0、1进行编码,即“是”用1表示,“否”用0表示。
- 2 分类自变量哑变量处理:二元logistic回归分析中自变量既可以是定量数据也可以是分类数据,如果是分类数据需要进行哑变量处理,在分析时将生成的哑变量少放一项,作为参考项。在进行分析时,对于严重程度【正常、轻、中、重度】4个哑变量,需要保留一项作为对照项,不放进分析框中。比如将“正常”作为对照项,则不将该哑变量放入分析框中,将剩下的3类程度放进分析框中。
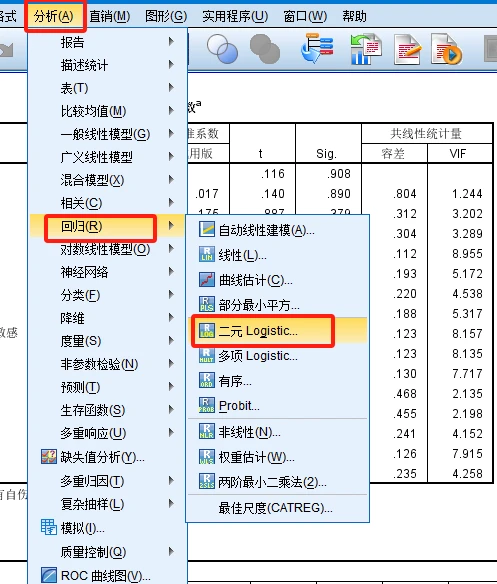
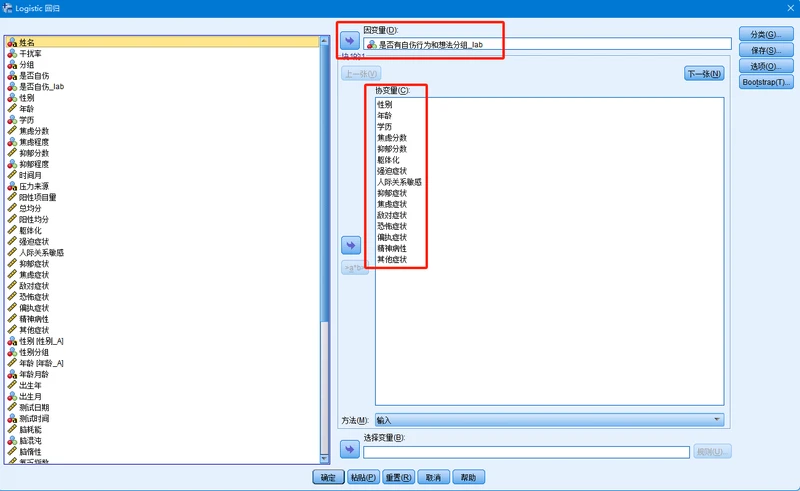
2.2 SPSS二元逻辑回归流程
- 1、分析–>回归–>二元Logistic
- 2、填入因变量–>填入自变量
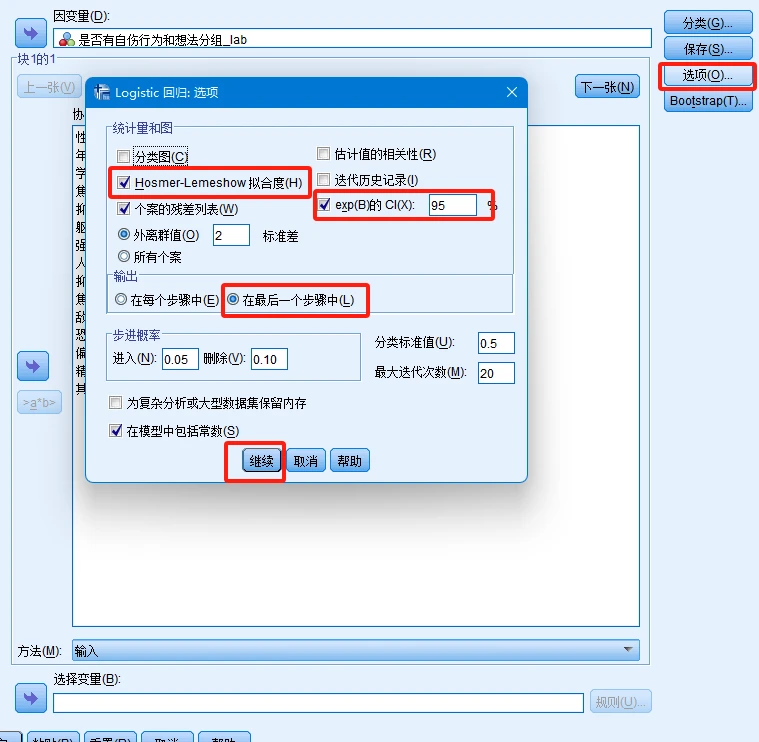
- 3、选项–>勾选【Hosmer-Lemeshow拟合度】–>勾选【exp(B)的CI(X)】–>勾选【在最后一个步骤中】
2.3 模型拟合评价
二元logistic回归分析的模型拟合情况判断可以分为两类,分别是:
- 模型系数的综合检验
- Hosmer-Lemeshow拟合度检验
2.2.1 模型系数的综合检验
- 模型系数的综合检验用于对整体模型的有效性进行检验;
- 模型系数的综合检验通常是指对模型中所有自变量系数的联合显著性进行检验。在二元逻辑回归中,这通常涉及到检验所有自变量系数是否同时等于零。如果检验结果表明这些系数显著不为零,那么我们可以认为模型中的自变量集合对因变量有显著影响。
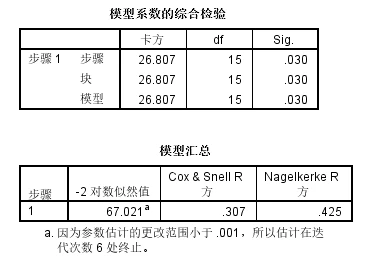
从上图可以看出,模型系数的综合检验的p值小于0.05,说明模型是有效的,反之说明模型无效。
在二元逻辑回归分析中,Cox & Snell R方和Nagelkerke R方都是用来衡量模型拟合优度的指标,它们提供了模型解释变量对响应变量变异性的量化度量。由于逻辑回归模型的输出是概率,而不是线性回归中的直接响应变量,因此不能直接使用传统的R方来衡量模型的拟合优度。Cox& Snell R方和Nagelkerke R方作为伪R方,提供了一种替代的方法。
Cox & Snell R方:
Cox & Snell R方衡量的是模型相对于一个只有截距的模型(即没有自变量的模型)的改进程度。
Cox & Snell R方的值范围在0到1之间,值越大表示模型的拟合越好。但是,它的最大值通常小于1,这意味着它不能完全反映模型的解释能力。
Nagelkerke R方:
- Nagelkerke R方是对Cox & Snell R方的调整,使其最大值可以达到1,从而提供了一个更直观的衡量模型拟合优度的指标。
- Nagelkerke R方的值范围也是0到1,它考虑了模型中自变量的数量,因此在比较包含不同数量自变量的模型时更为公平。
在实际应用中,Cox & Snell R方和Nagelkerke R方通常都会被报告,因为它们提供了从不同角度评估模型拟合优度的方法。然而,需要注意的是,这些伪R方值并不像线性回归中的R方那样直接反映模型解释的方差比例,它们的值通常较小,且在比较不同模型时需要谨慎。此外,这些指标的值不应该被用来跨数据集比较模型的拟合优度,而应该在同一数据集内比较不同模型的拟合程度。在解释这些指标时,应该结合模型的其他方面,如预测准确性、变量的显著性以及模型的实际应用价值。


2.2.2 Hosmer-Lemeshow拟合度检验
Hosmer-Lemeshow拟合度检验是用于评估二元逻辑回归模型拟合优度的一种统计方法。这种检验的目的是检查模型预测的概率与实际观测到的概率之间是否存在显著差异。如果模型预测的概率与实际概率非常接近,那么我们可以认为模型拟合得较好;如果存在显著差异,则表明模型可能没有很好地捕捉到数据中的信息。
Hosmer-Lemeshow检验的步骤如下:
计算预测概率:对于模型中的每个观测值,使用逻辑回归模型计算出因变量发生的概率。
分组:将所有观测值根据预测概率分成若干组(通常为10组),每组包含大约10%的观测值。分组的目的是将预测概率相近的观测值放在一起。
计算观察频率和预期频率:对于每组,计算实际发生因变量的观测频率(即实际发生的事件数除以该组的总观测数)和预期频率(即根据模型预测概率计算的预期事件数)。
计算卡方统计量:使用观察频率和预期频率计算卡方统计量。这个统计量衡量了观察到的事件数与预期事件数之间的差异。
确定P值:将计算出的卡方统计量与相应的卡方分布进行比较,以确定P值。P值表示在模型正确的情况下,观察到当前或更极端的卡方统计量的概率。
做出决策:如果P值大于预先设定的显著性水平(通常为0.05),则没有足够的证据拒绝模型拟合良好的假设,即模型拟合度可接受。如果P值小于显著性水平,则拒绝模型拟合良好的假设,表明模型可能不适合数据。
Hosmer-Lemeshow检验的一个关键点是选择分组的数量。分组数量的选择可能会影响检验的结果,因此在实际应用中需要谨慎选择。此外,这种检验假设模型中的预测变量与因变量之间存在线性关系,如果这种假设不成立,检验结果可能不准确。
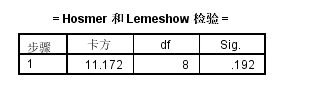
Hosmer-Lemeshow拟合度检验(简写为HL检验)用于判断模型拟合优度。p值大于0.05则说明通过HL检验,反之则说明模型没有通过HL检验,模型拟合优度差。从上表可知:检验对应的 p值大于0.05,说明本次模型通过HL检验,模型拟合优度较好。
2.3 回归分析结果解读
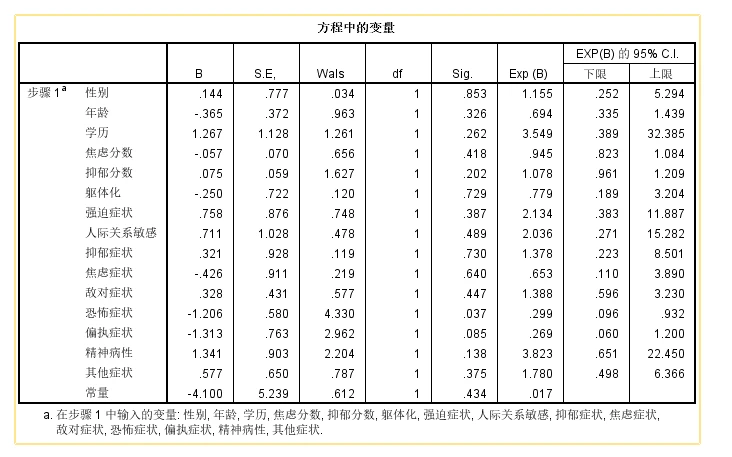
2.3.1 sig.(全称是significance)
- 在统计学中,“sig” 是 "significance"的缩写,它通常用来表示统计显著性。统计显著性是指在进行假设检验时,观察到的数据与原假设(null hypothesis)之间的差异是否足够大,以至于不太可能仅仅是由于随机变异造成的。换句话说,它衡量的是拒绝原假设的证据强度。
- 在实际应用中,研究者会设定一个显著性水平(α),这个水平通常设定为0.05、0.01或其他阈值,取决于研究的具体情况和领域标准。如果计算出的P值(概率值)小于这个显著性水平,那么结果被认为是统计显著的(sig.),这意味着有足够的证据拒绝原假设,认为观察到的效应或差异是真实的。
- 例如,如果一个研究的显著性水平设定为0.05,而计算出的P值为0.03,那么这个结果就是统计显著的(sig.),因为P值小于0.05。这表明观察到的数据不太可能仅仅是由于随机因素产生的,从而支持了备择假设(alternative hypothesis)。
- 在二元逻辑回归结果中,如果sig.小于研究者设定的显著性水平(一般为0.05),那么研究者会拒绝原假设,认为该自变量对因变量(响应变量)有显著的影响。在这种情况下,我们说该自变量在统计上是显著的。
- 只有在自变量P值小于设定的显著性水平值时,此自变量才纳入模型中。
2.3.2 B(回归系数)
-
在二元逻辑回归结果中,“B” 通常指的是回归系数,也就是偏回归系数。在逻辑回归模型中,这些系数表示的是自变量(解释变量)对因变量(通常是二分类的响应变量)的对数几率(log odds)的影响。每个回归系数代表了在其他自变量保持不变的情况下,相应自变量每增加一个单位,对数几率的变化量。
-
偏回归系数是在控制了模型中所有其他自变量的影响后,单个自变量对因变量的影响。在逻辑回归中,由于模型的性质,回归系数和偏回归系数是相同的。这意味着,当我们谈论 “B” 值时,我们实际上是在讨论在给定其他自变量的情况下,每个自变量对因变量对数几率的边际影响。
-
在输出结果中,每个自变量的回归系数(B)旁边通常会有一个标准误差(SE)和P值,用于评估该系数的统计显著性。如果P值小于显著性水平(如0.05),则认为该自变量在统计上显著,即它对因变量有显著的影响。
B(或称为回归系数)的大小和符号代表了自变量(解释变量)对因变量(响应变量)的影响程度和方向。具体来说:
B的大小:
- B的绝对值越大,表示自变量每变化一个单位,因变量发生的概率变化越大。
- 换句话说,自变量对因变量的影响越强。 在逻辑回归中,B的值通常被解释为对数几率(log odds)的变化。
- 例如,如果B的值为0.5,那么自变量每增加一个单位,因变量发生的概率大约会增加到原来的1.65倍(因为
B的符号:
- B的符号表示自变量对因变量影响的方向。
- 如果B为正,表示自变量与因变量呈正相关,即自变量的增加会导致因变量发生的概率增加。
- 如果B为负,表示自变量与因变量呈负相关,即自变量的增加会导致因变量发生的概率减少。
在解释逻辑回归模型的系数时,还需要注意以下几点:
- 解释系数时要考虑模型的整体:单个系数的解释需要在模型的整体背景下进行,因为模型中的其他变量可能会影响特定系数的解释。
- 考虑系数的显著性:通常,我们会计算每个系数的标准误差和对应的P值,以判断该系数是否在统计上显著。如果P值小于显著性水平(如0.05),则认为该系数显著,即自变量对因变量的影响是统计上显著的。
- 考虑模型的其他统计指标:除了单个系数,还需要考虑模型的整体拟合优度(如伪R方)、模型的预测能力以及模型中可能存在的多重共线性等问题。
总之,B的大小和符号在二元逻辑回归中提供了自变量对因变量影响程度和方向的重要信息,但这些信息需要结合模型的其他统计指标和背景来综合解释。
2.3.3 Wald
-
在二元逻辑回归分析中,"Wald"通常指的是Wald统计量,这是一种用于检验模型中单个自变量系数显著性的统计方法。Wald统计量是基于最大似然估计(MLE)的,它衡量的是模型中某个特定参数的估计值与零的差异程度。
-
在二元逻辑回归模型中,Wald统计量用于检验每个自变量的系数是否显著不为零。如果一个自变量的Wald统计量显著(即对应的P值小于预先设定的显著性水平,如0.05),则认为该自变量对因变量有显著影响。换句话说,这个自变量在模型中是重要的,不应该被移除。
-
Wald统计量的计算公式通常如下:
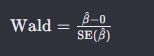
其中:- β^是自变量系数的估计值。
- SE( β^) 是估计值的标准误差。
-
Wald统计量遵循卡方分布,其自由度等于自变量的系数个数。在实际应用中,Wald统计量的结果通常与P值一起报告,P值提供了在零假设(自变量系数为零)下观察到当前统计量或更极端情况的概率。如果P值小于显著性水平,我们拒绝零假设,认为自变量对因变量有显著影响。
-
Wald统计量的大小代表了自变量系数估计值相对于其标准误差的大小。具体来说,Wald统计量是一个比值,它衡量的是估计的系数(β)与零(即没有影响)之间的差异程度,相对于估计系数的标准误差(SE( β^))。
-
Wald统计量的大小可以解释如下:
-
如果Wald统计量较大,意味着估计的系数与零的差异较大,这通常表明自变量对因变量有较强的影响,且这种影响在统计上不太可能是偶然发生的。在这种情况下,对应的P值通常较小,表明自变量在统计上是显著的。
-
如果Wald统计量较小,意味着估计的系数与零的差异不大,这可能表明自变量对因变量的影响较弱或不显著。在这种情况下,对应的P值较大,可能不会拒绝零假设,即认为自变量对因变量没有显著影响。
-
在实际应用中,Wald统计量的大小可以帮助研究者理解每个自变量在模型中的重要性。然而,需要注意的是,Wald统计量的大小并不直接反映影响的大小或方向,它只是用来检验系数是否显著不为零。影响的大小和方向通常通过系数的估计值(β^)和其解释(如比值比(Odds Ratio))来解释。
2.3.4 EXP(B)及EXP(B)的95%C.I.上下限
在二元逻辑回归结果中,EXP(B) 通常指的是回归系数(B)的指数化,也就是比值比(Odds Ratio,简称OR)。这个值用于解释自变量对因变量的影响强度和方向。EXP(B) 的95%置信区间(C.I.)提供了一个范围,用于估计这个比值比的真实值在多大程度上是可信的。
-
EXP(B):
EXP(B) 表示的是自变量每变化一个单位,因变量发生的几率比(odds ratio)的变化。如果 EXP(B) 大于1,表示自变量的增加与因变量发生几率的增加相关;如果 EXP(B) 小于1,表示自变量的增加与因变量发生几率的减少相关;如果 EXP(B) 等于1,表示自变量的变化与因变量发生几率无关。在逻辑回归中,OR值(Odds Ratio)用于衡量自变量与因变量之间关联的强度和方向。OR值的解释依赖于其数值大小(如果因变量代表的是一个不希望发生的结果时):
- 如果OR值大于1,通常表示自变量与因变量之间存在正相关,即自变量的增加与因变量的发生风险增加相关,此时自变量被视为危险因素。
- 如果OR值小于1,表示自变量与因变量之间存在负相关,即自变量的增加与因变量的发生风险减少相关,此时自变量被视为保护因素。
- 如果OR值等于1,表示自变量与因变量之间没有显著的关联。
在二元逻辑回归中,当OR值(Odds Ratio,几率比)大于1时,确实表示自变量与因变量之间存在正向关联。这意味着自变量的增加与因变量发生的几率增加相关。然而,是否将这种正向关联解释为“危险性因素”取决于因变量的性质:
- 如果因变量代表的是一个不希望发生的结果(例如疾病、事故等),那么自变量的正向关联(OR > 1)通常被视为危险性因素,因为它增加了不希望结果发生的风险。
- 相反,如果因变量代表的是一个积极的结果(例如康复、成功等),那么自变量的正向关联(OR >1)可能被视为保护性因素,因为它增加了积极结果发生的可能性。
-
95% C.I. 上下限:
95%置信区间的上下限提供了一个范围,表示我们可以有95%的把握认为真实的比值比落在这个区间内。如果这个区间不包含1,那么我们可以认为自变量对因变量的影响在统计上是显著的。 -
大小和符号的解释:
- EXP(B) 的大小表示自变量对因变量影响的强度。值越大,表示影响越强;值越小,表示影响越弱。
- EXP(B) 的符号表示影响的方向。大于1表示正向影响,小于1表示负向影响。
例如:
- 如果一个自变量的 EXP(B) 为2.5,95% C.I.上下限分别为1.5和4.0,这意味着我们可以有95%的把握认为该自变量每增加一个单位,因变量发生的几率比真实值在1.5到4.0之间。由于这个区间不包含1,我们可以认为这个自变量对因变量有显著的正向影响。
- 当一个自变量的EXP(B)的95%置信区间(C.I.)跨越了1(例如,上下限分别为0.5和4.0),这意味着我们不能确定该自变量对因变量的影响是正向的还是负向的,或者是否有显著影响。
- 由于在这种情况下,置信区间包含了1,表明真实的几率比(Odds Ratio)可能大于1(正向影响),也可能小于1(负向影响),或者恰好等于1(没有影响)。
- 由于95% C.I.的下限为0.5,这表明如果自变量增加一个单位,因变量发生的几率可能会减少(因为0.5小于1)。
- 由于同时,由于上限为4.0,这也表明因变量发生的几率可能会增加。因此,我们不能得出关于自变量影响方向的明确结论,只能说在当前的数据和模型下,自变量对因变量的影响是不确定的。
- 在实际研究中,遇到这种情况时,研究者通常会谨慎地解释结果,指出自变量的影响方向和显著性是不确定的,并可能需要更多的数据或进一步的研究来探索这一关系。同时,研究者也可能会考虑模型的假设、数据的质量和可能的混杂因素,以确保分析的准确性。