
模糊数学也称为弗晰数学或模糊性数学,是应用数学的一个重要分支,最早可追溯于1965年美国控制论专家L.A.Zadel教授发表的一篇名为Fuzzy Sets的论文,在这篇论文中首次引用“隶属度”、“隶属函数”描述差异的中间过渡,处理刻画模糊现象。它主要用于研究现实世界中许多界限模糊的问题,在模式识别、机器学习(如模糊聚类等方法)、深度学习(模糊神经网络等模型)等领域具有广泛应用。模糊数学与概率论(probability theory)、灰色系统理论(grey system theory)并称为研究不确定性系统的三种常用方法。
所以,对于模糊数学,它的内容实际上是十分广泛的,并且与概率论、数理统计一样,其下有诸多的分支。不过概率论发展较早,并且由于其重要应用,在很多非数学本科专业课程中都作为必修课,有成知识体系的教材,有些甚至还会开设试验设计、多元统计等更深入的统计学课程。而对于模糊数学,则与之不同,很多相关书籍阅读时需要较多的数理基础,并且有时更侧重于数学分析。兔兔在本文略去较深的理论,主要讲解模糊数学中最基础的以及与之后实际应用相关的部分,为后面的机器学习、深度学习的相关知识讲解作好铺垫。
一:经典集合
无论是概率论还是模糊数学,其基础都是从集合开始,概率论建立在经典集合之上,而模糊数学则以模糊集合为基础,我们在这里先回顾以经典集合的基础知识。
经典集合的运算:
1. 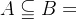 :表示集合A属于集合B,即A中所有元素在B中都能找到。反之为
:表示集合A属于集合B,即A中所有元素在B中都能找到。反之为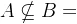 ,表示A不属于B,B不包含A。
,表示A不属于B,B不包含A。
2.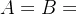 :表示A集合与B集合相等。
:表示A集合与B集合相等。
3.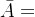 :表示集合A的余集或补集。即全集U中去掉所有A集合中的元素,剩下的元素所组成的集合,有时也表示成
:表示集合A的余集或补集。即全集U中去掉所有A集合中的元素,剩下的元素所组成的集合,有时也表示成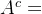 。
。
4.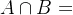 :表示集合A与集合B交集,即两个集合公共元素组成的集合。
:表示集合A与集合B交集,即两个集合公共元素组成的集合。
5.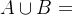 :表示集合A与集合B并集,即两个集合所有元素所组成的集合。
:表示集合A与集合B并集,即两个集合所有元素所组成的集合。
6.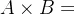 :表示集合A与集合B的直积,
:表示集合A与集合B的直积,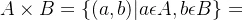 ,即A中所有元素与B中所有元素组合成各个二元数组组成的集合。
,即A中所有元素与B中所有元素组合成各个二元数组组成的集合。
运算性质:
1.交换律: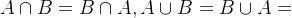 。
。
2.结合律: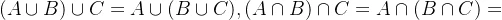 。
。
3.分配律: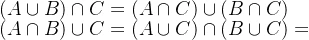
4.对偶律: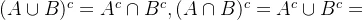 。
。
5.还原律: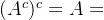 。
。
6.0-1律: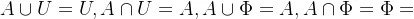 ,其中U表示全集,Φ表示空集。
,其中U表示全集,Φ表示空集。
7.排中律: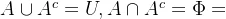
特征函数:
对于经典集合A,其特征函数表示为:
即对于一个元素x,如果属于集合A,特征函数值为1,否则为0。
特征函数的运算性质:
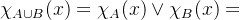
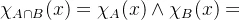
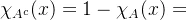
其中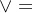 是取大运算,
是取大运算,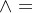 是取小运算,如
是取小运算,如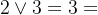 ,
,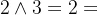 。
。
二元关系:
二元关系简称为关系,是集合A与集合B的直积的子集,也称为从X到Y的二元关系,例如A={1,2,3},B={2,3,4},则直积为{(1,2),(1,3),(1,4),(2,2),(2,3),(2,4),(3,2),(3,3),(3,3)},如果施加条件限制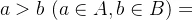 ,则在此限制条件下关系表示为:
,则在此限制条件下关系表示为:
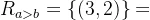
如果限制条件是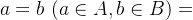 ,则关系可以表示为:
,则关系可以表示为:
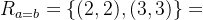
像这样对A×B施加一定条件限制后得到的新集合R称为二元关系。如果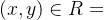 ,则称元素x与元素y有关系,否则无关系。
,则称元素x与元素y有关系,否则无关系。
关系R除了上面的表示方法,更多情况下用矩阵的形式表示:
其中:
ui,uj分别表示A集合第i个元素与B集合第j个元素,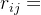 表示关系矩阵R的第i行j列。这样用矩阵表示的方法实际上也是关系的特征函数。
表示关系矩阵R的第i行j列。这样用矩阵表示的方法实际上也是关系的特征函数。
这样,前面的关系就可以用矩阵表示为:
如果集合A=B,则称之为A上的二元关系。
二元关系的合成:
设R1为A到B的关系,R2为B到C的关系,则R1与R2的合成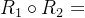 是A到C上的一个关系。
是A到C上的一个关系。
设X={x1,x2,...,xm},Y={y1,y2,...,ys},Z={z1,z2,...,zn},且X到Y的关系: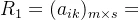 ,Y到Z的关系
,Y到Z的关系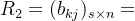 ,则X到Z的关系可表示为矩阵的合成:
,则X到Z的关系可表示为矩阵的合成:
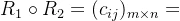
其中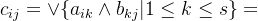
这个计算过程与矩阵相乘十分相似,矩阵相乘是前一矩阵i行分别乘后一矩阵j列元素并求和,结果在新矩阵的i行j列;这里关系矩阵的合成是前一矩阵i行与后一矩阵j列元素分别比较取较小那一个,然后在这些数中再取最大的那一个,结果放在新矩阵的i行j列。
若R为n阶方阵,定义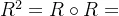 ,
,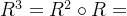 ,......
,......
举例:
设X={1,2,3,4},Y={2,3,4},Z={1,2,3},R1是X到Y上的关系,R2是Y到Z上的关系。
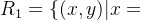
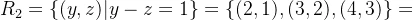
则R1与R2的合成:
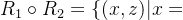
如果运用矩阵计算,会发现矩阵结果与上述事实一致。
二元关系合成运算性质:
1.结合律: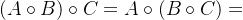
2.
3.分配律: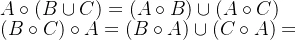
4.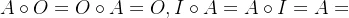
其中A、B、C都是关系矩阵,O为零矩阵,I为单位阵,矩阵交集表示两个矩阵对应位置元素取较小的那个并形成新的矩阵,并集表示两个矩阵相应位置元素取较大的元素并组成新的矩阵。
注:合成运算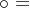 关于∩的分配律是不成立的。
关于∩的分配律是不成立的。
二:模糊集合
与经典集合不同,在模糊集合中,对于一个元素,我们无法绝对地认为该元素是属于该集合还是不属于该集合,而是说该元素多大程度上属于该集合,即模糊集合没有明确边界。在这里,兔兔先引入一个概念:论域。
论域:被讨论的对象(元素)的全体称为论域。与集合一样,通常用大小字母U,V等表示,从某种方面来说,论域与经典集合中全集是相对应的,只不过经典集合中,全集中的元素绝对的属于或不属于经典集合A,A是全集的子集;而模糊集合中,论域中所有元素是不同程度地属于模糊集A,无法绝对刻画,A是论域的模糊子集。
模糊集表示:
我们发现,模糊集无法像经典集合一样,用数学表达式或元素集合来表示,论域中所有对象都是不同程度地属于模糊集U,所以我们需要引入表示属于模糊集程度的方法,进而用这种表示方法表示模糊集。这种属于模糊集程度即为隶属度(元素属于模糊集合的程度,为[0,1],值越大,越属于该模糊集),计算元素在模糊集M的隶属度的函数称为隶属函数,此时可以用M表示隶属函数,则元素x在模糊集M的隶属度为M(x),使M(x)=0.5的点x称为过渡点,此点最具模糊性。
如果隶属函数只取0,1二值,此时模糊集就变成经典集合,隶属函数也就是经典集合的特征函数。
隶属函数通常采用模糊统计方法、例证法和指派法。其中指派法是根据人们实践经验确定某些模糊集合隶属函数的方法,如果模糊集定义在实数域,则隶属函数也称为模糊分布,常见的模糊分布详见附录。
当论域U为有限集,记论域U={u1,u2...un},U上的模糊集记作F或F(U),则该模糊集有下列三种常见表示方法,其中扎德表示法更为常见。
1.序偶表示法:
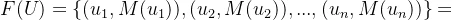
2.向量表示:
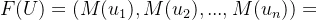
3.扎德表示法:
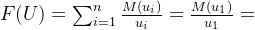
其中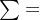 ,+不是求和,分数也不是两数相除,只是一种表示方法。
,+不是求和,分数也不是两数相除,只是一种表示方法。
当论域U为无限集,U上的模糊集M可表示为:
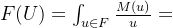
其中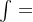 不是积分,+不是求和,分数也不是相除,只是一种表示方法。
不是积分,+不是求和,分数也不是相除,只是一种表示方法。
举例:
设论域U={140,150,160,170,180,190}表示人的身高(cm),那么U上的一个模糊集“高个子”A的隶属函数可以定义为:A(x)=(x-140)/(190-140),模糊集的扎德表示法为:
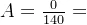
如果论域U是[140,190]无限集,则模糊集可以表示为:
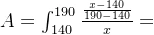
模糊集合运算
1.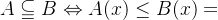 ,即:若A模糊集合包含于B集合,论域中任意元素的A隶属度小于等于B的隶属度。
,即:若A模糊集合包含于B集合,论域中任意元素的A隶属度小于等于B的隶属度。
2.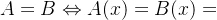 。
。
3.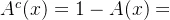 。
。
4.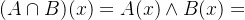 。模糊集A与模糊集B交集为两个隶属函数的较小值部分。
。模糊集A与模糊集B交集为两个隶属函数的较小值部分。
5.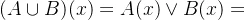 。模糊集A与模糊集B并集为两个隶属函数的较大值部分。
。模糊集A与模糊集B并集为两个隶属函数的较大值部分。
这里模糊集的运算是与经典集合运算相一致,只不过那里可以特征函数计算,这里需要用隶属函数计算。
运算性质:
模糊集合的运算性质与经典集合运算性质基本完全相同,只有排中律是模糊集所不具备的,即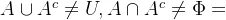 ,说明模糊集不具有“非此即彼”的特征,这也正是模糊性带来的本质特征。
,说明模糊集不具有“非此即彼”的特征,这也正是模糊性带来的本质特征。
λ-截集:
λ-截集是经典集合,它是由模糊集合A中隶属度不小于λ的元素组成的集合。表示为:
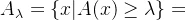
举例:
以前面“高个子”模糊集A为例,若λ=0.4,则该模糊集的0.4-截集为: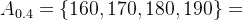 。
。
模糊关系
模糊关系与经典集合的二元关系相对应,模糊感谢是对普通集合的直积施加某种模糊条件限制后得到的模糊关系,也记作R,模糊关系可以用扎德表示法、隶属函数或矩阵形式来表示。
例如,对于两个不同论域的普通集合A=(1,2,3),B=(1,2,3,4,5),对A×B施加“远小于”的模糊条件(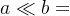 )后得到的一个模糊关系为:
)后得到的一个模糊关系为:
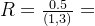
模糊矩阵表示为:
与经典二元关系有所不同,它不是元素绝对地判断元素是否属于该条件,也不像经典关系矩阵那样只有0,1二值,模糊关系是认为元素以一定程度属于该条件,所以模糊关系矩阵也不再是0,1二值,而是从0~1之间的数值。这里的模糊关系中隶属函数是人为选的一种较为符合常识的一种函数,也可以选其它的标准。
模糊关系的合成:
模糊关系运算与经典集合关系运算是完全一致的,运算符号仍是,模糊关系矩阵运算与经典关系矩阵运算过程一致。
模糊关系合成的运算性质:
模糊关系合成运算的性质与经典的二元关系合成运算是一致的。
模糊关系矩阵的λ-截矩阵:
设模糊关系矩阵为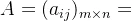 ,称
,称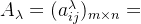 为模糊矩阵A的λ-截矩阵,其中:
为模糊矩阵A的λ-截矩阵,其中:
这样得到的截矩阵就是布尔矩阵了。
举例:
设某一模糊矩阵A为:
若λ=0.5,则A的0.5-截矩阵为:
三:模糊概率
传统的概率论是建立在经典集合之上,而模糊事件的概率是以模糊集为基础。设模糊事件A是模糊集,定义其概率:
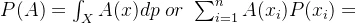
式子左边表示连续的情况,右边是不连续的情况。
举例:
某人射击命中率为0.7,现向目标射击,记A为"只射了不几次就射中",设论域X={1,2,...}表示击中目标所需次数,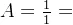 ,则P(A)为:
,则P(A)为:
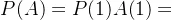
模糊概率理论是模糊数学中一个主要分支,兔兔在这里仅引出最为基本的概念,感兴趣的同学可以进行进一步研究。
四:总结
在本篇文章中,兔兔以经典集合为基础,着重讲述模糊集合、模糊关系等内容,至于扩张原理、模糊数、凸模糊集等内容,它们更偏于理论分析;模糊等价关系、模糊矩阵交、并、余运算及其运算性质以及关系的三大特性(自反、对称、传递性)等知识点在后面应用较少,且内容较为简单。所以这些内容在本文兔兔并没有论述。当然,本文内容毕竟是基础知识,对于其中更多的内容,在后面的模糊聚类、模糊模式识别等相关文章中,兔兔会对其中出现的新的模糊数学知识点作详细阐述。
附录:
(1)模糊关系矩阵(或普通关系矩阵)合成运算。
import numpy as np
def multiply(R1,R2):
'''关系矩阵R1,R2合成'''
m,s1=R1.shape
s2,n=R2.shape
if s1 !=s2:
raise ValueError('s1 is unequal to s2')
s=s1
R=[]
for i in range(m):
a=[]
for j in range(n):
b=[]
for k in range(s):
b.append(min(R1[i][k],R2[k][j]))
a.append(max(b))
R.append(a)
return np.array(R)
R1=np.array([[0.1,0.2,0.5],
[0.6,0.4,0.7]])
R2=np.array([[0.8,0.9],
[0.1,0.7],
[0.2,0.8]])
print(multiply(R1,R2))(2)模糊集A的λ-截集计算。
def lambda_cut_sets(sets,l):
'''计算模糊集sets的λ截集
sets:模糊集
l:λ,取值为[0,1]'''
if l>1 or l<0:
raise ValueError('λ value should in [0,1]')
new_sets=set()
for s in sets:
if s[1]>=l:
new_sets.add(s[0])
else:
continue
return new_sets
sets={(140,0),(150,0.2),(160,0.4),(170,0.6),(180,0.8),(190,1)} #sets为模糊集,括号中前一个表示论域中元素,后一个表示隶属度
print(lambda_cut_sets(sets=sets,l=0.5))(3)模糊关系矩阵λ-截矩阵计算。
import numpy as np
def cut_matrix(R,l):
'''计算模糊关系矩阵R的λ截矩阵
R:模糊矩阵
l:λ,取值为[0,1]'''
m,n=R.shape
for i in range(m):
for j in range(n):
if R[i][j]>=l:
R[i][j]=1
else:
R[i][j]=0
return R
R=np.array([[0.1,0.6],
[0.9,0.4]])
print(cut_matrix(R=R,l=0.5))(4)常见的模糊分布。
| 类型 | 偏小型 | 中间型 | 偏大型 |
| 矩阵型 | |||
| 梯形型 | |||
| k次抛物型 | |||
| Γ型 | |||
| 正态型 | ![M(x)=exp[-(\frac{x-a}{\sigma})^2]](https://yyzqsoft.com/uploads/202407/04/c8e0043d220a108f.webp) | ||
| 柯西型 | (α>0,β为正偶数) |