
说明:
项目主要随机抓取易烊千玺100万+转发的微博置顶的100万条转发数据,并利用数据可视化的方式分析易烊千玺真假粉丝比例。
分为:爬虫+数据分析
一、爬虫【爬取易烊千玺100万条的转发数据】
#爬取微博的移动端 #爬取链接:https://m.weibo.cn/api/statuses/repostTimeline?id=4305133380410769&page=1 【易烊千玺最新一条微博】 - `4378444341049276`是每条微博对应的id,只要通过抓包得到这个id,便可以爬取你想要爬取的任何微博的转发数据 - `page的最大参数`随转发量不同而变化,需要自行测试
1.1简单的单页爬取
import requests
import json
def get_page(url):
headers={'user-agent':'Mozilla/5.0'}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parse_page(url):
info=[]
html=get_page(url)
res=json.loads(html)
if res['ok']==1:
data=res['data']['data']
for rep_data in data: #只是删除不需要的信息
del rep_data['retweeted_status']
del rep_data['number_display_strategy']
del rep_data['text']
del rep_data['visible']
info.append(rep_data)
return info
if __name__ == '__main__':
url='https://m.weibo.cn/api/statuses/repostTimeline?id=4305133380410769&page=1'
info=parse_page(url)
print(info)
print(len(info))1.2Scrapy框架爬取易烊千玺微博的转发信息
【保存到MongoDB数据库中】
(1)在cmd中的基础操作:
C:\Users\Administrator\Desktop>scrapy startproject YYQX C:\Users\Administrator\Desktop>cd YYQX C:\Users\Administrator\Desktop\YYQX>scrapy genspider yyqx m.weibo.cn
#项目构架
``` ├── YYQX │ ├── __init__.py # 初始文件 │ ├── items.py # 项目项定义文件 │ ├── middlewares.py # 项目中间件文件 │ ├── pipelines.py # 项目管道文件 │ ├── settings.py # 项目设置文件 │ └── spiders # 爬虫 │ ├── __init__.py # 爬虫初始文件 │ └── yyqx.py # 爬虫文件 └── scrapy.cfg # 部署配置文件 ```
说明:因为微博转发数据是json格式,本身就是键值对类型,所以不需要自己设置items.py进行键值对的格式配置。
(2)在yyqx.py中设置爬虫代码
import scrapy
import random
import json
class YyqxSpider(scrapy.Spider):
name = 'yyqx'
allowed_domains = ['m.weibo.cn']
#start_urls = ['http://m.weibo.cn/'] #需要自己设置爬取的初始url
def start_requests(self): #以start_requests代替start_urls启动爬虫
urls=['https://m.weibo.cn/api/statuses/repostTimeline?id=4305133380410769&page={}'.format(i) for i in range(1,50000)] #设置爬取50000页
random.shuffle(urls) # 这个api的数据是实时更新的,所以不需要按照顺序爬,shuffle一下可以增加爬虫效率
for url in urls:
yield scrapy.Request(url=url,callback=self.parse,dont_filter=True)
def parse(self, response): #解析函数
res=json.loads(response.text)
if res['ok']==1:
data=res['data']['data']
for rep_data in data:
del rep_data['number_display_strategy']
del rep_data['retweeted_status']
del rep_data['text']
del rep_data['visible']
item=rep_data
yield item微博反爬的应对措施
直接大批量抓取,很快会被微博反爬,很多page抓取不到数据,应对措施有:
- - 在middlewares.py里面增加IP代理
- - 在settings.py里面设置爬取间隔时间
- - 由于IP限制,且本人没有配置代理IP,而是在middlewares.py里增加了一个重试类`TooManyRequestsRetryMiddleware`,只要返回418状态码,整个爬虫暂停1分钟,并在setting.py里面设置了重试次数 当然如果你的代理IP质量好的话,可以直接上代理
(3)编辑settings.py配置文件
- 需要打开pipelines.py 编写代码将数据保存到MongoDB数据库中
- 需要打开middlewares.py 编写代码增加IP代理,防止反爬
import os
BOT_NAME = 'YYQX'
SPIDER_MODULES = ['YYQX.spiders']
NEWSPIDER_MODULE = 'YYQX.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 32
DEFAULT_REQUEST_HEADERS = {
'Accept': 'application/json, text/plain, */*',
'MWeibo-Pwa': '1',
'Referer': 'https://m.weibo.cn/status/Hk1YczUdT',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/72.0.3626.119 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
DOWNLOADER_MIDDLEWARES = {'YYQX.middlewares.TooManyRequestsRetryMiddleware': 543,}
RETRY_HTTP_CODES = [418]
RETRY_TIMES = 2
ITEM_PIPELINES = {'YYQX.pipelines.YyqxPipeline': 300,}
MONGODB_HOST = os.environ.get('MONGODB_HOST', '127.0.0.1') #本地数据库
MONGODB_PORT = os.environ.get('MONGODB_PORT', '27017') #数据库端口
MONGODB_URI = 'mongodb://{}:{}'.format(MONGODB_HOST, MONGODB_PORT)
MONGODB_DATABASE = os.environ.get('MONGODB_DATABASE', 'YYQX') #数据库名字(4)编辑middlewares.py文件
当爬虫返回418错误时,爬虫休息60秒,稍后继续爬虫。
from scrapy.downloadermiddlewares.retry import RetryMiddleware
import time
class TooManyRequestsRetryMiddleware(RetryMiddleware):
def __init__(self,crawler):
super(TooManyRequestsRetryMiddleware,self).__init__(crawler.settings)
self.crawler=crawler
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_response(self, request, response, spider):
if response.status==418:
self.crawler.engine.pause()
time.sleep(60)
self.crawler.engine.unpause()
return request
return response(5)编辑pipelines.py文件
将数据保存到MongoDB数据库YYQX中的表repost中,并进行去重。
from pymongo import MongoClient
from scrapy.conf import settings
from pymongo.errors import DuplicateKeyError
class YyqxPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri=mongo_uri
self.mongo_db=mongo_db
self.client=None
self.db=None
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGODB_URI'),
mongo_db=settings.get('MONGODB_DATABASE','items')
)
def open_spider(self,spider):
self.client=MongoClient(self.mongo_uri)
self.db=self.client[self.mongo_db]
self.db['repost'].ensure_index('mid',unique=True) #YYQX数据库中的repost集合,存放数据
def close_spider(self,spider):
self.client.close()
def process_item(self, item, spider):
try:
# 通过mid判断,有就更新,没有就插入
self.db['repost'].update({'mid':item['mid']},{'$set':item},upsert=True)
except DuplicateKeyError:
spider.logger.debug('唯一键冲突报错')
except Exception as e:
spider.logger.debug(e)
return item(6)运行
要把数据保存到mongodb,要开2个cmd
- 第一个mongod用来启动服务器 :C:\Users\Administrator>mongod --dbpath D:\data\db --port 27017
- 第二个mongo用来启动客户端:C:\Users\Administrator>mongo
然后就可以在MongoDB Compass Community中查看数据
运行代码:
C:\Users\Administrator\Desktop\YYQX>scrapy crawl yyqx爬虫完成!且数据存储到MongoDB数据库YYQX中的repost存在数据。
二、数据分析【分析易烊千玺100万条的转发数据---比较真假粉丝】
采用:
- Jupyter notebook代码,对转发数据进行分析
- stopwords.txt: 停用词表
导入需要使用的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pymongo import MongoClient
from pandas.io.json import json_normalize
plt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure',figsize=(10,10)) #把plt默认的图片size调大一点
plt.rcParams['figure.dpi']=mpl.rcParams['axes.unicode_minus']=False #解决保存图片是负号-'显示为方块的问题
%matplotlib inline(1)首先从MongoDB数据库YYQX中的reposet表取出数据
conn=MongoClient(host='127.0.0.1',port=27017) #实例化MongoClient
db=conn.get_database('YYQX') #连接到YYQX数据库
repost=db.get_collection('repost') #连接到集合reposet
mon_data=repost.find() #查询该集合下的所有记录
data=json_normalize([comment for comment in mon_data]) #json数据格式化(2)检查数据
data.sample(3)
data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3132 entries, 0 to 3131 Columns: 107 entries, _id to version dtypes: bool(10), float64(53), int64(20), object(24) memory usage: 2.1+ MB
(3)数据清洗
由于数据入库的时候没有进行清洗,所以数据多出了很多没用的字段,需要先清洗掉
data.columns
Index(['_id', 'attitudes_count', 'bid', 'can_edit', 'cardid', 'comments_count',
'content_auth', 'created_at', 'darwin_tags', 'edit_at',
...
'user.profile_image_url', 'user.profile_url', 'user.screen_name',
'user.statuses_count', 'user.urank', 'user.verified',
'user.verified_reason', 'user.verified_type', 'user.verified_type_ext',
'version'],
dtype='object', length=107)选取需要的字段:
in_columns = ['attitudes_count', 'comments_count', 'reposts_count', 'mid', 'raw_text',
'source', 'user.description', 'user.follow_count', 'user.followers_count',
'user.gender', 'user.id', 'user.mbrank', 'user.mbtype', 'user.profile_url',
'user.profile_image_url', 'user.screen_name', 'user.statuses_count',
'user.urank', 'user.verified', 'user.verified_reason']
data = data[in_columns]
data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 3132 entries, 0 to 3131 Columns: 20 entries, _id to version dtypes: bool(1), int64(10), object(9) memory usage: 468.0+ KB
此时数据量明显缩小,由2.1MB变为468KB
(4)问题
- 易烊千玺的微博转发是否存在假流量?
- 真假流量所占的比例各有多少?
- 假流量粉丝是如何生产出来的?
- 真流量粉的粉丝画像
(4-1)易烊千玺的微博转发是否存在假流量?
#易烊千玺粉丝的性别比例
fans_num=data['user.gender'].value_counts() fans_num
m 1880 f 1252 Name: user.gender, dtype: int64
#利用Bar显示性别比例
from pyecharts import Bar
bar=Bar('易烊千玺粉丝性别比例',width=600,height=500)
bar.add('总数据{}条'.format(data.shape[0]),['男','女'],fans_num.values,
is_stack=True,xaxis_label_textsize=20,yaxis_label_textsize=14,is_label_show=True)
bar.render('结果.html')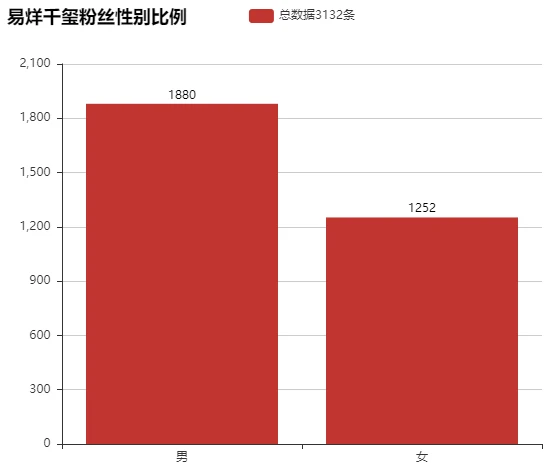
np.round(fans_num/fans_num.sum()*100,2) #男女比例
m 60.03 f 39.97 Name: user.gender, dtype: float64
data[data['user.gender']=='m'].sample(3) #随机显示3组性别为m的用户的信息
(4-2) 真假流量所占的比例各有多少?
#认为:粉丝数<=5且描述为空,评论为0,点赞为0.转发为0,mbran为0 这些用户为假流量
data_fake=data[
((data['user.follow_count']<=5)|(data['user.followers_count']<=5))&
(data['user.description']=='')&(data['comments_count']==0)&
(data['attitudes_count']==0)&(data['reposts_count']==0)&
(data['user.mbrank']==0)]# 昵称里包含“用户”的,基本上可以断定是假粉丝
data_fake2_index=data[ (data['user.follow_count']>5)&(data['user.followers_count']>5)&
(data['user.screen_name'].str.contains('用户'))].index#将假粉丝组合起来
data_fake=pd.concat([data_fake,data.iloc[data_fake2_index]])#取出真粉丝的转发
data_true=data.drop(data_fake.index)print('真粉丝转发数量的比例:{}%'.format(np.round(data_true.shape[0]/data.shape[0]*100,2)))
print('假粉丝转发数量的比例:{}%'.format(np.round(data_fake.shape[0]/data.shape[0]*100,2)))
真粉丝转发数量的比例:43.65%
假粉丝转发数量的比例:56.35%利用Bar显示:易烊千玺真假流量的转发量
bar = Bar("易烊千玺真假流量的转发量", width = 600,height=500)
bar.add("(总数据{}条)".format(data.shape[0]), ['总转发量', '假粉丝转发量', '真粉丝转发量'],
[data.shape[0], data_fake.shape[0], data_true.shape[0]], is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar.render('结果.html')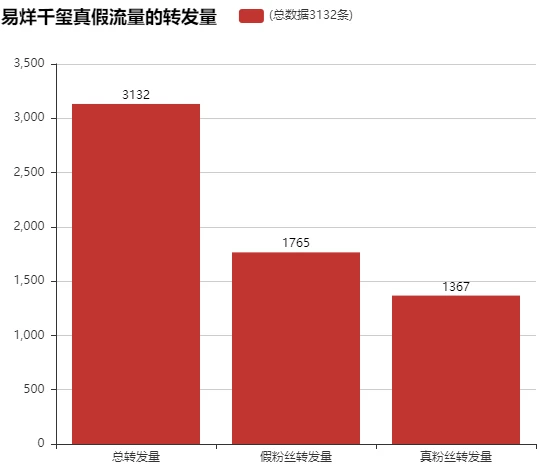
利用Bar显示:易烊千玺真假流量的转发量与真实转发粉丝量
real_fans_num = data_true.drop_duplicates(subset='user.id').shape[0] #真实转发的真粉丝!
bar = Bar("易烊千玺真假流量的转发量与真实转发粉丝量(总数据{}条)".format(data.shape[0]), width = 600,height=500)
bar.add('', ['总转发量', '假粉丝转发量', '真粉丝转发量', '真实转发粉丝量'],
[data.shape[0], data_fake.shape[0], data_true.shape[0], real_fans_num], is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=20)
bar.render('结果.html')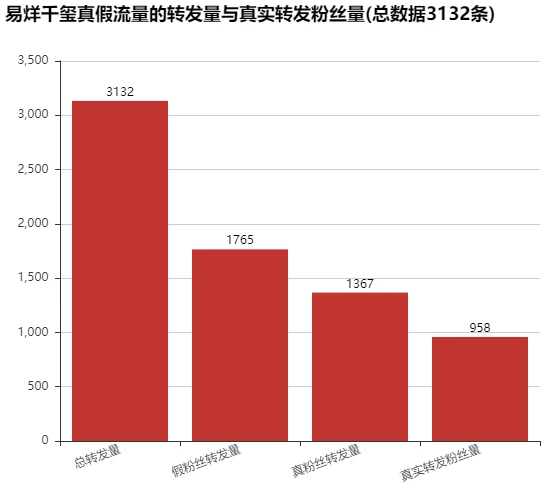
print('真实转发粉丝量占总转发数的{}%'.format(np.round(real_fans_num/data.shape[0]*100, 2)))
真实转发粉丝量占总转发数的30.59%(4-3)假流量粉丝是如何生产出来的? 【对data_fake进行讨论】
#假粉丝性别比例
data_fake_gender=data_fake.drop_duplicates(subset='user.id')['user.gender'].value_counts()
data_fake_genderm 1517 f 60 Name: user.gender, dtype: int64
利用Bar实现假粉丝性别比例:
bar=Bar('易烊千玺假粉丝性别比例',width=600,height=500)
bar.add('假粉丝总数{}'.format(data_fake.shape[0]),['男','女'],data_fake_gender.values,
is_stack=True,xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar.render('结果.html')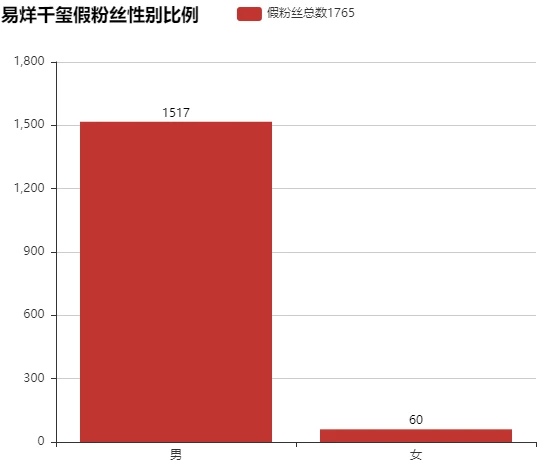
#假粉丝使用的前10设备 fake_source=data_fake['source'].value_counts()[:10] fake_source
Android 1393 Weico.Android 34 iPhone客户端 33 iPad客户端 26 vivo X20全面屏手机 19 三星Galaxy NOTE III 19 三星android智能手机 19 iPhone 6 Plus 15 Flyme 15 红米Redmi 14 Name: source, dtype: int64
利用Bar实现假粉丝使用设备比例:
bar = Bar("易烊千玺假粉丝Top10转发设备", width =2000,height=600)
bar.add("", fake_source.index, fake_source.values, is_stack=True,
xaxis_label_textsize=11, yaxis_label_textsize=14, is_label_show=True)
bar.render('结果.html')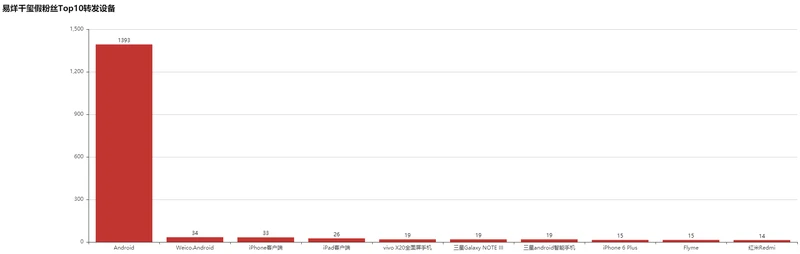
#假粉丝的一些信息分析 data_fake['user.follow_count'].mean() #假粉丝的平均关注数 #0.9852691218130312 data_fake['user.followers_count'].mean() #假分数的平均粉丝数 #1.1484419263456092 data_fake_sample = data_fake.sample(5) #拿出5个假粉丝 data_fake_sample['user.screen_name'] #5个假粉丝的用户名 """ 1279 用户6966658662 1192 用户6936908547 1832 用户6846024257 2353 用户2167181937 2573 用户6979430652 Name: user.screen_name, dtype: object """ data_fake_sample['user.profile_image_url'].values #5个假粉丝的头像,都是没有头像 """ array(['https://tvax1.sinaimg.cn/default/images/default_avatar_male_180.gif', 'https://tvax2.sinaimg.cn/default/images/default_avatar_female_180.gif', 'https://tvax1.sinaimg.cn/default/images/default_avatar_male_180.gif', 'https://tvax3.sinaimg.cn/default/images/default_avatar_male_180.gif', 'https://tvax3.sinaimg.cn/default/images/default_avatar_male_180.gif'], dtype=object) """ data_fake['user.screen_name'].str.contains('易|烊|千|玺|y|q|x').sum() #假粉丝名字中的一些特点 #35 data_fake.shape[0] #假粉丝一共有1765个 #1765 data_fake['user.statuses_count'].mean() #假粉丝中平均在线状态 #307.70481586402263
(4-4) 真流量粉的粉丝画像
#真粉丝性别比例
data_true_gender = data_true.drop_duplicates(subset='user.id')['user.gender'].value_counts()
data_true_gender #发现真粉丝中女生比较多f 827 m 131 Name: user.gender, dtype: int64
利用Bar实现真粉丝性别比例:
bar = Bar("易烊千玺真粉丝性别比例", width = 600,height=500)
bar.add("(真粉丝总数为{})".format(data_true.shape[0]), ['女', '男'], data_true_gender.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar.render('结果.html')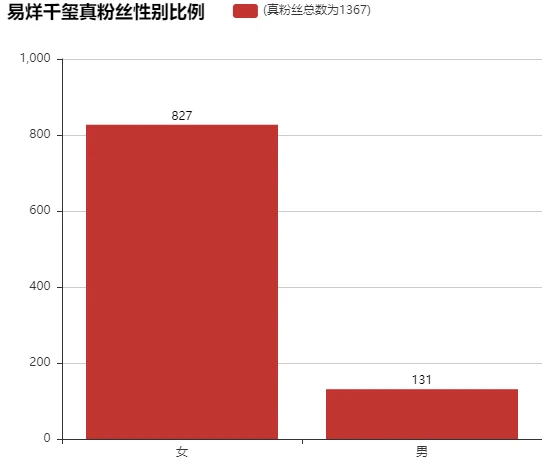
利用Bar实现真粉丝使用设备比例:
true_source = data_true['source'].value_counts()[:10] #真粉丝使用的设备
bar = Bar("易烊千玺真粉丝Top10转发设备", width = 2000,height=600)
bar.add("", true_source.index, true_source.values, is_stack=True,
xaxis_label_textsize=11, yaxis_label_textsize=14, is_label_show=True)
bar.render('结果.html')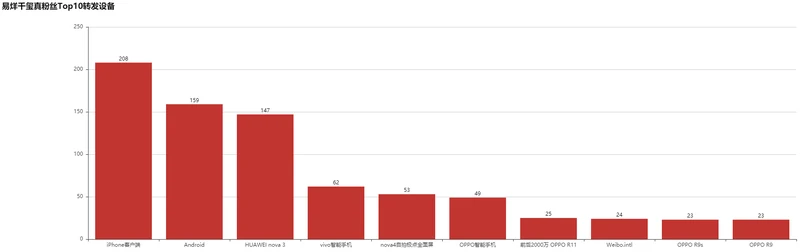
#真粉丝中的一些信息 data_true['user.follow_count'].mean() #真粉丝平均关注的人 #268.84198975859545 data_true['user.followers_count'].mean() #真粉丝的平均分数个数#1030.6942209217264 #1030.6942209217264 data_true.sample(5)['user.screen_name'] #真粉丝的名字 """ 3046 烊烊是我的小朋友 449 小花伞挽你 2268 宝贝儿今晚不眠夜 3047 我的大明星我的小朋友 426 一抹夏忧43084 Name: user.screen_name, dtype: object """ data_true.sample(5)['user.profile_image_url'].values #5个真粉丝的头像,都是有头像 """ array(['https://tvax4.sinaimg.cn/crop.0.0.996.996.180/006qg9yQly8g2n9vxftdvj30ro0rodgn.jpg', 'https://tvax3.sinaimg.cn/crop.0.0.996.996.180/88ca6fe4ly8g39aczbhfej20ro0ro40q.jpg', 'https://tvax1.sinaimg.cn/crop.0.0.736.736.180/007LKHcily8g2qs3hgmthj30kg0kgwfj.jpg', 'https://tvax1.sinaimg.cn/crop.0.0.512.512.180/006VZeF6ly8g31z57ubnnj30e80e8t98.jpg', 'https://tvax3.sinaimg.cn/crop.0.0.512.512.180/d4720c90ly8fuklmez1qbj20e80e8aag.jpg'], dtype=object) """ data_true['user.screen_name'].str.contains('易|烊|千|玺|y|q|x').sum() #真粉丝名字中的一些特点 #478 data_true.shape[0] #真粉丝一共有1367个 #1367 data_true['user.statuses_count'].mean() #真粉丝中平均在线状态 #8873.376005852231
#绘制易烊千玺真粉丝的简介词云图
import jieba
from collections import Counter
from pyecharts import WordCloud
jieba.add_word('易烊千玺')
swords = [x.strip() for x in open ('stopwords.txt',encoding='utf-8')]
def plot_word_cloud(data, swords, columns,filename):
text = ''.join(data[columns])
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
wordcloud.render('{}.html'.format(filename))
return wordcloud
plot_word_cloud(data=data_true, swords=swords, columns='raw_text',filename='转发文本词云展示')
【分析结束!!!!!!】