
无论是前端、后端或者运维同学,在平时的开发工作中,都会和HTTP缓存打交道,大家或多或少都了解HTTP缓存中的ETag字段,它是资源的特定版本的标识符,可以让缓存更高效,并节省带宽。本文系统性的阐述了ETag的起源、生成原理及使用。看完本文后,对于不了解ETag的同学能够知道ETag的来龙去脉,并能马上上手使用;对于熟悉ETag的同学也能做到温故而知新。
ETag定义及起源
ETag(Entity-Tag,下文简称:ETag)是万维网协议HTTP的一部分,它是 HTTP 为Web 缓存验证提供的多种机制之一,它允许客户端发出条件请求。这种机制允许缓存更有效并节省带宽,因为如果内容没有更改,Web 服务器不再需要发送完整的响应。
ETag 是由 Web 服务器分配给在URL中找到的特定版本资源的不透明标识符。如果该 URL 的资源表示发生了变化,则会重新分配一个新的 ETag。ETag 类似于指纹,可以快速进行比较以确定资源的两种表示是否相同。
ETag的正式提出是在 HTTP/1.1 协议的 rfc7232 文档中,引入 ETag 的目的主要是为了解决 Last-Modified 存在的一些问题:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新发起GET请求
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),
If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒) - 某些服务器不能精确的得到文件的最后修改时间
HTTP/1.1协议虽然提出了 ETag,但并没有规定ETag的内容是什么或者说要怎么实现,唯一规定的是ETag的内容必须放在""内。
强校验和弱校验
ETag的格式为:ETag= [ weak ] opaque-tag,其中[ weak ]表示可选。ETag支持强校验和弱校验,它们的区别在于 ETag 标识符中是否存在一个初始的“W/”(即有无 [ weak ]),格式如下所示:
| 值 | 类型 |
|---|---|
| ETag=“123456789” | 强校验 |
| ETag=W/“123456789” | 弱校验(W大小写敏感) |
强校验 ETag 匹配表明两个资源表示的内容是逐字节相同的,并且所有其它实体字段(例如 Content-Language)也未更改。强 ETag 允许缓存和重组部分响应,就像字节范围请求一样。
弱校验 ETag 匹配仅表明这两种表示在语义上是等效的,这意味着出于实际目的它们是可互换的并且可以使用缓存的副本。但是,资源表示不一定逐字节相同,因此弱 ETag 不适用于字节范围请求。弱 ETag 可能适用于 Web 服务器无法生成强 ETag 的情况,例如动态生成的内容。
我们通过下面的例子来看看强、弱校验的匹配对比:
| ETag1 | ETag2 | 强校验 | 弱校验 |
|---|---|---|---|
| W/“1” | W/“1” | 不匹配 | 匹配 |
| W/“1” | W/“2” | 不匹配 | 不匹配 |
| W/“1” | “1” | 不匹配 | 匹配 |
| “1” | “1” | 匹配 | 匹配 |
ETag交互过程
ETag由服务器端生成,发送给客户端,客户端再次访问时通过传If-None-Match字段,服务端判断请求中的If-None-Match来验证资源是否修改。下面是协商缓存(ETag)的请求流程:
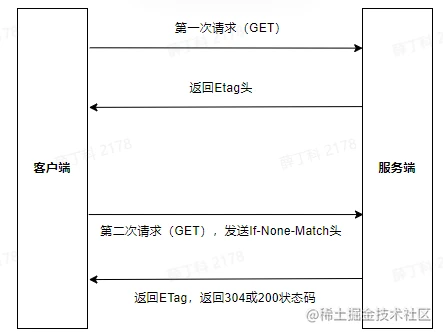
- 客户端发起GET请求
- 服务端接收、处理请求,返回Header值,里面包含ETag字段(如:ETag:“182ed89aac91e00e81c9b0c78de417f6”)
- 此时客户端再次发送请求,该请求头中就会携带上
If-None-Match字段,值是ETag返回的内容(如:If-None-Match: “182ed89aac91e00e81c9b0c78de417f6”)。服务器判断发送过来的If-None-Match字段的值与服务端计算出来的ETag值是否匹配,如果匹配,则返回304状态码,此时服务端不返回任何实体数据,即body为空;否则返回200,同时会返回最新的资源和ETag值;
例如当我们多次访问百度首页时,在控制面板中可以看到部分资源返回状态码是 304,其中Request Headers 和 Response Headers 出现了 ETag/If-None-Match 字段,这说明该资源走的是协商缓存策略。
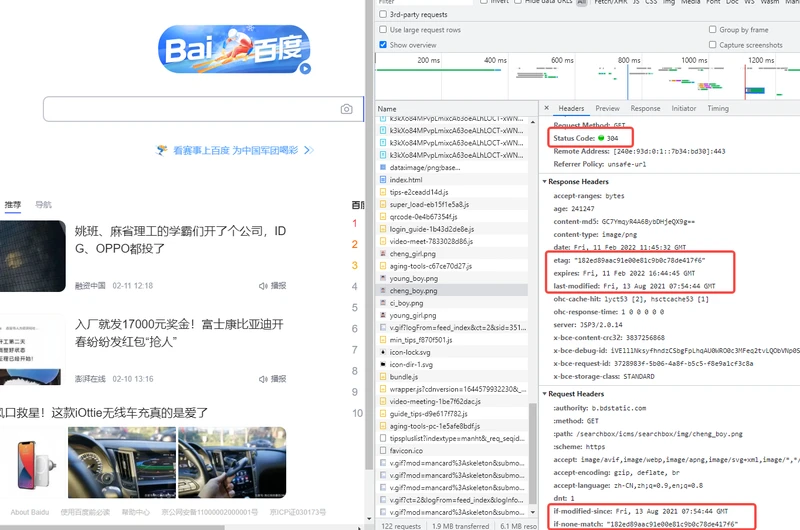
以上就是协商缓存(ETag)的交互过程,接下来我们就来看看ETag的生成原理。
ETag生成原理
虽然HTTP协议没有规定ETag的生成方法,但为了避免使用过期的缓存数据,用于生成 ETag 的方法应保证(尽可能)每个 ETag 是唯一的。生成的 ETag 常用方法包括使用资源内容的抗冲突 散列函数、最后修改时间戳的散列值或一个修订号。
我们接下来介绍的是koa框架中ETag的生成原理,其它框架/服务器生成的方式可能不太一致,但我们只需要了解其实现思路即可。
// https://github.com/koajs/ETag/blob/master/index.js
// 核心代码:生成ETag的函数(下面会具体分析)
const calculate = require('ETag')
// koa中间件,对ctx进行了处理
module.exports = function ETag (options) {
return async function ETag (ctx, next) {
await next()
const entity = await getResponseEntity(ctx) // 获取body内容
setETag(ctx, entity, options) // 生成ETag【重点】
}
}
async function getResponseEntity (ctx) {
// dosomething,最终返回body:return body
}
function setETag (ctx, entity, options) {
if (!entity) return
ctx.response.ETag = calculate(entity, options) // 生成ETag
}
https://github.com/jshttp/ETag/blob/master/index.js
// 核心代码:生成ETag的函数(承接上面)
module.exports = ETag
var crypto = require('crypto')
var Stats = require('fs').Stats
var toString = Object.prototype.toString
/** 为非Stats类型创建ETag */
function entitytag (entity) {
if (entity.length === 0) {
// fast-path empty
return '"0-2jmj7l5rSw0yVb/vlWAYkK/YBwk"'
}
// compute hash of entity
var hash = crypto.createHash('sha1').update(entity, 'utf8')
.digest('base64').substring(0, 27)
// compute length of entity
var len = typeof entity === 'string'
? Buffer.byteLength(entity, 'utf8')
: entity.length
// 重点:长度(16进制)+hash(entity)值
return '"' + len.toString(16) + '-' + hash + '"'
}
/** 生成ETag */
function ETag (entity, options) {
// support fs.Stats object
var isStats = isstats(entity)
var weak = options && typeof options.weak === 'boolean' ? options.weak : isStats
// generate entity tag
var tag = isStats ? stattag(entity) : entitytag(entity)
// 弱ETag 比 强ETag 多了个 W/
return weak ? 'W/' + tag : tag
}
/** 确定对象是否是 Stats 类型 */
function isstats (obj) {
// genuine fs.Stats
if (typeof Stats === 'function' && obj instanceof Stats) {
return true
}
// quack quack
return obj && typeof obj === 'object' &&
'ctime' in obj && toString.call(obj.ctime) === '[object Date]' &&
'mtime' in obj && toString.call(obj.mtime) === '[object Date]' &&
'ino' in obj && typeof obj.ino === 'number' &&
'size' in obj && typeof obj.size === 'number'
}
/** 为 Stats 类型创建ETag */
function stattag (stat) {
var mtime = stat.mtime.getTime().toString(16)
var size = stat.size.toString(16)
// 重点:文件大小的16进制+修改时间
return '"' + size + '-' + mtime + '"'
}
以上就是ETag的生成原理,总结如下:
ETag生成结论
1. 对于静态文件(如css、js、图片等),ETag的生成策略是:文件大小的16进制+修改时间
2. 对于字符串或Buffer,ETag的生成策略是:字符串/Buffer长度的16进制+对应的hash值
ETag如何生效
上面代码介绍了如何生成ETag,如果想让生成的ETag生效,还需要用到另一个koa中间件:koa-conditional-get,该中间件核心源码如下:
// https://github.com/koajs/conditional-get/blob/master/index.js
module.exports = function conditional () {
return async function (ctx, next) {
await next()
// 调用 ctx 上的fresh属性
if (ctx.fresh) {
ctx.status = 304
ctx.body = null
}
}
}
上面的代码中,我们看到koa-conditional-get中间件实际上调用了 ctx 上的fresh属性,如果该属性返回 true ,则将状态码重置为304,同时清空body。我们接着看 ctx.fresh 属性是怎么进行判断的,代码如下:
// https://github.com/koajs/koa/blob/master/lib/request.js
// ctx中fresh属性如下
const fresh = require('fresh') // 真正判断的函数
get fresh () {
const method = this.method
const s = this.ctx.status
// GET or HEAD for weak freshness validation only
if (method !== 'GET' && method !== 'HEAD') return false
// 2xx or 304 as per rfc2616 14.26
if ((s >= 200 && s < 300) || s === 304) {
return fresh(this.header, this.response.header) // 重点
}
return false
}
ctx.fresh 属性的核心内容是引入了第三方库(fresh)来判断资源是否足够新鲜,fresh库的核心代码如下:
// https://github.com/jshttp/fresh/blob/master/index.js
// fresh 核心代码如下
module.exports = fresh
function fresh (reqHeaders, resHeaders) {
// fields
var modifiedSince = reqHeaders['if-modified-since']
var noneMatch = reqHeaders['If-None-Match']
// unconditional request
if (!modifiedSince && !noneMatch) {
return false
}
// Always return stale when Cache-Control: no-cache
// to support end-to-end reload requests
// https://tools.ietf.org/html/rfc2616#section-14.9.4
var cacheControl = reqHeaders['cache-control']
if (cacheControl && CACHE_CONTROL_NO_CACHE_REGEXP.test(cacheControl)) {
return false
}
// If-None-Match
if (noneMatch && noneMatch !== '*') {
var ETag = resHeaders['ETag']
if (!ETag) {
return false
}
var ETagStale = true
var matches = parseTokenList(noneMatch)
for (var i = 0; i < matches.length; i++) {
var match = matches[i]
if (match === ETag || match === 'W/' + ETag || 'W/' + match === ETag) {
ETagStale = false
break
}
}
if (ETagStale) {
return false
}
}
// if-modified-since
if (modifiedSince) {
var lastModified = resHeaders['last-modified']
var modifiedStale = !lastModified || !(parseHttpDate(lastModified) <= parseHttpDate(modifiedSince))
if (modifiedStale) {
return false
}
}
return true
}
根据源码,将fresh函数的代码判断逻辑进行了整理,总结如下。
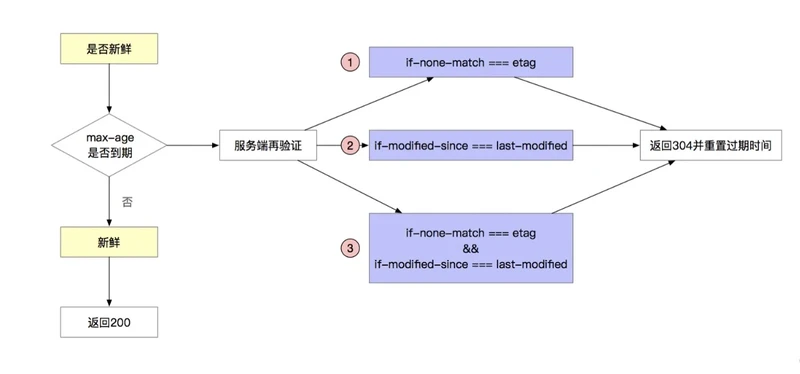
只要满足右边紫色部分的判断条件之一,fresh即为true。需要注意的是,判断条件的优先级是从上到下,即如果ETag和Last-Modified字段同时存在,ETag的优先级更高。
ETag实战
上一节中我们分析了如何让ETag策略生效,加下来我们将通过一个例子来更加直观的了解ETag:
const Koa = require('koa');
const etag = require('koa-etag');
const conditional = require('koa-conditional-get');
const app = new Koa();
// 放在 use(etag) 上面
app.use(conditional());
// 使用 etag
app.use(etag());
// 请求响应
app.use(async function(ctx, next){
await next();
ctx.body = {
name: 'tobi',
species: 'ferret',
age: 2
};
});
app.listen(3000, () => console.log('port 3000'));
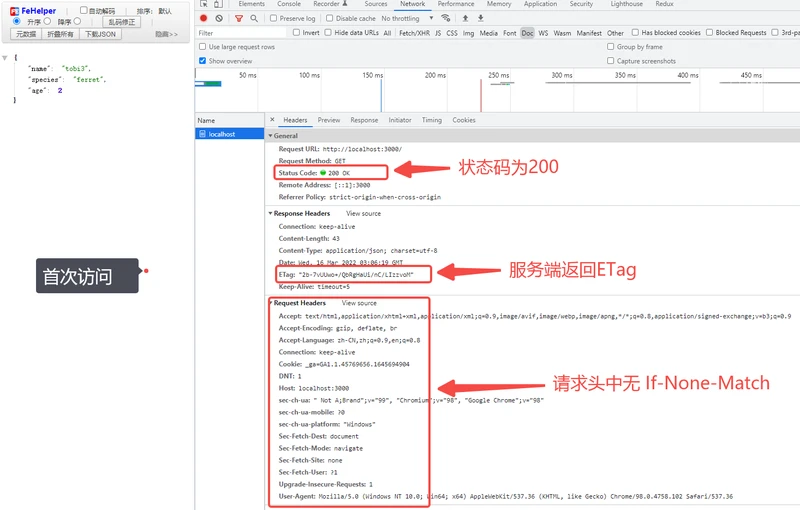

从上图中的访问结果来看,ETag策略已生效。我们这里只给出了最基础的用法,其它用法可根据业务进行调整。
总结
本文首先介绍了ETag的基本定义,它是资源的特定版本的标识符,可以让缓存更高效,并节省带宽;接下来讲述了ETag的起源、验证类型以及服务端与客户端的交互流程;最后,我们通过koa-ETag库的源码具体分析了ETag的生成原理及实战应用,让我们对Etag有了更加直观、清晰的认识。
ETag的提出主要是为了解决Last-Modified验证机制存在的一些问题,但ETag也并非完美,在传统意义上,ETag 只能在单个服务器提供内容的网站上使用,对于像 Apache(2.4版本以下) 或 IIS 等多服务器提供资源的网站,ETag则无法正常工作。此时需要单独对Etag进行配置,请参考 Apache ETag 和 IIS ETag。
不同服务器对ETag的生成策略不尽相同,如果你的请求中返回的ETag值与本文的格式不一致,这是正常现象;如果你想自定义ETag生成算法,可以直接在上述的源码中进行修改,其它服务器请参考 Nginx、Apache。
参考
https://github.com/koajs/etag
https://github.com/koajs/conditional-get/blob/master/index.js
https://github.com/koajs/koa/blob/master/lib/request.js
https://github.com/jshttp/fresh/blob/master/index.js
https://datatracker.ietf.org/doc/html/rfc7232#section-2.3
https://www.cnblogs.com/yalong/p/15207547.html
https://juejin.cn/post/6844904133024022536#heading-19