一、模型提出(1943——1969)
1.1 第一个神经元模型
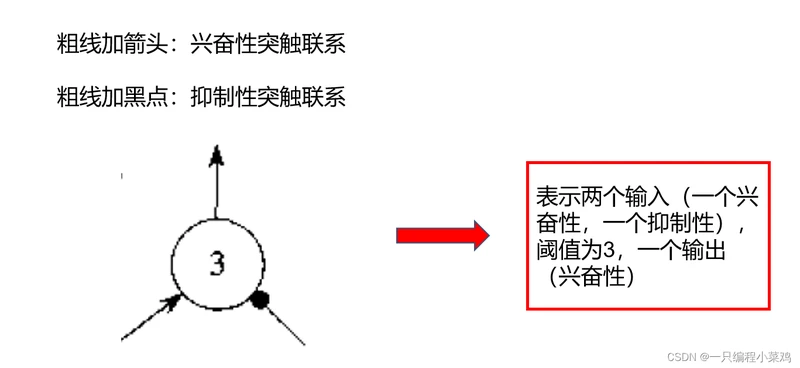
1943年,麦卡洛克(McCulloch)和皮茨(Pitts)为单个神经元建立了第一个数学模型,称为MP模型。
A logical calculus of the ideas immanent in nervous activity论文中提出了人工神经网络的概念,并给出了人工神经元的数学模型,从而开创了人工神经网络研究的时代。


1.2 感知机模型
1958年,罗森·布拉特在New York Times上发表文章Electronic “Brain” Teaches Itself,正式把算法取名为“Perceptron”。
感知机(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别。

二、冰河期(1969年——1982年)
2.1 XOR异或问题
1969年,马文明斯基出版《感知器》,指出神经网络两个缺陷:第一,感知器无法处理异或问题;第二,当时的计算机无法处理大型神经网络所需要的算力。

2.2 BP反向传播
1974年,哈佛大学的Paul Werbos发明BP算法,但在当时并没有受到重视。
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
BP反向传播算法详解:
http://t.csdn.cn/Dw6HR http://t.csdn.cn/Dw6HR
http://t.csdn.cn/Dw6HR
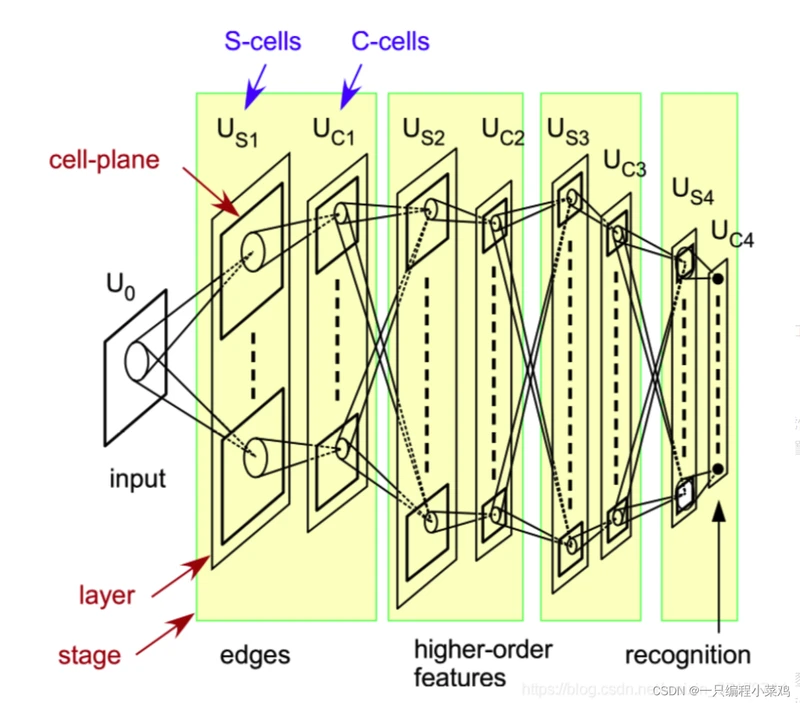
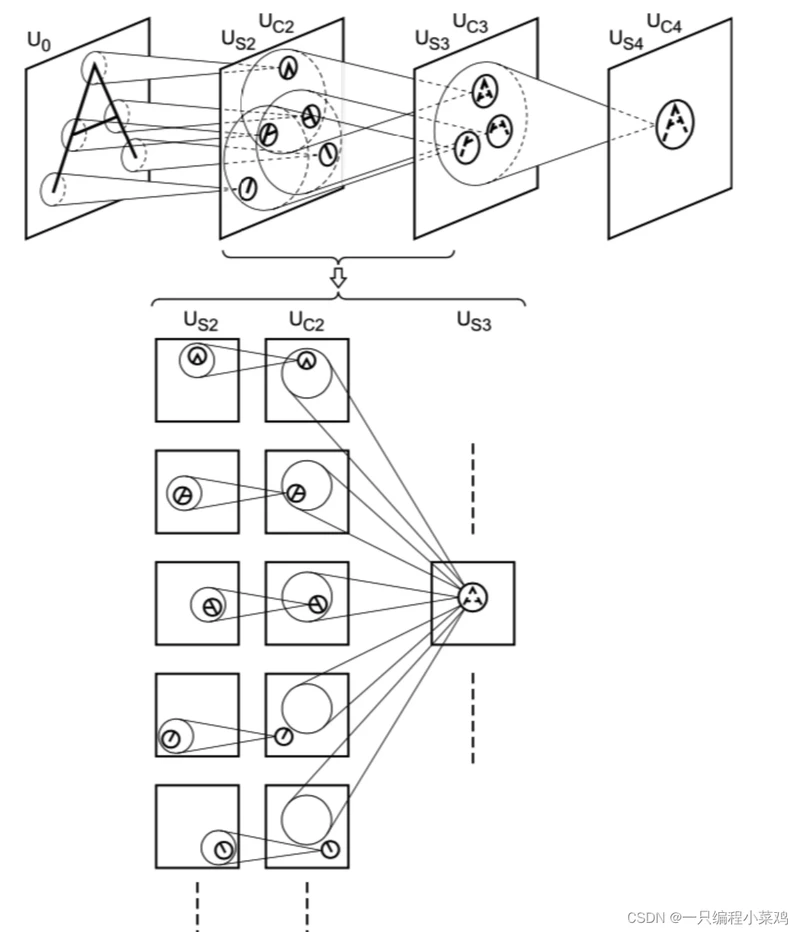
2.3 新识别机的提出
1979年,日本学者福岛邦彦(Fukushima)提出了神经认知机(neocognitron,亦译为“新识别机”)模型,这是一个使用无监督学习训练的神经网络模型,其实也就是卷积神经网络的雏形。
三、反向传播引起的复兴(1982年——1995年)
3.1 Hopfield网络
Hopfield神经网络是一种递归神经网络,由约翰·霍普菲尔德在1982年发明。Hopfield网络是一种结合存储系统和二元系统的神经网络。它保证了向局部极小的收敛,但收敛到错误的局部极小值(local minimum),而非全局极小(global minimum)的情况也可能发生。Hopfield网络也提供了模拟人类记忆的模型。
3.2 玻尔兹曼机
波茨曼机(Boltzmann machine)是随机神经网络和递归神经网络的一种,由杰弗里·辛顿(Geoffrey Hinton)和特里·谢泽诺斯基(Terry Sejnowski)在1985年发明。
波茨曼机可被视作随机过程的,可生成的相应的Hopfiled神经网络。它是最早能够学习内部表达,并能表达和(给定充足的时间)解决复杂的组合优化问题的神经网络。但是,没有特定限制连接方式的波茨曼机目前为止并未被证明对机器学习的实际问题有什么用。所以它目前只在理论上显得有趣。然而,由于局部性和训练算法的赫布性质(Hebbian nature),以及它们和简单物理过程相似的并行性,如果连接方式是受约束的(即约束波茨曼机),学习方式在解决实际问题上将会足够高效。
3.3 Yann LeCun(杨立坤)将BP算法引入神经网络
3.4 1986年 MLP神经网络
3.5 1986年 RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)
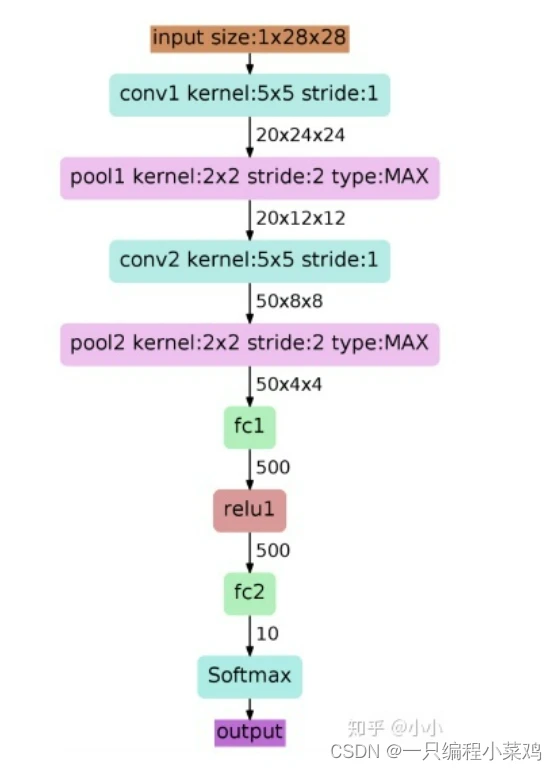
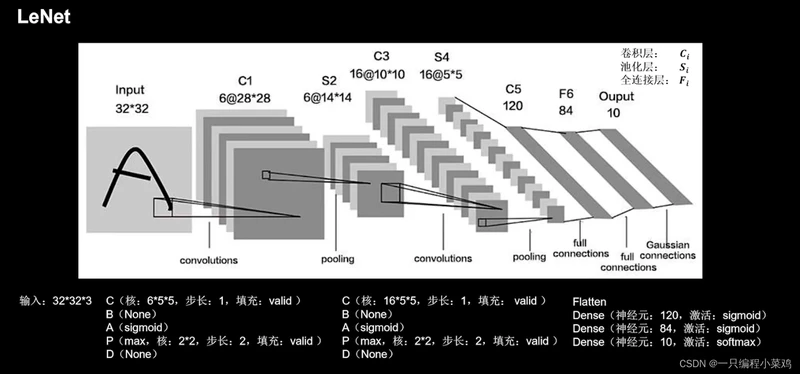
3.6 1990年 LeNet
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid,网络结构如下:
四、第二次低潮(1995年——2006年)
这一阶段主要是机器学习的一些策略的流行度超过了深度学习
4.1 1997年 LSTM、双向RNN
五、深度学习的崛起(2006年——今)
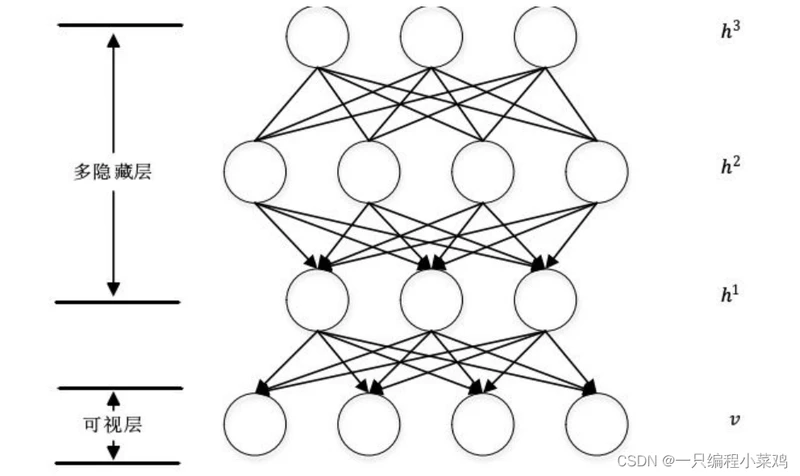
5.1 2006年 DBN深度置信网络
深度置信网络是深度学习方法中的一种神经网络模型,该模型以限制玻尔兹曼机为基础,运用多 RBM 的方式来实现概率生成,其概率生成方式主要是通过构造联合分布函数,函数中是针对输入数据与样本的标签之间的。
5.2 2009年 ImageNet
ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别; 一个典型的类别,如“气球”或“草莓”,包含数百个图像。第三方图像URL的注释数据库可以直接从ImageNet免费获得;但是,实际的图像不属于ImageNet。自2010年以来,ImageNet项目每年举办一次软件比赛,即ImageNet大规模视觉识别挑战赛(ILSVRC),软件程序竞相正确分类检测物体和场景。 ImageNet挑战使用了一个“修剪”的1000个非重叠类的列表。2012年在解决ImageNet挑战方面取得了巨大的突破,被广泛认为是2010年的深度学习革命的开始。
5.3 2012年 AlexNet
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。
该网络的亮点在于:
(1)首次利用 GPU 进行网络加速训练。
(2)使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
(3)使用了 LRN 局部响应归一化。
(4)在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。

http://t.csdn.cn/mrOrNhttp://t.csdn.cn/mrOrN
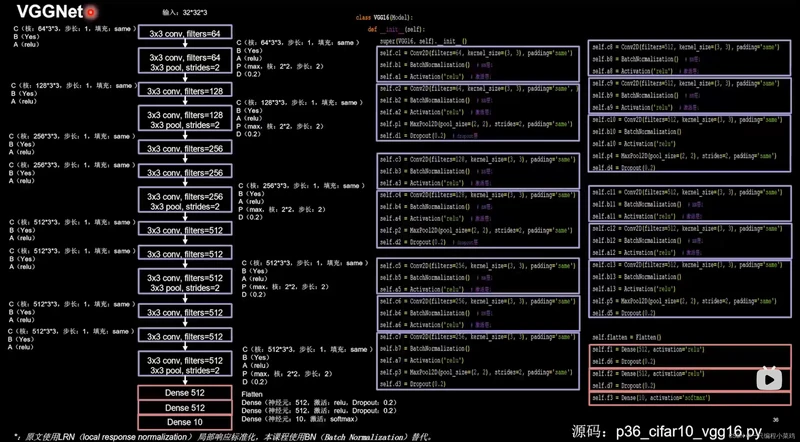
5.4 2014年 VGG GoogLeNet 、GAN对抗神经网络
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司一起研发了新的卷积神经网络,并命名为VGGNet。VGGNet是比AlexNet更深的深度卷积神经网络,该模型获得了2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。
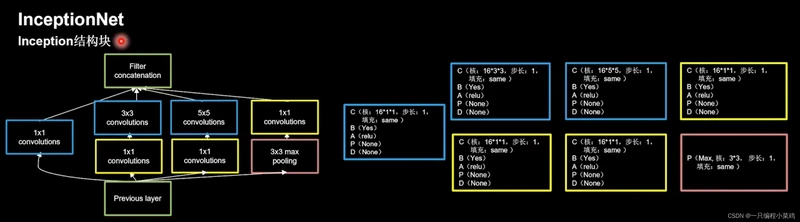
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。
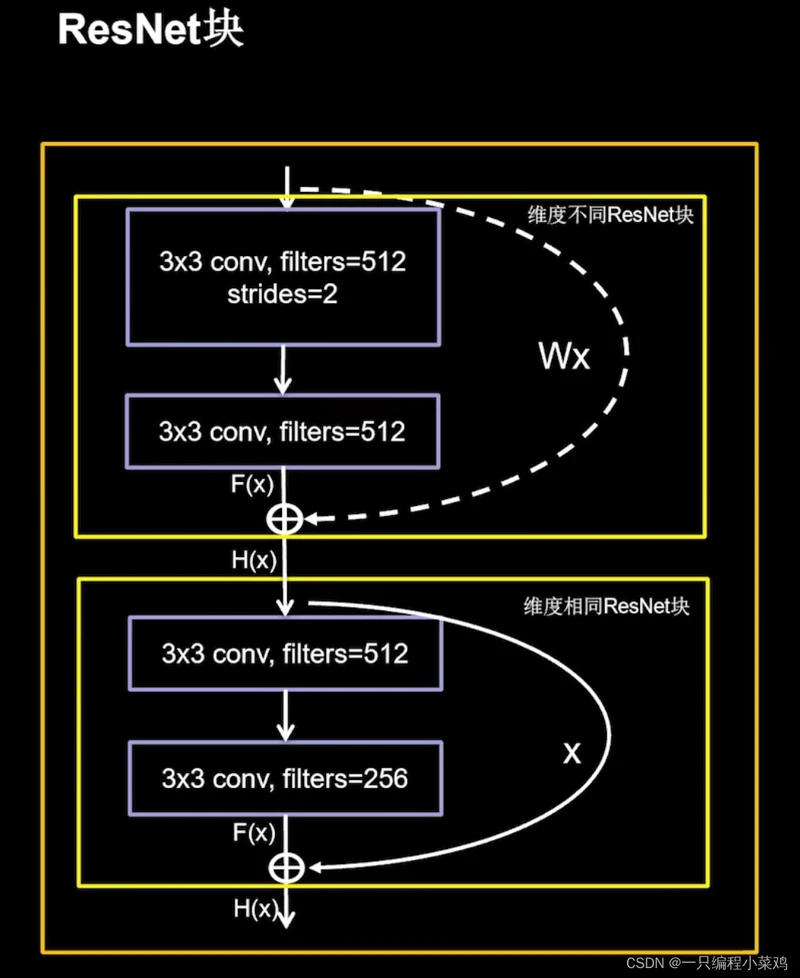
5.5 2015年 ResNet、DQN、Tensorflow发布、Batch Normalization
残差网络是由来自Microsoft Research的4位学者提出的卷积神经网络,在2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的优胜。 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题