
一、简介
1.1、概述
- Hive是Apache提供的一套用于进行数据仓库管理的机制
- Hive提供了类SQL(Hive QL -> HQL)语言来读写或者管理HDFS上的数据,在底层Hive会将这个类SQL语言转化为MapReduce程序执行,因此Hive的执行效率相对较低,适合于离线分析场景
- Hive原本是Hadoop的子工程,但是后来被独立出来成为单独的顶级工程
- 在启动Hive之前,需要先确保服务器上安装并且启动了Hadoop,还需要确保配置了环境变量HADOOP_HOME
- Hive启动的时候,自带一个default库。如果不指定,那么表默认是放在default库下
- 在Hive中,每一个database、table都对应了HDFS上的一个目录
- 在Hive中,没有主键的概念
- 在实际生产过程中,需要在建表的时候就给定这个表的字段之间的间隔符号
- 注意:insert into表示向表中追加数据,insert overwrite表示删除表中所有的数据重新写入
- 在Hive中,数据默认以文本格式(TEXT)存储,所以不支持update和delete语句。但是如果指定为ORC格式,则支持update和delete语句。虽然在实际生产过程中,可能会用到ORC格式,但是很少使用它的update和delete语句
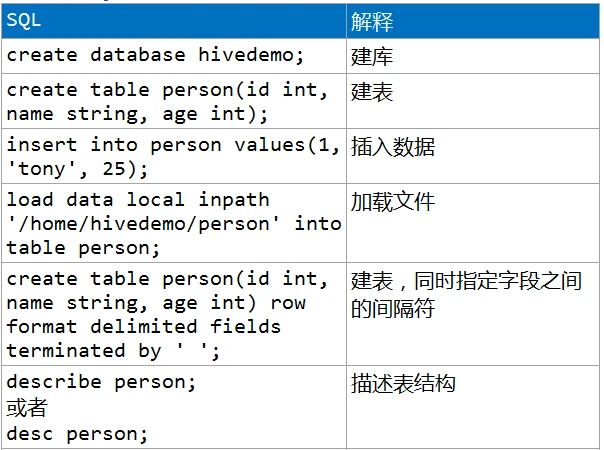
1.2、基本SQL
1.3、元数据
- 在Hive中,存在元数据的。元数据包含库名、表名、字段名、分区信息、分桶信息、函数信息、索引信息、视图信息等
- Hive的数据是维系在HDFS上的,但是Hive的元数据是维系在关系型数据库(RDBMS - Relational Database Management System)中。如果不指定,默认情况下,Hive会将它的元数据维系在Derby中。基于Derby的特性,所以实际生产过程中,会更换Hive的元数据库。Hive的元数据库只支持2个:Derby和MySQL
1.4、体系结构
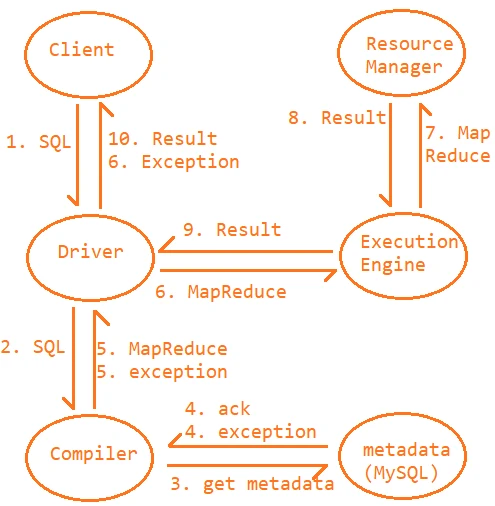
1、Driver:任务的居中调度
2、Compiler:编译,将SQL转化为MapReduce
3、ExecutionEngine:和YARN进行任务交互
1.5、优化
- map side join
a. 当小表join大表的时候,那么可以考虑将小表中的数据放到内存中,然后处理大表。如果需要用到小表中的数据,那么可以从内存中将对应的数据获取出来
b. 默认情况下,如果表(文件)的大小不足25M,则将这个表看作是一个小表。可以通过hive.mapjoin.smalltable.filesize来调节
c. 需要通过hive.auto.convert.join=true来开启map side join机制- join语句的优化:当join的时候出现了where,那么可以考虑先利用子查询执行where语句来降低数据量,然后再利用join来进行连接查询
- group by的优化
a. 在group by的时候,因为数据本身存在倾斜特性,所以ReduceTask之间处理的数据量不均衡从而产生数据倾斜,导致效率变低
b. 在Hive中,可以通过set hive.groupby.skewindata=true来开启二阶段聚合- count distinct:子查询中可以通过mapred.reduce.tasks来设置多个ReduceTask完成去重,最后再利用1个ReduceTask来完成计数
- 在数据量相对较小的时候,distinct的效率要稍微高一些;但是数据量大的时候,group by的效率要远高于distinct。根据实验证明,在百万条数据的时候,group by花费的时间大约是distinct花费时间的1/7
- 在MapReduce中,切片大小默认为128M。如果数据结构相对复杂或者处理逻辑相对复杂,那么可以考虑调小切片大小增多任务数量提高效率;如果数据结构相对简单或者处理逻辑相对简单,那么可以考虑增大切片大小减少任务数量节省资源。通过mapred.max.split.size来设置切片的大小 - 在任务容易完成的情况下,那么让每一个任务多执行点,减少任务数量,来节省集群资源;如果任务不容易完成,那么让每一个任务少执行,增多任务数量,来提升执行效率
- 开启严格模式:set hive.mapred.mode=strict
a. 禁止显式地产生笛卡尔积。例如select * from orders, users;这种写法就不被允许
b. 在严格模式下,查询分区表的时候必须携带分区字段
c. 在对数据进行排序的时候,要求必须携带limit- 关闭推测执行机制
- 实现JVM的重用:set mapred.job.reuse.jvm.num.tasks=20
二、基本表结构
2.1、内部表和外部表
- 在Hive中手动建表手动添加数据(insert/load),这种表称之为内部表
- Hive中手动建表来管理HDFS上已经存在的数据,这种表称之为外部表
- 当删除内部表的时候,内部表对应的目录会一起被删除;当删除外部表的时候,外部表对应的幕布不会被删除
- 在实际生产过程中,在数据处理的初期往往采用的是外部表;在数据处理的中后期采用的是内部表
2.2、分区表
- 分区表的作用也是对数据进行分类
- 在Hive中,每一个分区对应了一个单独的目录
- 如果在分区表中指定了分区字段来查询,那么查询效率相对较高;如果跨分区查询,在未分区表中查询快
- 注意:在分区表中,分区字段在原始数据中并不存在,而是在添加/加载数据的时候来手动指定的
- 在Hive中,支持多字段分区。实际生产过程中,如果需要对数据进行多级分类的时候,可以考虑多字段分区。前一个字段形成的目录会包含后一个字段形成的目录
2.3、分桶表
- 分桶表的作用是对数据进行抽样
- 在Hive中,默认分桶机制是不开启的,所以默认无法使用分桶表。如果需要使用分桶表,那么需要先开启分桶机制 set hive.enforce.bucketing = true;
- 注意:在向分桶表中添加数据的时候,只能使用insert方式,不能使用load方式。如果使用load方式,那么数据不会进行分桶
- 如果数据量相对较大但是有需要快速的获取结果,那么这个时候可以考虑进行抽样。注意,在抽样的时候,要求被抽样的字段和要分析的数据之间没有联系 - 部分代替整体
三、数据类型
3.1、概述
- 在Hive中,提供了丰富的数据类型。这些数据类型可以分类:基本类型和复杂类型
- 基本类型包含了10个类型:tinyint,smallint,int,bigint,float,double,boolean,string,timestamp,binary
- 复杂类型包含3个类型:array,map,struct
3.2、复杂类型
- array:数组类型,对应了Java中的数组或者集合
- map:映射类型,对应了Java中的Map类型
- struct:结构体类型。对应了Java中的对象
四、运算符和函数
4.1、概述
- 在Hive中,提供了非常丰富的运算符/函数,使得对数据的计算相对比较简便
- 在Hive中,如果原生提供的函数不足以解决的问题,那么Hive还允许自定义函数
4.2、常见函数
- 如果需要了解一个函数,那么可以通过desc function 函数名的方式来获取这个函数的信息
- year(str):输入一个字符串,然后将字符串中的年给提取出来。要求给定的字符串表示的日期必须用-间隔
- concat_ws:以指定的间隔符将数据来进行拼接
- nvl(s1, s2):如果s1的值为null,就会返回s2的值
- explode:会将数组和映射中的元素来进行拆分,将每一个元素提取出来形成单独的一行
4.3、自定义函数分类
- UDF:User-Defined Function - 用户定义函数。特点:一进一出。即输入一行数据会获取到一行结果。例如reverse,length,concat,split等
- UDAF:User-Defined Aggregation Function - 用户定义聚合函数。特点:多进一出。即输入多行数据会获取到一行结果。例如count,sum,collect_set,collect_list等
- UDTF:User-Defined Table-Generated Function - 用户定义表生成函数。特点:一进多出。即输入一行数据会获取到多行结果。例如explode等
五、其他操作
5.1、having
- having用于进行条件查询的。但是不同于where,having只能针对聚合结果来进行查询,where则只能针对字段来进行查询
- having在使用的时候必须结合group by来使用
5.2、排序
- 在Hive中,提供了两种排序方式:order by和sort by。其中,sort by是Hive单独提供的一种排序方式
- 区别
a. order by:无论ReduceTask的数量有几个,都是将所有的数据来进行统一的排序 - 整体排序
b. sort by:在每一个ReduceTask的内部将数据进行排序 - 局部排序- 在实际生产过程中,sort by结合distribute by来使用。distribute by是对数据来进行分类,分类之后再在每一个类中分别对数据来进行排序
- 在实际生产过程中,如果sort by和distribute by的字段一致,那么可以改写为cluster by。例如distribute by profit sort by profit 那么等价于cluster by profit
5.3、join
- 在Hive中,支持left join,right join,inner join和full outer join
- 在Hive中,如果不指定,那么默认使用的是inner join
- 在Hive中,还提供了left semi join。当a left semi join b,表示找a表中的哪些数据在b表中出现过
5.4、beeline
- beeline实际上是Hive提供的一个远程连接工具,连接指定服务器上的Hive服务
- 步骤:
a. 开启Hive的后台服务,这一步相当于公司的服务器上需要先开启Hive服务
sh hive --service hiveserver2 &
b. 发起远程连接
sh beeline -u jdbc:hive2://10.9.162.133:10000/demo -n root
5.5、SerDe
- SerDe(Serializer-Deserializer)实际上是Hive提供的一种序列化/反序列化机制
- 在实际生产过程中,会利用这个机制来处理不规则的数据。在处理的数据的时候,每一个捕获组对应表中一个字段,即捕获组的数量和字段的数量是一致的
5.6、索引
- 在MySQL中,会自动针对主键来建立索引。但是因为Hive中没有主键的概念,所以默认情况下,Hive中不会自动建立索引
- 在Hive中,如果需要建立索引,那么手动针对指定的字段来建立索引
5.7、视图
- 在实际生过程中,一个表中会包含多个字段,但是字段之间的使用频率并不相同,那么可以考虑将经常使用的字段抽取出来构成一个子表。在对子表进行大量查询的情况下,可以考虑将子表设计成一个视图 - 所以视图可以看作是原表的子表
- 如果视图是维系在内存中的,那么把这个视图称之为虚拟视图;如果视图是维系在磁盘上的,那么把这个视图称之为物化视图
- Hive中,只支持虚拟视图不支持物化视图
- 在建立视图的时候需要封装一个select语句,这个select语句的作用是用于进行字段的抽取。但是需要注意的是,在建立视图的时候封装的这个select语句并没有执行,而是在真正第一次使用这个视图的时候才会执行这个封装的select语句 - 懒加载
- 懒加载的原因:数据在开始处理之前,会先定好数据模型。但是数据模型中的视图建好不意味着会立即使用这些视图。如果没有用到这些视图,就将数据填充到视图中,会浪费大量的资源和空间。尤其是在大数据场景下,数据量较大,浪费的资源和空间会更多,所以会推迟这个数据的加载过程,直到真正用到这些数据为止,才会考虑加载这些数据
- 视图只能查询不能写入
六、Hive 的元数据库切换到 MySQL
在安装完成Hive之后默认是以Derby数据库作为元数据库,存储Hive有那些数据库,以及每个数据库中有哪些表,但是在实际生产过程中,并不是以derby作为Hive元数据库,都是以Mysql去替换derby。
1、究其原因主要是基于两点原因:
- Derby数据库不支持并发,也就是只支持单线程操作,当有一个用户在对Hive进行操作时,其他用户则无法操作,导致整体效率性能较低。
- 当在切换目录后,重新进入Hive会找不到原来已经创建的数据库和表。主要原因是比如第一次是在bin目录下进入Hive,那么在进入Hive后,会在bin目录下创建一个metaStore.db的目录,然后在此目录下会创建一个derby.log的日志文件,所有的元数据的信息都是存储在这个日志文件中。那么经过更换目录后,然后进入Hive就会存在一个问题,原有的元数据信息都是基于bin目录下创建的,所以在找数据库和表的信息时候,都是基于bin目录的,而此时就会存在找不到原有创建的数据库和表的信息,所以会将默认的Derby数据库进行更换为Mysql。
2、配置步骤:
1. 在MySQL中赋权
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
grant all on *.* to 'root'@'%' identified by 'root';
flush privileges;
2. 在MySQL中为Hive存储元数据创建数据库
create database hive character set latin1;
3. 进入Hive安装目录的子目录conf下
cd /home/software/apache-hive-1.2.0-bin/conf
4. 编辑
vim hive-site.xml
添加
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
5. 进入子目录lib下,下载MySQL的驱动jar包
cd ../lib
wget http://bj-yzjd.ufile.cn-north-02.ucloud.cn/mysql-connector-java-5.1.38-bin.jar
6. 回到bin目录下,启动Hive
cd ../bin
sh hive
七、Hive 下载地址:
百度云盘链接:https://pan.baidu.com/s/1hwI46iX5xQ2ccIxg1zkWpw(提取码:wx8l)
(如果提示过期,请评论再次更新)
• 由 ChiKong_Tam 写于 2021 年 1 月 26 日