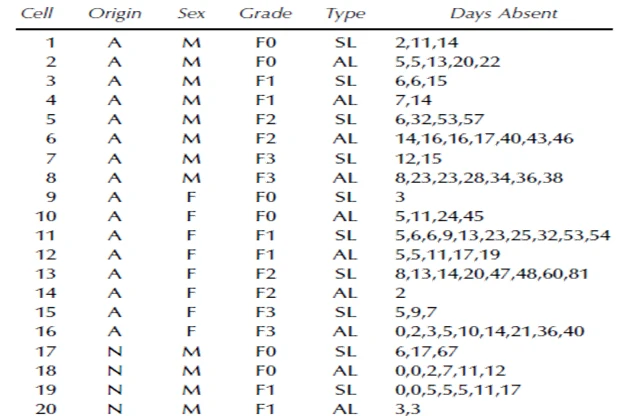
概念部分
作业一:
g) SAS语句通常以一个关键字开头。每一个SAS语句都以分号结尾。可以使用 contents过程查看SAS 数据集的描述部分。字符型变量长度最多能有 32767 字符长,并且每个字符使用 1 个字节存储。
h) 默认情况下,数值型变量存储为8 个字节。日期1960年1月3日数据值是2。
i) 一个SAS变量名有 1 到 32 个字符,以 字母 或者 下划线 开头一个缺失的字符值显示为 空格 ,一个缺失的数值显示为 句点 。当开始一个SAS会话时,SAS自动创建的临时逻辑库是 Work
j) 一个逻辑库名必须为 8个字符或更少。
k) 有哪两种程序步?data数据步和proc过程步
在SAS窗口环境中,三种主要窗口是什么?程序编辑器、日志、输出;
每一个SAS数据集都有哪两部分组成? 描述部分和数据部分;
变量的两种类型? 数值型和字符型。
两种类型的数据对象:数据集(Data sets)和数据视窗(Data View)
三种主要窗口:程序编辑器、日志、输出
字符型变量: 包含任意值:字母,数字,特殊字符以及空格。字符值的存储长度是1到32,767个字节。一个字节等于一个字符。
数值型变量: 默认情况下以长度为8个字节的浮点方式存储。8个字节的浮点方式存储提供了16或17个有效数位。并不局限于8个数位。
p.s. 日期型变量在SAS中被储存为数值,从1960年1月1日开始(为0)
缺失值: 字符的为空格,数值为点(.)
SAS变量命名特点: 1、长度可以是1至32个字符。2、必须以字母或下划线开头。后续字符可以是字母,下划线或数字。3、可以大写,小写或大小写混合。4、不区分大小写。
程序: 每个 SAS程序 由若干程序步组成。
语句: 通常以SAS关键字开头,始终以分号结束。
语法规则:
1、SAS语句书写格式自由。
2、一个或多个空格或特殊字符可以被用来分隔单词。
3、可以在任何列开始和结束。
4、单个语句可以延续多行。
5、多个语句可位于同一行上。
SAS语言:
1、SAS语句组成的序列称为SAS程序.
2、一个SAS语句是由SAS关键词、SAS名字、特殊字符和运算符组成的字符串,并必须以分号(;)结尾,它要求SAS系统执行一种操作或给SAS系统提供信息.
3、许多SAS语句都是以关键词开始并用它识别语句的类型.如DATA语句、PROC语句、INPUT语句等.
4、SAS语句中可能出现的SAS名字种类很多,如变量名、SAS数据集名、格式名、过程名、数组名、语句标号名、以及作为文件标记和库标记的特殊名字.
SAS语言-数据步:
数据步以DATA语句开始, RUN语句结尾,用于创建和加工SAS数据集。
SAS语言-数据步一般包括:
⑴ 文件操作语句--要求SAS创建一个或几个新的SAS数据集的语句,如DATA、INPUT、CARDS、INFILE、SET、MERGE等语句;
⑵ 运行语句–对创建数据集所必须进行的运算语句,如赋值、累加、where和in等语句;
⑶ 控制语句—实现从程序的一部分转移到另一部分的语句,如DO循环、IF、GOTO、 SELECT、LINK等语句;
⑷ 信息语句—给出关于数据集或正被生成的数据集的附加信息,如ARRAY、INFORMAT、FORMAT、LENGTH、ATTRIB、KEEP、DROP等语句.
SAS语言-输出:
1、日志(LOG)窗口:显示程序执行中记录的信息;它包括执行哪个语句;生成的数据集中变量个数及观测个数是多少;每一步花费的时间及出错信息等等
2、输出(OUTPUT):SAS过程产生的输出
SAS语言-SAS运算符: SAS运算符包括算术、比较、逻辑等运算符。
1、算术运算符为 +,-,*,/,**,运算优先级按通常的优先规则。
2、比较运算符用于比较常量、变量的值大小、相等,包括
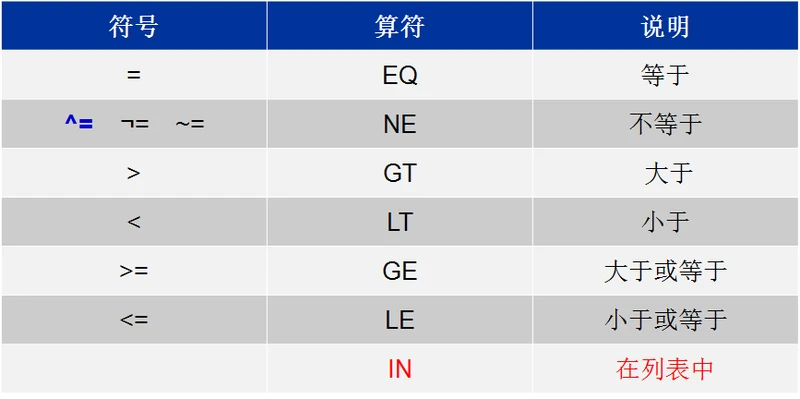
运算符IN是一个SAS特有的比较运算符 (值必须用逗号或空格分隔),用来检查某个变量的取值是否在一个给定列表中,比如 prov in (‘北京’, ‘上海’, ‘天津’, ‘重庆’) 可以判断变量prov的取值是否为四个直辖市之一。
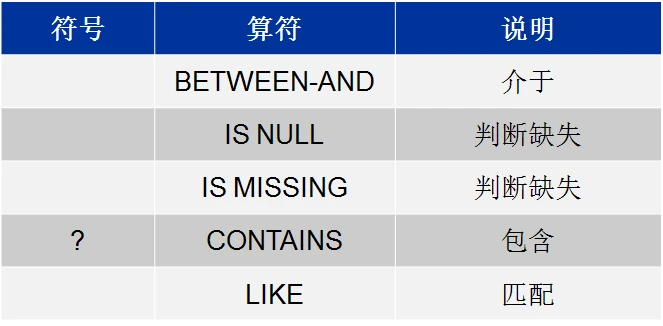
特殊WHERE运算符 是只能用于where表达式中的运算符:
3、逻辑运算符用来连接比较得到的结果以构成复杂的条件,有三种逻辑运算符:
&(AND) |(OR) ^(NOT)
其中AND是&(与)的等价写法,OR是|(或)的等价写法,NOT是^(非)的等价写法。
例如
(salary >= 1000) AND (salary < 2000)
表示工资收入在1000-2000之间(不含2000);
(age <= 3) OR (sex = ‘女’)
表示三岁以下(含三岁)的婴儿或妇女;
NOT ((salary >= 1000) AND (salary < 2000))
表示工资收入不在1000-2000之间。
4、其它的运算符还有用于连接两个字符串的||(两个连续的|号),用于取两个运算值中较大一个的<>(比如3<>5结果为5),用于取两个运算值中较小一个的>< (比如3><5结果为3)。
SAS函数(统计部分)
分布函数和分布密度函数
分布函数值 = CDF(‘分布’, x <, 参数表>);
密度值 = PDF(‘分布’, x <, 参数表>);
概率值 = PMF(‘分布’, x <, 参数表>);
对数密度值 = LOGPDF(‘分布’, x <, 参数表>);
对数概率值 = LOGPMF(‘分布’, x <, 参数表>);
例:
PDF(‘NORMAL’, 1.96)
计算标准正态分布在1.96处的密度值(0.05844);
CDF(‘NORMAL’,1.96)
计算标准正态分布在1.96处的分布函数值(0.975)
PMF(‘NORMAL’,1.96)=PDF(‘NORMAL’,1.96)
即PMF对连续型分布即为PDF。
① PROBNORM(x):计算标准正态的分布函数.即计算服从标准正态分布的随机变量U小于等于给定x的概率(P{U<=x}).
② PROBCHI(x,df,nc):计算自由度为df,非中心参数为nc的卡方分布的分布函数.如果nc没有规定或取为0,那么被计算的就是中心卡方分布.自由度df允许不是整数.
例如:
p=1-probchi(31.264,11); 的结果为1-0.999=0.001.
③ PROBGAM(x,a):计算形状参数a(a>0)的伽马分布的分布函数.
例如: p=probgam(7.5,5.2);的结果为0.84885.
④ PROBBETA(x,a,b):计算贝塔分布的分布函数(其中:0≤x≤1,a,b>0).例如:
p=probbeta(0.75,4,2.5);的结果为0.7467.
⑤ PROBF(x,ndf,ddf,nc):计算F分布分布函数(其中ndf为分子自由度,ddf为分母自由度,nc是非中心参数).当分布是中心F分布时,取nc=0或不规定这项自变量.自由度可以是非整数.例如:p=1-probf(3.32,2,30);的结果是0.04983.
⑥ PROBBNML(p,n,m)(其中:0≤p≤1,n≥1,0≤m≤n) :计算二项分布的概率分布函数.
⑦ PROBT(x,df,nc):计算t分布分布函数(其中df为自由度,nc为非中心参数).若参数nc没有规定或取为0,那么被计算的就是中心t分布.自由度df允许非整数.
⑧ POISSON(lambda,n)(其中 lambda≥0,n≥):计算柏松 分布的概率分布函数.
⑨ PROBNEGB(p,n,m)(其中0≤p≤1,n>0,m≥0):计算负二项分布的概率分布函数.
⑩ PROBHYPR(nn,k,n,x,r)(其中nn≥1,0≤k≤nn, 0≤n≤nn,max (0,k+n-nn)≤x≤min(k,n) ):计算超几何分布的概率分布函数. 设nn个产品中有K个不合格品,抽取n个样品,其中不合格品数小于等于x的概率为此函数值。可选参数r是不匀率,缺省为1,r代表抽到不合格品的概率是抽到合格品概率的多少倍。
⑾ PROBBNRM(x,y,r) 标准二元正态分布的分布函数,r为相关系数。
分位数函数
① CINV(p,df,nc)(其中 0≤p≤1,自由度df>0,非中心参数nc≥0)计算卡方分布的分位数.例如:
data;
q1=cinv(0.95,3);put ′q1=′q1;
q2=cinv(0.95,3.5,4.5);put q2=;
run;
结果是q1=7.8147,q2=17.505 (在LOG窗口显示).
② BETAINV(p,a,b)(其中:0≤p≤1,a>0,b>0):
计算贝塔分布的分位数.例如:
x=betainv(0.001,2,4);的结果为0.0101.
③ FINV(p,ndf,ddf,nc)(其中 0≤p≤1,分子自由度ndf>0,分母自由度ddf>0,非中心参数nc≥0):计算F分布的分位数.例如以下DATA步计算的结果为q1=4.1028,q2=7.5838.
data null;
q1=finv(0.95,2,10);put q1=;
q2=finv(0.95,2,10,3.2);put q2=;
run;
④ TINV(p,df,nc)(其中0≤p≤1,自由度df>0 ):计算t分布的分位数.若nc没有规定或取nc=0,那么计算的就是中心t分布的分位数.若nc的绝对值很大,使用的算法可能失败.这种情况函数得到一个缺失值.
⑤ PROBIT§(0≤p≤1):计算标准正态分布的分位数.它是概率函数PROBNORM的逆函数.
如果随机变量X~N(0,1),则
P{X≤probit(z)}=z,
这个函数产生的结果在-5和5之间.
⑥ GAMINV(p,a)(其中:0≤p≤1,a>0):计算伽马分布的分位数.
例如: x=gaminv(0.75,3.5);的结果为4.51857.
样本统计函数
①均值:MEAN(of x1-xn)或MEAN(x,y,z,…).例如
x=mean(2,·,·,6);结果为4.
x=mean(1,2,3,2); 结果为2.
②最大值:MAX(of x1-xn)或 MAX(x,y,…)
③最小值:MIN(of x1-xn)或 MIN(x,y,…)
④ 非缺失数据的个数:
N(of x1-xn)或 N(x,y,…)
⑤ 缺失数据的个数:
NMISS(of x1-xn) 或 NMISS(x1,x2,…).
⑥求和:SUM(of x1-xn) 或 SUM(x1,x2,…).
⑦方差:VAR(of x1-xn) 或 VAR(x1,x2,…).
⑧标准差:STD(of x1-xn)或 STD(x1,x2,…).
例如 x=std(2,6);和x=std(2,·,6);的结果都是2.828427. x=std(2,4,6,3,1);的结果为1.923538.
⑨ 标准误:STDERR(of x1-xn)或STDERR(x1,x2,…).
例如: x=stderr(2,6,3,4);或
x=stderr(2,6,3,4,·);的结果都是0.8539126。
⑩ 变异系数:CV(of x1-xn)或 CV(x1,x2,…).
⑾ 极差:RANGE(of x1-xn)或RANGE(x1,x2,…).
⑿ 偏差平方和(校正平方和):
CSS(of x1-xn)或 CSS(x1,x2,…).
该函数计算非缺失自变量关于均值的偏差平方和.
⒀ 未校正的平方和:
USS(of x1-xn) 或 USS(x1,x2,…).
该函数计算非缺失自变量的(未校正)平方和.
⒁ 偏斜度:
SKEWNESS(of x1-xn)或SKEWNESS(x1,x2,…).
该函数计算非缺失自变量的偏斜度.
⒂ 峰度:
KURTOSIS(of x1-xn)或KURTOSIS(x1,x2,…).
计算非缺失自变量的峰度,它要求至少有4个非缺失自变量.
⒃ORDINAL(k,x1,x2,…xn)—返回数值列表x1, x2,…xn中第k小的值.
随机数函数
设随机变量η的分布函数为F(x),称随机变量的抽样序列η1,η2,…ηn…为F(x)分布随机数.产生各种常用分布的随机数是随机模拟方法的基础.SAS系统提供产生11种常见分布随机数的函数.
① 均匀分布随机数函数:
UNIFORM(seed)和RANUNI(seed).
② 标准正态分布随机数函数:
NORMAL(seed)和RANNOR(seed).
利用这个函数经变换还可以得到一般正态分布随机数及对数正态随机数.例如记 X=M+sqrt(SQ)rannor(seed)
Y=exp(M+sqrt(SQ)rannor(seed))=exp(X)
则X是均值为M、方差为SQ的正态随机变量;Y是对数正态变量,均值为exp(M+SQ/2),方差为exp(2M+SQ)*(exp(SQ)-1).
③ 指数分布随机数函数:RANEXP(seed).
④ 伽马分布随机数函数:
RANGAM(seed,alpha) (其中 alpha>0).
⑤ 三角分布随机数函数:RANTRI(seed,h)(其中0<h<1).
⑥ 柯西分布随机数函数:RANCAU(seed).
⑦ 二项分布随机数函数:RANBIN(seed,n,p)(n>0为整数,0<p<1).
⑧ 泊松分布随机数函数:RANPOI(seed,lambda)(lambda>0 ).
⑨ 离散分布随机数函数: RANTBL(seed,p1,…,pi,…,pn)
(其中0≤??≤1(?=1,2,…,?),??=1)
截取、算术、数学和三角函数等
CEIL(x)–取≥自变量x的最小整数.CEIL(4.5)=5.
FLOOR(x)–取≤自变量x的最大整数.Floor(4.5)=4.
INT(x)–取x的整数部分.如INT(4.5)=4.
ABS(x)–求x的绝对值.
MOD(x,y)–求x除以y的余数.
SQRT(x)–求x的平方根.
DIGAMMA(x)–对自变量x计算GAMMA函数对数的导数.
GAMMA(x)–对自变量x计算完全GAMMA函数.
LOG(x)–对自变量x求以e为底的自然对数.
LOG2(x)–对自变量x求以2为底的对数.
LOG10(x)–对自变量x求以10为底的对数.
ERF(x)–计算误差函数.
EXP(x)–计算e的x次幂.EXP(x)=ex.
SIN(x),COS(x),TAN(x)–求x的正弦,余弦和正切.
SINH(x),COSH(x),TANH(x)–求双曲正弦,余弦和正切
UPCASE(s)–把字符串s转化为大写字母。
LOWCASE(s)–把字符串s转化为小写字母。
SUBSTR(s,p,n)–从字串s中第p个字符开始取n个字符的子串连
LAGn(x)—返回该自变量x前n条观测(记录)中该变量的值.
DIFn(x)—得到该自变量x的值减去前n条观测(记录 )中该变量的值.
计算同比环比
data lagdif;
set dst.air;
pct1=dif(air)/lag(air);
pct2=dif12(air)/lag12(air);
run;
Proc print data=Lagdif;
id date;
var air pct1 pct2;
Run;
SAS日期常数和函数
日期函数
日期时间直接作为数值型常数:
‘ddMMMyy ’D(例如 : ‘12JAN96’d )
一些操作日期的函数:
DATE()—取今天的日期作为SAS日期值,
TODAY()–取当日的日期作为SAS日期值,
DATETIME()–取当日的日期和时间作为SAS日期时间值,
TIME()–取今天的时间作为SAS时间值,
HOUR(time | datetime)—由SAS的时间或日期时间得到小时,
MINUTE(time | datetime)–由SAS的时间或日期时间得到分钟,
SECOND(time | datetime)–由SAS的时间或日期时间得到秒钟
YEAR(date)–由SAS日期date得到年,
MONTH(date)–由SAS日期date得到月,
DAY(date)–由SAS日期date得到日,
WEEKDAY(date)–由SAS日期date得到星期几(周日1) QTR(date)–由SAS日期date得到季度值,
MDY(month,day,year)–生成year年month月day日的日期值,
HMS(hour,minute,second)–由小时hour,分钟minute,秒second生成时间值,
DHMS(date,hour,minute,second)–生成日期时间值,
DATEPART (datetime)–取SAS日期时时间值datetime的日期部分,
INTNX(interval,from,n)–计算从from开始经过n个间隔后的SAS日期其中interval可以取‘YEAR’、‘QTR’、‘MONTH’、‘WEEK’、‘DAY’等。比如,
INTNX(‘MONTH’, '16Dec1997’d,3)
结果为1998年3月1日。注意它总是返回一个周期的开始值。
INTCK(interval,from,to)–计算从日期from到日期to中间经过的interval间隔的个数,其中interval取‘MONTH’等.比如,
INTCK(‘YEAR’, ‘31Dec1996’d, ‘1Jan1998’d)
计算1996年12月31日到1998年1月1日经过的年间隔的个数,
结果得2,尽管这两个日期之间实际只隔1年。
数据部分(DATA步)
一、数据读取
四中方式建立数据集:
用VIEWTABLE或菜单系统
编程:用DATA步
用Import菜单
用SAS/ACCESS
data步建立(直接输入、文本数据):
data:数据步的开始、命名要创立的 数据集。
Input:确定输入的数据所对应的变量。
datalines; (新用法,对长度无限制)
cards; 输入数据 (很久很久以前,data储存在cards上)
例1 直接输入 (小数据量) :
data da1;
input x y z;
sum=x+y+z;
cards;
1 3.1 5
3 2.3 7
6 3.4 6
;
run;
例2 文本数据 (大数据量)也可以用datalines:
data da2;
infile ‘c:\f1.txt’;
infile datalines;
dlm=' ,' 规定分隔符
input x y z;
mean=(x+y+z)/3;
run;
文本数据文件f1.txt的内容:
1 3.1 5
3 2.3 7
…….
***Options(选项):
(1) DLM=‘,’ delimiter=‘ab’—规定分隔符,可输入多个都在引号中;
(2) FIRSTOBS=n1 OBS=n2—读入源数据文件中的第n1行至n2行. 若只规定一项,另一项表示第一行或最后一行.
(3) DATALINES—规定直接从数据行读入数据.这时用DATALINES语句替代CARDS语句.
expandtabs 接受tab间隔符,
missover避免换行录入新数据,数据不够,则未录入数据的变量定义为缺失值
libname sasdata 'G:\sasdata';
proc import out=sasdata.sales/*输出的数据集名*/ datafile="G:\sasdata\sales.xls";/*要导入的excel文件的完整路径和数据名,要写清楚扩展名*/
sheet="sheet1";/*指出电子表格中的那一个表单,就是表单名字*/
getnames=yes;/*指出第一行是否有字段名*/
run;
隐含循环
data a ;
put x= y= z= ;
input x y ;
z=x+y ;
put x= y= z= ;
cards ;
10 20
100 200
;
run ;
这个程序的运行流程是这样的:
⑴ DATA语句标志了数据步开始,并指定了数据步结束时要生成的数据集名字为A(实际是WORK.A)。
⑵第一个PUT语句要输出变量X、Y、Z的值,但它们还都没有定义,所以LOG窗口的结果显示为三个缺失值.
⑶下面是INPUT语句,它从CARDS语句后面的数据行中读取变量X的值10,变量Y的值20。
⑷下一个赋值语句计算变量Z的值得到30。因此,LOG窗口中的第二行输出显示三个变量的值分别为10、20、30。
⑸从CARDS语句开始到空语句(;)的各行是非执行的,程序运行到RUN语句,发现这是本数据步的最后一个语句,按一般的程序语言的规则,程序到这里就应该结束了,程序中的第二行数据100 200就不能被读入。
但SAS是一个专用的数据处理语言,所以,这个程序运行到RUN语句后,先把读入的观测(这是第一个观测)写入输出数据集;并继续执行下面步骤。
⑹又返回到DATA语句后的第一个可执行语句开始执行,并先把所有的变量置初值为缺失值.于是,第一个PUT语句的结果显示三个变量均为缺失值,而不是上一步的10、20、30。
⑺下一个INPUT语句从数据行中读入下一个观测,把变量X、Y赋值100、200。读取位置由运行时设置的一个数据指针指示。然后计算变量Z的值得300。
于是PUT语句输出的X、Y、Z值分别为100、200、300。
⑻然后,运行控制跳过CARDS语句到空语句,到数据步结尾,把第二个观测输出到数据集,
⑼再返回到数据步开头,把变量值赋初值为缺失值,所以第一个PUT语句输出的三个变量值为缺失值。
⑽然后运行到INPUT语句,应该读入下一个观测,但是查询数据指针发现已经读完了所有数据,所以本数据步结束,并把两个观测写入数据集WORK.A中。
从这个例子可以看出SAS数据步程序和普通程序的一个重大区别:
SAS数据步如果有数据输入,比如用INPUT、SET、MERGE、UPDATE、MODIFY等语句读入数据,则数据步中隐含了一个循环,即数据步程序执行到最后一个语句后,会返回到数据步内的第一个可执行语句开始继续执行,直到读入数据语句(INPUT、SET、MERGE、UPDATE、MODIFY等)读入了数据结束标志为止才停止执行数据步,并把读入的各个观测写入在DATA语句中指定的数据集内。如果没有数据输入而只是直接计算,则数据步程序不需要此隐含循环。数据步因为有这样一个隐含循环,所以也提供了用来查询某一步是第几次循环的特殊变量_N_,它的值为数据步循环计数值。
输入的格式
INPUT 语句:
INPUT <设定1><. . .设定n > <@|@@>;
设定的格式:
List: 变量名 <$><:输入格式>.
Colunm: 变量名 <$>始列-终列
Formatted: 指针 变量名 输入格式[指针:@n或+n]
Named: 变量名= <$>始列-终列
输入换行控制:
单尾符@:不换行等待下一个Input语句;
双尾符@@: 形成输出记录时输入也不换行.当一数据行含有多个观测时用双尾符控制.
CARDS语句后的数据行或源数据文件中的记录数据间至少有一个空格或特定字符分隔;
数据行的数据只能按顺序输入;
无论是字符型或数值型缺失值必须用点(.)表示;
字符变量的值不能含有空格,长度一般不超过8个字符,开头和结尾的空格将被忽略。
List格式(自由格式)的例子:
data list ;
input name $ sex $ height weight;
cards ;
王永成 男 176 65
李宏志 男 181 78
贺佳 女 162 54
;
优点:使用简单;输入数据时不必上下对齐;不需要知道每个变量的具体列数而只需知道它的次序。
Column(列)格式
data col1 ;
input name $1-6 sex $8-9
height 11-13 weight 15-16 ;
cards ;
王永成 男 176 65
李宏志 男 181 78
贺 佳 女 162 54
;
CARDS语句后的数据行或源数据文件中各变量所在位置必须是有规则的,即数据行各项上下对齐 ;
各数值之间可以没有任何分隔,连续写在一起;
列方式不要求数据项之间分开,所以经常用来输入紧缩格式的数据。比如,数据行为一批身份证号码,但只须读入其中的出生年、月、日信息,就可以用例2。
Formatted格式
data format ;
input name $6. @8 sex $2. +1 height : 3. Weight : 2.;
cards;
王永成 男 176 65
李宏志 男 181 78
贺 佳 女 162 54
;
每个变量按输入格式读入指定的长度;
可用指针控制下一个变量读入的始点;
@n:定位符(第n列);+n:移位符(右移n格)
变量值可含空格(包括头尾空格、单独的小数点);
变量输入次序可以是任意的,任何字段或起部分可重复读入.
如果需要完全原样地输入字符型数据(包括头尾空格、单独的小数点),可以用有格式输入,即在字符型变量名和$符后加上一个输入格式如CHAR10.表示读入10个字符。
有特殊格式的数据需要用有格式输入,即在变量名后加格式名。 其中最常见的是用来输入日期。数据中日期的写法经常是多种多样的,比如1998年10月9日可以写成“1998-10-9 ”,“19981009”,“9/10/98”等等,为读入这样的日期数据就需要为它指定特殊的日期输入格式。另外,日期数据在SAS中是按数值存储的,所以如果要显示日期值,也需要为它指定特殊的日期输出格式。
data for1;
input date yymmdd8. Sales;
format date yymmdd10.;
cards ;
56-6-13 1100
67.12.15 1200
78 10 2 1300
891001 1400
19960101 1500
20020901 1600
;
以上例子程序中数据行的日期数据占据8列位置,如果不满8列要用空格补充,不能让后面的数据进入这8列。
此例可以输入年、月、日之间用减号、小数点、空格分隔的日期,可以输入YYMMDD格式的六位数的日期(一位数的月、日前面补0)。FORMAT语句规定输出日期变量时使用的显示格式YYMMDD10.
如果日期变量不是第一个,则它的前一项最好使用列格式并且指定结束列号为日期值的前一列,或者前一项也使用指定输入格式的输入方法,并且使前一项的输入域宽占满日期前的列。
如果用自由格式则当前一项与日期数据之间间隔超过一个空格时有可能导致日期读入时对不准位置。
如果数据是按列对齐的,还可以在日期变量前加上“@开始列号”说明日期变量开始读取的位置。
input进阶
Retain语句:保留变量当前值,直到被更新。 适用于多类型数据行处理。用retain语句将其中一类数据保留,进而可与其他多类数据行分别合并形成输出为一行观测值。
列指针:#n 读入输入数据缓冲位置的第n行。 适合读入含多种类型被拆分多行的数据行。
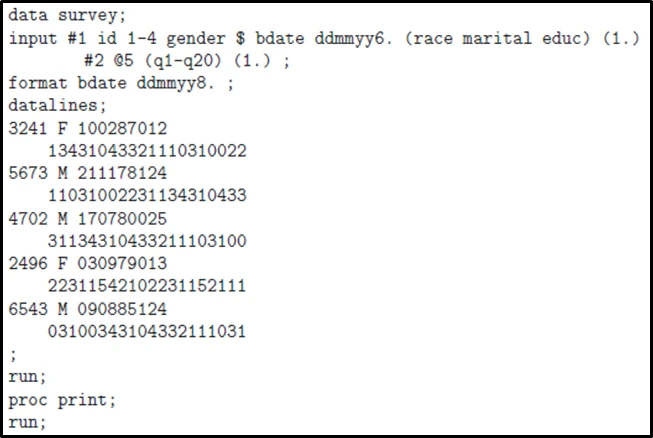
数据集描述
整体描述(contents)
proc contents data=work.class;
run;
数据部分浏览(print)
proc print data=work.Class;
run;
默认( 所有观测、 所有变量、 左侧增加Obs一列)
选项:
NOOBS选项去掉了报告左侧的观测数一列(与print同行)
VAR语句选择报告中显示的变量及顺序
proc print data=work.class noobs;
var Name Height Weight;
run;
二、数据处理
选择观测
比较运算符(in 必须用空格或逗号分隔)
特殊where运算符
BETWEEN-AND运算符 选择变量值落入一个值域内的观测(如果是数值用and连接则左右都包含)。**
IS NULL和IS MISSING运算符 选择变量值是缺失的观测。运算符可用于字符型变量和数值型变量,将NOT 逻辑运算符和IS NULL或IS MISSING合并(is not null),可选择非缺失值。
CONTAINS (?)运算符 选择包含指定的子字符串的观测。变量值中的子字符串的位置不重要,运算符区分大小写
LIKE运算符 通过比较字符值和匹配模式来选择观测。
通过比较字符值和匹配模式来选择观测。
有两个可用于定义模式的特殊字符,称为通配符:
百分号 (%) :任意数量的字符。
下划线 (_) : 代替一个字符。
where Name like '%N';
这个WHERE语句选择的观测以任意数量的字符开始,并以一个N结束。
where Name like 'T_M%';
这个WHERE语句选择的观测以一个T开始,后跟一个单个字符,一个M和任意数量的字符。
注:可以指定连续下划线,百分号和下划线可在同一个模式中使用,运算符区分大小写。
选择观测语句
if
保留
IF expression;
data a;
set old;
if sex=‘F’;
run;
剔除
IF expression THEN DELETE;
data a;
set old;
if sex=‘M’ then delete;
run;
where
在DATA 语句中用 选项WHERE=
在SET 语句中用选项WHERE=
在SET 语句中用 选项FIRSTOBS= 和/ 或OBS=
在DATA步中用where
(1) data new(where=(sex=‘F’));
(2) set old(where=(age>13));
(3) set old(firstobs=6 obs=20) ;
例:
libname saslib ‘路径';
data work.subset1;
set saslib.Admitjune;
where Sex='F' and Age > 40;
keep Name Height Weight
Date ActLevel Fee;
label ActLevel='Action Level'
Name='Full Name';
format Fee comma8.1 Date ddmmyy10.;
run;
proc contents data=work.subset1;
run;
proc print data=work.subset1 label;
run;
选择变量
在DATA 语句中用数据集选项DROP= 和 KEEP=
在SET 语句中用数据集选项DROP= 和 KEEP=
在DATA步中加入 DROP语句和 KEEP语句
例: (1) data new(drop=x y);
(2) set old(keep=x y);
(3) data new;
……
drop x y;
run;
数据集中变量的属性:
必须:
变量名(Name):字母或下划线开始且不超过 32个(V6为8)个字符、数字或下划线构成
类型(Type):数值型、字符型($)
长度(Length):缺省(默认)8字节( <=32767)
可选:
标签(Label): <=256字节
输入格式(Informat): 输入格式名w.d
输出格式(Format): 输出格式名w.d
当展示报告时,
标签Label改变了变量名称的外观。
格式Format改变了变量值的外观
变量的属性包括:
(1) 变量的类型是字符型或数值型,INPUT语句读入字符型数据时在变量名后面必须加$号加以说明;
(2)变量存储长度(LENGTH),数值型变量一般长度为8字节;也可以对取值范围小的变量规定较小的长度以便节省存储空间;字符型变量的长度为该变量值的最大字符个数,缺省时为8个字符。
(3)变量的输入格式(INFORMAT),规定如何把外部数据按一定格式读入后转化为SAS数据。
(4)变量的输出格式(FORMAT),规定按什么样的格式输出SAS的数据值。
(5)变量标签(LABEL),可以给变量附加一个长度不超过40个字符的标签(可以用汉字),这些标签可以使用在以后分析结果的输出中。
以上这些属性在DATA步中可以用ATTRIB语句来规定。在一个ATTRIB语句中可以为多个变量规定属性;也可以为一个变量同时规定多种属性。例如:
data sales;
ATTRIB name LABEL=“姓名” LENGTH=$6
date LABEL=“日期” FORMAT=yymmdd10.
INFORMAT=mmddyy8.
amount LABEL=“金额” FORMAT=10.2 ;
input name $ 1-6 date amount;
cards ;
王永成 10/15/98 17665
李宏志 1/3/1999 18178
贺 佳 11/5/99 16254
;
proc print data=sales noobs label;
run;
数据集标签、变量标签(label)
1.数据集标签:
data a (label=‘my dataset’);
input year sales cost;
cards;
1981 12132 11021
1982 19823 12928
1983 16982 14002
1984 18432 14590
;
2.变量标签:我们可以使用label语句在data step和proc step命名变量标签,二者的区别是前者的标签可以在任何使用该数据集的procedures中使用,而后者仅在当前步有效。
data b;
set a;
label year=”年份”
sales=”销售额”
cost=”价格”;
run;
PROC CONTENTS DATA=b;
RUN;
3.变量值标签:
变量值标签的创建需要两步:
1.用value语句在PROC FORMAT;中创建标签格式
2.把创建的标签格式用FORMAT语句赋给相应的变量,该FORMAT语句可以用在proc or data steps。
PROC FORMAT;
VALUE yearl 1981=“m”
1982=“n”
1983=”o”
1984=”p”
;
字符型变量在定义值标签时,要在标签格式前面加$;
4.在SQL中使用标签
proc sql;
create table tem (
name char(30) format=$30. label=‘姓名’,
sex num format=1. label=‘性别’
);
quit;
变量属性
DATA步中设定变量属性的语句:
LENGTH 变量名 <$>长度 . . . ;
INFORMAT 变量名 输入格式 . . .;
FORMAT 变量名 输出格式 . . .;
LABEL 变量名= 字符串输入格式 . . .;
ATTRIB 变量名 属性 变量名 属性. . . ;
数据格式(format)
format Birth_Date Hire_Date ddmmyy10.
Term_Date monyy7.;
DATA步常用功能
变量属性设定语句,赋值语句, 累加语句
条件语句(IF), 选择语句(SELECT)
循环语句(DO), 数组语句(ARRAY)
转移语句(GOTO), RETAIN语句
PUT语句, OUTPUT语句
赋值语句
累加语句
var +expression ;
var – 累加变量名.
expression--由变量、SAS函数和四则运算
(+, -,*,/,**)构成的表达式.
累加语句将表达式的值累加到累加变量上,下一个等于上一个加上表达式.
例如:
n+1;
sumx+x*x;
ba+(-deb);
RETAIN语句
该语句使得用INPUT或赋值语句指定的变量值当DATA步从当前这次到下一次重复时被保留.如果没有RETAIN语句,SAS系统在DATA步每次重复执行之前,把用INPUT或赋值语句指定的变量设置为缺失值.
累加语句:
n+1;
等价于:
retain n 0/上一个值;
n=n+1;
retain n;
retain var1-var3 (1 2 3);
retain var1-var4(1,2,3,4);
retain;
data a;
retain sum 0;
file print;
put sum= air=;
input air;
sum=sum+air;
put sum= air=;
cards;
112
118
120
130
PUT输出语句
PUT语句在关键字后面列出要输出的各项,每一项可以是变量名或字符串,不能为数值常量或表达式,各项之间用空格分开.PUT语句的输出结果显示在LOG窗口.例如:
data ;
x=0.5; y=sin(x);
put ‘Sin( ’ x ‘)= ’ y ;
run;
结果将在日志窗口显示一行
Sin(0.5)= 0.4794255386
如果在PUT语句中使用“变量名=”来指定输出项可以显示带有变量名的输出结果,比如把上程序中的PUT语句改为
put @10 x= @30 y=;
则结果在LOG窗口从第10列开始显示 X=0.5 从第30列开始显示Y=0.4794255386.
PUT语句的输出项还可以指定具体列位置,比如,下面的PUT语句指定把X数值显示在第10-20列,把Y数值显示在第30-40列,并保留小数点后6位小数:
put x 10-20 .6 y 30-40 .6;
输出占不满指定宽度时,数值型数据向右对齐,字符型数据向左对齐。
如果希望PUT语句的输出不产生换行,使下一个PUT的结果可以显示在同一行,只要在PUT 语句结尾处加一个@符,如:
put i @ ;
PUT语句的输出结果缺省情况下被送到运行记录窗口。在PUT语句之前用FILE语句可以改变PUT语句的输出目的地。比如,在PUT语句之前用file print ;
可以把PUT语句的输出转向到输出窗口
在FILE语句中指定一个包含文件名的字符串可以把PUT语句的输出转向到此文件中。比如
file ‘out.txt’;
把后续的PUT语句输出转向到当前工作目录下的文件“tmp.out”中,生成输出文件tmp.out。
OUTPUT数据集输出语句
如果在DATA步中使用OUTPUT语句,则生成的观测立即写入到OUTPUT语句指定的数据集中.
data normal50;
do k=1 to 50;
x=normal(0);output;
end;
run ;
data a;
set sasuser.class;
ratio=weight/height;
output;
run;
将读入的一条记录写成几个观测
data new(drop=g1-g4);
set stu;
grade=1; gpa=g1; output;
grade=2; gpa=g2; output;
grade=3; gpa=g3; output;
grade=4; gpa=g4; output;
run;
将读入的记录写入不同的SAS数据集中.
data classm classf;
set sasuser.class;
if sex='M’ then output classm;
if sex='F’ then output classf;
run;
if条件语句
(1) if sex=‘F’ then y=100+y;
if upcase(dest)=‘LAX’ then y=x+z;
(2) if sum le 170 then delete;
(3) if upcase(dest)=‘LAX’ then
do;
y=x+z;
city=‘Dallas’;
end;
(4) if x>=0 then x=2*x ;
ELSE x = -x;
select选择语句
SAS的条件语句不提供多分支结构。而SAS的SELECT语句提供了更为灵活的多分支结构,可以实现比其它语言的IF-ELSEIF-ELSE结构更强的功能。
形式一
执行SELECT结构时,先计算出选择表达式和值列表中的所有值,然后把选择表达式值由前向后与值列表中的值相比,发现相等值则执行对应的语句,然后退出SELECT结构(不再查看后面的值列表).如果选择表达式的值不等于任何值列表中的值则执行OTHERWISE对应的语句,这种情况下没有OTHERWISE语句会出错。
形式二
这种SELECT语句没有选择表达式,而是在每一个 WHEN语句指定一个条件(逻辑表达式),执行第一个满足条件的WHEN后的语句。如果所有条件都不满足则执行OTHERWISE后的语句。
(1) SELECT(month);
WHEN(‘Feb’, ‘Mar’, ‘Apr’) put ‘春天’;
WHEN(‘May’, ‘Jun’, ‘Jul’) put ‘夏天’;
OTHERWISE put '秋天或冬天';
END;
(2) SELECT;
WHEN(age<=12) put ‘少年’;
WHEN(age<35) put ‘青年’;
OTHERWISE put ‘中老年’;
END;
循环语句
1、计数标准DO循环
2、当型、直到型循环
计数标准DO循环
data;
DO i = 1 TO 20 BY 2;
j = i**3;
put i 3. j 5.;
END;
run;
可以输出一个1,3,5,7,…,19的立方表。
在循环体中可以用LEAVE语句跳出循环,相当于C语言的break语句。
在循环体内用CONTINUE语句可以立即结束本轮循环并转入下一轮循环的判断与执行。
if j>1000 then LEAVE;
if y<0 then CONTINUE;
指标变量设定的例子:
do i=2 to 10 by 2;
do i=10 to 2 by –2;
do x=3.6 to 4.8 by 0.05;
do n=1, 5, 10, 30, 60;
do n=1, 5 to 10 , 20 , 30 ;
do month=‘JAN’, ’FEB’, ’MAR’;
do z=k to n/10 ;
当型&直到型循环
当型循环
data;
x=1333333;
i=3;
DO WHILE (mod(x,i) ^= 0);
i=i+2;
END;
if i<x then put x= '不是素数';
else put x= '是素数';
run;
当型循环程序判断循环退出条件是否成立,成立则结束循环,否则执行循环体。
直到型
data;
n=0;
do until (n>=5);
n+1; put n=;
end;
run;
可以依次输出n=1,2,3,4,5,当n=5时退出条件“n>=5”满足,循环结束。
此例中语句:n+1;叫做累加语句,等价于 n=n+1;
直到型程序先执行循环体,再判断循环退出条件是否成立,成立则结束循环,否则继续。
注意每轮循环都是先执行循环体再判断是否退出
do计数循环相当于当型循环
do month=1 to 12;
end;
相当于
month=1;
do while month<=12;
month=month+1;
end;
!!!!最后输出的month为13
最后参数保留的一定是不满足while条件的第一个数值
循环语句的一般形式
Data ;
do i=3,7, 11 to 23 by 3 while (i**2<200) ;
j=i**2 ;
put i= j= ;
end;
run;
循环变量i取3,7,11,14循环体被执行,当i取17时i的平方为289<200,故循环体不被执行,循环结束.注意WHILE条件只作用于用逗号隔开的最后一项.
array数组语句
数值型数组
ARRAY tests(3) math chinese english (0,0,0);
比如,上例中tests(1)代表数学成绩math, tests(2)代表语文成绩chinese,tests(3)代表英语成绩english.
初始值表给各数组元素赋初值,按顺序对应。
数组说明中初始值表可以省略,这时其初始值为相应数组元素的值(如果其数组元素还没有值则初值为缺失值)。
ARRAY x(3);
中数组x的各元素名为x1,x2,x3。
也可以在说明维数时用“下标下界:下标上界”来说明一个其它的下标下界,如
ARRAY sales(95:97) yr95-yr97 ;
这时sales(95)为yr95,sales(96)为yr96,sales(97) 为yr97。
上面的变量名列表是一种特殊的语法,在用到变量名列表时如果连续写几个前面字母相同,后面是连续的序号的变量,只要写出第一个和最后一个,中间用减号连接。
ARRAY tests(*) math chinese english (0, 0, 0);
一维数组的维数说明还可以是一个星号,这时数组大小由提供的元素列表中的变量个数决定
可以用函数DIM(数组名)来获得数组的长度。
可以定义二维数值型数组,只要在维数说明中指定用逗号分开的两个下标界说明,二维数组元素的顺序按行排列。
例如: array table(2,2) x11 x12 x21 x22;
说明table(1,1)为x11,table(1,2)为x12,table(2,1)为x21,table(2,2)为x22。
字符型数组
定义字符型数组的语法略复杂,它需要加一个$符来说明数组元素类型为字符型,并且要说明每一元素所能存储的字符串的最大长度.说明格式如下:
ARRAY 数组名(维数说明) $ 元素长度说明
数组元素名列表 (初始值表);
例如:
ARRAY names(3) $ 10 child father mother;
字符型数组其它方面的用法与数值型相同。
临时数组
数组元素只由数组名和序号决定,没有对应变量名
定义格式:
ARRAY 数组名(维数说明)_TEMPORARY_(初始值表);
可见临时数组就是在数组说明中用_TEMPORARY_代替了数组元素列表。
例如:
ARRAY x(3) TEMPORARY (0, 0, 0);
说明了一个有三个元素的临时数组x。其元素为x(1),x(2),x(3),即使变量x1,x2,x3 存在也与此数组无关。临时数组的特点是它只用于中间计算,最终不被写入数据集。并且临时数组与其它变量不同的是, 它在数据步隐含循环(后面会解释此概念)中能自动保留上一步得到的值。 临时数组当然也可以有多维数组,或字符型数组。
用新的数组代替原有两个数组进行求和
data sales;
input comp1-comp10 prin1-prin6 ;
ARRAY y(*) comp1-comp10 prin1-prin6;
tot=0 ;
do i=1 to DIM(y);
tot + y(i);
end ;
cards ;
………
run;
事实上,在数组说明的数组元素列表部分除了列出具体的变量名表外,还可以用特殊名字_NUMERIC_代表所有数值型变量的列表,用_CHARACTER_代表所有字符型变量的列表,用_ALL_代表所有变量的列表(用_ALL_ 时所有变量应该同为数值型或同为字符型,否则出错)。所以上例中的数组y的说明中还可以用_NUMERIC_或_ALL_代替变量名列表。如:
ARRAY y(*) _NUMERIC_;
ARRAY y(*) _ALL_ ;
实际上,SAS为变量累加提供了一个专门的函数***SUM(OF …),比如上面的tot变量可以用
SUM(OF comp1-comp12 prin1-prin6)
数组重组
(转置)
Data quizzes;
Input name $ quiz1-quiz5;
Array qz(5) quiz1-quiz5;
Drop quiz1-quiz5;
Do test=1 to 5;
if qz(test)=. Then qz(test)=0;
score = qz(test);
output;
End;
Datalines;
Smith 8 7 9 . 3
Jones 4 5 10 8 4
;
Run;
Proc print data=quizzes;
Run;
(合并)
串接(set)
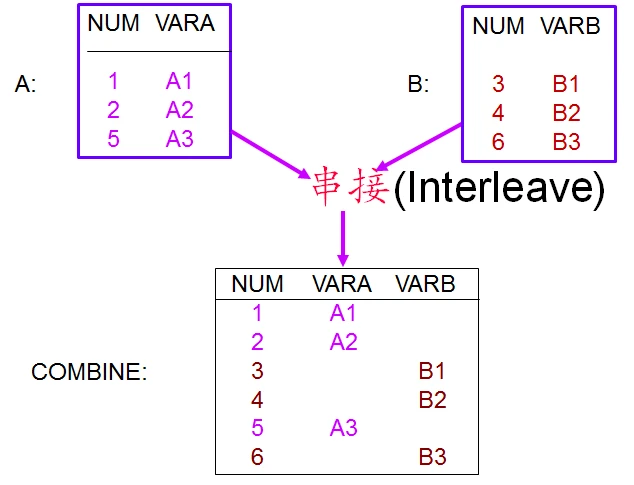
DATA SAS-data-set ;
SET SAS-data-set1
SAS-data-set2 . . . ;
BY Variables;
其它SAS语句;
RUN;
用插入式串接时要求这几个数据集已按by变量排好序.如果还没有排好序,必须先用SORT过程排序.
PROC SORT DATA=SAS-dat-set1
OUT=SAS-dat-set2;
BY by-variables;
RUN;
并接(merge)
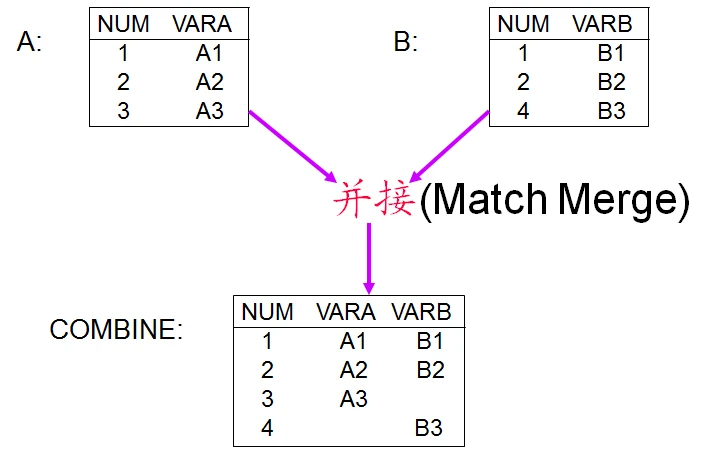
DATA SAS-data-set;
MERGE SAS-data-set1 SAS-data-set2;
BY by-variables;
其它SAS语句;
RUN:
在DATA步中使用SET语句读入多个数据集,除Keep,Drop等一些选项外,
还可用选项 IN=来检测记录取自哪个数据集。
一般用法:SET … 数据集k(IN=vark) … ;
这时在PDV(程序数据向量)中产生内部变量k:
vark =1, 当记录来自数据集k ,
vark =0, 当记录来自其它数据集。
data combine;
set a(in=ina) b(in=inb);
run;
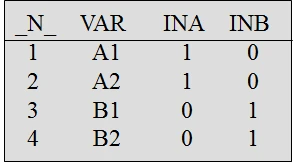
例1:合并后保留两个数据集都有数据的观测.
DATA COMBINE1;
merge A(in=ia) B(in=ib);
by num;
if ia=1 and ib=1; /* 或 if ia and ib; */
run;
例2:合并后只保留第一个数据集中的观测.
DATA COMBINE2;
merge A(in=ia) B(in=ib);
by num;
if ia ; /* 或 if ia=1; */
run;
例3:临时变量FIRST.var 和LAST.var.
在DATA步,SAS系统对每个BY组生成两个临时变量FIRST.var 和LAST.var,用于区分每个BY各组中的第一个观测和最后一个观测.这两个临时变量对DATA步编程是很有用的.
DATA COMB(drop=qtr sales);
merge mma(in=ia) mmb(in=ib);
by num;
if ia=1 and ib=1;
if first.num then salesum=0;
salesum+sales;
if last.num=1;
run;
*** 空值也可以比较,但都为否。
***retain只能保留到该数变化之前,如果变化后未接retain,则该数仍会变化。
*** 数值型和字符型变量转换函数:input(字符变量,格式),put(数值变量,格式)
***sum在计算的时候无论是否有缺失值都可以输出数据,而直接加和如果有缺失值则无法输出数据