
关于Fortigate HA的配置在一本通里逻辑及配置已经阐述的很详细了,本文主要记录近期的一次HA的Out Of Sync的配置及相关排错,作为分享
Fortigate HA重要概念
首先是HA配置的基本要求:
- 两台防火墙硬件同型号
- 两台防火墙软件同版本(包括小型号)
- 所有接口不可有DHCP或PPPOE
然后是HA的两大模式A-A和A-P模式,官方描述如下:
Active-Passive(A-P)模式
集群中的所有防火墙必须工作在同一个模式下。可以对运行中的HA集群进行模式的修改,但会造成一定的延时,因为集群需要重新协商并选取新的主设备。A-P模式提供了备机保护。HA集群中由一台主设备,和一台以上到从设备组成。
从设备与主设备一样连接到网络,但不处理任何的数据包,从设备处于备用状态。从设备会自动同步主设备的配置,并时刻监视主设备到运行状态。整个失效保护的过程是透明的,一旦主设备失效,从设备会自动接替其工作。如果设备的接口或链路出现故障,集群内会更新链路状态数据库,重新选举新的主设备。
Active-Active(A-A)模式
A-A模式下会对占用资源较多的进程进行在各个设备中进行分担。需要处理协议识别、病毒扫描、ips、网页过滤、邮件过滤、数据防泄露、应用程序控制、voip内容扫描、协议保护, SCCP协议控制等。通过对如上内容的负载均担,A-A模式可以提供更高的UTM性能。安全策略中的终端控制,流控,用户认证功能,在A-A模式下没有什么提高效果。其他非UTM功能不会进行负载分担,将由主设备进行处理。除了UTM功能外,还可以实现对TCP会话进行分担。
以个人经验来讲,开启会话同步的场景下,AP和AA情况下HA灾备切换造成的网络中断基本没差别,A-A的优势在于性能的负载,尤其当单台设备的UTM等处理能力不够时,A-A在既能保证高可用的情况下又能解决单台的成本,但会增加运维风险和成本,在绝大多数的场景中,建议使用A-P方式部署HA
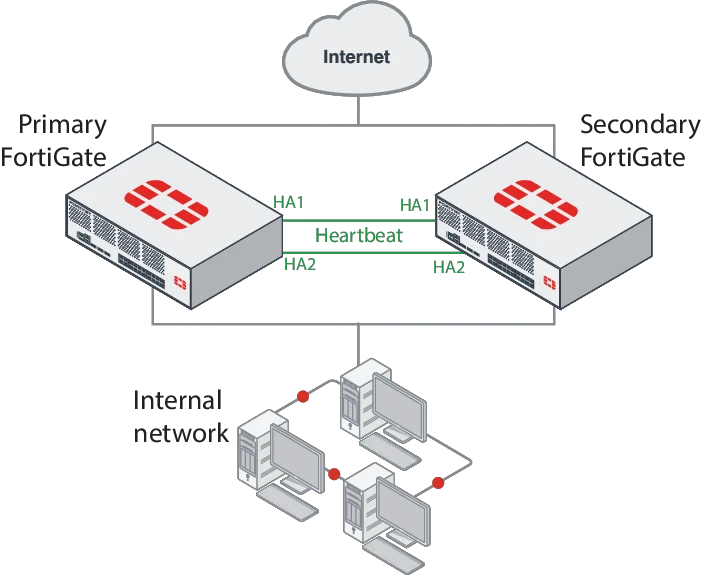
然后另一个重要概念是HA的选举机制,按照以下逻辑进行主备选举:
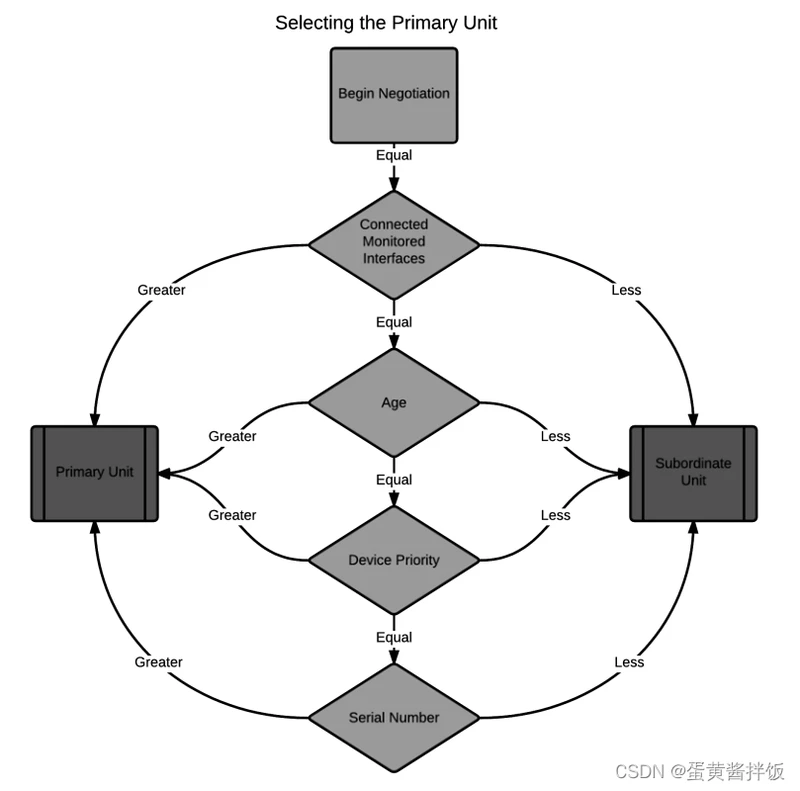
- 连接的接口数,接口数多的选为主设备,这个很好理解,很多HA场景中限于上行下行的网络原因无法做到完整的双线路,仅一台接线,HA仅用于配置同步,这种情况下自然接线的那台就会选为主设备
- 开机时间,开机时间越长约容易选为主设备
- 设备系统内手动定义的优先级,优先级越大的选为主设备
- 当以上三项都相同的情况下(基本不可能碰到),对比两台设备的序列号,较大的序列号选为主设备
Fortigate HA设计及配置
WebUI里配置HA比较简单,首先两台防火墙先不连接HA线单独进行配置
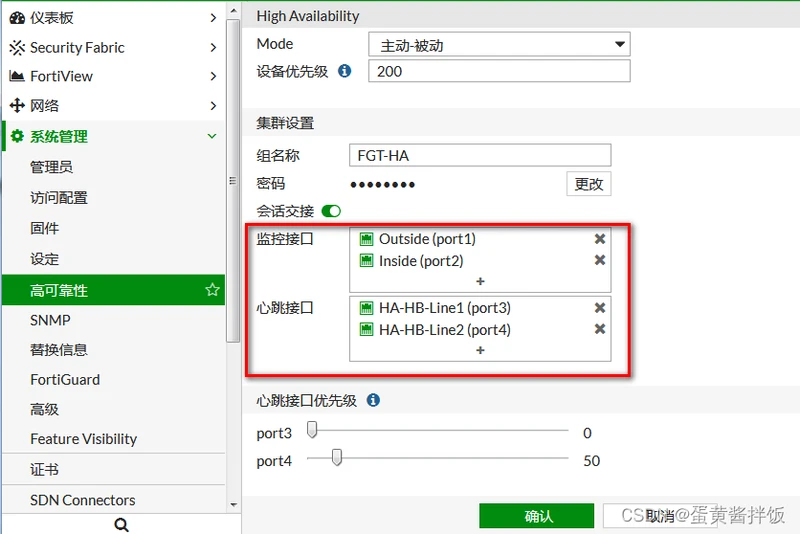
- 系统管理-高可靠性里开启主动-被动模式
- 设置组名称,组密码(两台一致)
- 选择对应的监控接口(一般选择使用中端口,主备选举最优先的接口选举看的就是这边的监控接口)
- 选择心跳接口(建议使用两条,一些型号直接有HA1,HA2接口),配置心跳接口优先级
配置完成后两台防火墙连接HA线,设备开始自动选举,顺利完成后可看到状态
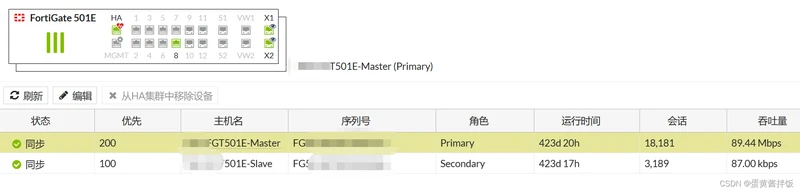
其他配置HA注意事项:
- 开始配置前记得备份配置!
- 会话同步开启
- HA建议至少连接两路,最好能使用SFP接口
- 建议去命令行确认下Override是否开启,这个建议关闭,开启的情况下HA的选举参数发生变更会导致主备自动切换,慎用!
Out Of Sync问题排错
当然在很多情况下,HA配置并不一定会那么顺利,有些情况下状态会显示未同步,这时候我们就需要去CLI进行下排错
首先可先尝试下手动重新同步
Prim-FW (global) # execute ha synchronize start
看下HA的状态,如果有out-of-sync的状态就是有问题
Prim-FW (global) # get sys ha status
HA Health Status: OK
Model: FortiGate-VM64-KVM
Mode: HA A-P
Group: 9
Debug: 0
Cluster Uptime: 14 days 5:9:44
Cluster state change time: 2019-06-13 14:21:15
Master selected using:
<date:02> FGVMXXXXXXXXXX44 is selected as the master because it has the largest value of uptime. <--- this is the reason for last failover
<date:01> FGVMXXXXXXXXXX46 is selected as the master because it has the largest value of uptime.
<date:00> FGVMXXXXXXXXXX44 is selected as the master because it has the largest value of override priority.
ses_pickup: enable, ses_pickup_delay=disable
override: disable
Configuration Status:
FGVMXXXXXXXXXX44(updated 3 seconds ago): in-sync
FGVMXXXXXXXXXX46(updated 4 seconds ago): in-sync
System Usage stats:
FGVMXXXXXXXXXX44(updated 3 seconds ago):
sessions=42, average-cpu-user/nice/system/idle=0%/0%/0%/100%, memory=64%
FGVMXXXXXXXXXX46(updated 4 seconds ago):
sessions=5, average-cpu-user/nice/system/idle=0%/0%/0%/100%, memory=54%
HBDEV stats:
FGVMXXXXXXXXXX44(updated 3 seconds ago):
port8: physical/10000full, up, rx-bytes/packets/dropped/errors=2233369747/7606667/0/0, tx=3377368072/8036284/0/0
FGVMXXXXXXXXXX46(updated 4 seconds ago):
port8: physical/10000full, up, rx-bytes/packets/dropped/errors=3377712830/8038866/0/0, tx=2233022661/7604078/0/0
MONDEV stats:
FGVMXXXXXXXXXX44(updated 3 seconds ago):
port1: physical/10000full, up, rx-bytes/packets/dropped/errors=1140991879/3582047/0/0, tx=319625288/2631960/0/0
FGVMXXXXXXXXXX46(updated 4 seconds ago):
port1: physical/10000full, up, rx-bytes/packets/dropped/errors=99183156/1638504/0/0, tx=266853/1225/0/0
Master: Prim-FW , FGVMXXXXXXXXXX44, cluster index = 1
Slave : Bkup-Fw , FGVMXXXXXXXXXX46, cluster index = 0
number of vcluster: 1
vcluster 1: work 169.254.0.2
Master: FGVMXXXXXXXXXX44, operating cluster index = 0
Slave : FGVMXXXXXXXXXX46, operating cluster index = 1
对比两台防火墙所有vdom的checksum,确认下是哪个vdom有配置不一致的情况
Prim-FW(global)# diag sys ha checksum cluster
================== FGVMXXXXXXXXXX44 ==================
is_manage_master()=1, is_root_master()=1
debugzone
global: c5 33 93 23 26 9f 4d 79 ed 5f 29 fa 7a 8c c9 10
root: d3 b5 fc 60 f3 f0 f0 d0 ea e4 a1 7f 1d 17 05 fc
Cust-A: 84 af 8f 23 b5 31 ca 32 c1 0b f2 76 d2 57 d1 aa
all: 04 ae 37 7e dc 84 aa a4 42 3d db 3c a2 09 b0 g5
checksum
global: c5 33 93 23 26 9f 4d 79 ed 5f 29 fa 7a 8c c9 10
root: d3 b5 fc 60 f3 f0 f0 d0 ea e4 a1 7f 1d 17 05 fc
Cust-A: 84 af 8f 23 b5 31 ca 32 c1 0b f2 76 d2 57 d1 aa
all: 04 ae 37 7e dc 84 aa a4 42 3d db 3c a2 09 b0 g5
================== FGVMXXXXXXXXXX46 ==================
is_manage_master()=0, is_root_master()=0
debugzone
global: c5 33 93 23 26 9f 4d 79 ed 5f 29 fa 7a 8c c9 10
root: d3 b5 fc 60 f3 f0 f0 d0 ea e4 a1 7f 1d 17 05 fc
Cust-A: 84 af 8f 23 b5 31 ca 32 c1 0b f2 76 d2 57 d1 bc
all: 04 ae 37 7e dc 84 aa a4 42 3d db 3c a2 09 b0 60
checksum
global: c5 33 93 23 26 9f 4d 79 ed 5f 29 fa 7a 8c c9 10
root: d3 b5 fc 60 f3 f0 f0 d0 ea e4 a1 7f 1d 17 05 fc
Cust-A: 84 af 8f 23 b5 31 ca 32 c1 0b f2 76 d2 57 d1 bc
all: 04 ae 37 7e dc 84 aa a4 42 3d db 3c a2 09 b0 60
两台防火墙上分别把不一样的vdom的checksum拉出来
Prim-FW (global) # diag sys ha checksum show Cust-A
可用工具进行比对,如果有不一样的checksum的项,手动去配置里确认下,我以下只是修改了不一样做的示例,实际场景中完全一致
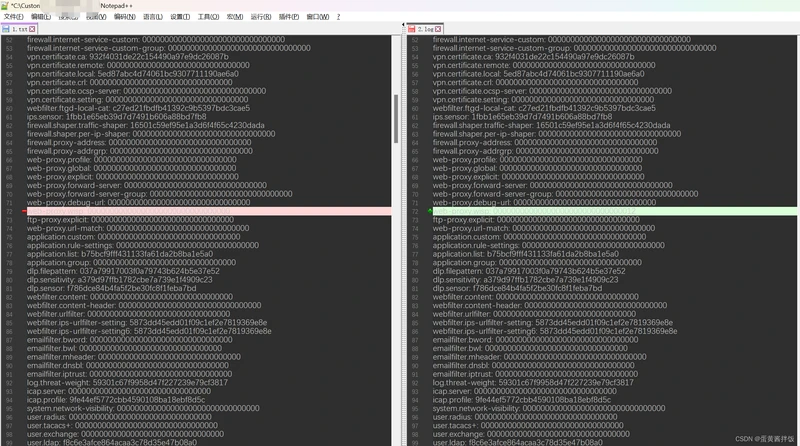
确定两边所有vdom的checksum都一致后进行checksum的重新计算
Prim-FW (global) # diagnose sys ha checksum recalculate
这个就是碰到的最大的坑,因为配置比对完全一致也从未变更过,也没想到去recalculate,最后跑了一下就ok了
后来跟一个400的哥们确认了下,这个算是bug,HA的recalculate在没有配置变更的情况下不会触发,这种情况要么手动跑一边recalculate,要么在防火墙里手动增删一条配置就ok