一、什么是数据湖?
在探讨数据湖技术或如何构建数据湖之前,我们需要先明确,什么是数据湖?
数据湖的起源,应该追溯到2010年10月。基于对半结构化、非结构化存储的需求,同时为了推广自家的Pentaho产品以及Hadoop,2010年Pentaho的创始人兼CTO James Dixon首次提出了数据湖的概念。
数据湖概念一经提出,便受到了广泛关注,人们发现此概念代表了一种新的数据存储理念,海量异构数据统一存储可以很好地解决企业数据孤岛问题,方便企业数据管理与应用。
「技术概念的提出,本质都是为了业务场景服务的,是为解决某类特定场景的问题。」
随着新一代信息技术的发展,以及数字化转型的深入推进,数据作为一种“无形资产”的重要性变得比以往更为凸显。物联网、直播、医疗等各种业务场景每天都会生成几GB、几百GB,甚至TB级的原始数据。面对海量数据的存储以及结构化数据、文本、二进制(图片、音频、视频)等数据的存储应用,传统架构的离线数据仓库越来越“力不从心”。
与此同时,随着大数据技术的融合发展,数据湖不断演变,当前我们所讨论的数据湖,已经远远超过了当初 James Dixon 所定义的数据湖。
根据维基的定义,数据湖是一个以原始格式(通常是对象块或文件)存储数的系统或存储库。数据湖通常是所有企业数据的单一存储,用于报告、可视化、高级分析和机器学习等任务。数据湖可以包括来自关系数据库的结构化数据(行和列)、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、pdf)和二进制数据(图像、音频、视频)。

二、袋鼠云数据湖平台
数字经济时代,如何有效利用不同来源、规模巨大的数据,从而加快数据价值化的呈现,把数据用活,成为很多企业的难题。
袋鼠云首发数据湖平台——DataLake。
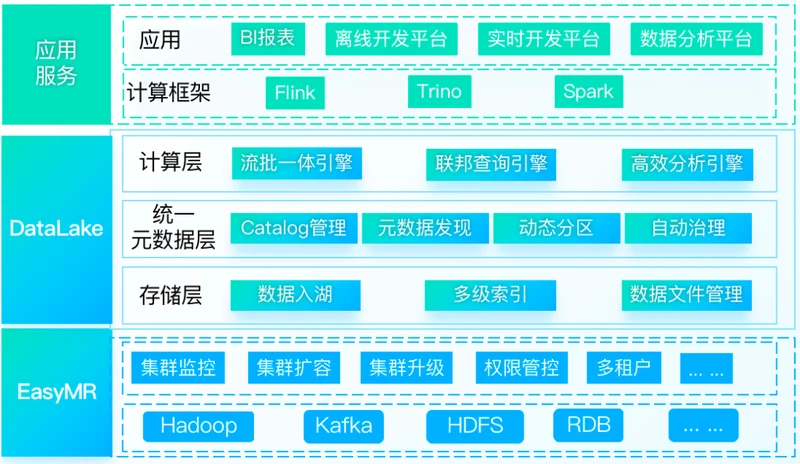
DataLake, 提供面向湖仓一体的数据湖管理分析服务,基于统一的元数据抽象构建一致性的数据访问,提供海量数据的存储管理和实时分析处理能力,可以帮助企业快速构建湖仓一体化平台,完成数字化基础建设。
DataLake让业务响应更加及时,让企业运转更加高效。
三、DataLake的核心特性
下文为大家着重介绍DataLake的核心特性:
1.高效数据入湖
通过⾃研批流⼀体数据集成框架ChunJun,可视化的任务配置,将外部数据高效入湖,让数据具备更高的新鲜度。同时也可对已有表hive结构进行快速扫描,一键生成湖表信息,节省10x倍数据的传输时间和50%磁盘空间。
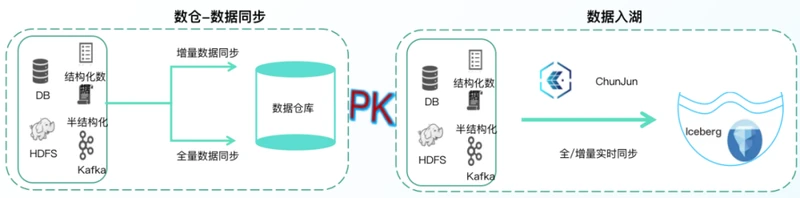
• 引入ChunJun,提供数据同步效率实现秒级快速入湖
• 全数据同步量/增量一体化,链路短组件少开发维护成本低
• 不影响在线业务的稳定
2.统一元数据管理
支持物理表、虚拟元数据的统一管理,支持表结构变更、时间旅行、数据文件自动治理能力。
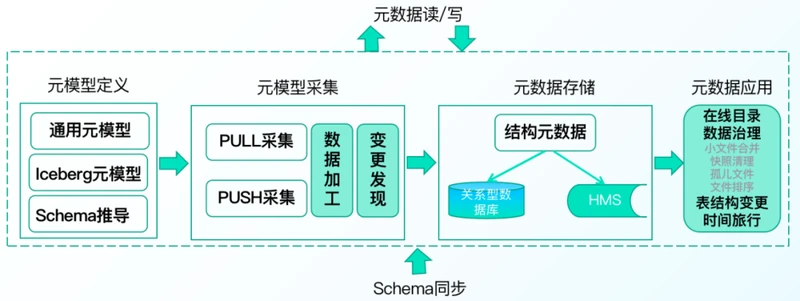
袋鼠云数据湖DataLake提供统一的在线数据目录和离线数据治理能力,主要由以下四个部分构成:
• 元模型定义:是对元数据的抽象描述,定义了通用元模型和Iceberg元模型
• 元数据采集:支持基于PULL定时拉取和PUSH主动上报的两种方式采集元数据,保证元数据的实时同步
• 元数据存储:根据不同元数据的数据结构和用途,形成以Hive Metastore为主,关系型数据库为辅的存储架构
• 元数据应用:提供线数据目录和离线数据治理能力。在线数据目录可为数据湖的计算引擎提供Schema管理功能;离线数据治理包括,小文件合并、快照清理、孤儿文件清理能治理能力,可以有效降低数据存储提高数据查询效率。同时还支持表结构变更、时间旅行的能力,可以快速对湖表进行加列改列删列,而数据无需重写,支持对数据和Schema进行版本管理一键回滚
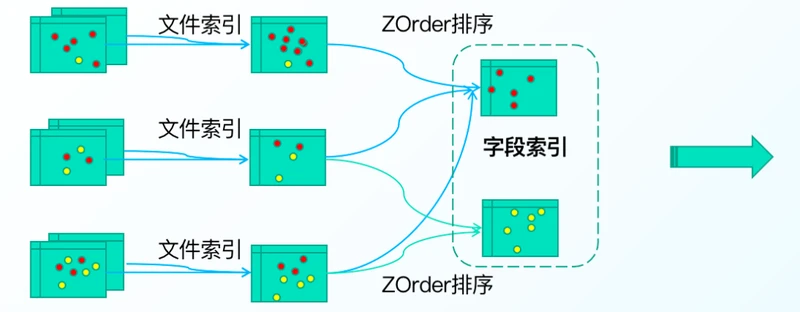
3.多级索引加速
高效Data Skipping方案,支持多种索引模式,如bloom index,data skipping index ……
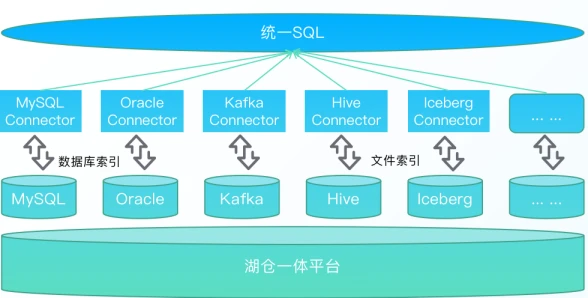
4.高性能联邦查询
内置多种数据连接器,并在开源基础上提供更高效的索引结构,极大提高了数据的跨源联合分析查询能力,可快速完成各类分析需求,带来极致的交互式数据分析体验。
支持MySQL、Oracle、Hive、Iceberg、ClickHouse、MongoDB等30+异构数据源连接器,满足市场95%客户需求。进行Connector整合统一SQL,对外提供标准数据API服务,极大简化用户多数据源数据查询的复杂度,一个标准接口可以同时查询30+数据库。
5.事务支持
支持所有ACID语义,T+0数据更新。
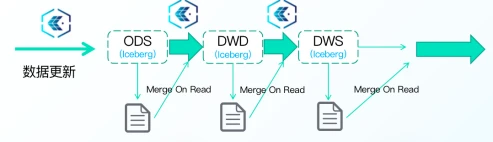
• 基于Iceberg架构数据湖支持Merge On Read模式,数据实际应用时进行Merge操作,可以支持近实时的数据导入和实时数据读取
• 支持ACID,保证了多任务数据同步的写入和查询的隔离性,不会产生脏数据
• 支持行级别快速数据更新,极大提高数据更新效率
6.流批一体
基于数据存储层的统一逻辑,支持流和批的一体化分析,一套架构同时满足流批业务操作,降低学习、使用、维护成本。
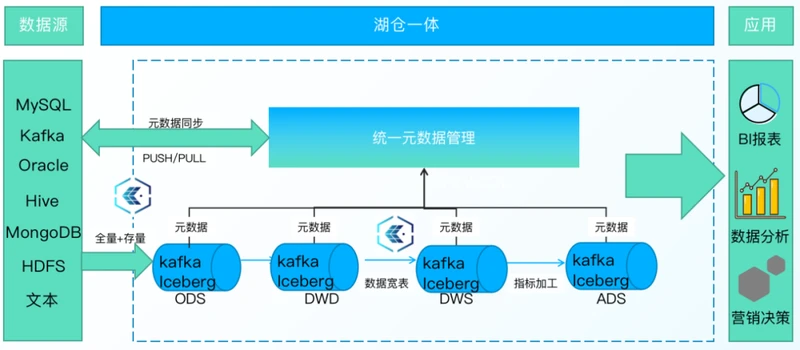
异构数据源数据通过ChunJun同步到数据湖平台,历史数据存储Iceberg湖内,可以提供更高效的查询同时具备廉价存储。增量数据运用消息队列提供低延时的写入和消费能力,存储于kafka,同时kafka内数据自动同步到Iceberg内,并记录kafka偏移,以保证数据一致性。
数据进行流式消费时,湖内会自动根据数据读取情况判断读取Kafka 还是 Iceberg 内数据,系统进行自动切换,以实现秒级毫秒级的数据实时查询。
7.多种底层存储
湖仓平台支持HDFS、S3、OSS、MInio等多种底层存储,灵活满足客户不同数据存储需求。
四、一起体验DataLake
结合这些核心特性,接下来一起玩转袋鼠云数据湖平台DataLake吧~
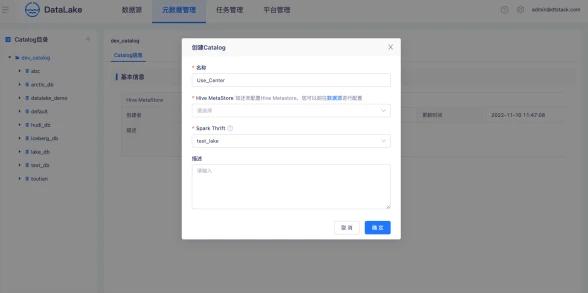
创建CalaLog
首先创建一个Calalog,一个Calalog只允许绑定一个Hive MetaStore,Calalog与Hive MetaStore是一一对应,用户可以使用Calalog进行业务部门数据隔离。
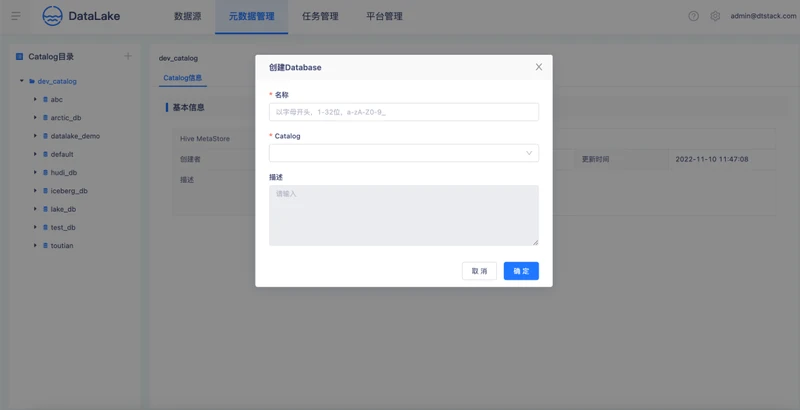
创建Database
创建一个Database绑定到Calalog上。
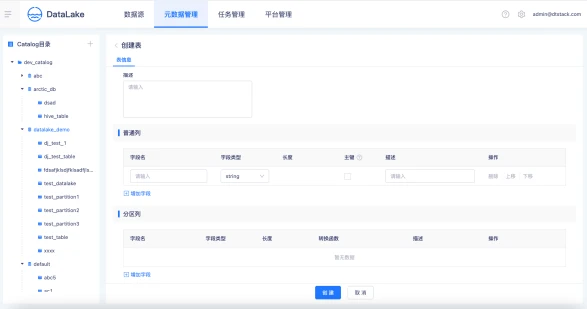
创建一张Table
选择Table所在的Catalog、Database,创建一张Iceberg湖表,设置表普通列。支持对普通列字段设置主键,可以用作表的唯一标识。
选择普通列字段作为分区字段,设置分区字段的转换函数,袋鼠云数据湖平台支持时间字段按照年、月、日和小时粒度划分区,支持行组级索引设置和自定义高级参数设置。
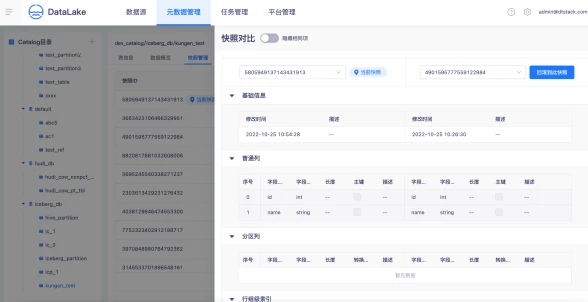
快照管理
袋鼠云数据湖平台支持快照历史管理,支持多版本间快照变更对比,支持湖表时间旅行,一键回滚到指定数据版本。
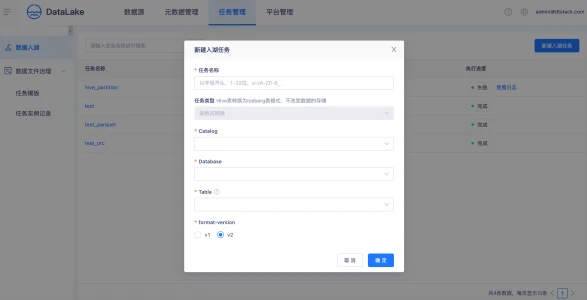
数据入湖
创建入湖任务,选择一张Hive进行转表入湖,一键生成湖表信息。对比数据同步入湖,可以节省10x倍数据的传输时间。
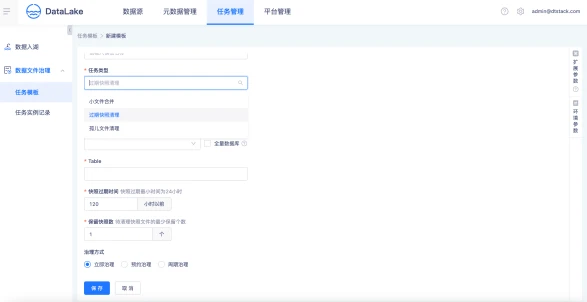
数据文件治理
创建数据文件治理任务模板,支持小文件合并、快照清理、孤儿文件清理等数据文件治理任务,支持立即支持、预约治理、周期治理多种数据治理方式。