
唠嗑
不同平台上的我表现出来的是不同的样子,但是无论表现的是什么样子,我都知道她们都属于真正的我。最近又开始被一件事情影响到了,不过要趁着假期彻底解决这件事情了。emmm…貌似有点困难hhh
0. 快速上手指南
本次实验需要在 Lab1 已完成的 flex 词法分析器的基础上,进一步使用 bison 完成语法分析器。
主要工作
1.了解 bison 基础知识和理解 Cminus-f 语法(重在了解如何将文法产生式转换为 bison 语句)
2。阅读 /src/common/SyntaxTree.c,对应头文件 /include/SyntaxTree.h(重在理解分析树如何生成)
3.了解 bison 与 flex 之间是如何协同工作,看懂pass_node函数并改写 Lab1 代码(提示:了解 yylval 是如何工作,在代码层面上如何将值传给$1、$2等)
4.补全 src/parser/syntax_analyzer.y 文件和 lexical_analyzer.l 文件
Tips:在未编译的代码文件中是无法看到关于协同工作部分的代码,建议先编译 1.3 给出的计算器样例代码,再阅读 /build/src/parser/ 中的 syntax_analyzer.h 与 syntax_analyzer.c 文件
思考题
本部分不算做实验分,出题的本意在于想要帮助同学们加深对实验细节的理解,欢迎有兴趣和余力的同学在报告中写下你的思考答案,或者在issue中分享出你的看法。
1.在1.3样例代码中存在左递归文法,为什么 bison 可以处理?(提示:不用研究bison内部运作机制,在下面知识介绍中有提到 bison 的一种属性,请结合课内知识思考)
2.请在代码层面上简述下 yylval 是怎么完成协同工作的。(提示:无需研究原理,只分析维护了什么数据结构,该数据结构是怎么和$1、$2等联系起来?)
3.请尝试使用1.3样例代码运行除法运算除数为0的例子(测试case中有)看下是否可以通过,如果不,为什么我们在case中把该例子认为是合法的?(请从语法与语义上简单思考)
4.能否尝试修改下1.3计算器文法,使得它支持除数0规避功能。
1. 基础知识
我们在这里简单介绍如何让 bison 和 flex 协同工作及其原理,并简单介绍 bison 的一些基础知识。
1.1 Cminus-f 语法
本小节将给出Cminus-f的语法,该语法在Cminus语言的基础上增加了float类型。
Cminus的详情请参考《编译原理与实践》第九章附录。
我们将 Cminus-f 的所有规则分为五类。
1.字面量、关键字、运算符与标识符
id
type-specifier
relop
addop
mulop
2.声明
declaration-list
declaration
var-declaration
fun-declaration
local-declarations
3.语句
compound-stmt
statement-list
statement
expression-stmt
iteration-stmt
selection-stmt
return-stmt
4.表达式
expression
var
additive-expression
term
factor
integer
float
call
5.其他
params
param-list
param
args
arg-list
起始符号是 program。
Cminus-f语法
$\text{program} \rightarrow \text{declaration-list}$
$\text{declaration-list} \rightarrow \text{declaration-list}\ \text{declaration}\ |\ \text{declaration}$
$\text{declaration} \rightarrow \text{var-declaration}\ |\ \text{fun-declaration}$
$\text{var-declaration}\ \rightarrow \text{type-specifier}\ \textbf{ID}\ \textbf{;}\ |\ \text{type-specifier}\ \textbf{ID}\ \textbf{[}\ \textbf{INTEGER}\ \textbf{]}\ \textbf{;}$
$\text{type-specifier} \rightarrow \textbf{int}\ |\ \textbf{float}\ |\ \textbf{void}$
$\text{fun-declaration} \rightarrow \text{type-specifier}\ \textbf{ID}\ \textbf{(}\ \text{params}\ \textbf{)}\ \text{compound-stmt}$
$\text{params} \rightarrow \text{param-list}\ |\ \textbf{void}$
$\text{param-list} \rightarrow \text{param-list}\ ,\ \text{param}\ |\ \text{param}$
$\text{param} \rightarrow \text{type-specifier}\ \textbf{ID}\ |\ \text{type-specifier}\ \textbf{ID}\ \textbf{[]}$
$\text{compound-stmt} \rightarrow \textbf{\{}\ \text{local-declarations}\ \text{statement-list} \textbf{\}}$
$\text{local-declarations} \rightarrow \text{local-declarations var-declaration}\ |\ \text{empty}$
$\text{statement-list} \rightarrow \text{statement-list}\ \text{statement}\ |\ \text{empty}$
$\begin{aligned}\text{statement} \rightarrow\ &\text{expression-stmt}\\ &|\ \text{compound-stmt}\\ &|\ \text{selection-stmt}\\ &|\ \text{iteration-stmt}\\ &|\ \text{return-stmt}\end{aligned}$
$\text{expression-stmt} \rightarrow \text{expression}\ \textbf{;}\ |\ \textbf{;}$
$\begin{aligned}\text{selection-stmt} \rightarrow\ &\textbf{if}\ \textbf{(}\ \text{expression}\ \textbf{)}\ \text{statement}\\ &|\ \textbf{if}\ \textbf{(}\ \text{expression}\ \textbf{)}\ \text{statement}\ \textbf{else}\ \text{statement}\end{aligned}$
$\text{iteration-stmt} \rightarrow \textbf{while}\ \textbf{(}\ \text{expression}\ \textbf{)}\ \text{statement}$
$\text{return-stmt} \rightarrow \textbf{return}\ \textbf{;}\ |\ \textbf{return}\ \text{expression}\ \textbf{;}$
$\text{expression} \rightarrow \text{var}\ \textbf{=}\ \text{expression}\ |\ \text{simple-expression}$
$\text{var} \rightarrow \textbf{ID}\ |\ \textbf{ID}\ \textbf{[}\ \text{expression} \textbf{]}$
$\text{simple-expression} \rightarrow \text{additive-expression}\ \text{relop}\ \text{additive-expression}\ |\ \text{additive-expression}$
$\text{relop}\ \rightarrow \textbf{<=}\ |\ \textbf{<}\ |\ \textbf{>}\ |\ \textbf{>=}\ |\ \textbf{==}\ |\ \textbf{!=}$
$\text{additive-expression} \rightarrow \text{additive-expression}\ \text{addop}\ \text{term}\ |\ \text{term}$
$\text{addop} \rightarrow \textbf{+}\ |\ \textbf{-}$
$\text{term} \rightarrow \text{term}\ \text{mulop}\ \text{factor}\ |\ \text{factor}$
$\text{mulop} \rightarrow \textbf{*}\ |\ \textbf{/}$
$\text{factor} \rightarrow \textbf{(}\ \text{expression}\ \textbf{)}\ |\ \text{var}\ |\ \text{call}\ |\ \text{integer}\ |\ \text{float}$
$\text{integer} \rightarrow \textbf{INTEGER}$
$\text{float} \rightarrow \textbf{FLOATPOINT}$
$\text{call} \rightarrow \textbf{ID}\ \textbf{(}\ \text{args} \textbf{)}$
$\text{args} \rightarrow \text{arg-list}\ |\ \text{empty}$
$\text{arg-list} \rightarrow \text{arg-list}\ \textbf{,}\ \text{expression}\ |\ \text{expression}$
1.2 Bison 简介
Bison 是一款解析器生成器(parser generator),它可以将 LALR 文法转换成可编译的 C 代码,从而大大减轻程序员手动设计解析器的负担。Bison 是 GNU 对早期 Unix 的 Yacc 工具的一个重新实现,所以文件扩展名为 .y。(Yacc 的意思是 Yet Another Compiler Compiler。)
每个 Bison 文件由 %% 分成三部分。
%{
#include <stdio.h>
/* 这里是序曲 */
/* 这部分代码会被原样拷贝到生成的 .c 文件的开头 */
int yylex(void);
void yyerror(const char *s);
%}
/* 这些地方可以输入一些 bison 指令 */
/* 比如用 %start 指令指定起始符号,用 %token 定义一个 token */
%start reimu
%token REIMU
%%
/* 从这里开始,下面是解析规则 */
reimu : marisa { /* 这里写与该规则对应的处理代码 */ puts("rule1"); }
| REIMU { /* 这里写与该规则对应的处理代码 */ puts("rule2"); }
; /* 规则最后不要忘了用分号结束哦~ */
/* 这种写法表示 ε —— 空输入 */
marisa : { puts("Hello!"); }
%%
/* 这里是尾声 */
/* 这部分代码会被原样拷贝到生成的 .c 文件的末尾 */
int yylex(void)
{
int c = getchar(); // 从 stdin 获取下一个字符
switch (c) {
case EOF: return YYEOF;
case 'R': return REIMU;
default: return 0; // 返回无效 token 值,迫使 bison 报错
}
}
void yyerror(const char *s)
{
fprintf(stderr, "%s\n", s);
}
int main(void)
{
yyparse(); // 启动解析
return 0;
}
另外有一些值得注意的点:
1.Bison 传统上将 token 用大写单词表示,将 symbol 用小写字母表示。
2.Bison 能且只能生成解析器源代码(一个 .c 文件),并且入口是 yyparse,所以为了让程序能跑起来,你需要手动提供 main 函数(但不一定要在 .y 文件中——你懂“链接”是什么,对吧?)。
3.Bison 不能检测你的 action code 是否正确——它只能检测文法的部分错误,其他代码都是原样粘贴到 .c 文件中。
4.Bison 需要你提供一个 yylex 来获取下一个 token。
5.Bison 需要你提供一个 yyerror 来提供合适的报错机制。
顺便提一嘴,上面这个 .y 是可以工作的——尽管它只能接受两个字符串。把上面这段代码保存为 reimu.y,执行如下命令来构建这个程序:
$ bison reimu.y
$ gcc reimu.tab.c
$ ./a.out
R<-- 不要回车在这里按 Ctrl-D
rule2
$ ./a.out
<-- 不要回车在这里按 Ctrl-D
Hello!
rule1
$ ./a.out
blablabla <-- 回车或者 Ctrl-D
Hello!
rule1 <-- 匹配到了 rule1
syntax error <-- 发现了错误
于是我们验证了上述代码的确识别了该文法定义的语言 { “”, “R” }。
1.3 Bison 和 Flex 的关系
聪明的你应该发现了,我们这里手写了一个 yylex 函数作为词法分析器。而 lab1 我们正好使用 flex 自动生成了一个词法分析器。如何让这两者协同工作呢?特别是,我们需要在这两者之间共享 token 定义和一些数据,难道要手动维护吗?哈哈,当然不用!下面我们用一个四则运算计算器来简单介绍如何让 bison 和 flex 协同工作——重点是如何维护解析器状态、YYSTYPE 和头文件的生成。
首先,我们必须明白,整个工作流程中,bison 是占据主导地位的,而 flex 仅仅是一个辅助工具,仅用来生成 yylex 函数。因此,最好先写 .y 文件。
/* calc.y */
%{
#include <stdio.h>
int yylex(void);
void yyerror(const char *s);
%}
%token RET
%token <num> NUMBER
%token <op> ADDOP MULOP LPAREN RPAREN
%type <num> top line expr term factor
%start top
%union {
char op;
double num;
}
%%
top
: top line {}
| {}
line
: expr RET
{
printf(" = %f\n", $1);
}
expr
: term
{
$$ = $1;
}
| expr ADDOP term
{
switch ($2) {
case '+': $$ = $1 + $3; break;
case '-': $$ = $1 - $3; break;
}
}
term
: factor
{
$$ = $1;
}
| term MULOP factor
{
switch ($2) {
case '*': $$ = $1 * $3; break;
case '/': $$ = $1 / $3; break; // 想想看,这里会出什么问题?
}
}
factor
: LPAREN expr RPAREN
{
$$ = $2;
}
| NUMBER
{
$$ = $1;
}
%%
void yyerror(const char *s)
{
fprintf(stderr, "%s\n", s);
}
/* calc.l */
%option noyywrap
%{
/* 引入 calc.y 定义的 token */
#include "calc.tab.h"
%}
%%
\( { return LPAREN; }
\) { return RPAREN; }
"+"|"-" { yylval.op = yytext[0]; return ADDOP; }
"*"|"/" { yylval.op = yytext[0]; return MULOP; }
[0-9]+|[0-9]+\.[0-9]*|[0-9]*\.[0-9]+ { yylval.num = atof(yytext); return NUMBER; }
" "|\t { }
\r\n|\n|\r { return RET; }
%%
最后,我们补充一个 driver.c 来提供 main 函数。
int yyparse();
int main()
{
yyparse();
return 0;
}
使用如下命令构建并测试程序:
$ bison -d calc.y
(生成 calc.tab.c 和 calc.tab.h。如果不给出 -d 参数,则不会生成 .h 文件。)
$ flex calc.l
(生成 lex.yy.c)
$ gcc lex.yy.c calc.tab.c driver.c -o calc
$ ./calc
1+1
= 1.000000
2*(1+1)
= 4.000000
2*1+1
= 3.000000
如果你复制粘贴了上述程序,可能会觉得很神奇,并且有些地方看不懂。下面就详细讲解上面新出现的各种构造。
·YYSTYPE: 在 bison 解析过程中,每个 symbol 最终都对应到一个语义值上。或者说,在 parse tree 上,每个节点都对应一个语义值,这个值的类型是 YYSTYPE。YYSTYPE 的具体内容是由 %union 构造指出的。上面的例子中,
%union {
char op;
double num;
}
会生成类似这样的代码
typedef union YYSTYPE {
char op;
double num;
} YYSTYPE;
为什么使用 union 呢?因为不同节点可能需要不同类型的语义值。比如,上面的例子中,我们希望 ADDOP 的值是 char 类型,而 NUMBER 应该是 double 类型的。
·$$ 和 $1, $2, $3, …:现在我们来看如何从已有的值推出当前节点归约后应有的值。以加法为例:
term : term ADDOP factor
{
switch $2 {
case '+': $$ = $1 + $3; break;
case '-': $$ = $1 - $3; break;
}
}
其实很好理解。当前节点使用 $$ 代表,而已解析的节点则是从左到右依次编号,称作 $1, $2, $3…
·%type <> 和 %token <>:注意,我们上面可没有写 $1.num 或者 $2.op 哦!那么 bison 是怎么知道应该用 union 的哪部分值的呢?其秘诀就在文件一开始的 %type 和 %token 上。
例如,term 应该使用 num 部分,那么我们就写
%type <num> term
这样,以后用 $ 去取某个值的时候,bison 就能自动生成类似 stack[i].num 这样的代码了。
%token<> 见下一条。
·%token:当我们用 %token 声明一个 token 时,这个 token 就会导出到 .h 中,可以在 C 代码中直接使用(注意 token 名千万不要和别的东西冲突!),供 flex 使用。%token ADDOP 与之类似,但顺便也将 ADDOP 传递给 %type,这样一行代码相当于两行代码,岂不是很赚。
·yylval:这时候我们可以打开 .h 文件,看看里面有什么。除了 token 定义,最末尾还有一个 extern YYSTYPE yylval; 。这个变量我们上面已经使用了,通过这个变量,我们就可以在 lexer 里面设置某个 token 的值。
呼……说了这么多,现在回头看看上面的代码,应该可以完全看懂了吧!这时候你可能才意识到为什么 flex 生成的分析器入口是 yylex,因为这个函数就是 bison 专门让程序员自己填的,作为一种扩展机制。另外,bison(或者说 yacc)生成的变量和函数名通常都带有 yy 前缀,希望在这里说还不太晚……
最后还得提一下,尽管上面所讲已经足够应付很大一部分解析需求了,但是 bison 还有一些高级功能,比如自动处理运算符的优先级和结合性(于是我们就不需要手动把 expr 拆成 factor, term 了)。这部分功能,就留给同学们自己去探索吧!
2. 实验要求
本次实验需要各位同学首先将自己的 lab1 的词法部分复制到 /src/parser 目录的 lexical_analyzer.l并合理修改相应部分,然后根据 cminus-f 的语法补全 syntax_analyer.y 文件,完成语法分析器,要求最终能够输出解析树。如:
输入:
int bar;
float foo(void) { return 1.0; }
则 parser 将输出如下解析树:
>--+ program
| >--+ declaration-list
| | >--+ declaration-list
| | | >--+ declaration
| | | | >--+ var-declaration
| | | | | >--+ type-specifier
| | | | | | >--* int
| | | | | >--* bar
| | | | | >--* ;
| | >--+ declaration
| | | >--+ fun-declaration
| | | | >--+ type-specifier
| | | | | >--* float
| | | | >--* foo
| | | | >--* (
| | | | >--+ params
| | | | | >--* void
| | | | >--* )
| | | | >--+ compound-stmt
| | | | | >--* {
| | | | | >--+ local-declarations
| | | | | | >--* epsilon
| | | | | >--+ statement-list
| | | | | | >--+ statement-list
| | | | | | | >--* epsilon
| | | | | | >--+ statement
| | | | | | | >--+ return-stmt
| | | | | | | | >--* return
| | | | | | | | >--+ expression
| | | | | | | | | >--+ simple-expression
| | | | | | | | | | >--+ additive-expression
| | | | | | | | | | | >--+ term
| | | | | | | | | | | | >--+ factor
| | | | | | | | | | | | | >--+ float
| | | | | | | | | | | | | | >--* 1.0
| | | | | | | | >--* ;
| | | | | >--* }
请注意,上述解析树含有每个解析规则的所有子成分,包括诸如 ; { } 这样的符号,请在编写规则时务必不要忘了它们。
2.1 目录结构
.
├── CMakeLists.txt
├── Documentations
│ ├── lab1
│ └── lab2
│ ├── readings.md <- 扩展阅读
│ └── README.md <- lab2实验文档说明(你在这里)
├── README.md
├── Reports
│ ├── lab1
│ └── lab2
│ └── report.md <- lab2所需提交的实验报告(你需要在此提交实验报告)
├── include <- 实验所需的头文件
│ ├── lexical_analyzer.h
│ └── SyntaxTree.h
├── src <- 源代码
│ ├── common
│ │ └── SyntaxTree.c <- 分析树相关代码
│ ├── lexer
│ └── parser
│ ├── lexical_analyzer.l <- lab1 的词法部分复制到这,并进行一定改写
│ └── syntax_analyzer.y <- lab2 需要完善的文件
└── tests <- 测试文件
├── lab1
└── lab2 <- lab2 测试用例文件夹
2.2 编译、运行和验证
·编译
与 lab1 相同。若编译成功,则将在 ${WORKSPACE}/build/ 下生成 parser 命令。
·运行
与 lexer 命令不同,本次实验的 parser 命令使用 shell 的输入重定向功能,即程序本身使用标准输入输出(stdin 和 stdout),但在 shell 运行命令时可以使用 < > 和 >> 灵活地自定义输出和输入从哪里来。
$ cd cminus_compiler-2021-fall
$ ./build/parser # 交互式使用(不进行输入重定向)
<在这里输入 Cminus-f 代码,如果遇到了错误,将程序将报错并退出。>
<输入完成后按 ^D 结束输入,此时程序将输出解析树。>
$ ./build/parser < test.cminus # 重定向标准输入
<此时程序从 test.cminus 文件中读取输入,因此不需要输入任何内容。>
<如果遇到了错误,将程序将报错并退出;否则,将输出解析树。>
$ ./build/parser test.cminus # 不使用重定向,直接从 test.cminus 中读入
$ ./build/parser < test.cminus > out
<此时程序从 test.cminus 文件中读取输入,因此不需要输入任何内容。>
<如果遇到了错误,将程序将报错并退出;否则,将输出解析树到 out 文件中。>
通过灵活使用重定向,可以比较方便地完成各种各样的需求,请同学们务必掌握这个 shell 功能。
此外,提供了 shell 脚本 /tests/lab2/test_syntax.sh 调用 parser 批量分析测试文件。注意,这个脚本假设 parser 在 项目目录/build 下。
# test_syntax.sh 脚本将自动分析 ./tests/lab2/testcase_$1 下所有文件后缀为 .cminus 的文件,并将输出结果保存在 ./tests/lab2/syntree_$1 文件夹下
$ ./tests/lab2/test_syntax.sh easy
...
...
...
$ ls ./tests/lab2/syntree_easy
<成功分析的文件>
$ ./tests/lab2/test_syntax.sh normal
$ ls ./tests/lab2/syntree_normal
·验证
本次试验测试案例较多,为此我们将这些测试分为两类:
1.easy: 这部分测试均比较简单且单纯,适合开发时调试。
2.normal: 较为综合,适合完成实验后系统测试。
我们使用 diff 命令进行验证。将自己的生成结果和助教提供的 xxx_std 进行比较。
$ diff ./tests/lab2/syntree_easy ./tests/lab2/syntree_easy_std
# 如果结果完全正确,则没有任何输出结果
# 如果有不一致,则会汇报具体哪个文件哪部分不一致
# 使用 -qr 参数可以仅列出文件名
test_syntax.sh 脚本也支持自动调用 diff。
# test_syntax.sh 脚本将自动分析 ./tests/lab2/testcase_$1 下所有文件后缀为 .cminus 的文件,并将输出结果保存在 ./tests/lab2/syntree_$1 文件夹下
$ ./tests/lab2/test_syntax.sh easy yes
<分析所有 .cminus 文件并将结果与标准对比,仅输出有差异的文件名>
$ ./tests/lab2/test_syntax.sh easy verbose
<分析所有 .cminus 文件并将结果与标准对比,详细输出所有差异>
请注意助教提供的testcase并不能涵盖全部的测试情况,完成此部分仅能拿到基础分,请自行设计自己的testcase进行测试。
2.3 提交要求和评分标准
·提交要求
本实验的提交要求分为两部分:实验部分的文件和报告,git提交的规范性。
·实验部分:
·需要完善 ./src/parser/lexical_analyzer.l 文件;
·需要完善 ./src/parser/syntax_analyzer.y 文件;
·需要在 ./Report/lab2/report.md 撰写实验报告。
·实验报告内容包括:
·实验要求、实验难点、实验设计、实验结果验证、实验反馈(具体参考report.md);
·实验报告不参与评分标准,但是必须完成并提交.
·本次实验收取 ./src/parser/lexical_analyzer.l 文件、./src/parser/syntax_analyzer.y 文件和 ./Report/lab2 目录
·git提交规范:
·不破坏目录结构(report.md所需的图片请放在./Reports/lab2/figs/下);
·不上传临时文件(凡是自动生成的文件和临时文件请不要上传);
·git log言之有物(不强制, 请不要git commit -m ‘commit 1’, git commit -m ‘sdfsdf’,每次commit请提交有用的comment信息)
·评分标准
·git提交规范(6分);
·实现语法分析器并通过给出的 easy 测试集(一个3分,共20个,60分);
·通过 normal 测试集(一个3分,共8个,24分);
·提交后通过助教进阶的多个测试用例(10分)。
代码
lexical_analyzer.l
%option noyywrap
%{
#include <stdio.h>
#include <stdlib.h>
#include "syntax_tree.h"
#include "syntax_analyzer.h"
int files_count;
int lines;
int pos_start;
int pos_end;
void pass_node(char *text){
yylval.node = new_syntax_tree_node(text);
}
%}
/***************
TO STUDENTS: Copy your Lab1 here. Make adjustments if necessary.
Note: don't modify the prologue unless you know what you are doing.
***************/
/* Example for you :-) */
%%
\+ { pos_start = pos_end; pos_end += 1; pass_node(yytext); return ADD; }
\- {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return SUB;}
\* {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return MUL;}
\/ {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return DIV;}
\< {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return LT;}
"<=" {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return LTE;}
\> {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return GT;}
">=" {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return GTE;}
"==" {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return EQ;}
"!=" {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return NEQ;}
\= {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return ASSIN;}
\; {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return SEMICOLON;}
\, {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return COMMA;}
\( {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return LPARENTHESE;}
\) {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return RPARENTHESE;}
\[ {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return LBRACKET;}
\] {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return RBRACKET;}
\{ {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return LBRACE;}
\} {pos_start=pos_end;pos_end=pos_start+1; pass_node(yytext); return RBRACE;}
else {pos_start=pos_end;pos_end=pos_start+4; pass_node(yytext); return ELSE;}
if {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return IF;}
int {pos_start=pos_end;pos_end=pos_start+3; pass_node(yytext); return INT;}
float {pos_start=pos_end;pos_end=pos_start+5; pass_node(yytext); return FLOAT;}
return {pos_start=pos_end;pos_end=pos_start+6; pass_node(yytext); return RETURN;}
void {pos_start=pos_end;pos_end=pos_start+4; pass_node(yytext); return VOID;}
while {pos_start=pos_end;pos_end=pos_start+5; pass_node(yytext); return WHILE;}
[a-zA-Z]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext); pass_node(yytext); return IDENTIFIER;}
[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext); pass_node(yytext); return INTEGER;}
[0-9]*\.[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext); pass_node(yytext); return FLOATPOINT;}
"[]" {pos_start=pos_end;pos_end=pos_start+2; pass_node(yytext); return ARRAY;}
[0-9]+\. {pos_start=pos_end;pos_end=pos_start+strlen(yytext); pass_node(yytext); return FLOATPOINT;}
\n { lines+=1;pos_start=1;pos_end=1; }
\/\*([^\*]|(\*)*[^\*\/])*(\*)*\*\/ { pos_start = pos_end;
int num = count_num_enter(yytext);
if ( num != 0 ) { //kua
lines += num;
pos_end = strlen(strrchr(yytext, '\n'));
}
else pos_end += strlen(yytext);
}
" " {pos_start = pos_end; pos_end += 1;}
\t {pos_start = pos_end; pos_end += 1;}
. {return 0;}
%%
int count_num_enter(char *string) {
int ret = 0;
int index = 0;
while(string[index] != '\0') {
if(string[index] == '\n')
ret++;
index++;
}
return ret;
}
syntax_analyzer.y
%{
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdarg.h>
#include "syntax_tree.h"
// external functions from lex
extern int yylex();
// external variables from lexical_analyzer module
extern int lines;
extern char *yytext;
extern int pos_end;
extern int pos_start;
extern FILE* yyin;
// Global syntax tree
syntax_tree *gt;
// Error reporting
void yyerror(const char *s);
// Helper functions written for you with love
syntax_tree_node *node(const char *node_name, int children_num, ...);
%}
/* TODO: Complete this definition. */
%union {syntax_tree_node * node;}
/* TODO: Your tokens here. */
%token <node> ADD SUB MUL DIV LT LTE GT GTE EQ NEQ ASSIN SEMICOLON COMMA LPARENTHESE RPARENTHESE LBRACKET RBRACKET LBRACE RBRACE ELSE IF INT FLOAT RETURN VOID WHILE IDENTIFIER INTEGER FLOATPOINT ARRAY EOL COMMENT BLANK
%type <node> program type-specifier relop addop mulop declaration-list declaration var-declaration fun-declaration local-declarations compound-stmt statement-list statement expression-stmt iteration-stmt selection-stmt return-stmt expression var additive-expression term factor integer float call simple-expression params param-list param args arg-list
%start program
%%
/* TODO: Your rules here. */
program : declaration-list
{ $$ = node("program", 1, $1); gt->root = $$; }
declaration-list : declaration-list declaration
{ $$ = node("declaration-list", 2, $1, $2);}
| declaration
{$$ = node("declaration-list", 1, $1);}
;
declaration : var-declaration
{$$ = node("declaration", 1, $1);}
| fun-declaration
{$$ = node("declaration", 1, $1);}
;
var-declaration : type-specifier IDENTIFIER SEMICOLON
{$$ = node("var-declaration", 3, $1, $2, $3);}
| type-specifier IDENTIFIER LBRACKET INTEGER RBRACKET SEMICOLON
{$$ = node("var-declaration", 6, $1, $2, $3, $4, $5, $6);}
;
type-specifier : INT
{$$ = node("type-specifier", 1, $1);}
| FLOAT
{$$ = node("type-specifier", 1, $1);}
| VOID
{$$ = node("type-specifier", 1, $1);}
;
fun-declaration : type-specifier IDENTIFIER LPARENTHESE params RPARENTHESE compound-stmt
{$$ = node("fun-declaration", 6, $1, $2, $3, $4, $5, $6);}
;
params : param-list
{$$ = node("params", 1, $1);}
| VOID
{$$ = node("params", 1, $1);}
;
param-list : param-list COMMA param
{$$ = node("param-list", 3, $1, $2, $3);}
| param
{$$ = node("param-list", 1, $1);}
;
param : type-specifier IDENTIFIER
{$$ = node("param", 2, $1, $2);}
| type-specifier IDENTIFIER ARRAY
{$$ = node("param", 3, $1, $2, $3);}
;
compound-stmt : LBRACE local-declarations statement-list RBRACE
{$$ = node("compound-stmt", 4, $1, $2, $3, $4);}
;
local-declarations : local-declarations var-declaration
{$$ = node("local-declarations", 2, $1, $2);}
|
{$$ = node("local-declarations", 0);}
;
statement-list : statement-list statement
{$$ = node("statement-list", 2, $1, $2);}
|
{$$ = node("statement-list", 0);}
;
statement : expression-stmt
{$$ = node("statement", 1, $1);}
| compound-stmt
{$$ = node("statement", 1, $1);}
| selection-stmt
{$$ = node("statement", 1, $1);}
| iteration-stmt
{$$ = node("statement", 1, $1);}
| return-stmt
{$$ = node("statement", 1, $1);}
;
expression-stmt : expression SEMICOLON
{$$ = node("expression-stmt", 2, $1, $2);}
| SEMICOLON
{$$ = node("expression-stmt", 1, $1);}
;
selection-stmt : IF LPARENTHESE expression RPARENTHESE statement
{$$ = node("selection-stmt", 5, $1, $2, $3, $4, $5);}
| IF LPARENTHESE expression RPARENTHESE statement ELSE statement
{$$ = node("selection-stmt", 7, $1, $2, $3, $4, $5, $6, $7);}
;
iteration-stmt : WHILE LPARENTHESE expression RPARENTHESE statement
{$$ = node("iteration-stmt", 5, $1, $2, $3, $4, $5);}
;
return-stmt : RETURN SEMICOLON
{$$ = node("return-stmt", 2, $1, $2);}
| RETURN expression SEMICOLON
{$$ = node("return-stmt", 3, $1, $2, $3);}
;
expression : var ASSIN expression
{$$ = node("expression", 3, $1, $2, $3);}
| simple-expression
{$$ = node("expression", 1, $1);}
;
var : IDENTIFIER
{$$ = node("var", 1, $1);}
| IDENTIFIER LBRACKET expression RBRACKET
{$$ = node("var", 4, $1, $2, $3, $4);}
;
simple-expression : additive-expression relop additive-expression
{$$ = node("simple-expression", 3, $1, $2, $3);}
| additive-expression
{$$ = node("simple-expression", 1, $1);}
;
relop : LTE
{$$ = node("relop", 1, $1);}
| LT
{$$ = node("relop", 1, $1);}
| GT
{$$ = node("relop", 1, $1);}
| GTE
{$$ = node("relop", 1, $1);}
| EQ
{$$ = node("relop", 1, $1);}
| NEQ
{$$ = node("relop", 1, $1);}
;
additive-expression : additive-expression addop term
{$$ = node("additive-expression", 3, $1, $2, $3);}
| term
{$$ = node("additive-expression", 1, $1);}
;
addop : ADD
{$$ = node("addop", 1, $1);}
| SUB
{$$ = node("addop", 1, $1);}
;
term : term mulop factor
{$$ = node("term", 3, $1, $2, $3);}
| factor
{$$ = node("term", 1, $1);}
;
mulop : MUL
{$$ = node("mulop", 1, $1);}
| DIV
{$$ = node("mulop", 1, $1);}
;
factor : LPARENTHESE expression RPARENTHESE
{$$ = node("factor", 3, $1, $2, $3);}
| var
{$$ = node("factor", 1, $1);}
| call
{$$ = node("factor", 1, $1);}
| integer
{$$ = node("factor", 1, $1);}
| float
{$$ = node("factor", 1, $1);}
;
integer : INTEGER
{$$ = node("integer", 1, $1);}
;
float : FLOATPOINT
{$$ = node("float", 1, $1);}
;
call : IDENTIFIER LPARENTHESE args RPARENTHESE
{$$ = node("call", 4, $1, $2, $3, $4);}
;
args : arg-list
{$$ = node("args", 1, $1);}
|
{$$ = node("args", 0);}
;
arg-list : arg-list COMMA expression
{$$ = node("arg-list", 3, $1, $2, $3);}
| expression
{$$ = node("arg-list", 1, $1);}
;
%%
/// The error reporting function.
void yyerror(const char *s)
{
// TO STUDENTS: This is just an example.
// You can customize it as you like.
fprintf(stderr, "error at line %d column %d: %s\n", lines, pos_start, s);
}
/// Parse input from file `input_path`, and prints the parsing results
/// to stdout. If input_path is NULL, read from stdin.
///
/// This function initializes essential states before running yyparse().
syntax_tree *parse(const char *input_path)
{
if (input_path != NULL) {
if (!(yyin = fopen(input_path, "r"))) {
fprintf(stderr, "[ERR] Open input file %s failed.\n", input_path);
exit(1);
}
} else {
yyin = stdin;
}
lines = pos_start = pos_end = 1;
gt = new_syntax_tree();
yyrestart(yyin);
yyparse();
return gt;
}
/// A helper function to quickly construct a tree node.
///
/// e.g.
/// $$ = node("program", 1, $1);
/// $$ = node("local-declarations", 0);
syntax_tree_node *node(const char *name, int children_num, ...)
{
syntax_tree_node *p = new_syntax_tree_node(name);
syntax_tree_node *child;
if (children_num == 0) {
child = new_syntax_tree_node("epsilon");
syntax_tree_add_child(p, child);
} else {
va_list ap;
va_start(ap, children_num);
for (int i = 0; i < children_num; ++i) {
child = va_arg(ap, syntax_tree_node *);
syntax_tree_add_child(p, child);
}
va_end(ap);
}
return p;
}
思路之类的
好像第二次实验也是开始的时候一头雾水,因为不清楚应该要怎么做,然后在参考了前人的代码之后豁然开朗,不由感叹:居然是这样…
1.首先对于lexical_analyzer.l文件,需要把在lab1中完成的lexical_analyzer.l文件按照本次实验的需求进行改写,使其可以与bison进行协同工作。具体实现为:对于一般的符号,只需要根据给出的样例,在返回之前加上一句pass_node(yytext);来建立一个新的节点。而对于注释,空格,回车和错误,则因为不需要建立节点而不需要添加且需要删除掉返回值,同时需要将在case中的注释是否有跨行的判断加入到识别中。
2.对于syntax_analyzer.y文件:首先需要给出一个节点的定义;然后再分别声明%token节点和%type节点的符号,其中%token的符号是大写,代表终结符,对应词法分析,而%type的符号是小写,代表非终结符,对应这次的语法分析;根据给出的样例,我们可以看出来,语法分析的结构其实还是很简单的,在:前面写出产生式左部,在:后面写出产生式右部,然后再在{}里面进行赋值定义,node的第一个参数为产生式左部名称,第二个参数代表有多少个子节点,然后再在后面的参数分别标上序号。
码一个我当时的疑惑(也许你们可以解决)
如果在这个位置加上分号
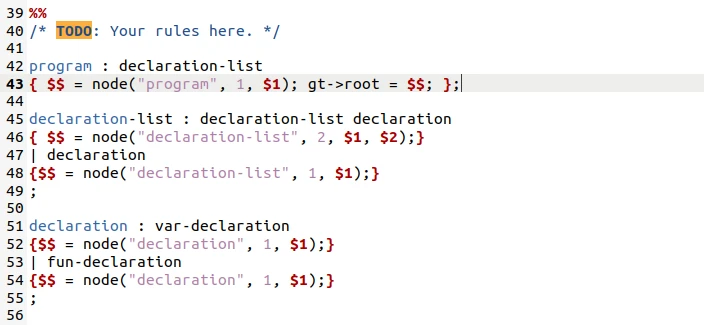
在make parser的时候会有警告:移进规约冲突
但是在运行的时候可以正常运行