
1. 前言
本文讲解小样本学习(Few-Shot Learning)基本概念及基本思路,孪生网络(Siamese Network)基本原理及训练方法。
小样本学习(Few-Shot Learning)(二)讲解小样本学习问题的Pretraining+Fine Tuning解法。
小样本学习(Few-Shot Learning)(三)使用飞桨(PaddlePaddle)基于paddle.vision.datasets.Flowers数据集实践小样本学习问题的Pretraining+Fine Tuning解法。
本文搬运自我的CSDN博客,更多机器学习及深度学习文章请关注:DeepGeGe
2. 小样本学习
1997年5月2日,小敏生日,在动物园游玩。小敏走进极地馆,发现了图一所示毛茸茸的可爱小动物,她非常喜欢,但是小敏之前没有见过,不知道它的名字。小敏拿出入园时领取的动物学识卡,逐一翻阅卡片,确定图一中的小动物是狐狸。


小敏去动物园游玩之前没有见过狐狸,因此不可能认识图一中的小动物,但是她只需要看一下动物学识卡,就能学会辨认图一中小动物是狐狸。小敏可以做到,那么计算机是否也可以做到?
或者说,如果训练集中每一类只有一两个样本,计算机能否做出像小敏一样正确的分类呢?
2.1. 基本概念
2.1.1 元学习(Meta Learning)
元学习的解释为学会学习(Learning to learn)。“学会”是指训练模型直至收敛,“学习”是指学习的能力。“学会学习”是指通过训练机器学习模型,使得其具备学习的能力。
元学习是人工智能领域的一个重要研究分支,是一切尝试让机器具备学习能力的理论和工程方法的统称。小样本学习是元学习的一个子领域。
如何理解【学习的能力】?
上述例子中,小敏没有见过狐狸,她作出图一中小动物是狐狸这一判断的依据是图一中的小动物和入园时领取的动物学识卡中的狐狸长得非常像,即小敏能够判断动物之间的异同。这种能够判断事物之间异同的能力就是一种【学习的能力】。
【学习的能力】远不止判断事物之间的异同这一种,但是在小样本学习领域,主要方法之一是通过训练深度学习模型,使其具备这种判断事物之间异同的能力,从而解决小样本学习问题。
2.1.2 Support Set和Query
将上述小敏学会辨认狐狸的例子抽象成小样本学习问题,由于小敏在进动物园游玩前没有见过狐狸,因此小敏不可能认识狐狸。小敏要知道图一中小动物的名字,必须有入园时领取的动物学识卡提供额外信息。
在小样本学习中,动物学识卡这种数据集被称为Support Set,图一这种需要判断其类别的图片被成为Query。根据Support Set中类别数量和样本数量的不同,Support Set可被称为�k-way �n-shot Support Set。
- �k-way:Support Set中存在�k个类别
- �n-shot:每个类别中存在�n个样本
在上述小敏学会辨认狐狸的例子中,小敏入园时领取的动物学识卡构成的Support Set中有狐狸、松鼠、兔子、仓鼠、水獭和海狸6种不同的小动物,因此�k等于6。每种小动物卡片只有一张,所有�n等于1。这个Support Set是6-way 1-shot Support Set。
小样本分类准确率会受到Support Set中类别数量和样本数量的影响,随着类别数量增加,分类准确率会降低。随着每个类别样本数增加,分类会更准确。
Support Set与训练集的区别:
训练集是一个非常大的数据集,每一类均包含非常多张图片。训练集足够大,可以用来训练一个深度神经网络。Support Set非常小,每一类只包含一张或几张图片,不足以训练一个深度神经网络。Support Set用于在预测时提供额外信息,使得模型能够断出所属类别不在训练集中的Query图片的类别。
2.1.3 传统机器学习与小样本学习的区别
传统监督学习首先会在一个训练集上训练模型,模型训练好之后可以用来做预测,给定一张测试图片,模型预测该图片类别。测试图片不在训练集中,但是其归属于训练集中的某一类。
小样本学习与传统监督学习有所不同,小样本学习的目标不是让机器识别训练集中的图片并且泛化到测试集,小样本学习的目标是让机器自己学会学习。用一个很大的数据集训练神经网络,学习的目的不是让模型知道什么是狐狸什么是老鼠,从而能够识别没有见过的狐狸和老鼠。学习的目的是让模型理解事物的异同,学会区分不同的事物。给定两张图片,不是让模型识别两张图片是什么,而是让模型判断两张图片中的对象是否相同。
因为训练集中不包含测试样本及其类别,因此小样本学习比传统监督学习更难。
2.2 基本思路
在小样本学习问题中,Support Set中每一类往往只有少数几个样本,单单依靠这些样本,不可能训练出一个深度神经网络,甚至无法采用迁移学习中的Pretraining+Fine Tuning方法。即对于小样本学习问题,不能采用传统的监督学习方法来进行分类。
小样本学习的最基本想法是学习一个���sim函数来判断相似度。给定两张图片�x和�′x′,如果两张图片越相似,则���(�,�′)sim(x,x′)的值越大。在理想情况下,若�x和�′x′属于同一类,则���(�,�′)=1sim(x,x′)=1,若�x和�′x′属于不同类,则���(�,�′)=0sim(x,x′)=0。
具体可以按照如下思路解决小样本学习问题:
- 在一个大数据集中学习一个判断两张图片相似程度的相似度函数;
- 给定一个Query图片,将其和Support Set中各图片逐一对比,计算相似度;
- 在Support Set中找到与Queryt图片相似度最高的图片,将其类别作为预测结果。
3. 孪生网络
前面提到解决小样本学习问题的思路之一是学习一个相似度函数,孪生网络就是断两张图片相似程度的深度神经网络,其使用同一个深度神经网络对两张输入图片�1x1和�2x2分别提取特征,得到�(�1)f(x1)和�(�2)f(x2),计算�(�1)f(x1)和�(�2)f(x2)之间的相似度并更新深度神经网络参数。预测时根据�(��)f(xq)和�(��)f(xs)之间的相似度判断给定Query图片的类别。
孪生网络用同一个网络分别从不同输出中提取特征,将得到的特征融合并判断输入之间的相似度。网络“身体”是分开的,“头”是相连的,因此命名为孪生网络。
3.1 训练孪生网络
3.1.1 Learning Pairwise Similarity Scores
训练孪生网络需要用到一个大的分类数据集,数据集中每张图片均有标注,每一类均包含许多张图片。训练的第一种方法是每次从数据集中随机抽取两个样本,比较他们的相似度,并根据相似度函数损失更新网络参数。
首先须使用数据集来构造正样本和负样本,其中正样本用于告诉神经网络什么东西是同一类,负样本用于告诉神经网络事物之间的区别。构造正样本首先须从数据集中随机抽取一张图片�1x1,然后从同一类中随机抽取另一张图片�2x2,形成三元组(�1,�2,1)(x1,x2,1)。构造负样本每次先随机抽取一张图片�1′x1′,然后排除�1′x1′的类别,从随机集中随机抽取另一张图片�2′x2′,形成三元组(�1′,�2′,0)(x1′,x2′,0)。重复上述构造正样本和负样本的过程,即可生成用于训练孪生网络的训练集。

搭建卷积神经网络用于提取图片中的特征,网络输入是一张图片�x,输出是提取的特征向量�(�)f(x)。将生成的训练集中一个样本的两张图片�1x1和�2x2分别输入搭建的卷积神经网络,得到特征向量ℎ1h1和ℎ2h2。将向量ℎ1h1和ℎ2h2结合形成特征向量�z(如令�=������(ℎ1,ℎ2)z=concat(h1,h2)或�=∣ℎ1−ℎ2∣z=∣h1−h2∣等等),然后用一些全连接层处理�z向量,输出一个标量,并将该标量经过�������Sigmoid激活函数,得到一个介于0∼10∼1之间的实数。
该实数可以衡量输入的两张图片�1x1和�2x2之间的相似度,如果�1x1和�2x2属于同一个类别,则输出实数应该接近于1,否则应该接近于0。使用网络输出与真实标签之间的交叉熵(������������CrossEntropy)作为损失函数,通过反向传播计算模型参数的梯度,并使用梯度下降法来更新模型参数。
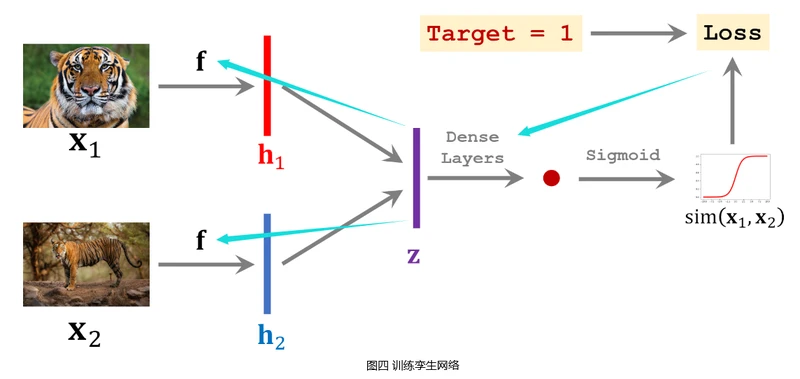
训练孪生网络需要准备数量大致相当的正样本和负样本,负样本是不同类别的两张图片,其标签为0,通过训练使孪生网络输出接近于0。
训练好孪生网络之后,可以用来做小样本分类。逐一对比Query图片与Support Set中的图片,返回Support Set中相似度最高的图片类别作为预测结果。
3.1.2 Triplet Loss
上述训练孪生网络方法从理论上看起来很完美,但是在深度学习实践中,上述方法效果并不是特别好。在深度学习领域,理论上看起来很完美,但是实际效果却一塌糊涂的例子数见不鲜,比上述方法更好的训练孪生网络的方法是使用Triplet Loss。
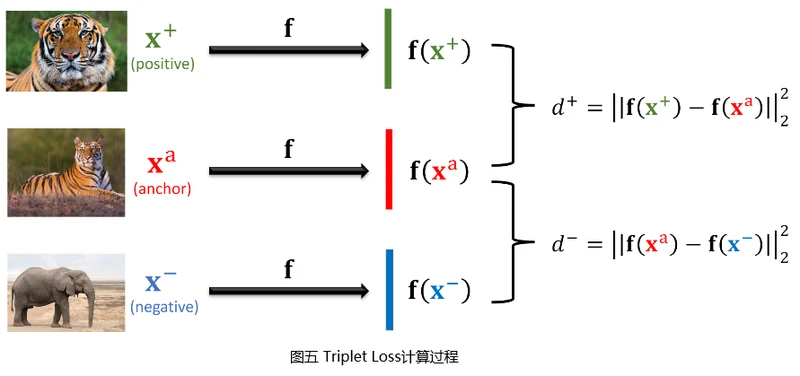
使用Triplet Loss,在构建训练集时,需每次从数据集中选取3张图片。首先从数据集中随机选取一张图片作为锚点(Anchor),再从锚点图片所在类别中随机抽取另一张图片作为正样本(Positive),然后排除锚点图片所在类别,从数据集中随机选取一张图片作为负样本(Negative)。
将锚点图片、正样本图片和负样本图片分别输入搭建好的用于提取图片特征的卷积神经网络,得到三个特征向量�(�+)、�(��)f(x+)、f(xa)和�(�−)f(x−)。分别计算�(�+)f(x+)和�(��)f(xa)、�(�−)f(x−)和�(��)f(xa) 二范数 的平方�+d+和�−d−,即�+=∣∣�(�+)−�(��)∣∣22d+=∣∣f(x+)−f(xa)∣∣22,�−=∣∣�(��−�(�−))∣∣22d−=∣∣f(xa−f(x−))∣∣22。
卷积神经网络能够把一张图片映射成特征空间中的一个点,为了解决小样本学习问题,我们期望训练好的神经网络能够将相同类别的图片在特征空间中对应点全部聚集在一起,将不同类别的图片在特征空间中对应的点分开。如图六所示,因为正样本和锚点属于同一类别,负样本和锚点属于不同类别,因此�+d+应该很小,�−d−应该很大。
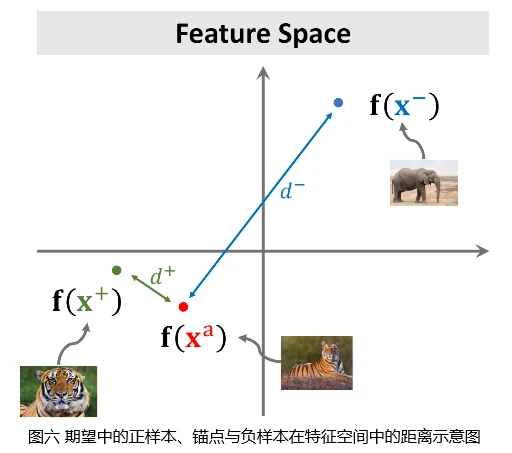
训练孪生网络的损失函数首先应该鼓励正样本在特征空间上接近锚点,即使�+d+尽量小。其次应该鼓励负样本在特征空间上远离锚点,即使�−d−尽量大。因此,可分为如下两种情况:
- 如果�−⩾�++�d−⩾d++α,可认为这一组样本分类正确,����=0Loss=0;
- 假如上述条件不满足,说明模型无法区分该组正负样本,����=�++�−�−Loss=d++α−d−。
即Triplet Loss可定义如下:
����(��,�+,�−)=���{0,�++�−�−}Loss(xa,x+,x−)=max{0,d++α−d−},其中�α被称为间隔(Margin),是一个超参数。
确定损失函数之后,可以求损失函数关于模型参数的梯度,并使用随机梯度下降法更新模型参数。训练好孪生网络之后,可以通过如下方法来做小样本分类。
将Query图片和Support Set中所有图片全部转化为特征向量,然后依次计算Query图片对应的特征向量和Support Set中各图片对应特征向量之间的距离,返回Support Set中距离最小的图片类别作为预测结果。
二范数: 向量的二范数即向量的模。
小样本学习(Few-Shot Learning)(二)
1. 前言
本文讲解小样本学习问题的Pretraining+Fine Tuning解法。
2. 预训练(Pretraining)
在小样本学习问题中,测试样本及其类别均不在训练集中,但是Support Set包含的类别是固定不变的。使用孪生网络解决小样本学习问题,会训练一个可以用来衡量图片之间相似度的神经网络,逐一比较Query图片和Support Set中各图片的相似度,并返回相似度最高的图片类别作为预测结果。这种小样本学习问题的解法显然没有利用Support Set中包含的类别固定不变的性质,因此并不是小样本学习问题最好的解决方法。
小样本学习问题的Pretraining+Fine Tuning解法的基本想法是在大规模数据集上预训练模型,然后在小规模的Support Set上做Fine Tuning。这种解决方法非常简单,但是准确率基本与小样本学习领域最好的方法相当。相较之下,许多非常复杂的方法的准确率没有显著高于这种非常简单的Pretraining+Fine Tuning方法。
由于小样本学习问题中Support Set包含的样本数量非常少,因此小样本学习问题的Pretraining+Fine Tuning解法与传统迁移学习中的Pretraining+Fine Tuning方法有所不同。 Pretraining阶段,搭建一个卷积神经网络用于从图片中提取特征,在大规模数据集上通过以下两个步骤训练该卷积神经网络:
- 基于�������+������������Softmax+CrossEntropy损失,使用标准的分类监督学习方法训练卷积神经网络;
- 使用孪生网络中提到的方法,继续训练第1步中训练好的卷积神经网络。
深度学习实践证明,先使用交叉熵损失,基于传统的分类监督学习方法训练模型,而不是直接使用孪生网络相关方法训练模型,可以使得模型更快收敛;
使用孪生网络相关方法继续训练模型,可以使用余弦相似度(Cosine Similarity)作为损失函数,本文后续Fine Tuning阶段及预测时候会基于余弦相似度来进行小样本分类;
不同网络结构和训练方法会对最终结果产生影响。
2.1 使用预训练模型进行小样本分类
模型预训练完成后,已经可用来解决小样本分类问题了。如图一所示,给定一个3-Way 2-Shot Support Set,解决该小样本学习问题首先要用预训练好的神经网络提取特征,将所有图片全部变成特征向量。对每个类别所有图片的特征向量做平均,得到可以表征该类别的特征向量。进一步对得到的三个特征向量做归一化,形成�1,�2,�3μ1,μ2,μ3。
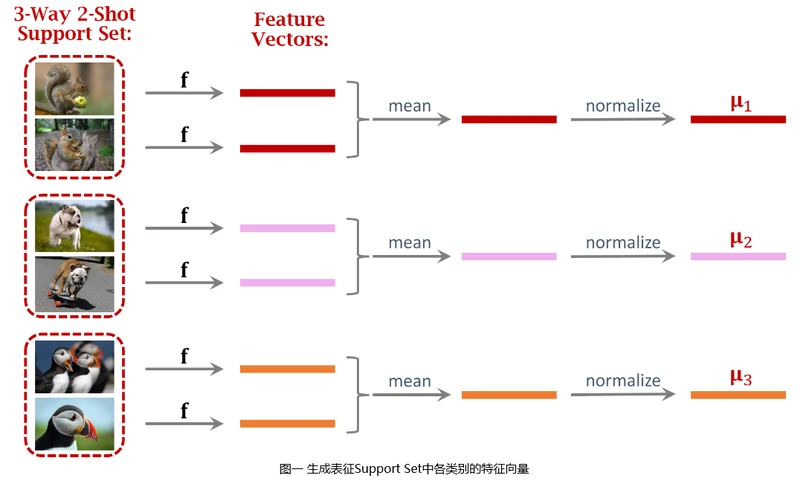
�1,�2,�3μ1,μ2,μ3可以看做对给定Support Set各类别的表征,其二范数均等于一。在分类的时候,需要拿Query图片的特征向量与Support Set中各类别的特征向量进行对比。
给定Query图片�x,按照上述提取Support Set中图片特征向量的步骤,提取Query图片特征并归一化,得到向量�q。将从Support Set中提取的三个向量�1,�2,�3μ1,μ2,μ3堆叠起来,形成矩阵�M,�=[�1��2��3�]M=⎣⎢⎡μ1Tμ2Tμ3T⎦⎥⎤。将矩阵�M与�q相乘,并将结果输入�������Softmax函数,得到向量�p,�=�������(��)=�������([�1���2���3��])p=Softmax(Mq)=Softmax(⎣⎢⎡μ1Tqμ2Tqμ3Tq⎦⎥⎤)。�p是�������Softmax函数的输出,是一个概率分布,其每个元素分别表示Query图片属于每个类别的置信度。
在Support Set的各类特征向量�1,�2,�3μ1,μ2,μ3中,若�1μ1与�q的余弦相似度最大,则�1��μ1Tq的值比�2��μ2Tq和�3��μ3Tq大,因此向量�p的第一个元素值最大,输出分类结果会是第一类。
3. 微调模型参数(Fine Tuning)
在大规模数据集上预训练好神经网络之后,可以在Support Set上进行Fine Tuning来进一步提高预测准确率。很多论文的实验结果表明,Fine Tuning可以大幅提高预测准确率。一篇ICLR 2020的论文实验表明,在5-way 1-shot Support Set上做Fine Tuning可以提升2%∼7%2%∼7%的准确率,在5-way 5-shot Support Set上做Fine Tuning可以提升1.5%∼4%1.5%∼4%的准确率。小样本学习领域很多论文中的实验都证明了,尽管Support Set非常小,但是用Support Set来训练分类器有助于提升准确率,使用Pretraining+Fine Tuning比只使用Pretraining要好很多。
假设(��,��)(xj,yj)为Support Set中一个样本,其中��xj为图片,��yj为标签。使用预训练好的神经网络可以将图片��xj转换成特征向量�(��)f(xj)。将特征向量�(��)f(xj)输入�������Softmax分类器,分类器会输出概率分布��=�������(��(��)+�)pj=Softmax(Wf(xj)+b),��pj的各个元素分别表示图片��xj属于各类别的概率。
不进行Fine Tuning,直接使用预训练模型进行小样本分类,相当于不学习�������Softmax分类器中的参数矩阵�W和�b,而是直接使�=�,�W=M,b等于全0向量。�M矩阵的每一行是Support Set中一个类别的均值向量,将�������Softmax分类器中的参数矩阵�W设置为�M矩阵,则分类器输出向量��pj的每个元素可以反映出Query图片��xj的特征与Support Set中各类别特征之间的相似度。
比上述直接使用预训练模型进行小样本分类更好的方法是进行Fine Tuning,在Support Set上学习�������Softmax分类器中的参数矩阵�W和�b。在Support Set中有几个或者几十个样本,对于每个样本(��,��)(xj,yj),计算�������Softmax分类器的输出向量��pj和图片��xj的标签��yj的������������CrossEntropy,将Support Set中所有样本的������������CrossEntropy相加作为目标函数,即使用Support Set中所有图片及其标签来训练�������Softmax分类器。
最小化目标函数,���∑�������������(��,��)min∑jCrossEntropy(yj,pj),使得�������Softmax分类器的输出��pj尽量接近图片的真实标签��yj。计算目标函数关于�������Softmax分类器的参数�W和�b的梯度,使用梯度下降法更新分类器参数。
除了学习�������Softmax分类器参数,也可以让梯度传播至卷积神经网络,更新卷积神经网络参数,使其提取的特征更有效。
3.1 Fine Tuning技巧
由于Support Set中样本数量非常少,使用上述传统迁移学习中的Fine Tuning方法训练�������Softmax分类器效果一般不好,在小样本学习领域,在Support Set上进行Fine Tuning必须使用一定技巧。
3.1.1 A Good Initialization
FineTuning阶段的目标是在Support Set中学习一个�������Softmax分类器,分类器的参数是�W和�b。由于Support Set中样本数量非常少,一般会把�������Softmax分类器的参数�W初始化为�M,�b初始化为全0向量。
根据2.1所述使用预训练模型进行小样本分类方法,如果只使用Pretraining而不使用Fine Tuning,相当于将�������Softmax分类器的参数�W初始化为�M,�b初始化为全0向量。这样设置,哪怕不进行Fine Tuning,也能够有不错的效果。因此相比较于传统迁移学习中的随机初始化,这种将将�������Softmax分类器的参数�W初始化为�M,�b初始化为全0向量的方法是一种非常合理的初始化。
3.1.2 Entropy Regularization
由于Support Set非常小,因此需要在目标函数上添加正则项(Regularization)防止过拟合。在小样本学习领域,一种非常合适的Regularization方法是Entropy Regularization。
神经网络提取图片�x中的特征,得到特征向量�(�)f(x),将�(�)f(x)输入�������Softmax分类器,得到一个表示概率分布的向量�p。计算Support Set中所有样本图片对应的�p向量的Entropy,所有�p向量的Entropy的均值即为Entropy Regularization。
Entropy Regularization是小样本学习领域一个非常合理的Regularization,其原因如下:
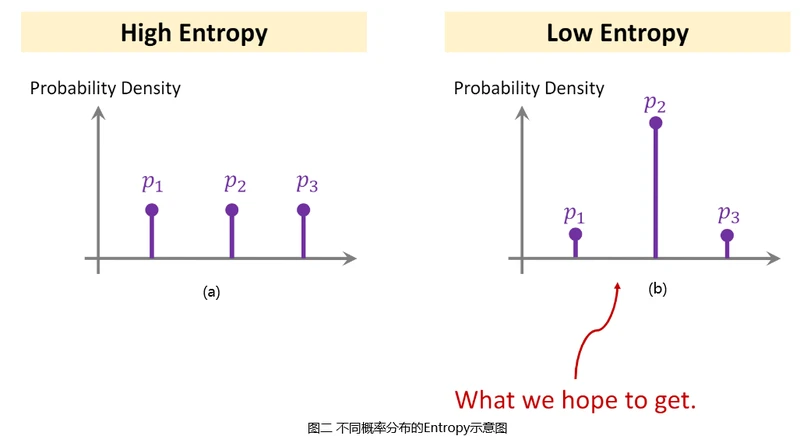
向量�p的Entropy计算公式为:�(�)=−∑���log��H(p)=−∑ipilogpi,其可以用来衡量概率分布�p的信息量。假设小样本分类问题中Support Set共三个类别,�������Softmax分类器输出概率分布p,分别表示每个类别的概率值。
在图二中,左侧图(a)对应的��pa表明输入图片属于三个类别概率几乎相同,这种情况说明分类器无法判别输入图片属于哪一类。右侧图(b)对应的��pb表明输入图片属于第二个类别概率非常大,属于其余类别概率很小,即分类器有较大把握认为输入图片属于第二类。
由于左侧图(a)对应的��pa各个概率值几乎相同,因此��pa对应的Entropy非常大,右侧图(b)对应的��pb某个概率值非常大,其余概率值很小,因此��pb对应的Entropy非常小。左侧图(a)表明分类器无法区分输入图片的类别,右侧图(b)表明分类器有相当大的把握将图片分到某一个类别。
右侧图(b)所示情况即我们期望的概率分布形式,Entropy越小则分类器输出概率分布�p越接近于右侧图(b)所示形式,因此可以在小样本学习领域使用Entropy Regularization。
3.1.3 Cosine Similarity+Softmax Classifier
第三个技巧是结合Cosine Similarity和�������Softmax分类器,根据小样本学习领域的一些最新的论文,这个很小的改进技巧可以显著提高分类准确率。
假设Support Set中共三类,则�������Softmax分类器输出概率分布�=�������(��+�)=�������([�1��+�1�2��+�2�3��+�3])p=Softmax(Wq+b)=Softmax(⎣⎢⎡w1Tq+b1w2Tq+b2w3Tq+b3⎦⎥⎤)。
将Cosine Similarity和�������Softmax分类器相结合,只需将���wiq替换成��wi和�q的Cosine Similarity,即�=�������([���(�1,�)+�1���(�2,�)+�2���(�3,�)+�3])p=Softmax(⎣⎢⎡sim(w1,q)+b1sim(w2,q)+b2sim(w3,q)+b3⎦⎥⎤),其中���(��,�)=����∣∣��∣∣2∣∣�∣∣2sim(wi,q)=∣∣wi∣∣2∣∣q∣∣2wiTq,即��wi和�q的Cosine Similarity。
小样本学习(Few-Shot Learning)(三)
1. 前言
本文使用飞桨(PaddlePaddle)基于paddle.vision.datasets.Flowers数据集实践小样本学习问题的Pretraining+Fine Tuning解法。
2. 预训练神经网络(Pretraining)
使用Pretraining+Fine Tuning方法解决小样本分类问题,首先须预训练一个用于从图片中提取特征卷积神经网络。根据小样本学习(Few-Shot Learning)(二)一文所述预训练方法,预训练步骤如下:
- 在大规模数据集上使用传统分类监督学习方法预训练模型;
- 使用余弦相似度损失继续训练模型。
本文讲解的小样本分类实践,使用了PaddlePaddle内置预训练模型resnet18作为从图片中提取特征的网络模型,加载预训练模型参数代替预训练步骤1,并在paddle.vision.datasets.Flowers 数据训练集上生成预训练步骤2所需训练数据。
2.1 数据处理
从paddle.vision.datasets.Flowers数据训练集中加载前�k类数据,随机生成(anchor_image, positive_image, negative_image)图片对,构造使用余弦相似度训练特征提取模型的训练集。
定义create_emb_model_data_reader函数,依次选择anchor_image,positive_image和negative_image,并返回一个数据读取迭代器:
In [1]
import paddle
from paddle.vision.models import resnet18
import paddle.vision.transforms as transformers
import numpy as np
from typing import Callable
from collections import defaultdict
import random
import warnings
warnings.filterwarnings('ignore')
print(paddle.__version__) # 2.1.0
def create_emb_model_data_reader(chosen_classes: int = 5,
batch_size: int = 32,
num_batches: int = 100) -> Callable:
"""
生成用于训练特征提取网络的数据
:param chosen_classes: 从paddle.vision.datasets.Flowers数据集中选取前chosen_classes个类
:param batch_size: 正负样本总数
:param num_batches: 构建训练数据批次总数
:return: 一个Callable对象
"""
assert chosen_classes >= 2, '训练数据中须包含相同类别图片和不同类别图片,因此类别数必须大于或等于2,' \
'但是接收chosen_classes参数值为:{}'.format(chosen_classes)
assert batch_size % 2 == 0, 'batch_size必须是偶数,但是接收的batch_size参数值为:{}'.format(batch_size)
trans = transformers.Compose([
transformers.Resize((224, 224)), # 将图片大小调整成224x224
transformers.Transpose((2, 0, 1)) # 将图片数据调整成channel_first
])
# 读取数据
flowers_data = paddle.vision.datasets.Flowers(mode='train', transform=trans)
# 筛选出一个小数据集,对整个数据集进行处理速度太慢
# 之所以不随机选择类别,是因为从flowers_data读取数据非常慢
print('正在读取特征提取模型训练数据集……')
mini_flowers_data = []
for flower_data in flowers_data:
if flower_data[1] <= chosen_classes:
mini_flowers_data.append(flower_data)
else:
break
print('读取数据完毕!')
# 将图片按类别分类
class_idx_to_image_idxs = defaultdict(list)
for image, label in mini_flowers_data:
class_idx_to_image_idxs[label.tolist()[0]].append(image / 255.)
def reader():
for _ in range(num_batches):
# 定义存放一个batch数据的numpy数组
# 每条数据包含anchor图片、正样本图片、负样本图片各一张
x = np.empty((3, batch_size // 2, 3, 224, 224), dtype='float32')
for batch_image_idx in range(batch_size // 2):
# 选定抽取的两类图片类别id
images_class_idxs = list(class_idx_to_image_idxs.keys())
base_class_idx = random.choice(images_class_idxs)
negative_class_idx = random.choice(images_class_idxs)
while base_class_idx == negative_class_idx:
negative_class_idx = random.choice(images_class_idxs)
base_examples_for_class = class_idx_to_image_idxs[base_class_idx]
negative_examples_for_class = class_idx_to_image_idxs[negative_class_idx]
# 随机选择图片
anchor_image_idx = random.choice(range(len(base_examples_for_class)))
positive_image_idx = random.choice(range(len(base_examples_for_class)))
while positive_image_idx == anchor_image_idx:
positive_image_idx = random.choice(range(len(base_examples_for_class)))
negative_image_idx = random.choice(range(len(negative_examples_for_class)))
x[0, batch_image_idx] = base_examples_for_class[anchor_image_idx]
x[1, batch_image_idx] = base_examples_for_class[positive_image_idx]
x[2, batch_image_idx] = negative_examples_for_class[negative_image_idx]
yield x
return reader2.1.2
这里吐槽一下,飞桨内置数据集
paddle.vision.datasets.Flowers中__getitem__方法,每次调用会执行image = self.data_tar.extractfile(img_ele).read()从压缩文件中读取数据,使得整个数据读取过程非常慢。
2.2 构建特征提取模型
定义继承自paddle.nn.Layer的FSCEmbNet类,加载PaddlePaddle内置预训练模型resnet18作为backbone,并自定义一个全连接层输出指定维度的特征向量:
In [2]
class FSCEmbNet(paddle.nn.Layer):
"""用于从图片中提取特征的网络
该网络利用预训练的resnet18骨干网络,再连接一个FC层,将图片Embedding层一个指定维度的特征向量
Args:
embedding_dim: 指定将图片映射成多少维的特征向量
"""
def __init__(self, embedding_dim=128):
super(FSCEmbNet, self).__init__()
rn18 = resnet18(pretrained=True)
# 从预训练resnet18模型中将backbone提取出来
# 加载预训练模型的本质,是将模型中各模块参数进行了赋值。灵活地使用预训练模型,可以按照如下方式从模型中提取所需的模块
self.backbone = paddle.nn.Sequential(rn18.conv1, rn18.bn1, rn18.relu, rn18.maxpool,
rn18.layer1, rn18.layer2, rn18.layer3, rn18.layer4,
rn18.avgpool, paddle.nn.Flatten())
self.fc = paddle.nn.Linear(in_features=512, out_features=embedding_dim)
def forward(self, x):
x = self.backbone(x)
x = self.fc(x)
# 将输出向量归一化
x = x / paddle.norm(x, axis=1, keepdim=True)
return x2.3 预训练特征提取模型
定义函数train_emb_model,实例化FSCEmbNet模型对象,定义Adam优化器,固定resnet18模型参数,传入特征提取模型中自定义全连接层参数作为优化参数。
使用FSCEmbNet分别提取anchor_image,positive_image和negative_image特征向量,并计算余弦相似度。构造训练数据集标签,并使用图片之间的余弦相似度与标签的均方误差作为损失函数。
计算损失函数关于模型参数的梯度,并优化相关参数:
In [3]
def train_emb_model(epochs: int,
batch_size: int,
learning_rate: float,
data_reader: Callable,
embedding_dim: int = 128) -> None:
"""
训练图片特征提取网络
:param epochs: 生成的训练数据集迭代的次数
:param batch_size: 每个batch数据量
:param learning_rate: 学习率
:param data_reader: 训练数据读取器,每次读取一个batch的数据
:param embedding_dim: 将图片转换成特征向量的维度
:return:
"""
emb_model = FSCEmbNet(embedding_dim=embedding_dim)
emb_model.train()
# 定义优化器,只训练fc层参数
opt = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=emb_model.fc.parameters())
for epoch in range(epochs):
for batch_id, batch_data in enumerate(data_reader()):
# 分别获取anchor数据、正样本数据、负样本数据
anchors_data, positives_data, negatives_data = batch_data[0], batch_data[1], batch_data[2]
anchors = paddle.to_tensor(anchors_data)
positives = paddle.to_tensor(positives_data)
negatives = paddle.to_tensor(negatives_data)
# 得到三种数据对应的特征向量
anchors_embedding = emb_model(anchors)
positives_embedding = emb_model(positives)
negatives_embedding = emb_model(negatives)
# 生成标签
label = paddle.concat([paddle.ones([batch_size // 2, ]), paddle.zeros([batch_size // 2, ])])
# 计算余弦相似度
positives_similarity = paddle.nn.functional.cosine_similarity(anchors_embedding, positives_embedding)
negatives_similarity = paddle.nn.functional.cosine_similarity(anchors_embedding, negatives_embedding)
# 拼接成最终输出
similarity = paddle.concat([positives_similarity, negatives_similarity])
# 计算损失
loss = paddle.nn.functional.mse_loss(similarity, label)
if (batch_id + 1) % 50 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch+1, batch_id+1, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
# 训练完保存模型参数
paddle.save(emb_model.state_dict(), 'models/emb_model.pdparams')指定emb_epochs = 10,emb_batch_size = 32,emb_learning_rate = 0.0005,chosen_classes = 25,调用create_emb_model_data_reader函数生成训练数据迭代器,并调用train_emb_model函数训练特征提取模型:
In [4]
# 训练特征提取网络
emb_epochs = 10
emb_batch_size = 32
emb_learning_rate = 0.0005
chosen_classes = 25
# 创建训练数据读取器
emb_data_reader = create_emb_model_data_reader(chosen_classes=chosen_classes, batch_size=emb_batch_size)
train_emb_model(epochs=emb_epochs, batch_size=emb_batch_size, learning_rate=emb_learning_rate,
data_reader=emb_data_reader)Cache file /home/aistudio/.cache/paddle/dataset/flowers/102flowers.tgz not found, downloading http://paddlemodels.bj.bcebos.com/flowers/102flowers.tgz Begin to download Download finished Cache file /home/aistudio/.cache/paddle/dataset/flowers/imagelabels.mat not found, downloading http://paddlemodels.bj.bcebos.com/flowers/imagelabels.mat Begin to download . Download finished Cache file /home/aistudio/.cache/paddle/dataset/flowers/setid.mat not found, downloading http://paddlemodels.bj.bcebos.com/flowers/setid.mat Begin to download .... Download finished
正在读取特征提取模型训练数据集…… 读取数据完毕!
100%|██████████| 69183/69183 [00:02<00:00, 34434.08it/s]
epoch: 1, batch_id: 50, loss is: [0.1479936] epoch: 1, batch_id: 100, loss is: [0.09583269] epoch: 2, batch_id: 50, loss is: [0.07862969] epoch: 2, batch_id: 100, loss is: [0.08754252] epoch: 3, batch_id: 50, loss is: [0.06303474] epoch: 3, batch_id: 100, loss is: [0.12130889] epoch: 4, batch_id: 50, loss is: [0.09460499] epoch: 4, batch_id: 100, loss is: [0.07076697] epoch: 5, batch_id: 50, loss is: [0.04907225] epoch: 5, batch_id: 100, loss is: [0.08168642] epoch: 6, batch_id: 50, loss is: [0.03804927] epoch: 6, batch_id: 100, loss is: [0.07668801] epoch: 7, batch_id: 50, loss is: [0.07033476] epoch: 7, batch_id: 100, loss is: [0.0767039] epoch: 8, batch_id: 50, loss is: [0.05300082] epoch: 8, batch_id: 100, loss is: [0.06635693] epoch: 9, batch_id: 50, loss is: [0.04415393] epoch: 9, batch_id: 100, loss is: [0.10611122] epoch: 10, batch_id: 50, loss is: [0.04935977] epoch: 10, batch_id: 100, loss is: [0.07397036]
3. Fine Tuning
使用小样本学习(Few-Shot Learning)(二)一文所述Fine Tuning方法及A Good Initialization、Entropy Regularization和Cosine Similarity+Softmax Classifier技巧在Support Set中微调分类器参数。
3.1 生成Support Set与测试集
定义create_support_set_and_test_dataset函数,从paddle.vision.datasets.Flowers数据测试集前�k类中随机选择部分数据,并划分成support_set和test_set:
In [5]
def create_support_set_and_test_dataset(chosen_classes: int = 5,
num_shot: int = 2,
num_test: int = 5):
"""
从paddle.vision.datasets.Flowers数据集的测试集中选取support set和测试数据
:param chosen_classes: 选取的类别数
:param num_shot: Support set中每个类别选取多少个样本
:param num_test: 测试数据中每个类别选取多少个样本
:return:
"""
trans = transformers.Compose([
transformers.Resize((224, 224)), # 将图片大小调整成224x224
transformers.Transpose((2, 0, 1)) # 将图片数据调整成channel_first
])
flowers_data = paddle.vision.datasets.Flowers(mode='test', transform=trans)
# 筛选出一个小数据集,对整个数据集进行处理速度太慢
# 之所以不随机选择类别,是因为从flowers_data读取数据非常慢
print('正在读取类别预测模型训练数据集……')
mini_flowers_data = []
for flower_data in flowers_data:
if flower_data[1] <= chosen_classes:
mini_flowers_data.append(flower_data)
else:
break
print('数据读取完毕!')
# 将图片按类别分类
class_idx_to_images = defaultdict(list)
for image, label in mini_flowers_data:
class_idx_to_images[label.tolist()[0]].append(image / 255.)
# 检测选择的各类别中时候样本数均比num_shot+num_test大
# 之所以不随机选择类别,是因为从flowers_data读取数据非常慢
for key in class_idx_to_images.keys():
assert num_shot + num_test < len(class_idx_to_images[key]), \
'num_shot和num_test值过大,检测到某类数据图片数为:{}'.format(len(class_idx_to_images[key]))
support_set = defaultdict(list)
test_set = defaultdict(list)
for class_id in class_idx_to_images.keys():
total_samples = random.sample(class_idx_to_images[class_id], num_shot + num_test)
support_set[class_id] = total_samples[:num_shot]
test_set[class_id] = total_samples[-num_test:]
return support_set, test_set3.2 构建小样本分类问题预测网络
定义继承自paddle.nn.Layer的FSCPredictor类,自定义小样本学习(Few-Shot Learning)(二)一文所述�������Softmax分类器参数�W和�b,并使用A Good Initialization技巧初始化参数矩阵�W。在forward函数中使用Cosine Similarity+Softmax Classifier计算��wi和�q的Cosine Similarity:
In [6]
class FSCPredictor(paddle.nn.Layer):
"""小样本分类问题预测网络
Args:
embedding_net: 将图片映射成特征向量的网络
support_set: 小样本分类问题的Support Set
"""
def __init__(self, embedding_net, support_set):
super(FSCPredictor, self).__init__()
self.embedding_net = embedding_net
self.embedding_net.eval()
# 将Support Set中各类别图片全部转换成特征向量,并求平均,得到M矩阵
matrix_m = []
for class_id in support_set.keys():
one_class = paddle.to_tensor(support_set[class_id])
class_embs = embedding_net(one_class)
this_emb = paddle.mean(class_embs, axis=0)
matrix_m.append(this_emb.numpy())
matrix_m = np.array(matrix_m, dtype='float32')
# 创建Softmax分类器中的参数W和b
softmax_classifier_w = self.create_parameter(shape=list(matrix_m.shape),
default_initializer=paddle.nn.initializer.Assign(matrix_m))
softmax_classifier_b = self.create_parameter(shape=[matrix_m.shape[0]], is_bias=True)
self.add_parameter('softmax_classifier_w', softmax_classifier_w)
self.add_parameter('softmax_classifier_b', softmax_classifier_b)
def forward(self, x):
x = self.embedding_net(x)
# 根据fine tuning技巧,计算w和b的余弦相似度,需要将self.softmax_classifier_w进行归一化
normed_w = self.softmax_classifier_w / paddle.norm(self.softmax_classifier_w, axis=1, keepdim=True)
normed_w = paddle.transpose(normed_w, [1, 0])
# x不需要进行归一化,因为embedding_net输出已经进行归一化了
x = paddle.matmul(x, normed_w)
x = x + self.softmax_classifier_b
return x3.3 训练小样本分类问题预测网络
定义函数train_predictor,实例化FSCPredictor模型对象,定义Adam优化器,固定embedding_model模型参数,传入�W和�b作为优化参数。
使用预测网络输出与Support Set中图片类别标签的������������CrossEntropy作为损失函数,优化相关参数:
In [7]
def train_predictor(embedding_model: paddle.nn.Layer,
support_set: defaultdict,
epochs: int,
learning_rate: float,
use_entropy_regularization: bool = True) -> None:
"""
训练小样本分类问题预测器
:param embedding_model: 用于提取图片特征的网络
:param support_set: 小样本分类问题的Support set
:param epochs: 训练预测器的数据迭代轮数
:param learning_rate: 训练分类器的学习率
:param use_entropy_regularization: 是否使用entropy regularization
:return:
"""
predictor = FSCPredictor(embedding_net=embedding_model, support_set=support_set)
predictor.train()
# 只学习Softmax分类器中的参数W和b
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=[predictor.softmax_classifier_w, predictor.softmax_classifier_b])
for epoch in range(epochs):
# 将整个Support set作为训练数据
input_datas = []
labels = []
for class_id in support_set:
input_datas += support_set[class_id]
labels += [class_id - 1] * len(support_set[class_id])
input_datas = paddle.to_tensor(input_datas)
labels = paddle.to_tensor(labels, dtype='int64')
logits = predictor(input_datas)
loss = paddle.nn.functional.cross_entropy(logits, labels)
if use_entropy_regularization:
# 计算Entropy Regularization,向量p的entropy等于自己和自己的cross_entropy
softmaxed_logits = paddle.nn.functional.softmax(logits)
entropy_regularization = paddle.nn.functional.cross_entropy(softmaxed_logits, softmaxed_logits,
use_softmax=False, soft_label=True)
loss += entropy_regularization
if (epoch + 1) % 20 == 0:
print("epoch: {}, loss is: {}".format(epoch+1, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
# 训练完保存参数
paddle.save(predictor.state_dict(), 'models/predictor.pdparams')指定predictor_epochs = 200,predictor_learning_rate = 0.0005,调用create_support_set_and_test_dataset函数生成Support Set与训练集,实例化emb_model,并调用train_predictor函数训练预测网络:
In [8]
# 训练小样本分类问题预测器
predictor_epochs = 200
predictor_learning_rate = 0.0005
support_set, test_set = create_support_set_and_test_dataset()
# 加载训练好的特征提取网络
emb_model = FSCEmbNet()
emb_model_state_dict = paddle.load('models/emb_model.pdparams')
emb_model.set_state_dict(emb_model_state_dict)
# 开始训练
train_predictor(emb_model, support_set, epochs=predictor_epochs, learning_rate=predictor_learning_rate)正在读取类别预测模型训练数据集…… 数据读取完毕! epoch: 20, loss is: [2.5981064] epoch: 40, loss is: [2.56492] epoch: 60, loss is: [2.539666] epoch: 80, loss is: [2.52052] epoch: 100, loss is: [2.5059874] epoch: 120, loss is: [2.494969] epoch: 140, loss is: [2.486631] epoch: 160, loss is: [2.4803236] epoch: 180, loss is: [2.475542] epoch: 200, loss is: [2.4719038]
4. 小样本分类模型测试
定义test函数,分别计算测试集中各类别准确率及在整个测试集上的小样本分类准确率:
In [9]
def test(predictor: paddle.nn.Layer,
test_set: defaultdict) -> None:
"""
测试小样本分类模型
:param predictor: 小样本分类问题预测器
:param test_set: 测试集
:return:
"""
total_test_samples_num = 0
total_right_samples_num = 0
print('============================================================')
for class_id in test_set.keys():
this_class_data = test_set[class_id]
this_class_samples_num = len(this_class_data)
total_test_samples_num += this_class_samples_num
this_class_data = paddle.to_tensor(this_class_data)
predict_this_class = predictor(this_class_data)
predict_label = paddle.argmax(predict_this_class, axis=1).numpy()
this_right_samples_num = np.sum(predict_label == (class_id - 1))
total_right_samples_num += this_right_samples_num
print('当前类别标签:{},该类样本数:{},预测正确数:{},该类预测准确率:{:.2f}'.format(class_id,
this_class_samples_num, this_right_samples_num,
this_right_samples_num/this_class_samples_num))
print('测试负样本总数:{},预测正确总数:{},预测准确率:{:.2f}'.format(total_test_samples_num, total_right_samples_num,
total_right_samples_num / total_test_samples_num))实例化小样本分类预测模型,加载训练参数,并调用test函数:
In [10]
support_set, test_set = create_support_set_and_test_dataset()
predictor = FSCPredictor(FSCEmbNet(), support_set)
predictor_state_dict = paddle.load('models/predictor.pdparams')
predictor.set_state_dict(predictor_state_dict)
test(predictor, test_set)正在读取类别预测模型训练数据集…… 数据读取完毕! ============================================================ 当前类别标签:1,该类样本数:5,预测正确数:5,该类预测准确率:1.00 当前类别标签:2,该类样本数:5,预测正确数:5,该类预测准确率:1.00 当前类别标签:3,该类样本数:5,预测正确数:3,该类预测准确率:0.60 当前类别标签:4,该类样本数:5,预测正确数:5,该类预测准确率:1.00 当前类别标签:5,该类样本数:5,预测正确数:5,该类预测准确率:1.00 测试负样本总数:25,预测正确总数:23,预测准确率:0.92
相关论文:
- Feifei L , Fergus R , Perona P . One-shot learning of object categories[J]. IEEE Trans Pattern Anal Mach Intell, 2006, 28(4):594-611.
- Bromley J , Guyon I , Lecun Y , et al. Signature Verification Using a Siamese Time Delay Neural Network[C]// Advances in Neural Information Processing Systems 6, [7th NIPS Conference, Denver, Colorado, USA, 1993]. 1993.
- G Koch, R Zemel, R Salakhutdinov. Siamese Neural Networks for One-shot Image Recognition.
- Schroff, Kalenichenko, & Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, 2015.
- Dhillon G S , Chaudhari P , Ravichandran A , et al. A Baseline for Few-Shot Image Classification[J]. arXiv, 2019.
- Chen Y , Wang X , Liu Z , et al. A New Meta-Baseline for Few-Shot Learning[J]. 2020.
- Authors A . A CLOSER LOOK AT FEW-SHOT CLASSIFICATION[J]. 2019.
参考资料链接
- https://www.youtube.com/watch?v=UkQ2FVpDxHg&list=PLvOO0btloRnuGl5OJM37a8c6auebn-rH2&index=1
- https://www.youtube.com/watch?v=Er8xH_k0Vj4&list=PLvOO0btloRnuGl5OJM37a8c6auebn-rH2&index=2
- DeepLearning/Slides/16_Meta_1.pdf at master · wangshusen/DeepLearning · GitHub
- DeepLearning/Slides/16_Meta_2.pdf at master · wangshusen/DeepLearning · GitHub
- https://www.youtube.com/watch?v=3zSYMuDm6RU&list=PLvOO0btloRnuGl5OJM37a8c6auebn-rH2&index=3
- DeepLearning/Slides/16_Meta_3.pdf at master · wangshusen/DeepLearning · GitHub
- https://www.paddlepaddle.org.cn/documentation/docs/zh/tutorial/cv_case/convnet_image_classific