
欢迎关注WX公众号:【程序员管小亮】
sklearn.naive_bayes.MultinomialNB()函数全称是先验为多项式分布的朴素贝叶斯。
除了MultinomialNB之外,还有GaussianNB就是先验为高斯分布的朴素贝叶斯,BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
class sklearn.naive_bayes.MultinomialNB(alpha=1.0,
fit_prior=True,
class_prior=None)
MultinomialNB假设特征的先验概率为多项式分布,即如下式:
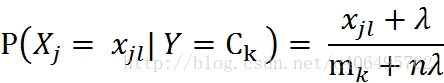
其中,
P
(
X
j
=
X
j
l
∣
Y
=
C
k
)
P(X_j = X_{jl} | Y = C_k)
P(Xj=Xjl∣Y=Ck) 是第
k
k
k 个类别的第
j
j
j 维特征的第
l
l
l 个取值条件概率。
m
k
m_k
mk 是训练集中输出为第
k
k
k 类的样本个数。
λ
λ
λ 为一个大于0的常数,尝尝取值为1,即拉普拉斯平滑,也可以取其他值。
参数:
alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior,让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为 P ( Y = C k ) = m k / m P(Y=C_k)=m_k/m P(Y=Ck)=mk/m。其中m为训练集样本总数量, m k m_k mk为输出为第k类别的训练集样本数。class_prior:可选参数,默认为None。
| fit_prior | class_prior | 最终先验概率 |
|---|---|---|
| False | 填或不填没有意义 | P ( Y = C k ) = 1 / k P(Y = C_k) = 1 / k P(Y=Ck)=1/k |
| True | 不填 | P ( Y = C k ) = m k / m P(Y = C_k) = m_k / m P(Y=Ck)=mk/m |
| True | 填 | P ( Y = C k ) = c l a s s _ p r i o r P(Y = C_k) = class\_prior P(Y=Ck)=class_prior |
还有其他参数:
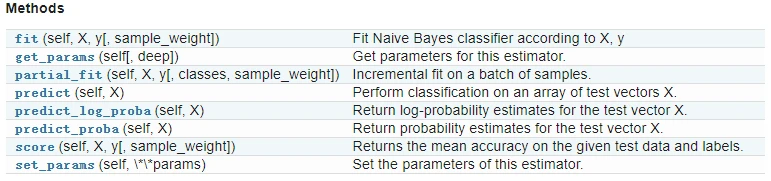
例子:
>>> import numpy as np
>>> X = np.random.randint(5, size=(6, 100))
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> from sklearn.naive_bayes import MultinomialNB
>>> clf = MultinomialNB()
>>> clf.fit(X, y)
MultinomialNB()
>>> print(clf.predict(X[2:3]))
[3]