
前言
到目前为止还没跑通,但是bug实在太多了,我的每一步都有错,如果不记录下来又会有遗漏,(肯定已经遗漏了很多),在这里把能想起来的都记录一下以便不时之需。另外,本人深度学习小白,一上来跑这么难的代码我大概是脑子进水了,如果有看到的话,十分欢迎且需要加微信跟我详细交流。以下纯属我个人理解,肯定有误差,仅为个人记录,请酌情参考。
9.29更新:能跑了能跑了,喜大普奔!!
10.1更新:evaluation出结果啦,准确率还真挺高!!
10.21更新:发现了之前几个疑惑的点的原因(写在最后)
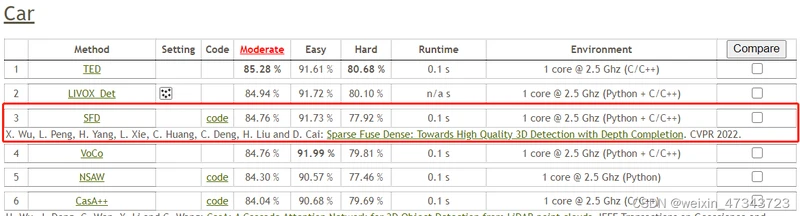
10.25更新:补齐SFD方法简介。
SFD简介
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion. CVPR 2022.
在kitti数据集上目前排名前三,文章通俗易懂(也可能是我没看懂)
(这部分后面再补吧)
文章贡献:
- 3D-GAF:融合点云和伪点云的网络
- SynAugment:针对SFD的数据增强方法
- CPConv:伪点云的特征提取器
这里有一个疑惑是: CPConv在3D-GAF前使用,但是作者却放在了最后一位介绍它,按逻辑来讲,放在后面的应该是最不重要的,但是3D-GAF反而是里面最难理解的。
个人理解: 最主要的创新在于——之前的方法都是FOV与BEV的2D融合,而本方法将2D信息通过深度转化为3D,使得在每个ROI中提取伪点云和原始点云的3D特征(在3D网格内),再按权重融合、reshanpe、FC。(这可能就是3D-GAF放在第一位的原因吧)。但是我还是没能理解CPConv,主要是维度变换好凌乱,一会儿N个一会儿K个,感觉还是需要输出看维度。
最后一个疑惑是: 从实验结果看,没有加这些操作的准确率就很高,因为本身的baseline准确率就很高,但并不知道baseline这么高的原因是?
代码调试
SFD:Github官方源码
环境配置
作者提供了两种方式:Voxel-R-CNN或者OpenPCDet,此处使用了后者。OpenPCDet安装步骤提供在如下链接,特别要提醒的是该文章中sudo apt-get install nvidia-cuda-toolkit命令千万千万不要在系统中输入,否则会导致你cuda,cudnn全部重装!!!其余按照步骤来就好。另外,文章中提到mayavi包的安装会出问题,其实我没有安装mayavi包的时候,OPenPDCet就能正常运行。但是SFD还是需要安装mayavi,终究还是逃不过。由于各种原因,我的Python是3.8版本,如果你也是python3.8的话,可参考链接安装mayavi包,最终需要在图形化界面运行以下命令(如:远程桌面连接或者vnc,反正不是ssh),否则会报错。
python demo.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --ckpt pv_rcnn_8369.pth --data_path data/kitti/training/velodyne/000008.bin
组织数据集
接着就按github上作者提供的路径下载数据集和相关文件。需要注意的是,这里的数据有70G+,所以要事先想好你是不是要挂载目录什么的,不要像我一样傻乎乎弄了半天发现服务器存储空间不够了(我真是哭死,也没人告诉我啊)。
问题报错
以下问题当你出错了再来查看,参考知乎连接包括:spconv包出错和单卡环境运行问题。
RunTimeError问题
原因: 因为服务器上只有两个gpu且不知道好不好用,总之按作者提供的方式运行就会报各种cuda错误,所以做出如下修改(因为时间过去有点久了,所以应该不全)。
首先,不使用文章中的命令,在终端中输入以下命令测试:
python train.py --cfg_file cfgs/kitti_models/sfd.yaml --batch_size 2
PS: 这里batch_size先设置成1就能跑起来,如果设置成2会报出很多错,下面会一一解决batch_size=2的问题。
1. DataLoader worker (pid xxx) is killed by signal
将num_workers设置为0,也就是\tools\train.py第27行,default =0
parser.add_argument('--workers', type=int, default=0, help='number of workers for dataloader')
2. No CUDA GPUs are available/Cuda out of memory
# tools/train.py
# 62行修改为0
os.environ["CUDA_VISIBLE_DEVICES"]="0"
# 这里根据你的需要来,如果gpu显存不够会报Cuda out of memory的错误
# os.environ["CUDA_VISIBLE_DEVICES"]="-1" #表示用cpu
KeyError问题
1.KeyError: ‘KittiDatasetSFD’
详细查看发现输出的根目录在OpenPCDet文件夹下,虽然我不知道为什么会代码会跑到这里,但是只要把OpenPCDet和SFD两个项目文件不要放在同一个文件夹下就可以解决。(即:把OpenPCDet藏得远远的)。github的issue里也有人有这个错误,不知道是不是跟我一样的情况。
cfg.ROOT_DIR总是会自动找错地方,就会发生KeyError或者DataLoader=0等问题,可以检查一下路径对不对。
2.KeyError: ‘road_plane’
在sfd.yaml文件中第12行
USE_ROAD_PLANE: Flase
TypeError
当batch_size=2时,kitti_dataset_spf.py中会报TypeError,是‘valid_noise’这个Key出了问题,参考知乎连接在for循环(约400行)前加入
data_dict = data_dict.pop('valid_noise')
会报其他的错误-----说是list没有item()方法,不懂==。干脆在上一个for循环里直接删除,代码如下:
#485行左右
for key, val in cur_sample.items():
(+) if key == 'valid_noise':
(+) continue
data_dict[key].append(val)
Sponcv包出错问题
这里先说明我安装的是sponcv2.1版本,也就是自动安装的

之后会报关于sponcv的各种错误,要做以下几处修改才能解决:
1. AttributeError: module ‘spconv‘ has no attribute ‘SparseModule‘
import spconv 要改写成 import spconv.pytorch as spconv
2. 我也不太记得了,总之要按照这个链接Github把所有报错(??)的文件都更改一遍,刚开始抱着试试看的态度逐行修改,确实不报错了。
理论上是应该把所有github中提到的文件都修改一遍,但我是哪里报错改哪里,所以只改了以下文件:
data_processor.py
dataset.py
detector3d_template.py
spconv_utils.py
AssertionError
AssertionError: must be contiguous tensor
model/roi_heads/sfd_head.py
#约第600行,更改如下
coords = sparse_idx.int().contiguous()
ModuleNotFoundError
重新运行setup
cd SFD
python setup.py develop
cd pcdet/ops/iou3d/cuda_op
python setup.py develop
cd ../../../..
NotImplementError或者是NAN的问题
具体错误如下
File "/home/tianran/workdir/SFD/pcdet/models/roi_heads/target_assigner/proposal_target_layer.py", line 162, in subsample_rois
raise NotImplementedError
NotImplementedError
maxoverlaps:(min=nan, max=nan)
ERROR: FG=0, BG=0
解决方案(此处参考知乎链接和github上的issue):
(必选) 在sfd_head_utils.py的points_features[:, 3:6] /= 255.0这一行代码后增加:
from torch.nn.functional import normalize
points_features[:, :3] = normalize(points_features[:, :3], dim=0)
points_features[:, 6:] = normalize(points_features[:, 6:], dim=0)
(可选)
sfd.yaml文件中配置如下参数:(可选择性尝试)
LR = 0.01 #(缩小十倍)
REG_Loss: giou # 换成diou
batch_size =1
验证阶段
assert lidar_file.exists()
# kitti_dataset_sfd.py 大约29行修改为以下内容
self.split = 'test' # self.dataset_cfg.DATA_SPLIT[self.mode] #{'train': 'train', 'test': 'val'}
# 62行左右,个人感觉这里有点问题,因为 self.split要么是train要么是val,不可能是test,所以就不可能跑到test路径下验证
self.root_split_path = self.root_path / ('training' if self.split != 'test' else 'testing') #这里没有改,只是写出来说明一下
准确率虽然运行出来了,0.7IOU大约94%,但我发现更改.txt文件并不会修改载入的数据量,似乎该载入什么数据早已在.pkl文件里写好了,这我就不能理解了,甚至产生了一个邪恶的想法。应该是因为代码太复杂我还理解不了吧,谁能告诉我原因吗?
刚开始有一点点眉目,老师就让我滚去做双目,好吧,先尝试到这里吧,花费三周时间跑代码,啊啊啊真可怕。
未完成的事情
1.模型的保存
2.如何评估准确率 √
3.准确率的问题 √
4.gpu多卡pytorch分布式训练;
5.结果可视化
6.跑自己的数据集
更新
- 为什么修改ImageSet文件夹下的.txt文件修改后训练的数据仍不变?
以下命令会根据你的.txt文件、配置文件等写入.pkl文件中,之后运行就只会用到.pkl文件,所以若想修改训练或测试数据集,需要再次生成一个.pkl文件。
python -m pcdet.datasets.kitti.lidar_kitti_dataset create_kitti_infos
- 会自动寻找到其他的文件夹下的文件
环境路径查找优先顺序需要调整,可参考链接中的Error7调整环境路径。