
一、什么是量表
量表是一种测量工具,通常用来测量人们的主观态度、意见或价值观念。我们经常会在问卷中使用量表对调查对象进行测量,最常见到的就是李克特量表。
1、定义:李克特量表
李克特量表是最常用的量表,是由美国社会心理学家李克特于1932年在原有的总加量表基础上改进而成的。这种量表由一组与某个主题相关的问题或陈述构成,通过计算量表中各题的总分,可以了解人们对该调查主题的综合态度或看法。
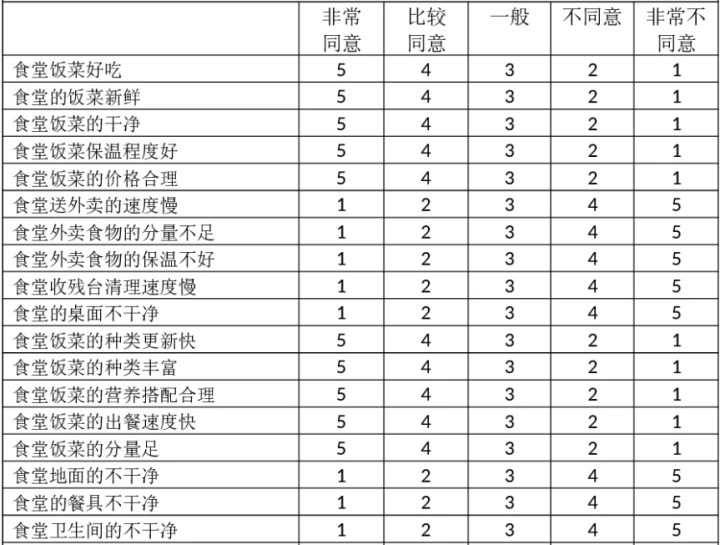
李克特量表的尺度形式有多种,我们常见是五级量表,即五个答项:"非常同意"、"同意"、"不一定"、"不同意"、"非常不同意"五种回答,分别记为1,2,3,4,5,每个被调查者的态度总分就是他对各道题的回答所的分数的加总,这一总分可说明他的态度强弱或她在这一量表上的不同状态。另外还会有七级量表、九级量表或者四级量表等。
2、李克特量表使用场景
李克特量表非常适合深入挖掘一个特定主题,详细地找出人们对这一主题的看法。所以,想获取更多信息的时候就可以使用李克特量表。例如: 了解消费者近期对产品的满意度情况 了解某个人群心理状态和影响因素情况 了解员工对工作的看法情况或者需要衡量特定事物情绪或其他问题,并且希望在答案中获得更深层次的详细信息,李克特量表都是不二选择。
3、李克特量表常用分析方法
除了常规的频数分析、计算平均值等,李克特量表同样适用于更多更专业的分析方法:
-
量表可靠性、有效性分析:信度分析、效度分析
-
差异关系:方差分析
-
影响关系:相关分析、回归分析
-
其他研究:调节作用、中介作用、调节中介作用等
4、李克特量表制作方法
常见的问卷网站里都提供有很多领域专业的量表问卷模板,需要直接点击复制到自己的问卷中就可以对问卷进行编辑处理了。
二、信效度分析
1、什么是信度&效度
(1)信度
信度分析用于测量样本回答结果是否可靠,即样本有没有真实作答量表类题项;
信度分析仅针对定量数据。
重要提示: 信度分析仅仅是针对量表数据,非量表数据一般不进行信度分析。
(2)效度
效度分析在学术研究中非常常见,其用于分析‘测量项是否真实有效地测量自己希望测量的变量’,效度分析的研究方式有多种,通常包括内容效度、结构效度(探索性因子分析法)、区分效度和收敛效度(验证性因子分析法)。可见下表格:

2、怎么做信度&效度分析
(1)信度分析
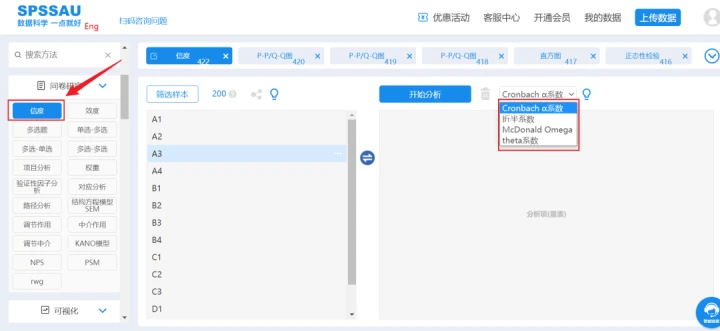
Cronbach信度分析是最为常见,使用最为广泛的一种测量方法,直接使用一个指标即Cronbach信度系数值来描述信度水平情况。
克隆巴赫信度系数(Cronbach α系数值)如果在0.8以上,则该测验或量表的信度非常好;
信度系数在0.7以上都是可以接受;
如果在0.6以上,则该量表应进行修订,但仍不失其价值;
如果低于0.6,量表就需要重新设计题项。
-
SPSSAU信度分析操作
信度分析仅仅是针对量表数据,需要对每一具体细分维度或者变量进行分析。
本例子中涉及4个维度,则分别需要进行4次操作,然后将4次操作的结果整理合并整理成一个表格用于研究报告中输出。以其中一个维度为例:
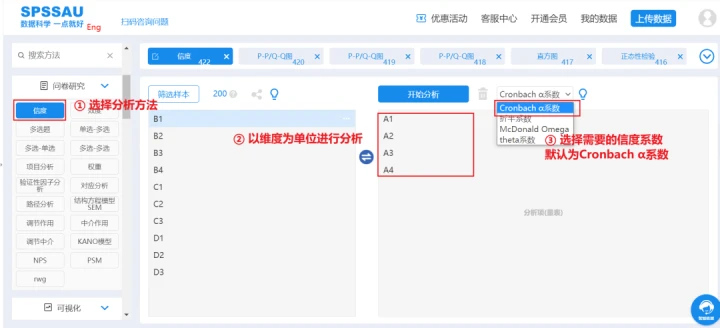
-
SPSSAU输出结果:
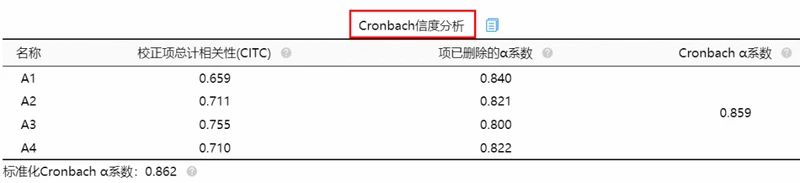
如果是正式数据进行信度分析,则上表格中仅0.859这个数字进行报告即可。四个维度则有四个α系数值。可将此4个值进行整理最终报告如下表所示:

(2)效度分析
3、疑难解惑:信效度不达标
(1)信度不达标怎么办?
建议按照以下七步检查:
① 使用 ‘ 描述分析 ’ 检验下是否有奇怪的异常值,如果有则需要使用 ‘ 数据处理->异常值 ’ 功能处理后再分析;
②‘ 非量表 ’ 数据是不能进行信度分析,只需要用文字进行描述证明数据凭什么可信,比如如何设计问卷如何收集数据,数据为什么可信等,有没有进行过异常值处理等;
③ 如果信度系数值依然很低(比如低于0.5),此时可考虑把所有量表题合并在一起进行一次信度分析(题项越多通常信度系数会越高);
④ 如果数据中有反向题,需要先使用 ‘ 数据处理->数据编码 ’ 将反向题处理后再分析;
⑤删除不合理的项,留下有意义的项;
⑥加大样本量,样本量越大通常情况下信度会越高;
⑦ 问卷设计时一个维度尽量4~7个题较好,题项越多信度会越高,而且如果不达标还可以删除个别不合理项。
(2)效度不达标怎么办?
针对问卷量表数据(重要提示:效度分析仅仅是针对量表数据),可以进行效度分析。效度分析需要注意以下几点:
1、效度分析时,是综合各项指标进行综合判断,包括KMO值,巴特球形检验,方差解释率,累积方差解释率值,因子载荷系数值,维度和题项对应关系等。
2、效度分析时, 很可能需要删除题目,以便于维度和题项对应关系符合预期。
3、效度分析时, 最关键的地方在于:维度和题项对应关系,是否与专业预期符合;其余指标相应比较容易达标,最核心的是让维度和题项对应关系保持基本一致性。
4、效度分析时,是个多次 来回重复对比的过程,很可能重复进行很多次,对比删除题目后找出最优结果。
5、如果分析题目专业预期应该对应5个维度,则应该先设置成数字5。
三、量表类数据分析
1、关系研究方法
(1)相关分析
相关分析可用于研究量表维度之间的相关关系
例如:研究 “淘宝客服服务态度” 与 “淘宝商家服务质量” 之间的相关关系。
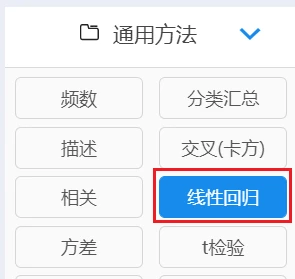
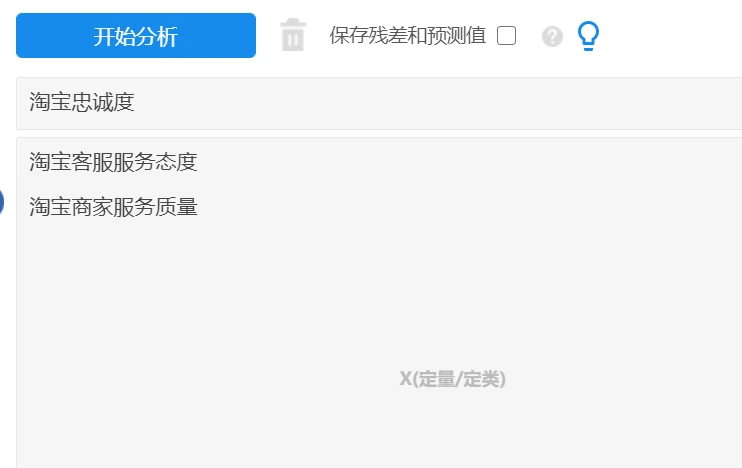
(2)回归分析
回归分析可用于研究量表维度之间的影响关系。
例如:研究 “ 淘宝客服服务态度 ” , “ 淘宝商家服务质量 ” 与 “ 淘宝忠诚度 ” 之间的关系情况,此句话中明显的可以看出 “ 淘宝客服服务态度 ” ,“ 淘宝商家服务质量 ” 这两项为 X;而
“ 淘宝忠诚度 ” 这项为 Y。
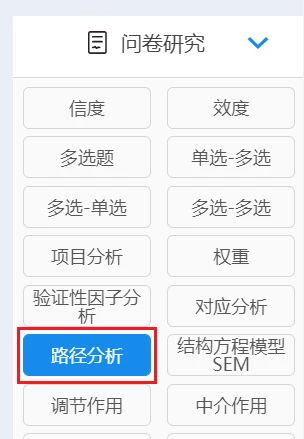
(3)路径分析
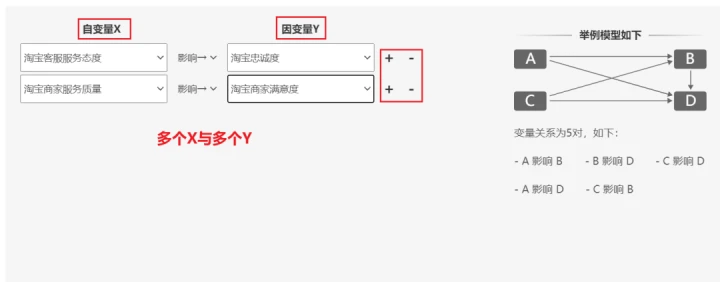
路径分析可用于研究量表维度之间的影响关系。
路径分析、线性回归均可以研究影响关系;
二者区别为路径分析可同时研究多个自变量,多个因变量的影响关系情况。而线性回归每次分析时只能有一个因变量。
2、差异研究方法
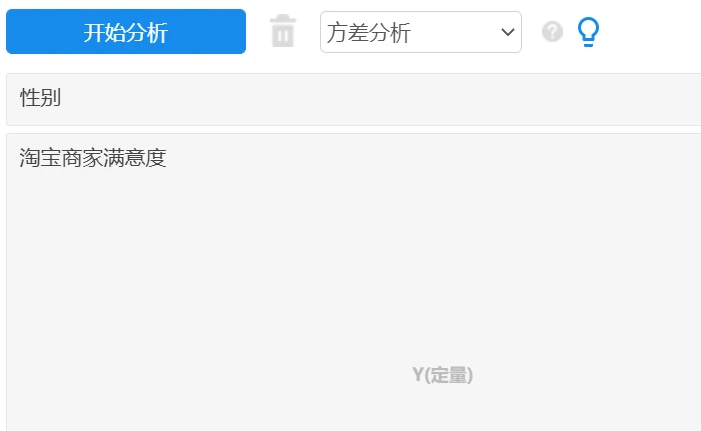
方差分析,研究个体属性(比如性别)与量表维度之间的认知差异关系。
例如:研究性别与 “ 淘宝商家满意度” 之间的差异关系。
3、其他研究方法
(1)调节作用
调节作用是研究X对Y的影响时,是否会受到调节变量Z的干扰。
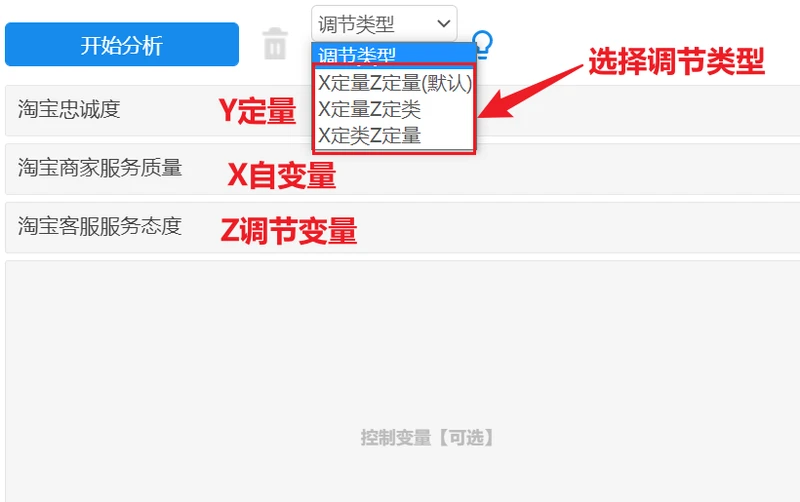
结合自变量X和调节变量Z的数据类型,调节作用共有四种情况,分别如下:

例如:研究 “ 淘宝商家服务质量 ”(X)会对 “ 淘宝忠诚度 ”(Y)产生影响,这种影响关系受到 “ 淘宝客服服务态度 ”(Z)的干扰。
(2)中介作用
中介作用是研究X对Y的影响时,是否会先通过中介变量M,再去影响Y;即是否有X->M->Y这样的关系,如果存在此种关系,则说明具有中介效应。
例如:“ 淘宝客服服务态度”(X)会影响到 “ 淘宝商家服务质量 ”(M),再影响最终 “ 淘宝忠诚度 ”(Y),此时 “ 淘宝商家服务质量 ” 就成为了这一因果链当中的中介变量。
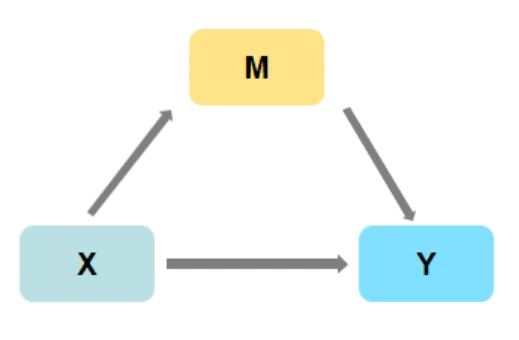
中介作用的分析较为复杂,共分为以下三个步骤:
第1步:确认数据,确保正确分析。中介作用在进行具体研究时需要对应使用研究方法(分层回归)去实现;中介作用分析时,Y一定是定量数据。X也是定量数据,中介变量M也是定量数据。
第2步:中介作用检验检验中介效应是否存在,其实就是检验X到M,M到Y的路径是否同时具有有显著性意义。
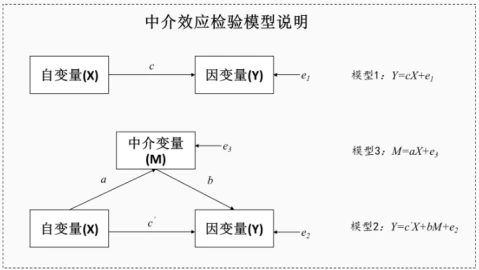
中介作用共分为3个模型。针对上图,需要说明如下:
模型1:自变量X和因变量(Y)的回归分析模型2:自变量X,中介变量(M)和因变量(Y)的回归分析模型3:自变量X和中介变量(M)的回归分析
模型1和模型2的区别在于,模型2在模型1的基础上加入了中介变量(M),因而模型1到模型2这两个模型应该使用分层回归分析(第一层放入X,第二层放入M)。
在理解了中介分析的原理之后,接着按照中介作用分析的步骤进行,如下图:
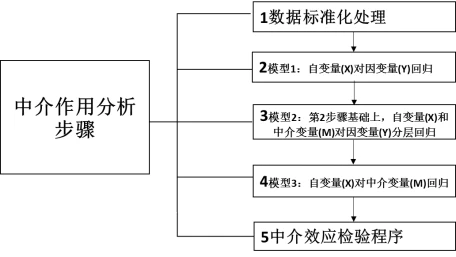
检验图如下:
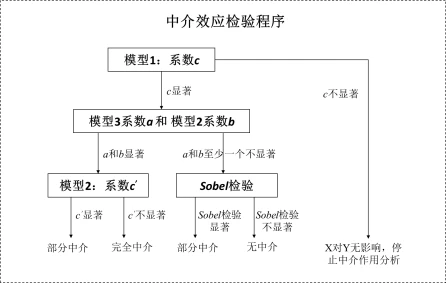
第3步:SPSSAU进行分析用户可以直接按照上图流程在SPSSAU中进行分析,生成结果。

(3)调节中介作用
调节中介作用同时考虑中介变量和调节作用,其核心是中介作用,基于中介作用基础上再进一步讨论调节作用。
比如X->M->Y这条中介路径存在,即说明具有中介作用。接着在进一步分析条件中介作用,即在另外一个调节变量Z取不同水平时(通常分为3个水平,低水平,平均水平,高水平),中介作用的幅度(也称条件间接效应)情况如何。
四、常见问题说明
(1)如何对量表进行维度划分?
进行效度分析时,维度个数通常需要结合自身专业知识判断维度个数即可。
(2)针对问卷量表数据,几个题表示一个维度,如何处理?比如有两个题“我愿意向朋友推荐SPSSAU”,“我有需要会再来使用SPSSAU”,此两个题是“忠诚度”的体现。可使用SPSSAU【数据处理-->生成变量(平均值)】功能完成。通常将多个题概括成一个整体之后,则可以进行相关分析、回归分析、方差分析等(以整体进行,而不是以题项分别进行)。
(3)如何测量量表中多个维度的分数?
通常情况下可使用描述分析计算平均值表示等。
(4)反向题处理
如果当前分值1分代表非常同意,2分代表同意,3分代表中立,4分代表不同意,5分代表非常不同意(分值越高,代表越不同意)。希望将分值反向处理即变成:1分代表非常不同意,2分代表不同意,3分代表中立,4分代表同意,5分代表非常同意(分值越高,代表越同意)。使用SPSSAU的数据编码功能,1编码为5;2编码为4;3编码为3;4编码为2;5编码为1。