
Go-Gota 源码解读
Created: December 21, 2023 3:43 PM
Class: Golang
Reviewed: No
.
├── CHANGELOG.md
├── LICENSE.md
├── README.md
├── ROADMAP.md
├── dataframe
│ ├── aggregationtype_string.go
│ ├── benchmark_test.go
│ **├── dataframe.go
│ ├── dataframe_test.go
│ └── examples_test.go
├── go.mod
├── go.sum
└── series
├── benchmarks_test.go
*├── rolling_window.go
├── rolling_window_test.go
**├── series.go*
├── series_test.go
*├── type-bool.go
*├── type-float.go
*├── type-int.go
*└── type-string.go
数据结构
Gota 所建立的数据结构主要有两个—— DataFrame 和 Series 。
type DataFrame struct {
columns []series.Series // 列表,包含多个 Series 对象,表示 DataFrame 的列
ncols int // 整数,表示 DataFrame 的列数
nrows int // 整数,表示 DataFrame 的行数
Err error // 错误对象,用于记录 DataFrame 操作过程中的错误
}
type Series struct {
Name string // 字符串,表示 Series 的名称
elements Elements // Elements 类型,包含元素的值
t Type // Type 类型,表示 Series 的数据类型
Err error // 错误对象,用于记录 Series 操作过程中的错误
}
DataFrame 数据帧主要是由 Series 序列组成的
Series 序列的值主要是由 Elements 元素组成,可以看到,Gota 定义了 Elements 接口和 Type 类型:
type Elements interface {
Elem(int) Element // Elem 方法根据给定的索引返回元素对象
Len() int // Len 方法返回元素集合的长度
}
type Type string
Go 属于强类型语言,将 Elements 定义为接口,使用四种数据类型去实现它
// intElements 是 Int 类型元素的具体实现。
type intElements []intElement
func (e intElements) Len() int { return len(e) }
func (e intElements) Elem(i int) Element { return &e[i] }
// stringElements 是 String 类型元素的具体实现。
type stringElements []stringElement
func (e stringElements) Len() int { return len(e) }
func (e stringElements) Elem(i int) Element { return &e[i] }
// floatElements 是 Float 类型元素的具体实现。
type floatElements []floatElement
func (e floatElements) Len() int { return len(e) }
func (e floatElements) Elem(i int) Element { return &e[i] }
// boolElements 是 Bool 类型元素的具体实现。
type boolElements []boolElement
func (e boolElements) Len() int { return len(e) }
func (e boolElements) Elem(i int) Element { return &e[i] }
对于 Element 元素,其本质也是一个接口,定义更多方法:
// Element 是为 Series 的元素定义方法的接口。
type Element interface {
// Set Setter 方法
Set(interface{})
// Eq 比较方法
Eq(Element) bool
Neq(Element) bool
Less(Element) bool
LessEq(Element) bool
Greater(Element) bool
GreaterEq(Element) bool
// Copy 访问器/转换方法
Copy() Element
Val() ElementValue
String() string
Int() (int, error)
Float() float64
Bool() (bool, error)
// IsNA 信息方法
IsNA() bool
Type() Type
}
对于 intElement, stringElement, floatElement, boolElement,数据结构为:
// intElement 表示 Series 中的整数元素。
type intElement struct {
e int
nan bool
}
// stringElement 表示 Series 中的字符串元素。
type stringElement struct {
e string
nan bool
}
// floatElement 表示一个带有 float64 值的元素。
type floatElement struct {
e float64 // 实际的 float 值
nan bool // 标志,表示值是否为 NaN(非数值)
}
// boolElement 表示 Series 中的布尔元素。
type boolElement struct {
e bool
nan bool
}
至此,我们应该能够梳理清楚 Gota 数据结构的基本组成:
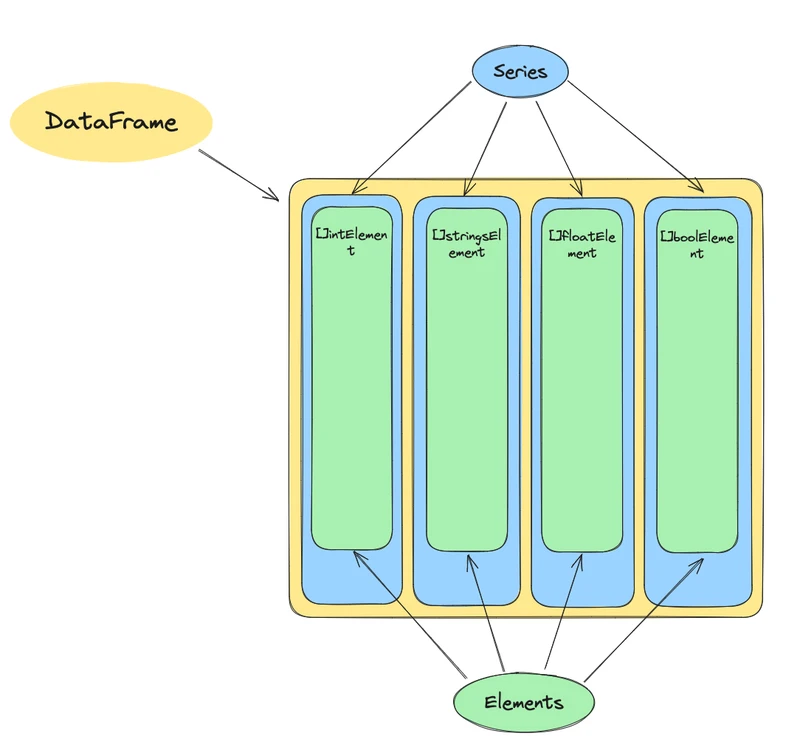
清楚数据结后,接下来由底向上来看各个方法。
Element
上面已经展示了 Element 接口规定的方法
对 Element 接口的四种类型(int,string,float,bool)的实现分别在type-int,type-string,type-float,type-bool 文件中,着重解读两个地方,源码及注释链接会放在文章尾部:
var _ Interface = (*Type)(nil)
// 强制 intElement 结构实现 Element 接口。
var _ Element = (*intElement)(nil)
Go 语言中,接口是隐式实现的,当一个类型正确实现了一个接口的所有方法,那么这个类型实现了这个接口,即使这个类型没有实现响应接口,程序仍旧是可以编译运行的。
程序运行时,这个类型的对象在调用方法时才会去动态检测这个类型是否实现了相应的接口,如果出现了这个类型未实现对应接口的情况,或许程序会出错。
而静态接口检测或者称为强制接口检测,会在源码进行编译的时进行接口检测,出现接口未被相应类型实现时会在编译时报错,并可提示缺少了哪些方法的实现。
func (e *intElement) Set(value interface{}){}
// Set 方法将给定的值设置为整数元素。
// 如果值为 "NaN" 或转换失败,则标记为 NaN。
func (e *intElement) Set(value interface{}) {
e.nan = false
switch val := value.(type) {
case string:
if val == "NaN" {
e.nan = true
return
}
i, err := strconv.Atoi(value.(string))
if err != nil {
e.nan = true
return
}
e.e = i
case int:
e.e = val
case float64:
f := val
if math.IsNaN(f) ||
math.IsInf(f, 0) ||
math.IsInf(f, 1) {
e.nan = true
return
}
e.e = int(f)
case bool:
b := val
if b {
e.e = 1
} else {
e.e = 0
}
case Element:
v, err := val.Int()
if err != nil {
e.nan = true
return
}
e.e = v
default:
e.nan = true
return
}
}
Set 方法接受一个实现了 interface 的类型,使他能够接受基本所有 Go 的类型,但是只能够转换四种支持的类型,其余的都会为空且将 nan 属性值更改为 true 表示此 Element 为空值。
其他的方法都比较简单,这里不再细说。
Series
Series 是一个用于操作符合特定类型结构的元素数组的数据结构。它们足够灵活,可以转换为其他 Series 类型,并考虑缺失或非有效元素。Series 的强大之处主要在于能够比较和子集化不同类型的 Series。
Series 的创建
func New(values interface{}, t Type, name string) Series {}
New 是通用的 Series 构造函数
func New(values interface{}, t Type, name string) Series {
ret := Series{
Name: name,
t: t,
}
// 预先分配元素
preAlloc := func(n int) {
switch t {
case String:
ret.elements = make(stringElements, n)
case Int:
ret.elements = make(intElements, n)
case Float:
ret.elements = make(floatElements, n)
case Bool:
ret.elements = make(boolElements, n)
default:
panic(fmt.Sprintf("unknown type %v", t))
}
}
if values == nil {
preAlloc(1)
ret.elements.Elem(0).Set(nil)
return ret
}
switch v := values.(type) {
case []string:
l := len(v)
preAlloc(l)
for i := 0; i < l; i++ {
ret.elements.Elem(i).Set(v[i])
}
case []float64:
l := len(v)
preAlloc(l)
for i := 0; i < l; i++ {
ret.elements.Elem(i).Set(v[i])
}
case []int:
l := len(v)
preAlloc(l)
for i := 0; i < l; i++ {
ret.elements.Elem(i).Set(v[i])
}
case []bool:
l := len(v)
preAlloc(l)
for i := 0; i < l; i++ {
ret.elements.Elem(i).Set(v[i])
}
case Series:
l := v.Len()
preAlloc(l)
for i := 0; i < l; i++ {
ret.elements.Elem(i).Set(v.elements.Elem(i))
}
default:
switch reflect.TypeOf(values).Kind() {
case reflect.Slice:
v := reflect.ValueOf(values)
l := v.Len()
preAlloc(v.Len())
for i := 0; i < l; i++ {
val := v.Index(i).Interface()
ret.elements.Elem(i).Set(val)
}
default:
preAlloc(1)
v := reflect.ValueOf(values)
val := v.Interface()
ret.elements.Elem(0).Set(val)
}
}
return ret
}
New 方法接受 Series 序列的值,类型以及名称,New 方法不立刻进行赋值操作,而是先使用名称和类型创建一个 Series 对象,然后根据传入的 Type 类型来构造对应类型的 Series ,之前已经说过,Series 只允许创建实现了Elements的类型(int,string,float,bool),进行构造 Series 时,并不会直接将数据填入,而是先创建对应类型的数据结构切片,然后才会将数据填入,填入时使用的是Element 类型实现的 Set 方法 ret.elements.Elem(i).Set(v.elements.Elem(i)),所以需要进行先构造后赋值的方式进行。
整体流程为:根据 Type,Name 创建 Series;初始化 Series 的 Elements;填入 Elements 值。
func Types(values interface{}) Series {}
这个 Types 可以是 Strings,Ints,Floats,Bools。内部还是调用了 New - Series 通用创建方法。
比如:
// Strings 是 String Series 的构造函数。
func Strings(values interface{}) Series {
return New(values, String, "")
}
Series 的处理
Series 的处理指的是为 Series 增加新元素,删除指定元素,以及截取元素等等。有:
- Append: 将新元素添加到 Series 的末尾。使用 Append 时,将直接修改 Series;
- Concat: 连接两个 Series。它将返回一个包含两个 Series 元素的新 Series;
- Subset: 根据给定的 Indexes 返回 Series 的子集;
- Set: 方法设置 Series 的索引处的值并返回自身的引用。原始 Series 会被修改;
- Copy: 方法将返回 Series 的副本。
这些都是比较简单实现的方法,拿 Append 举例:
func (s *Series) Append(values interface{}) {
if err := s.Err; err != nil {
return
}
news := New(values, s.t, s.Name)
switch s.t {
case String:
s.elements = append(s.elements.(stringElements), news.elements.(stringElements)...)
case Int:
s.elements = append(s.elements.(intElements), news.elements.(intElements)...)
case Float:
s.elements = append(s.elements.(floatElements), news.elements.(floatElements)...)
case Bool:
s.elements = append(s.elements.(boolElements), news.elements.(boolElements)...)
}
}
Append 方法会根据参数创建一个与接收器 Series 相同类型名称的 Series 对象(这时如果 Value 与接收器 Series 的类型不同会报错),然后接收器类型进行断言,最后将新 Series 对象的Elements 断言后以切片拓展添加即可。
Concat 方法也会使用 Append 方法,只是会返回一个新的 Series。
其他的不再举例
Series 的判断
Series 的判断指的是判断 Series 中是否含有空值,Series 是否为空序列,Series 之间的比较。有:
- HasNaN: 方法检查 Series 是否包含 NaN 元素;
- IsNaN: 方法返回一个标识哪些元素是 NaN 的数组;
- Compare: 方法比较 Series 的值与其他元素。为此,要比较的元素首先转换为与调用方相同类型的 Series.
对于Series的空值,Element 类型中中有 nan 的 bool 值来表示是否为空,而四种数据类型对应的空值分别是:
- String: “NaN”
- Int: 0
- Float: math.NaN()
- Bool: false
Series 的判断中比较复杂的是 Compare 方法:
func (s Series) Compare(comparator Comparator, comparando interface{}) Series {
if err := s.Err; err != nil {
return s
}
compareElements := func(a, b Element, c Comparator) (bool, error) {
var ret bool
switch c {
case Eq:
ret = a.Eq(b)
case Neq:
ret = a.Neq(b)
case Greater:
ret = a.Greater(b)
case GreaterEq:
ret = a.GreaterEq(b)
case Less:
ret = a.Less(b)
case LessEq:
ret = a.LessEq(b)
default:
return false, fmt.Errorf("未知比较器: %v", c)
}
return ret, nil
}
bools := make([]bool, s.Len())
// CompFunc 比较器比较
if comparator == CompFunc {
f, ok := comparando.(compFunc)
if !ok {
panic("comparando 不是一个 func(el Element) bool 类型的比较函数")
}
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
bools[i] = f(e)
}
return Bools(bools)
}
comp := New(comparando, s.t, "")
// In 比较器比较
if comparator == In {
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
b := false
for j := 0; j < comp.Len(); j++ {
m := comp.elements.Elem(j)
c, err := compareElements(e, m, Eq)
if err != nil {
s = s.Empty()
s.Err = err
return s
}
if c {
b = true
break
}
}
bools[i] = b
}
return Bools(bools)
}
// 单一元素比较
if comp.Len() == 1 {
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
c, err := compareElements(e, comp.elements.Elem(0), comparator)
if err != nil {
s = s.Empty()
s.Err = err
return s
}
bools[i] = c
}
return Bools(bools)
}
// 多元素比较
if s.Len() != comp.Len() {
s := s.Empty()
s.Err = fmt.Errorf("无法比较: 长度不匹配")
return s
}
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
c, err := compareElements(e, comp.elements.Elem(i), comparator)
if err != nil {
s = s.Empty()
s.Err = err
return s
}
bools[i] = c
}
return Bools(bools)
}
Compare 方法最终返回一个 Bool 类型、且长度与原 Series 相同的 Series 序列。
Compare 有三种比较方式,判断顺序为:比较器比较、单一元素比较、多元素比较
其中比较器比较中比较器有:
// 支持的比较器
const (
Eq Comparator = "==" // 等于
Neq Comparator = "!=" // 不等于
Greater Comparator = ">" // 大于
GreaterEq Comparator = ">=" // 大于等于
Less Comparator = "<" // 小于
LessEq Comparator = "<=" // 小于等于
In Comparator = "in" // 包含
CompFunc Comparator = "func" // 用户定义的比较函数
)
Series 的数据遍历
Series 的数据遍历,也就是查看 Series 里的元素,相应的,四种数据类型也会有不同的实现方法:
- Records: 方法将 Series 的元素作为 []string 返回;
- Float: 方法将 Series 的元素作为 []float64 返回。如果元素无法转换为 float64 或包含 NaN,则返回 NaN 的 float 表示;
- Int: 方法将 Series 的元素作为 []int 返回,如果转换不可能则返回错误;
- Bool: 方法将 Series 的元素作为 []bool 返回,如果转换不可能则返回错误;
- Val: 方法返回给定索引处的 Series 的值。如果索引超出范围,则会引发 panic;
- Elem: 方法返回给定索引处的 Series 的元素。如果索引超出范围,则会引发 panic
Records、Float、Int、Bool 方法是很相似的,这里拿 Records举例:
func (s Series) Records() []string {
ret := make([]string, s.Len())
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
ret[i] = e.String()
}
return ret
}
创建对应类型长度的切片,取出序列元素,做断言后放入切片,返回切片即可。
四者的区别在于创建的切片类型以及所做的断言不同。
Val和 Elem 方法最终都是返回到 Elements 的第 i 个元素
Series 的计算
Series 的计算包括,排序、元素交换、计算标准差、平均值、中间值、最大最小值、取样等等:
- Order: 方法返回排序 Series 所需的索引。NaN 元素按出现顺序推送到末尾
- Swap: 方法交换两个元素
- StdDev: 方法计算 Series 的标准差
- Mean: 方法计算 Series 的平均值
- Median: 方法计算中间值或中位数,与平均值相反,它不太容易受到异常值的影响
- Max: 方法返回 Series 中的最大元素值
- MaxStr: 方法返回字符串类型 Series 中的最大元素值
- Min: 方法返回 Series 中的最小元素值
- MinStr: 方法返回字符串类型 Series 中的最小元素值
- Quantile: 方法返回 Series 样本,使得 x 大于或等于样本比例 p,注意: 当以字符串类型调用时,gonum/stat 会引发 panic
- Sum: 方法计算 Series 的和
拿 Order 来举例:
func (s Series) Order(reverse bool) []int {
var ie indexedElements
var nasIdx []int
for i := 0; i < s.Len(); i++ {
e := s.elements.Elem(i)
if e.IsNA() {
nasIdx = append(nasIdx, i)
} else {
ie = append(ie, indexedElement{i, e})
}
}
var srt sort.Interface
srt = ie
if reverse {
srt = sort.Reverse(srt)
}
sort.Stable(srt)
var ret []int
for _, e := range ie {
ret = append(ret, e.index)
}
return append(ret, nasIdx...)
}
Order 方法返回的是排序后 Series 的索引。
声明了两个切片:ie 和 nasIdx ,前者用于存储带着索引的 Element ,后者存储为空的元素索引。
indexedElements 结构体以及实现方法为:
// indexedElement 结构表示带索引的元素。
type indexedElement struct {
index int
element Element
}
// indexedElements 是 indexedElement 的切片。
type indexedElements []indexedElement
// Len 方法返回切片的长度。
func (e indexedElements) Len() int { return len(e) }
// Less 方法比较两个元素的大小。
func (e indexedElements) Less(i, j int) bool { return e[i].element.Less(e[j].element) }
// Swap 方法交换两个元素。
func (e indexedElements) Swap(i, j int) { e[i], e[j] = e[j], e[i] }
// StdDev 方法计算 Series 的标准差。
func (s Series) StdDev() float64 {
stdDev := stat.StdDev(s.Float(), nil)
return stdDev
}
indexedElement 类型实现了Go 原生库中 sort 包中的 Interface 接口,即可作为参数传入到 Stable 稳定排序方法中进行排序,最后将返回的排序好的序号以及空元素的序号进行拼接后返回。
DataFrame
DataFrame 的创建
New 是 DataFrame 的通用创建方式
func New(se ...series.Series) DataFrame {
if se == nil || len(se) == 0 {
return DataFrame{Err: fmt.Errorf("empty DataFrame")}
}
columns := make([]series.Series, len(se))
for i, s := range se {
columns[i] = s.Copy()
}
nrows, ncols, err := checkColumnsDimensions(columns...)
if err != nil {
return DataFrame{Err: err}
}
df := DataFrame{
columns: columns,
ncols: ncols,
nrows: nrows,
}
colnames := df.Names()
fixColnames(colnames)
for i, colname := range colnames {
df.columns[i].Name = colname
}
return df
}
New 方法会接受一个 Series 序列的切片,根据它的长度创建列的数量,然后将进行赋值。
之后使用checkColumnsDimensions方法获取行和列的数量,根据序列切片、行数、列树创建出 DataFrame,Series 有名字,使用获取 DataFrame 的 Names ,使用 fixColnames 方法将序列名称赋值给列名。
除了使用 New 函数创建 DataFrame,还有其他从数据直接转换为 DataFrame 对象的方法,像是:
- LoadStructs: 函数从给定的切片中加载结构体数据,并返回一个DataFrame;
- LoadRecords: 从字符串切片记录加载 DataFrame;
- LoadMaps: 从 map 数组加载 DataFrame;
- LoadMatrix: 从矩阵加载 DataFrame;
- ReadCSV: 从 CSV 格式的输入读取 DataFrame;
- ReadJSON: 从 JSON 格式的输入读取 DataFrame;
- ReadHTML: 从 HTML 格式的输入读取多个 DataFrame,每个 DataFrame 对应一个 HTML 表格。
这里拿LoadStructs这个比较常用的方法来讲解:
func LoadStructs(i interface{}, options …LoadOption) DataFrame {}
func LoadStructs(i interface{}, options ...LoadOption) DataFrame {
// 检查输入是否为 nil
if i == nil {
return DataFrame{Err: fmt.Errorf("load: 无法从 <nil> 值创建 DataFrame")}
}
// 配置加载选项的默认值
cfg := loadOptions{
defaultType: series.String,
detectTypes: true,
hasHeader: true,
nanValues: []string{"NA", "NaN", "<nil>"},
}
// 应用用户提供的加载选项
for _, option := range options {
option(&cfg)
}
// 获取输入数据的类型和值
tpy, val := reflect.TypeOf(i), reflect.ValueOf(i)
// 检查输入数据是否为切片类型
switch tpy.Kind() {
case reflect.Slice:
// 检查切片元素类型是否为结构体
if tpy.Elem().Kind() != reflect.Struct {
return DataFrame{Err: fmt.Errorf(
"load: 类型 %s (%s %s) 不受支持,必须是 []struct", tpy.Name(), tpy.Elem().Kind(), tpy.Kind())}
}
// 检查切片是否为空
if val.Len() == 0 {
return DataFrame{Err: fmt.Errorf("load: 无法从空切片创建 DataFrame")}
}
// 获取结构体字段数量
numFields := val.Index(0).Type().NumField()
var columns []series.Series
// 遍历结构体字段
for j := 0; j < numFields; j++ {
// 如果字段不可导出,跳过
if !val.Index(0).Field(j).CanInterface() {
continue
}
// 获取字段信息
field := val.Index(0).Type().Field(j)
fieldName := field.Name
fieldType := field.Type.String()
// 获取字段的 dataframes 标签
fieldTags := field.Tag.Get("dataframe")
// 如果标签为 "-",表示不导入该字段
if fieldTags == "-" {
continue
}
// 解析字段标签
tagOpts := strings.Split(fieldTags, ",")
if len(tagOpts) > 2 {
return DataFrame{Err: fmt.Errorf("字段 %s 上的结构体标签格式错误: %s", fieldName, fieldTags)}
}
if len(tagOpts) > 0 {
// 使用标签中的名称覆盖字段名
if name := strings.TrimSpace(tagOpts[0]); name != "" {
fieldName = name
}
// 使用标签中的类型覆盖字段类型
if len(tagOpts) == 2 {
if tagType := strings.TrimSpace(tagOpts[1]); tagType != "" {
fieldType = tagType
}
}
}
// 确定字段的 series.Type
var t series.Type
if cfgtype, ok := cfg.types[fieldName]; ok {
t = cfgtype
} else {
// 如果允许类型检测,则根据字段类型字符串解析类型
if cfg.detectTypes {
parsedType, err := parseType(fieldType)
if err != nil {
return DataFrame{Err: err}
}
t = parsedType
} else {
// 否则使用默认类型
t = cfg.defaultType
}
}
// 创建字段对应的元素切片
elements := make([]interface{}, val.Len())
// 遍历结构体切片,提取字段值并填充元素切片
for i := 0; i < val.Len(); i++ {
fieldValue := val.Index(i).Field(j)
elements[i] = fieldValue.Interface()
// 如果字段值匹配 NaNValues 中的任何值,则将元素设置为 nil
if findInStringSlice(fmt.Sprint(elements[i]), cfg.nanValues) != -1 {
elements[i] = nil
}
}
// 如果不包含标题行,添加字段名到元素切片的开头,并清空字段名
if !cfg.hasHeader {
tmp := make([]interface{}, 1)
tmp[0] = fieldName
elements = append(tmp, elements...)
fieldName = ""
}
// 创建字段对应的 Series,并添加到列集合中
columns = append(columns, series.New(elements, t, fieldName))
}
// 使用列集合创建新的 DataFrame
return New(columns...)
}
// 如果输入不是切片类型,则返回错误
return DataFrame{Err: fmt.Errorf(
"load: 类型 %s (%s) 不受支持,必须是 []struct", tpy.Name(), tpy.Kind())}
}
LoadStructs 接受一个 interface 参数和一个配置切片,如果这个 interface 的值为 nil,则直接返回错误。之后进行配置,配置切片的每个配置都更改为默认配置。然后获取接口参数的类型和值,若接口的类型种类为切片,进一步判断是否为结构体,之后根据默认的配置进行创建 DataFrame。
我比较在意源码中为什么使用
switch tpy.Kind() {
case reflect.Slice:
}
(明明只有一个 Case),而不是
if tpy.Kind() == reflect.Slice {}
也许之前这个方法是一个综合的,可以接受不同结构的数据最终转换为 DataFrame,做了拆分后懒得改了?怕改回去?
之后获取结构体字段数量,遍历结构体字段,获取字段的 dataframes 标签,然后确定字段的series.Type,创建字段对应的元素切片、创建字段对应的 Series 并添加到集合之中。
DataFrame 数据及属性的查看
查看 DataFrame 的数据的方法多数是以不同的数据形式返回 DataFrame 的记录。
- Records: 返回 DataFrame 的记录,以二维字符串切片形式返回;
- Maps: 返回 DataFrame 的记录,以一维字符串切片映射为键值对形式返回;
- Elem: 返回指定行和列位置的 DataFrame 单元格元素;
- Col: 根据列名返回 DataFrame 的列;
DataFrame 的属性有:行数、列数、列类型、列名等等:
- Nrow 返回 DataFrame 的行数;
- Ncol 返回 DataFrame 的列数;
- Dims 返回 DataFrame 的行数和列数;
- Types: 返回 DataFrame 的列类型;
- Names: 返回 DataFrame 的列名;
- Describe: 返回 DataFrame 的描述性统计信息;
其中 Describe 会展示这个 DataFrame 的"平均值",“中位数”,“标准差”,“最小值”,“25%”,“50%”,“75%”,“最大值”。
简单看一下常用的 Maps方法:
func (df DataFrame) Maps() []map[string]interface{} {
maps := make([]map[string]interface{}, df.nrows)
colnames := df.Names()
for i := 0; i < df.nrows; i++ {
m := make(map[string]interface{})
for k, v := range colnames {
val := df.columns[k].Val(i)
m[v] = val
}
maps[i] = m
}
return maps
}
Maps 方法会首先创建一个 map[string]interface{}的切片,长度为 DataFrame 的行数,然后将切片中的每个 map 进行初始化,然后将列名和值作为key value,最后放入 maps 切片中。
DataFrame 的编辑处理
DataFrame 的编辑处理有:截取、连接、拼接、删除等等。具体有:
- Select: 方法根据提供的索引返回一个根据所选列进行选择的新DataFrame;
- Drop: 方法返回一个根据提供的索引删除列的新DataFrame;
- Rename: 方法用新的列名替换指定的旧列名,它返回修改后的DataFrame;
- CBind: 方法将两个DataFrame按列拼接,它返回包含拼接结果的新DataFrame;
- RBind: 方法将两个DataFrame按行拼接,它返回包含拼接结果的新DataFrame;
- Concat: 方法将两个DataFrame按列拼接,保留唯一列,它返回包含拼接结果的新DataFrame;
- Mutate: 方法用提供的Series替换DataFrame中的某一列,它返回修改后的DataFrame;
- InnerJoin: 执行内连接操作,将两个 DataFrame 按照指定的键连接;
- LeftJoin: 执行左连接操作,将两个 DataFrame 按照指定的键连接;
- RightJoin: 执行右连接操作,将两个 DataFrame 按照指定的键连接;
- OuterJoin: 执行外连接操作,将两个 DataFrame 按照指定的键连接;
- CrossJoin: 执行交叉连接操作,返回两个 DataFrame 的笛卡尔积;
- Capply 方法对DataFrame的每一列应用给定的函数,它返回包含应用结果的新DataFrame
- Rapply 方法对DataFrame的每一行应用给定的函数,它返回包含应用结果的新DataFrame
CBind只是将两个 DataFrame 作为字符串切片拼接后返回一个新的 DataFrame 而已,Concat 方法会使用一个 uniques map 将列进行去重,保证唯一。
具体看看比较复杂的 LeftJoin 和 Rapply 方法:
func (df DataFrame) LeftJoin(b DataFrame, keys …string) DataFrame {}
func (df DataFrame) LeftJoin(b DataFrame, keys ...string) DataFrame {
// 检查是否为连接操作指定了键
if len(keys) == 0 {
return DataFrame{Err: fmt.Errorf("未指定连接键")}
}
// 初始化数组以存储左右两个DataFrame中指定键的列索引
var iKeysA []int
var iKeysB []int
var errorArr []string
// 遍历指定的键
for _, key := range keys {
// 获取左侧DataFrame中键的列索引
i := df.colIndex(key)
if i < 0 {
// 如果在左侧DataFrame中找不到键,添加错误消息
errorArr = append(errorArr, fmt.Sprintf("在左侧 DataFrame 中找不到键 %q", key))
}
iKeysA = append(iKeysA, i)
// 获取右侧DataFrame中键的列索引
j := b.colIndex(key)
if j < 0 {
// 如果在右侧DataFrame中找不到键,添加错误消息
errorArr = append(errorArr, fmt.Sprintf("在右侧 DataFrame 中找不到键 %q", key))
}
iKeysB = append(iKeysB, j)
}
// 如果存在错误,则返回一个包含错误消息的DataFrame
if len(errorArr) != 0 {
return DataFrame{Err: fmt.Errorf(strings.Join(errorArr, "\n"))}
}
// 从两个DataFrame中提取列
aCols := df.columns
bCols := b.columns
// 初始化一个切片,用于存储结果DataFrame中的新列
var newCols []series.Series
// 处理左侧DataFrame中与键对应的列
for _, i := range iKeysA {
newCols = append(newCols, aCols[i].Empty())
}
// 处理左侧DataFrame中非键的列
var iNotKeysA []int
for i := 0; i < df.ncols; i++ {
if !inIntSlice(i, iKeysA) {
iNotKeysA = append(iNotKeysA, i)
newCols = append(newCols, aCols[i].Empty())
}
}
// 处理右侧DataFrame中非键的列
var iNotKeysB []int
for i := 0; i < b.ncols; i++ {
if !inIntSlice(i, iKeysB) {
iNotKeysB = append(iNotKeysB, i)
newCols = append(newCols, bCols[i].Empty())
}
}
// 遍历左侧DataFrame中的行
for i := 0; i < df.nrows; i++ {
// 用于跟踪在右侧DataFrame中是否找到匹配项的标志
matched := false
// 遍历右侧DataFrame中的行
for j := 0; j < b.nrows; j++ {
// 检查键列中的值是否匹配
match := true
for k := range keys {
aElem := aCols[iKeysA[k]].Elem(i)
bElem := bCols[iKeysB[k]].Elem(j)
match = match && aElem.Eq(bElem)
}
// 如果找到匹配项,使用两个DataFrame中的值更新新列
if match {
matched = true
ii := 0
for _, k := range iKeysA {
elem := aCols[k].Elem(i)
newCols[ii].Append(elem)
ii++
}
for _, k := range iNotKeysA {
elem := aCols[k].Elem(i)
newCols[ii].Append(elem)
ii++
}
for _, k := range iNotKeysB {
elem := bCols[k].Elem(j)
newCols[ii].Append(elem)
ii++
}
}
}
// 如果在右侧DataFrame中找不到匹配项,则将空值附加到新列
if !matched {
ii := 0
for _, k := range iKeysA {
elem := aCols[k].Elem(i)
newCols[ii].Append(elem)
ii++
}
for _, k := range iNotKeysA {
elem := aCols[k].Elem(i)
newCols[ii].Append(elem)
ii++
}
for range iNotKeysB {
newCols[ii].Append(nil)
ii++
}
}
}
// 从收集的列创建一个新的DataFrame并返回
return New(newCols...)
}
LeftJoin 方法会首先进行验证操作,验证 keys 是否为空、是否在两个 DF 中存在。
之后是提取列过程,先提取左 DF 的关键列和非关键列,然后提取右 DF 的非关键列。
之后开始遍历左右 DF 的行,并进行处理,左右 DF 键列匹配进行添加,不匹配则加入空值,最终返回一个新的 DF。
func (df DataFrame) Rapply(f func(series.Series) series.Series) DataFrame {}
Rapply 方法并没有 Capply 方法那样简单,因为 DataFrame 的子结构 Series 就是作为列而存在的,Series 的结构和实现的方法让它很容易处理。而 Rapply 则比较复杂:
func (df DataFrame) Rapply(f func(series.Series) series.Series) DataFrame {
// 检查原始DataFrame是否有错误,如果有,则返回相同的DataFrame。
if df.Err != nil {
return df
}
// 辅助函数,用于检测一组序列类型中的共同类型。
detectType := func(types []series.Type) series.Type {
var hasStrings, hasFloats, hasInts, hasBools bool
// 遍历类型并根据每种类型的存在情况设置标志。
for _, t := range types {
switch t {
case series.String:
hasStrings = true
case series.Float:
hasFloats = true
case series.Int:
hasInts = true
case series.Bool:
hasBools = true
}
}
// 根据检测到的标志返回共同的类型。
switch {
case hasStrings:
return series.String
case hasBools:
return series.Bool
case hasFloats:
return series.Float
case hasInts:
return series.Int
default:
// 如果没有找到支持的类型,则引发错误。
panic("不支持的类型")
}
}
// 获取DataFrame中列的类型。
types := df.Types()
// 确定行的共同类型。
rowType := detectType(types)
// 初始化二维数组以存储转换后的元素。
elements := make([][]series.Element, df.nrows)
// 用于跟踪每行的长度。
rowlen := -1
// 遍历DataFrame中的每一行。
for i := 0; i < df.nrows; i++ {
// 创建一个具有共同类型的新空行序列。
row := series.New(nil, rowType, "").Empty()
// 将每列的元素附加到行序列。
for _, col := range df.columns {
row.Append(col.Elem(i))
}
// 将给定函数应用于行。
row = f(row)
// 检查应用函数时是否发生错误。
if row.Err != nil {
return DataFrame{Err: fmt.Errorf("在行 %d 上应用函数时发生错误: %v", i, row.Err)}
}
// 检查行长度是否一致。
if rowlen != -1 && rowlen != row.Len() {
return DataFrame{Err: fmt.Errorf("应用函数时发生错误: 行具有不同的长度")}
}
rowlen = row.Len()
// 将行序列转换为元素切片并存储在elements数组中。
rowElems := make([]series.Element, rowlen)
for j := 0; j < rowlen; j++ {
rowElems[j] = row.Elem(j)
}
elements[i] = rowElems
}
// 初始化数组以存储转换后的列。
columns := make([]series.Series, rowlen)
// 遍历每一列。
for j := 0; j < rowlen; j++ {
// 为每个行中的列元素创建类型切片。
types := make([]series.Type, df.nrows)
for i := 0; i < df.nrows; i++ {
types[i] = elements[i][j].Type()
}
// 确定列的共同类型。
colType := detectType(types)
// 创建一个具有共同类型的新空列序列。
s := series.New(nil, colType, "").Empty()
// 将每行的元素附加到列序列。
for i := 0; i < df.nrows; i++ {
s.Append(elements[i][j])
}
// 将列序列存储在columns数组中。
columns[j] = s
}
// 检查转换后的列的维度。
nrows, ncols, err := checkColumnsDimensions(columns...)
if err != nil {
return DataFrame{Err: err}
}
// 创建一个带有转换后的列和更新维度的新DataFrame。
df = DataFrame{
columns: columns,
ncols: ncols,
nrows: nrows,
}
// 获取DataFrame的列名。
colnames := df.Names()
// 修复列名中的任何问题。
fixColnames(colnames)
// 更新DataFrame中列的名称。
for i, colname := range colnames {
df.columns[i].Name = colname
}
// 返回最终转换后的DataFrame。
return df
}
Rapply 和 Capply 都是将接收的方法用于DF 的行或列上,只是一行的数据类型都不尽相同,需要更严谨的处理。
Rapply 需要确定行的数据类型,根据行内存在的四种数据类型,优先使用的顺序是 String、Bools、Floats、Ints。然后依据行的数据类型创建空的 Series 并填充行数据,之后将给定的函数应用于行序列。
之后将行数据再次以同样形式转换为列,检查修复列名后返回到新的 DataFrame。
由此见,Gota 包实现了 Series 作为列来处理,并没有或许没有办法将其作为行来处理,使的对于行的数据处理变得麻烦不完整且很难拓展,对于确定行数据类型的操作,如果一行之内有 string,int,bool 都还能够使用 string 进行统一处理,但是如果想要 DataFrame 支持存储其他数据类型,例如 map,Rappley 方法就需要更佳复杂的实现。
DataFrame 的高级处理
DataFrame 的高级处理也不算高级,是对于数据表的一般操作,像是分组、过滤、排序等等:
- GroupBy: 方法按指定的列名对DataFrame进行分组,并返回Groups结构;
- Aggregation: 方法按照给定的AggregationType和列名对Groups进行聚合操作,它返回包含聚合结果的新DataFrame;
- GetGroups: 方法返回Groups中的分组数据;
- String:方法返回Aggregation的字符串表示;
- FilterAggregation: 方法根据提供的Aggregation类型和过滤器进行过滤DataFrame,并返回新的DataFrame;
- Sort: 函数返回一个升序排序的Order结构;
- RevSort: 函数返回一个降序排序的Order结构;
- Arrange: 方法按照指定的排序参数对DataFrame进行排序,它返回排序后的新DataFrame;
GroupBy 方法返回的是 Group 结构对象指针,Group 结构为:
// Groups 表示分组的数据并支持聚合操作。
type Groups struct {
groups map[string]DataFrame // 分组数据的映射,以分组的名称作为键,对应的值为DataFrame对象
colnames []string // 列名的切片
aggregation DataFrame // 聚合结果的DataFrame对象
Err error // 错误信息
}
GroupBy 方法根据指定的列名将 DataFrame 进行分组,并根据分组结果创建DataFrame的切片,存在一个新的 Groups 对象中。
GetGroups 方法便是简单返回 Groups 对象的 groups——DataFrame 切片。
Aggregation方法具体为:
func (gps Groups) Aggregation(typs []AggregationType, colnames []string) DataFrame {
// 错误检查:如果输入的分组为nil,则返回带有错误信息的新数据框。
if gps.groups == nil {
return DataFrame{Err: fmt.Errorf("Aggregation: 输入为nil")}
}
// 错误检查:如果聚合类型和列名数量不匹配,则返回带有错误信息的新数据框。
if len(typs) != len(colnames) {
return DataFrame{Err: fmt.Errorf("Aggregation: len(typs) != len(colanmes)")}
}
// 初始化用于存储聚合结果的切片。
dfMaps := make([]map[string]interface{}, 0)
// 遍历分组后的每个数据框。
for _, df := range gps.groups {
// 获取当前数据框的列名到数据映射。
targetMap := df.Maps()[0]
curMap := make(map[string]interface{})
// 复制分组列的值到当前映射。
for _, c := range gps.colnames {
if value, ok := targetMap[c]; ok {
curMap[c] = value
} else {
// 如果找不到列名,则返回带有错误信息的新数据框。
return DataFrame{Err: fmt.Errorf("Aggregation: 无法找到列名:%s", c)}
}
}
// 遍历要进行聚合的列。
for i, c := range colnames {
// 获取当前列的数据序列。
curSeries := df.Col(c)
var value float64
// 根据聚合类型选择相应的聚合方法。
switch typs[i] {
case Aggregation_MAX:
value = curSeries.Max()
case Aggregation_MEAN:
value = curSeries.Mean()
case Aggregation_MEDIAN:
value = curSeries.Median()
case Aggregation_MIN:
value = curSeries.Min()
case Aggregation_STD:
value = curSeries.StdDev()
case Aggregation_SUM:
value = curSeries.Sum()
case Aggregation_COUNT:
value = float64(curSeries.Len())
default:
// 如果找不到聚合方法,则返回带有错误信息的新数据框。
return DataFrame{Err: fmt.Errorf("Aggregation: 未找到该方法:%s", typs[i])}
}
// 将聚合结果添加到当前映射中。
curMap[fmt.Sprintf("%s_%s", c, typs[i])] = value
}
// 将当前映射添加到结果切片中。
dfMaps = append(dfMaps, curMap)
}
// 根据结果映射的数据类型创建列类型映射。
colTypes := map[string]series.Type{}
for k := range dfMaps[0] {
switch dfMaps[0][k].(type) {
case string:
colTypes[k] = series.String
case int, int16, int32, int64:
colTypes[k] = series.Int
case float32, float64:
colTypes[k] = series.Float
default:
continue
}
}
// 使用结果映射和列类型映射创建一个新的数据框。
gps.aggregation = LoadMaps(dfMaps, WithTypes(colTypes))
return gps.aggregation
}
Rolling Window
Rolling Window用于进行滚动窗口计算。有三个方法:
- Rolling方法用于创建一个新的RollingWindow对象。
- Mean方法返回滚动均值,通过调用getBlocks方法获取每个窗口大小的子序列,并计算它们的均值。
- StdDev方法返回滚动标准差,同样通过调用getBlocks方法获取每个窗口大小的子序列,并计算它们的标准差。
其中,getBlocks方法是核心方法,用于获取每个窗口大小的子序列。它通过遍历原始序列的每个元素,如果元素的位置小于窗口大小,则将一个空的Series对象添加到结果中;否则,通过计算窗口的索引范围,截取对应的子序列并将其添加到结果中。
func (r RollingWindow) getBlocks() (blocks []Series) {
for i := 1; i <= r.series.Len(); i++ {
if i < r.window {
// 如果当前索引小于窗口大小,则将块初始化为一个空的Series切片,并继续下一次循环
blocks = append(blocks, r.series.Empty())
continue
}
index := []int{}
for j := i - r.window; j < i; j++ {
// 构建一个索引切片,用于获取当前块所需的子集索引
index = append(index, j)
}
// 获取当前块的子集,并将其添加到块切片中
blocks = append(blocks, r.series.Subset(index))
}
return
}
Tips:
所有源码及注释:
https://github.com/Pilo-pillow/gota_study
本文来自:
https://pillow-blog.top/index.php/archives/55/#readmode