
Angora: Efficient Fuzzing by Principled Search
摘要
Angora的目标是提高分支覆盖率,不使用符号执行的方法来解决路径约束(听上去很神啊)
那么为了解决路径约束,本文引入一些关键技术:
- 可扩展的byte级别的taint跟踪
- 上下文有关的分支计数
- 基于搜索的梯度下降
- 输入长度探索
在LAVA-M数据集上,Angora几乎发现了所有的注入bug,而且比其他fuzzer找到更多bugs
1 介绍
已有的一些fuzzers使用magic bytes进行简单的fuzz,但是不能解决其他类型的路径约束
2 背景:AFL
2.1分支覆盖
AFL通过一系列branches记录path。AFL记录每个branch执行了多少次。branch表示为二元组 ( l p r e v , l c u r ) (l_{prev}, l_{cur}) (lprev,lcur)。 l p r e v l_{prev} lprev和 l c u r l_{cur} lcur分别表示条件语句前后的基本块的ID。 h ( l p r e v , l c u r ) h(l_{prev}, l_{cur}) h(lprev,lcur)表示分支的哈希值。
branch coverage table在每次运行时用8-bit记录每个分支执行的次数。举个栗子:若
b
3
b_3
b3设置了,则说明存在一个执行使这个分支执行[4,7]次。AFL就用这个来启发式的判定新的输入是否触发了一个新的内部状态。当下面任意一个条件成立时,就说明触发了一个新的内部状态:
- 程序执行了一个新的分支
- 存在一个分支执行的次数 n n n,与已有的执行次数不同。
2.2 变异策略
- bit或byte翻转
- 尝试设置“有意思”的bytes,words,dwords
- 在bytes,words,dwords上增加或减去小的整数
- 完全随机的单byte集合
- 块删除,块重复或插入等
- 将两个输入拼接
3 设计
3.1 总览

每个fuzzing loop,Angora都选择一个没探索到的分支去搜索探索这个分支的输入,接下来介绍主要技术:
- 对于大多条件语句,判定主要被输入中的少数字节影响,所以不需要变异整个输入。因此,当探索到新分之时,
Angora会哪些输入字节流参与判定并只变异这些字节 - 在确定编译的字节后,
Angora需要确定如何变异他们。使用随机或者启发式的变异方法可能不会有效快速地发现适合的值,因此讲分支上的路径约束看做输入上的黑盒函数,用梯度下降的方法去求解 - 在梯度下降期间,有些参数包含多个字节。举个例子,在输入中有四个连续的字节常常作为整数流同时使用,此时我们应该把这四个参数看做是一个输入。为了实现这个目标,我们需要推断输入中的哪些字节常常用于单个值,以及这些值的类型是什么
- 变异字节流是远远不够的,一些bug在输入长度超过一定阈值后才会触发。
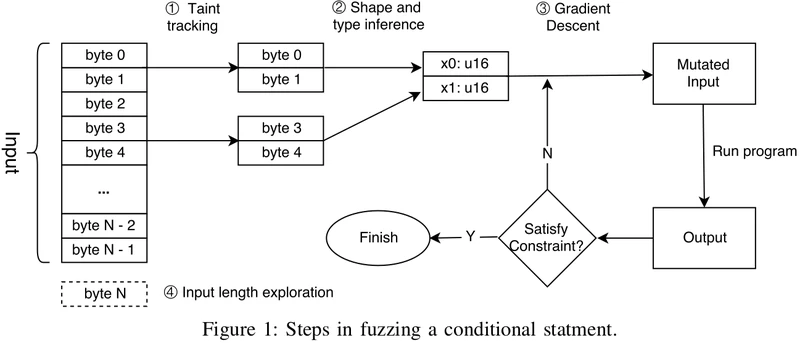

- Byte-level taint tracking:代码如图2所示,fuzzing第二行的条件时,使用byte-level taint tracking,它只和1024-1031这8个bit有关(前1024个char和传入参数i与j无关)。
- Search algorithm based on gradient descent:也是看第二行,通过梯度下降使参数满足不同分支
- Shape and type inference:假设
f
(
x
)
f(x)
f(x)是一个关于向量
x
\mathbf{x}
x的函数,通过梯度下降,
Angora计算f对每个分量(参数)的偏导,所以需要确定每个分量(参数)的大小和类型 - Input length exploration:main不会调用foo除非输入中至少有1032个字节。本文的方法不盲目尝试更长的输入,而是通过插桩读入函数来判断是否更长的输入会探索到新的状态。举个栗子,如果初始化输入小于1024字节,那么12行的代码会直接退出,
fread的返回值与1024比较,所以Angora知道了只有在输入不小于1024时才会探索到false分支
3.2 上下文敏感分支计数
AFL中实现的branch execution table存在局限性,AFL中分支是上下文无关的,所以在不同上下文中执行同一个分支就区分不出来。

举个栗子,见Fig. 3。考虑第3行,input[]=[true, false]和input[]=[false, true]会产生不同的结果,因为第二个输入会使triger=true,进而触发crash。于是用一个三元组
(
l
p
r
e
v
,
l
c
u
r
,
c
o
n
t
e
x
t
)
(l_{prev}, l_{cur}, context)
(lprev,lcur,context)定义一个分支,其中
c
o
n
t
e
x
t
context
context是
h
(
s
t
a
c
k
)
h(stack)
h(stack),
s
t
a
c
k
stack
stack包含了调用栈的状态。
Angora的
h
h
h做法是把调用栈中所有的调用点的ID进行
x
o
r
xor
xor,也就是说
h
(
s
t
a
c
k
)
=
⊕
c
s
∈
s
t
a
c
k
I
D
(
c
s
)
h(stack) = \oplus_{cs\in stack}ID(cs)
h(stack)=⊕cs∈stackID(cs)。
3.3 字节级别的污点分析
污点跟踪的代价是昂贵的,特别是跟踪的字节不是相互独立的情况下,所以AFL没有使用这个。
本文的观点是污点跟踪在大多数程序执行情况下式不必要的。Angora把变量
x
x
x与taint label
t
x
t_x
tx关联,
t
x
t_x
tx记录
x
x
x在输入中的字节偏移。taint label一个简单的实现是用一个bit vector,
i
t
h
i^{th}
ith比特表示
i
t
h
i^{th}
ith字节,但是这个向量大小与输入大小呈线性关系。于是为了减少taint label的大小,把bit vector保存在table里,由于需要记录的实体远小于字节的长度,所以能够很好的减少空间。
但是这种数据结构导致了新的挑战,taint label需要支持以下操作:
- I N S E R T ( b ) INSERT(b) INSERT(b):插入一个bit vector,返回其label
- F I N D ( t ) FIND(t) FIND(t):返回taint label t t t的的bit vector
- U N I O N ( t x , t y ) UNION(t_x, t_y) UNION(tx,ty):返回taint label为 t x t_x tx和 t y t_y ty的bit vector的union
然后大致意思是说明 U N I O N UNION UNION操作的代价很大。。
然后提出了一个新的数据结构存储这些bit vector来有效地支持以上三个操作:
对于每个bit vector,纾解结构给他一个unique uint作为label。当插入一个新的bit vector时,数据结构给他分配下一个可用的uint。
数据结构包含两个组件:
- 一个二叉,保存bit vector到label的映射关系。每个bit vector b b b表示为树上的一个结点 v b v_b vb,层次为 ∣ b ∣ |b| ∣b∣, ∣ b ∣ |b| ∣b∣为 b b b的长度。 v b v_b vb保存 b b b的label。(这!特!马!不!就!是!trie!树!嘛!)
- 查询表,记录从label到bit vector的映射
然后。。如果 x 00 ∗ x00* x00∗在树中,而 x 0 [ 01 ] ∗ 1 [ 01 ] ∗ x0[01]*1[01]* x0[01]∗1[01]∗不在数中,那么 x x x的下一级结点只需要有一个叶子 00 ∗ 00* 00∗。所以又提出了剪枝策略。。技术细节我就不看了。。(还是看了一眼真滴强,还分析了空间复杂度。。)
3.4 基于梯度下降的搜索策略
字节级别的污点跟踪输入中的哪些字节传入条件表达式中进行计算。但是如何变异这些输入来探索未探索到的区域?
已有的很多fuzzer都是随机地变异输入或使用粗糙的启发式方法。
本文把探索为探索区域的问题视为搜索问题。假设有一个黑盒函数 f ( x ) f(\mathbf{x}) f(x),其中 x \mathbf{x} x是一个值的向量。对于 f ( x ) f(x) f(x)有三种约束:
- f ( x ) < 0 f(x)\lt 0 f(x)<0
- f ( x ) ≤ 0 f(x)\leq 0 f(x)≤0
- f ( x ) = = 0 f(x)==0 f(x)==0
然后一些比较就可以转换为上述三种约束了,如下表:

若有逻辑表达式&&或||,就把他们拆成多条单独的判断,如:
if (a && b) {s} else {t}
就可以转化为:
if (a) {if (b) {s} else {t}}

然后上面这个算法5就展示了搜索算法,每次迭代从输入 x \mathbf{x} x开始,然后计算 f ( x ) f(\mathbf{x}) f(x)在 x \mathbf{x} x处的梯度$\nabla_x f(x) , 然 后 进 行 梯 度 下 降 操 作 ,然后进行梯度下降操作 ,然后进行梯度下降操作x\leftarrow x - \epsilon\nabla_x f(x) , 其 中 ,其中 ,其中\epsilon$是学习率。
机器学习中的梯度下降常常会陷入局部最优,但是在fuzzing中不存在这个问题,举个栗子,若一个约束是 f ( x ) < 0 f(x)\lt 0 f(x)<0,我们只需要找到满足这个约束的 x x x就行了,而不需要找到 f ( x ) f(x) f(x)的全局最小值。
在神经网络中,求偏导可以得到 f ( x ) f(x) f(x)的解析形式,但是在fuzzing时 f ( x ) f(x) f(x)是黑盒的。
对于这个问题采取使用数值近似的方法:
∂
f
(
x
)
∂
x
i
=
f
(
x
+
δ
v
i
)
−
f
(
x
)
δ
\frac{\partial f(x)}{\partial x_i}=\frac{f(x+\delta v_i)-f(x)}{\delta}
∂xi∂f(x)=δf(x+δvi)−f(x)
其中
v
i
v_i
vi是第
i
i
i维的单元向量。
理论上梯度下降可以解决任何约束,在实际中,梯度下降的速度依赖于数学函数的复杂度:
- 如果 f ( x ) f(x) f(x)是单调或者凸函数,梯度下降可以很快的找到解,即使 f ( x ) f(x) f(x)是一个复杂的解析形式
- 若局部最小值满足约束,那么找到解也是很快的
- 若局部最优找不到解,
Angora会随机采样到其他的 x ′ \mathbf{x'} x′,然后重新进行梯度下降来找到另一个满足约束的局部最优
3.5 形状和类型推导
x \mathbf{x} x是输入中值的向量。
我们可以把 x \mathbf{x} x中的每一个字节作为一个元素。但是在梯度下降时,由于类型不匹配会产生问题。
假设四个连续的字节序列 b 3 b 2 b 1 b 0 b_3b_2b_1b_0 b3b2b1b0是一个整数, x i x_i xi表示一个整数值。当计算 f ( x + δ v i ) f(x+\delta v_i) f(x+δvi)时,我们应该 δ \delta δ到整数中。但是这样简单地把 x x x中的每个字节 b i b_i bi看做一个值,把其中某个字节增加后再拼接起来,在求偏导数就会出现问题。
为了抑制这个问题,需要确定:
- 输入中的哪些字节常作为一个值来使用
- 值的类型是什么
本文把第一个问题称为shape inference,第二个问题称为type inference,并在动态污点分析时解决他们。
对于shape inference,初始化输入中的所有字节都是独立的。在污点分析期间,当插桩读到字节序列符合某些原始的大小(1,2,4,8字节等),Angora就会把这些字节标记为同一个值。当产生冲突时,Angora选择匹配到的最小的size。
对于type inference,Angora依赖于在这些值上的操作的插桩。举个栗子,如果在一个有符号整数上进行插桩操作,Angora就会把两个操作数视为有符号整数。若一个值同时作为有符号和无符号整数,则把他视为无符号类型。如果Angora没有成功推导值的精确的大小和类型,梯度下降并不会阻碍它找到一个结果,只是搜索时间会更长。

3.6 输入长度探索
Angora只在可能探索到新分支的时候增加输入长度
在污点跟踪时,Angora把read相关函数调用的目标内存地址和相关的字节偏移相关联,同时也记录read调用的返回值,如果返回值在条件语句中使用且约束不满足,则Angora增加输入长度。
4 实现
4.1. 插桩
对于每一个分析的程序,Angora通过使用LLVM Pass插桩得到相关的可执行文件
插桩工具:
- 收集条件表达式的基本信息,将条件语句链接到相关的输入字节使用污染分析
- 记录执行的路径来识别新的输入
- 支持运行时上下文
- 在判定时收集表达式的值
Angora依赖于LLVM 4.0.0,LLVM Pass包含820行c++代码,运行时有1950行代码
4.2 Fuzzer
使用4488行Rust代码实现了Angora
5 评价
5.1 Angora与其他fuzzers比较
5.2 在未修改的真实程序上评价Angora
5.3 上下文敏感计数
5.4 基于搜索的梯度下降
5.5 输入长度探索
5.6 执行速度
6 相关工作
6.1 种子输入优先级
6.2 基于污染的fuzzing
6.3 符号执行辅助的fuzzing
7 结论
我们设计实现了Angora,可以产生高质量的输入,借助了本文提出的关键技术:可扩展的字节级别的污点跟踪,上下文敏感的分支计数,基于搜索算法的梯度下降,shape和类型推导,输入长度探索。在LAVA数据集上找到了103个LAVA作者没有准备的bugs。在8个真实开源的项目上发现了175个新bug。