
一、正则表达式
1、简介
正则表达式 (RE) 是一种字符模式,用于在查找过程中匹配指定的字符。大多数程序中,正则表达式置于两个正斜杠之间。
2、示例
判断用户输入的内容是否为数字:if [[ $num =~ ^[0-9]+$ ]]
=~ 正则表达式匹配符
^[0-9]:以0-9任意一个数开头
+$:以一个或多个数字结尾

3、元字符
(1) 简介:用一类字符表达特殊的含义。
(2) 基本正则表达式元字符
^ 行首定位符

$ 行尾定位符
. 匹配任意单个字符
* 匹配前导符 0 到多次 (c 出现 0 次 ~ 多次)

.* 匹配任意多个字符

[ ] 匹配指定范围内的一个字符
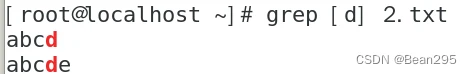
[-] 匹配连续范围内的字符 ( [a-z] )
[^] 匹配不在指定范围内的字符 ( [^a-z] )
\ 转义元字符
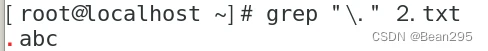
\< 词首定位符 ; \> 词尾定义符

() 组字符,将匹配的部分作为一个整体
例 :1,5 s/\(.*\)/#\1/
s/ / / sed 替换操作
\(.*\) (.*) 匹配所有的内容并作为一个整体,括号前加上 \ 转义
/# 在匹配的内容前添加 #
\1 第一部分 每个 () 代表一个部分

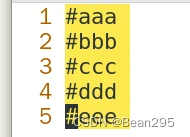
x\{m\} 字符x出现m次
x\{m,\} 字符x出现m次及以上
x\{m,n\} 字符x出现m到n次
(3) 扩展正则表达式元字符
| + | 匹配 1~n 个前导符 |
| ? | 匹配 0~1 个前导符 |
| a|b | 匹配 a 或 b |
(4) 示例:
| /^[A-Z]..$/ | 以一个大写字母开头,两个任意字符结尾 |
| /^[A-Z][a-z]*3[0-5]/ | A-Z开头;a-z 出现0或多次;跟一个3;结尾是数字 0-5 |
| /^ *[A-Z][a-z][a-z]$/ | 0到多个空格开头;跟一个大写两个小写 |
| /^[A-Za-z]*[^,][A-Za-z]*$/ | 以0到多个任意字母开头;不以, 开头;任意字母结尾 |
| /5{2}2{3}\./ | 5出现两次;2出现3次;跟一个点 . |
| /^[ \t]*$/ | 搜索 0 到多个空格或 tab 的行 |
| /^[ \t]*#/ | 搜索 0 到多个空格或 tab 的注释行 |
| :1,$ s/\([Oo]ccure\)ence/\1rence/ | :1,$ 匹配1到末尾行 s/\([Oo]ccure\)ence/\1rence/ 在 Occure 或 occure 后面加上 rence |
二、grep
1、作用:
查找文档中的内容
grep 查找的内容 查找位置1 查找位置2 …
2、种类
| grep | 支持基本正则表达式元字符搜索 |
| egrep | 支持扩展正则表达式元字符搜索 |
| fgrep | 不支持正则表达式元字符搜索 |
3、返回值
| 返回 0 | 找到结果 |
| 返回1 | 没找到结果 |
| 返回2 | 搜索的位置有错误 |
4、参数
| -q | 静默搜索(不输出搜索结果) |
| -v | 取反搜索 |
| -R | 查看目录下的文件 |
| -o | 只找关键字 |
| -B2 | 显示搜索的内容及前两行 |
| -A2 | 显示搜索的内容及后两行 |
| -C2 | 显示搜索的内容及上下两行 |
| -n | 显示行号 |
三、sed
1、简介
Stream EDitor:流编辑,用于从文本文件或标准输入流中读取文本,并根据用户指定的规则进行文本编辑和转换。
2、格式
① sed 选项 命令 文件
② sed 选项 -f 脚本 文件
3、返回值
sed 的返回值都是 0,无论对错;只有命令存在语法错误时,才为非 0
4、sed 命令
删除命令:d
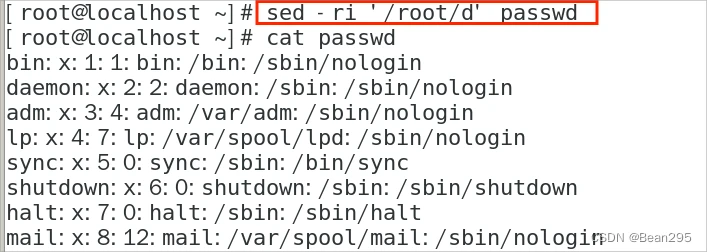
① sed -r '/root/d' passwd:
-r:支持匹配正则表达式元字符
'/root/d':/匹配的内容/d 删除
passwd:查找的文件
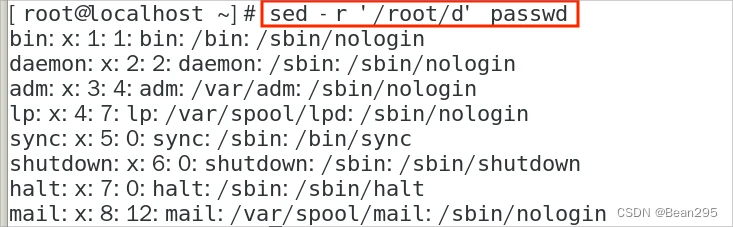
文件本身没有被改变,需要加上 -i 选项才会修改文件内容:
② sed -r '数字d':删除第几行
例:sed -r '3d':删除第三行 ;'1,3d':删除 1~3 行 ;'$':删除尾行
替换命令:s
sed -r 's/root/aofa/' passwd: 默认只替换每行的第一个 root
sed -r 's/root/aofa/g' passwd: g → global 全局替换
sed -r 's/^root/aofa/' passwd: /^root/ → 替换以 root 为行首的行
sed -r 's/[0-9][0-9]$'/&.5/' passwdz:[0-9][0-9] 以两个数字结尾;&.5:调用前方匹配的内容,再加 0.5(10→10.5)
读文件命令:r
在当前文件中读取其他文件内容
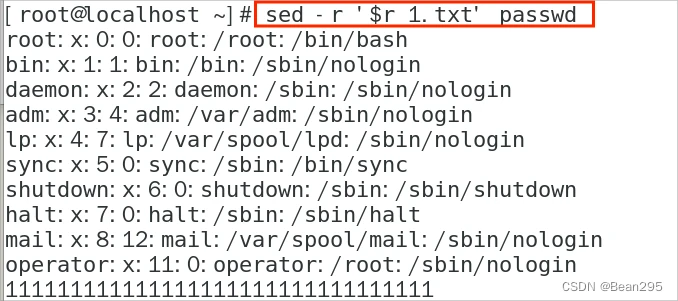
sed -r '$r 1.txt' passwd:在末行读取 1.txt 的内容
不指定行则会在每一行都都读取 1.txt 的内容
写文件命令:w(另存为)
sed -r 'w 123.txt' 1.txt:把 1.txt 的内容存到 123.txt
追加命令:a(添加在行后);i(添加在行前)
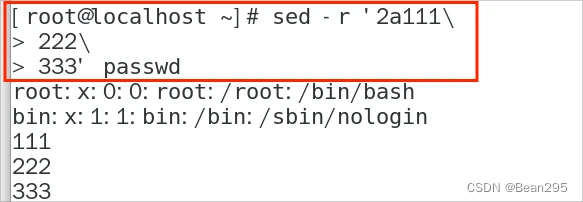
sed -r '2a123' passwd:在 passwd 第二行后添加123
插入多行:用 \ 转义回车
替换整行命令:c
sed -r '2caaaaaa' passwd:把第二行换成 aaaaaa
获取下一行命令:n
反向选择:!
sed -r '2,$!d' passwd:2到最后一行之外的部分删除
多重编辑:e
在一条命令中发布多条指令
sed -r -e '1,3d' -e '4s/adm/admin/g' passwd
四、awk
1、awk 工作原理
逐行处理文件,寻找匹配了特定模式的行,并进行相应操作。
awk 将每行赋值给内部变量 $0,再将一行里的每一个字段依次赋值给$1、$2… 处理完一行后再接着处理下一行。

-F: 将冒号作为分隔符

2、语法
awk 选项 '命令' 文件名
awk 命令:
BEGIN{ }:行处理前
{ }:行处理时,读一行执行一行
END{ }:行处理后

3、awk 内部变量
FS:输入字段分隔符,默认空格,-F的另一种写法
awk 'BEGIN{FS=":"} {print $1}' passwd

OFS:输出字段分隔符,默认空格
awk 'BEGIN{FS=":";OFS="++"} {print $1,$2,$3}' passwd

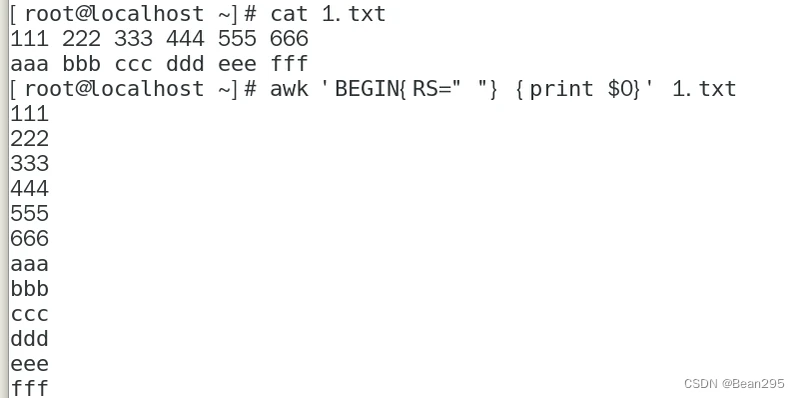
RS:输入记录分隔符,默认是换行符
awk 'BEGIN{RS=" "} {print $0}' 1.txt
将空格作为记录分隔,而不是回车
ORS:输出记录分隔符,默认是换行符
awk 'BEGIN{ORS="++"} {print $0}' 1.txt
输出的记录以++作为分隔
![]()
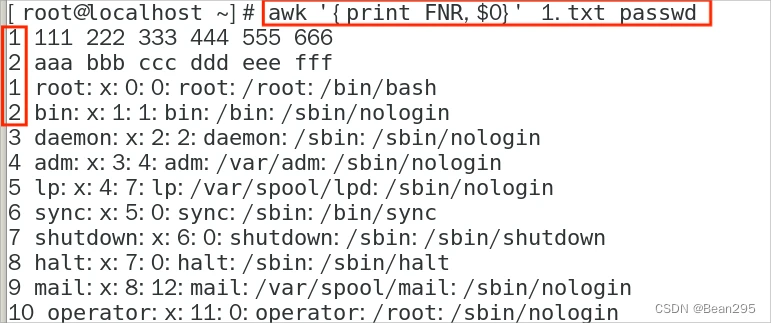
FNR:多文件独立编号
NR:多文件汇总编号
NF:统计字段总数
awk '{print NF,$0}' 1.txt

4、模式(正则表达)和动作
模式可以是任何条件语句或复合语句或正则表达式,模式决定动作语句何时触发及触发事件。
(1) 字符串比较
awk '$0 ~ /^root/' passwd:像以 root 开头的字段
(2) 数值比较
awk -F: '$3 > 10' passwd:$3 字段大于 10 的行
== 既可以用于数值比较,也可以用于字符串判断。
(3) 运算
+ - * / % ^
awk -F: '$3*2 > 5' passwd
(4) 逻辑操作符和复合模式
&&:逻辑与 ; || :逻辑或 ; !逻辑非
(5) 范围模式
语法:awk '/从哪里/, /到哪里/' 文件名

五、awk 脚本编程
1、条件判断
(1) if 语句
格式:{ if (表达式) {语句1;语句2;…} }
示例:判断用户 id 是否为 0
awk -F: '{if($3==0){print $1"是管理员"}}' passwd
(2) if … else 语句
格式:{ if (表达式) {语句1;语句2;…} else {语句1;语句2;…} }
awk -F: '{if($3==0){print $1"是管理员"} else {print $1"是普 通用户"}' passwd
(3) 多分支语句
示例:显示三种用户的信息(管理员 id=0、内置用户 id<1000、普通用户 id>999)
awk -F: '{ if($3==0){num1++} else if($3>999){num3++} else {num2++}} END{print num1;print num2;print num3}' /etc/passwd

2、循环
while、for
循环打印 1~10
awk 'BEGIN{while(i<=10) {print i;i++} }'
awk 'BEGIN{for(i=1;i<=10;i++) {print i} }'
3、数组
awk -F: '{username[i++]=$1}END{for(i in username){print i, username[i]}}' passwd | sort
把用户名添加进数组,再通过 for 循环打印出用户名
