
目录
前言
什么是 Fragment Shader(片段着色器)?
为什么 shaders 运行特别快?
为什么 Shaders 有名但不好学?
Hello World
总结
前言
Shader(着色器)是一种计算机程序,主要用于控制计算机图形学中的图形渲染过程。它定义了图形对象的表面属性、光照效果、材质质感等,在渲染过程中确定最终图像的外观。着色器通常由顶点着色器和片段着色器组成。
-
顶点着色器(Vertex Shader):顶点着色器负责处理场景中的顶点数据。它接收输入的顶点信息,并对其进行一系列操作,如变换、光照计算、法线处理等。顶点着色器的输出结果会传递给下一阶段。
-
片段着色器(Fragment Shader):片段着色器也称为像素着色器,负责处理图形对象内部的每个像素(片段)。它对输入的像素属性进行计算,如颜色、纹理坐标、法线等,并根据需要执行光照、纹理采样、色彩插值等操作,以确定最终像素的颜色。
什么是 Fragment Shader(片段着色器)?
如果你曾经有用计算机绘图的经验,你就知道在这个过程中你需要画一个圆,然后一个长方形,一条线,一些三角形……直到画出你想要的图像。这个过程很像用手写一封信或一本书 —— 都是一系列的指令,需要你一件一件完成。
Shaders 也是一系列的指令,但是这些指令会对屏幕上的每个像素同时下达。也就是说,你的代码必须根据像素在屏幕上的不同位置执行不同的操作。就像活字印刷,你的程序就像一个 function(函数),输入位置信息,输出颜色信息,当它编译完之后会以相当快的速度运行。

为什么 shaders 运行特别快?
为了回答这个问题,不得不给大家介绍并行处理(parallel processing)的神奇之处。
想象你的 CPU 是一个大的工业管道,然后每一个任务都是通过这个管道的某些东西 —— 就像一个生产流水线那样。有些任务要比别的大,也就是说要花费更多时间和精力去处理。我们就称它要求更强的处理能力。由于计算机自身的架构,这些任务需要串行;即一次一个地依序完成。现代计算机通常有一组四个处理器,就像这个管道一样运行,一个接一个地处理这些任务,从而使计算机流畅运行。每个管道通常被称为线程。
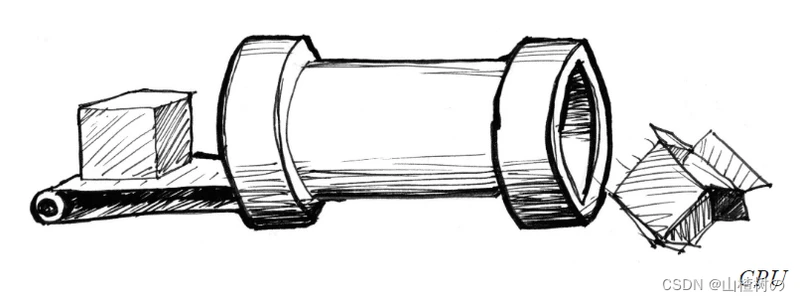 视频游戏和其他图形应用比起别的程序来说,需要高得多的处理能力。因为它们的图形内容需要操作无数像素。想想看,屏幕上的每一个像素都需要计算,而在 3D 游戏中几何和透视也都需要计算。
视频游戏和其他图形应用比起别的程序来说,需要高得多的处理能力。因为它们的图形内容需要操作无数像素。想想看,屏幕上的每一个像素都需要计算,而在 3D 游戏中几何和透视也都需要计算。
让我们回到开始那个关于管道和任务的比喻。屏幕上的每个像素都代表一个最简单的任务。单独来看完成任何一个像素的任务对 CPU 来说都很容易,那么问题来了,屏幕上的每一个像素都需要解决这样的小任务!也就是说,哪怕是对于一个老式的屏幕(分辨率 800x600)来说,都需要每帧处理480000个像素,即每秒进行14400000次计算!是的,这对于微处理器就是大问题了!而对于一个现代的 2800x1800 视网膜屏,每秒运行60帧,就需要每秒进行311040000次计算。图形工程师是如何解决这个问题的?
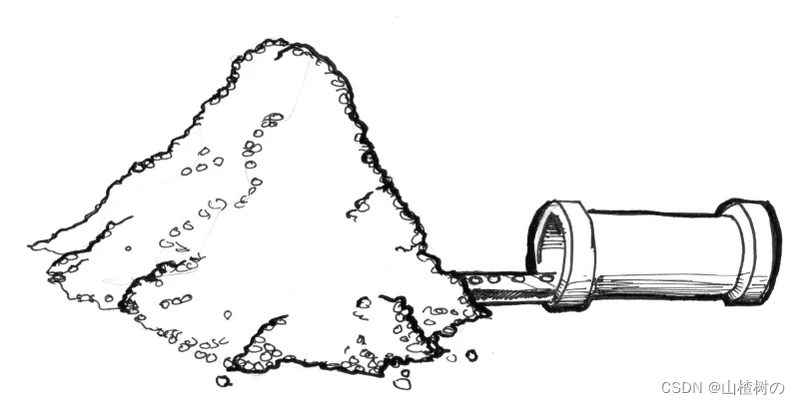
这个时候,并行处理就是最好的解决方案。比起用三五个强大的微处理器(或者说“管道”)来处理这些信息,用一大堆小的微处理器来并行计算,就要好得多。这就是图形处理器(GPU : Graphic Processor Unit)的来由。
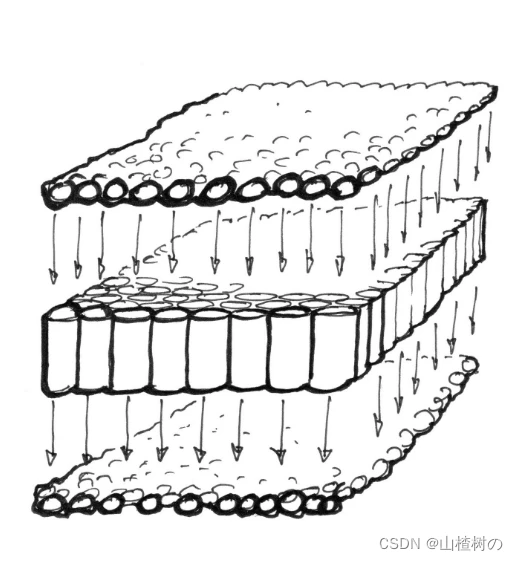
设想一堆小型微处理器排成一个平面的画面,假设每个像素的数据是乒乓球。14400000个乒乓球可以在一秒内阻塞几乎任何管道。但是一面800x600的管道墙,每秒接收30波480000个像素的信息就可以流畅完成。这在更高的分辨率下也是成立的 —— 并行的处理器越多,可以处理的数据流就越大。
另一个 GPU 的魔法是特殊数学函数可通过硬件加速。非常复杂的数学操作可以直接被微芯片解决,而无须通过软件。这就表示可以有更快的三角和矩阵运算 —— 和电流一样快。
为什么 Shaders 有名但不好学?
就像蜘蛛侠里的那句名言,能力越大责任越大,并行计算也是如此;GPU 的强大的架构设计也有其限制与不足。
为了能使许多管线并行运行,每一个线程必须与其他的相独立。我们称这些线程对于其他线程在进行的运算是“盲视”的。这个限制就会使得所有数据必须以相同的方向流动。所以就不可能检查其他线程的输出结果,修改输入的数据,或者把一个线程的输出结果输入给另一个线程。允许数据在线程之间线程流动会使数据的整体性面临威胁。
并且 GPU 会让所有并行的微处理器(管道们)一直处在忙碌状态;只要它们一有空闲就会接到新的信息。一个线程不可能知道它前一刻在做什么。它可能是在画操作系统界面上的一个按钮,然后渲染了游戏中的一部分天空,然后显示了一封 email 中的一些文字。每个线程不仅是“盲视”的,而且还是“无记忆”的。同时,它要求编写一个通用的规则,依据像素的不同位置依次输出不同的结果。这种抽象性,和盲视、无记忆的限制使得 shaders 在程序员新手中不是很受欢迎。
Hello World
“Hello world!”在 GPU 的世界里,第一步就渲染一行文字太难了,所以我们改为选择一个鲜艳的欢迎色!
#ifdef GL_ES
precision mediump float;
#endif
uniform float u_time;
void main() {
gl_FragColor = vec4(1.0,0.0,1.0,1.0);
}
效果

尽管这几行简单的代码看起来不像有很多内容,我们还是可以据此推测出一些知识点:
-
shader 语言 有一个
main函数,会在最后返回颜色值。这点和 C 语言很像。 -
最终的像素颜色取决于预设的全局变量
gl_FragColor。 -
这个类 C 语言有内建的变量(像
gl_FragColor),函数和数据类型。在本例中我们刚刚介绍了vec4(四分量浮点向量)。之后我们会见到更多的类型,像vec3(三分量浮点向量)和vec2(二分量浮点向量),还有非常著名的:float(单精度浮点型),int(整型) 和bool(布尔型)。 -
如果我们仔细观察
vec4类型,可以推测这四个变元分别响应红,绿,蓝和透明度通道。同时我们也可以看到这些变量是规范化的,意思是它们的值是从0到1的。之后我们会学习如何规范化变量,使得在变量间map(映射)数值更加容易。 -
另一个可以从本例看出来的很重要的类 C 语言特征是,预处理程序的宏指令。宏指令是预编译的一部分。有了宏才可以
#define(定义)全局变量和进行一些基础的条件运算(通过使用#ifdef和#endif)。所有的宏都以#开头。预编译会在编译前一刻发生,把所有的命令复制到#defines里,检查#ifdef条件句是否已被定义,#ifndef条件句是否没有被定义。在我们刚刚的“hello world!”的例子中,如果定义了GL_ES这个变量,才会插入运行第2行的代码,这个通常用在移动端或浏览器的编译中。 -
float类型在 shaders 中非常重要,所以精度非常重要。更低的精度会有更快的渲染速度,但是会以质量为代价。你可以选择每一个浮点值的精度。在第一行(precision mediump float;)我们就是设定了所有的浮点值都是中等精度。但我们也可以选择把这个值设为“低”(precision lowp float;)或者“高”(precision highp float;)。 - 最后可能也是最重要的细节是,GLSL 语言规范并不保证变量会被自动转换类别。这句话是什么意思呢?显卡的硬件制造商各有不同的显卡加速方式,但是却被要求有最精简的语言规范。因而,自动强制类型转换并没有包括在其中。在我们的“hello world!”例子中,
vec4精确到单精度浮点,所以应被赋予float格式。但是如果你想要代码前后一致,不要之后花费大量时间 debug 的话,最好养成在float型数值里加一个.的好习惯。如下这种代码就可能不能正常运行:
void main() {
gl_FragColor = vec4(1,0,0,1); // 出错
}总结
Shader着色器使用特定的着色器语言编写,如OpenGL Shading Language(GLSL)或HLSL(High-Level Shader Language)。这些语言提供了各种内置函数和变量,用于控制顶点和片段的属性、光照计算、纹理采样等操作。
通过编写着色器,我们可以实现各种复杂的图形效果和渲染技术,如光照、阴影、反射、透明度、纹理映射等。着色器还可以与其他图形处理技术结合,如几何着色器、计算着色器等,以实现更加复杂和精细的图形渲染。
着色器具有很高的执行效率,主要因为它们在图形硬件上运行,并利用了硬件并行计算的能力。同时,着色器可以通过优化算法和数据结构,充分利用现代GPU的功能,进一步提高渲染性能。